機器學習筆記——梯度下降優化方案
- 一、梯度下降粒度優化
- 1.1 Batch gradient descent
- 1.2 Stochastic gradient descent
- 1.3 Mini-batch gradient descent
- 1.4 三種方法的代碼分析
- 二、梯度下降引數優化
- 2.1 步長與梯度的關系
- 2.2 AdaGrad 與 RMSProp
- 2.4 AdaDelta
- 2.5 Momentum 與 Nesterov Momentum
- 2.6 Adam
- 2.7 AdaBelief
一、梯度下降粒度優化
1.1 Batch gradient descent
- 批量梯度下降(Batch gradient descent)是根據所有樣本訓練得到的梯度來更新引數,每更新一次引數便要用到所有的訓練樣本資料集,決定了批量梯度下降法訓練時間長、收斂速度緩慢,
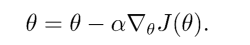
1.2 Stochastic gradient descent
- 隨機梯度下降(Stochastic gradient descent)每次僅根據單個樣本
(
x
i
,
y
i
)
(x^i,y^i)
(xi,yi)計算得到的梯度來更新引數,隨機梯度下降計算簡單收斂速度快,但收斂程序易震蕩不穩定,不穩定的特征有好有壞,好處在于可以讓引數跳出區域最優,壞處在于收斂結果不精確,
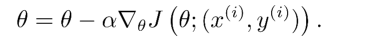
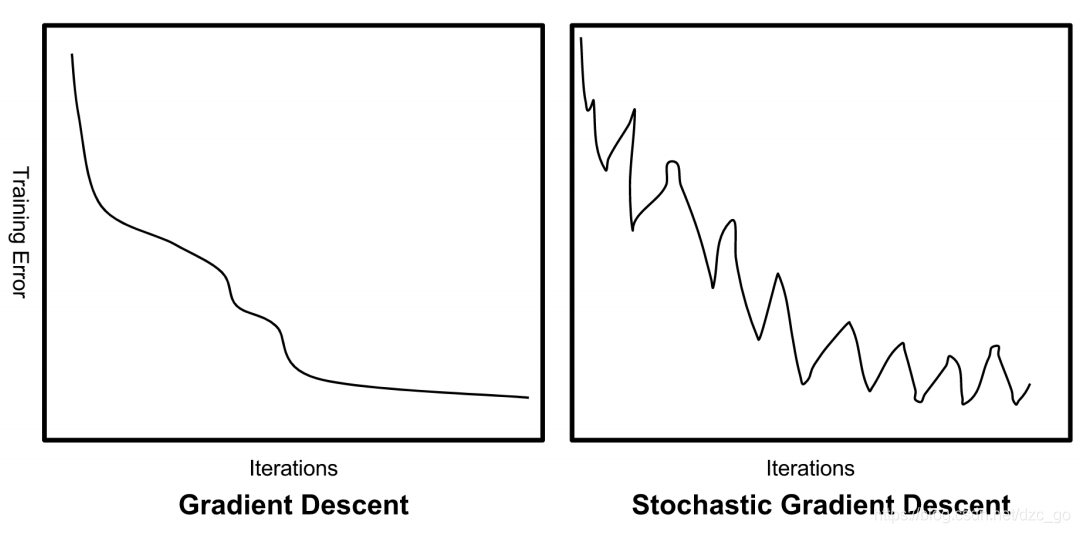
- 下面是批量梯度下降與隨機梯度下降的示意圖,表征訓練誤差隨迭代次數增加的變化規律,可以明顯看出隨機梯度下降抖動明顯,
1.3 Mini-batch gradient descent
- 小批量梯度下降(Mini-bacth gradient descent)是以上兩種方法的綜合,批量梯度下降運算速度、收斂速度慢但收斂穩定,隨機梯度下降運算速度、收斂速度快但收斂易震蕩,
- 其實相對來說,每次更新引數計算1個樣本與每次更新引數計算10個樣本的速度差異不大,而帶來的訓練程序的穩定性優化確實十分巨大的,因此小批量的樣本數大約集中在50-256之間,在保證運算速度的前提下大大優化訓練穩定性,
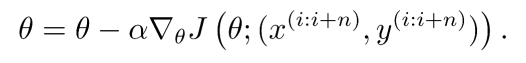
- 批量梯度下降與隨機梯度下降都有明顯的缺陷,因此在大型學習程序中我們普遍使用小批量梯度下降,我們常說的SGD也指的是小批量梯度下降,
1.4 三種方法的代碼分析

- 批量梯度下降每次更新引數都要拿全部訓練集資料參與運算,對訓練集不需要執行什么操作,
- 隨機梯度下降每次更新引數都需要在訓練資料集中隨機挑選一個樣本計算梯度,小批量梯度下降每次需要在訓練集中隨機獲得一個固定大小的樣本集用于計算梯度,需要注意的是:這兩種方法在每次取單個樣本或樣本集之前都需要打亂當前資料集,
二、梯度下降引數優化
2.1 步長與梯度的關系
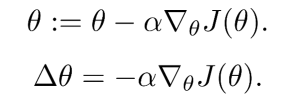
- 上面是我們最基礎的引數更新公式,可以看出步長
Δ
θ
\Delta\theta
Δθ與梯度正相關,也就是說梯度大的地方步長長,梯度下降的速度快步伐大;梯度小的地方步長短,梯度下降的速度慢步伐小,那么這個規律是正確的嗎?的的確確適合于我們梯度下降的程序嗎?
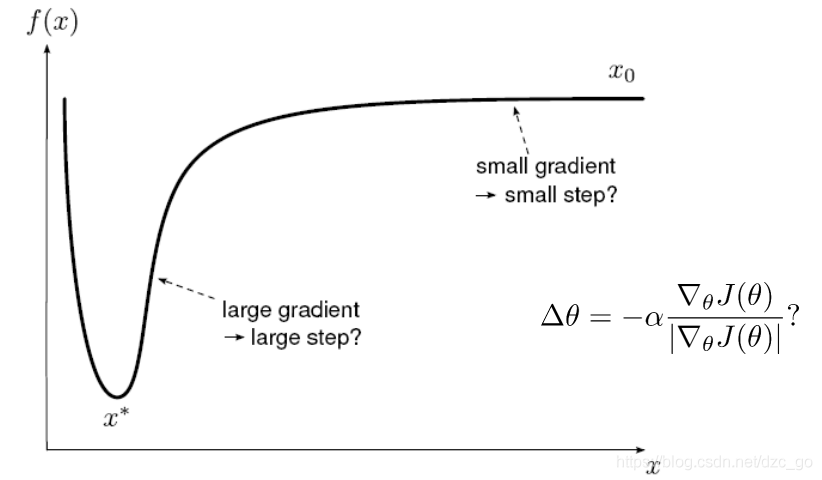
- 上圖我們可以理解為一個特殊的損失函式曲線,可以看出梯度較小也就是說較平坦的地方離最小值較遠,因此我們需要較大步幅加速跳過這部分,而根據上面的正比關系我們得到的確實小步長,同理分析可得,大梯度部分的步長也與理想狀況相反,這樣會導致引數在離最小值較遠的地方遲遲不收斂或者在最小值附近以大步幅來回震蕩下不去,
- 看到了問題,我們就要想方法去解決, Δ θ \Delta\theta Δθ由兩部分決定,梯度與學習率,而梯度是固定不變的,我們就只能在學習率身上下功夫,下面將介紹多種學習率的調整優化方案,
2.2 AdaGrad 與 RMSProp
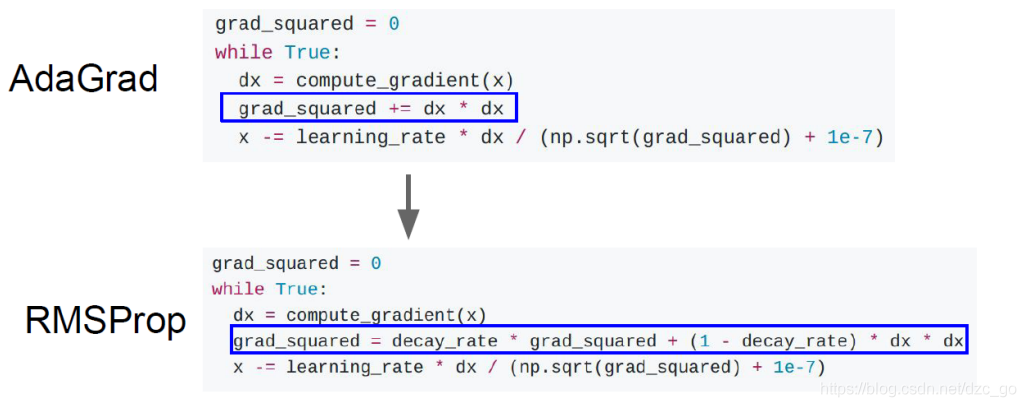
- AdaGrad的基本思路是:梯度下降的不同階段學習率大小不同,也就是說學習率隨著迭代次數改變而改變,梯度下降的不同引數所使用的學習率也要不同,
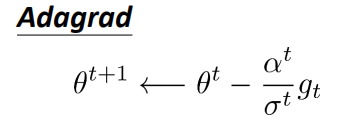
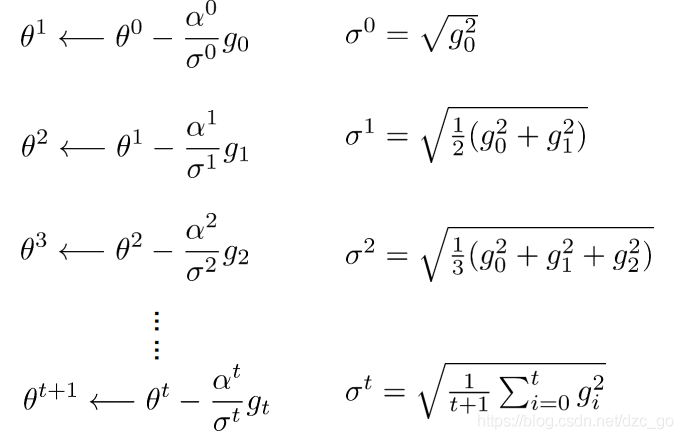
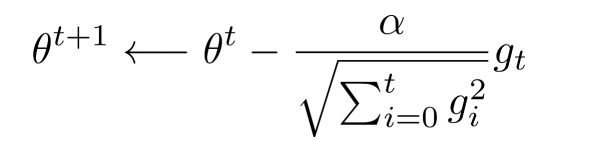
- AdaGrad思路簡單計算也相對好理解,上面最后一個式子是最侄訓簡的結果,分析該式子我們能發現一個問題,當迭代次數很大的時候,分母部分會變得很大從而導致 Δ θ \Delta\theta Δθ很小,也就是出現了我們所說的“學不動了”的情況,
- 針對以上問題,RMSProp應運而生,在計算分母部分以往梯度的平方和時,每次計算都是先以一個0-1之間的比例衰減上次求和值,再加入新平方,這樣每次迭代,越早出現的梯度平方就會乘更多的
ρ
\rho
ρ,也就會衰減的值特別小,不會出現AdaGrad那樣“學不動”的情況,
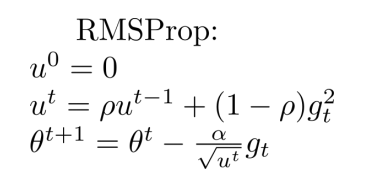
2.4 AdaDelta
- 根據AdaGrad與RMSProp的最侄訓簡后的公式,梯度下降的性能還與一個超參學習率 α \alpha α相關,也就是說我們梯度下降的程序還存在一定的偶然性與不可確定性,性能取決于學習率 α \alpha α的選擇,
- AdaDelta在RMSProp的基礎上針對學習率
α
\alpha
α做出了進一步的修改,取消了超參學習率
α
\alpha
α,取而代之的是
Δ
θ
\Delta\theta
Δθ的RMS函式,修改后的引數調整程序不確定性大大減小,


2.5 Momentum 與 Nesterov Momentum
- 梯度下降法當梯度接近于0時就會出現“學習不動”的情況,我們把這類情況稱之為梯度消失,確實當我們逼近于全域最小值時會出現梯度消失的情況,但出現梯度消失情況時卻不一定是得到了最優解,比如可能卡在了區域最小值或者是卡在了鞍部,
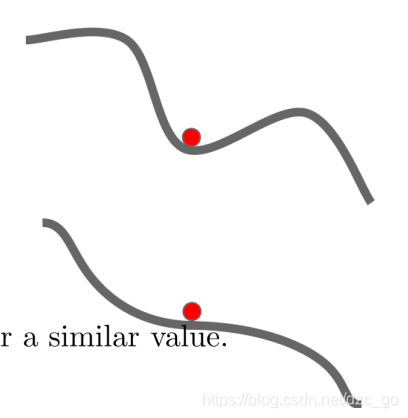
- 如上圖所示,卡在區域最小值或者是卡在鞍部,梯度學習的程序都會停滯,那么我們該用什么方法沖出區域最小或者是鞍部呢?我們引入了物理中實際存在的慣性機制,也就是說小球從高度滾下即便在某些位置沒有繼續加速的動力也會因為慣性沖出這些位置,根據此思想誕生了Momentum(動量)演算法,
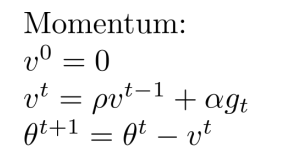
- 舍棄掉之前的
Δ
θ
\Delta\theta
Δθ,現在的
Δ
θ
=
v
t
\Delta\theta=v^t
Δθ=vt,
v
t
v^t
vt一般由兩部分組成,一部分是上一次引數更新的速度乘以一個衰減系數(一般為0.9),另一部分是學習率與梯度在這里插入圖片描述
的乘積, - 在Momentum演算法的基礎之上又創新型地獲得了Nesterov Momentum演算法,該演算法的思想與Momentum的區別主要在于梯度計算的時機,Nesterov Momentum演算法是預判在上一環節速度的基礎上到達位置再做出梯度計算,
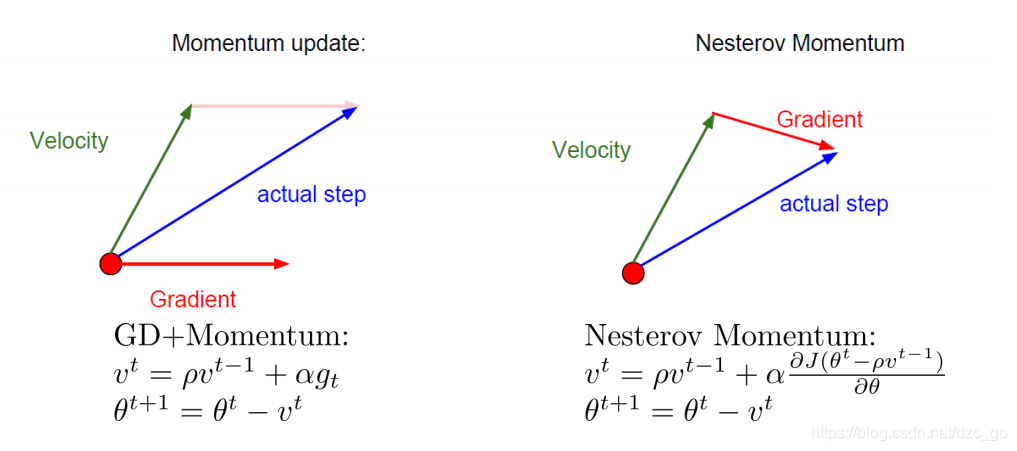
2.6 Adam
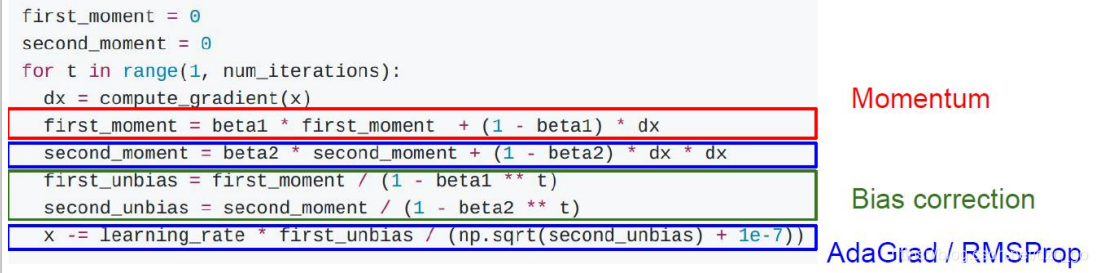
- RMSProp與Momentum演算法分別以不同的角度去優化梯度下降的引數調整細節,我們如果將以上兩種思想進行融合便得到了我們本章節要去探討的Adam演算法,
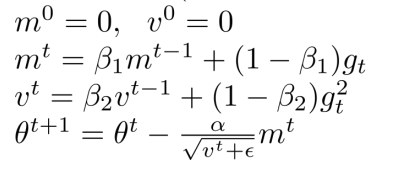
- 其實在Adam公式中我們還是可以看到很多之前演算法的影子,比如說與AdaGrad進行類比,
m
t
m^t
mt來近似模擬
g
t
g_t
gt?,
v
t
v^t
vt來近似模擬
g
t
2
g_t^2
gt2?,
m
t
m^t
mt與
v
t
v^t
vt均使用到了RMSProp中的指數平均的思想,而
v
t
v^t
vt則使用到了Momentum中速度動量的思想,
2.7 AdaBelief
- 我們與Adam相比給出AdaBelief的相關定義公式,可以看出Adam與AdaBelief只有一個地方不同,那就是
v
t
v^t
vt的
g
t
2
g_t^2
gt2?變成了
s
t
s^t
st的
(
g
t
?
m
t
)
2
(g_t-m_t)^2
(gt??mt?)2,
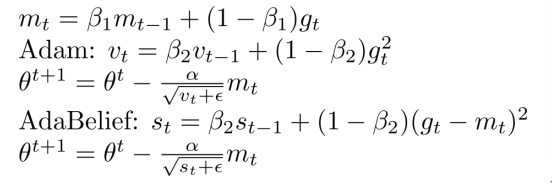
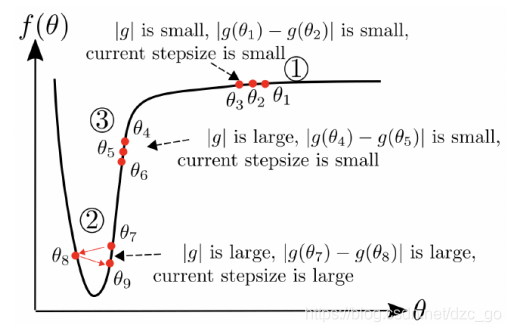
- 在1區域,梯度很小并且距離最小值較遠,我們需要較大步長,SGD步長正比于梯度,因此步長很小,而Adam與AdaBelief分母 v t v^t vt與 s t s^t st都很小,因此步長很大符合要求,
- 在2區域,梯度很大并且距離最小值很近,我們需要較小步長,SGD步長正比于梯度,因此步長很大,而Adam與AdaBelief分母 v t v^t vt與 s t s^t st都很大,因此步長很小符合要求,
- 以上兩區域Adam與AdaBelief沒有明顯的差別,而在3區域就體現出了AdaBelief在“大梯度,小曲率”情況下的優勢,在這種情況下, v t v^t vt與 ∣ g t ∣ |g_t| ∣gt?∣都很大,而 ∣ g t ? g t ? 1 ∣ |g_t-g_{t-1}| ∣gt??gt?1?∣與 s t s^t st很小,理想情況下我們需要大步長,SGD步長正比于梯度,因此步長很大,Adam因為 v t v^t vt很大從而步長很小,AdaBelief因為 s t s^t st很小從而步長很大,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/198063.html
標籤:java
下一篇:Batch Normalization批標準化是什么? | BN有啥用 | Batch Normalization是什么