今天不講原理了,我感覺寫一大堆,讓大家也理解不透
簡要說一下:
- 不僅僅極大提升了訓練速度,收斂程序大大加快;
- 還能增加分類效果,一種解釋是這是類似于Dropout的一種防止過擬合的正則化表達方式,所以不用Dropout也能達到相當的效果;
- 另外調參程序也簡單多了,對于初始化要求沒那么高,而且可以使用大的學習率等,
在網上還找到一些比較不錯的圖,可以啟發
資料做預處理
可以用 normalization 歸一化 ,或者 standardization 標準化,
用來將資料的不同 feature 轉換到同一范圍內,
normalization 歸一化 :將資料轉換到 [0, 1] 之間,
standardization 標準化:轉換后的資料符合標準正態分布

為什么要做歸一化和標準化?
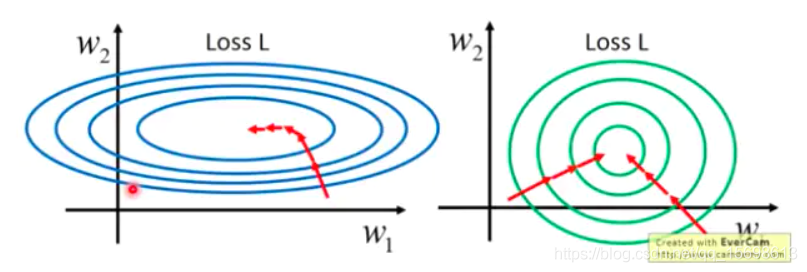
不同的特征具有不同數量級的資料,它們對線性組合后的結果的影響所占比重就很不相同,數量級大的特征顯然影響更大,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/198064.html
標籤:java