現代的開發語言除了C++以外,大部分都對記憶體管理做好了封裝,一般的開發者根本都接觸不到記憶體的底層操作,更何況現在各種優秀的開源組件應用越來越多,例如mysql、redis等,這些甚至都不需要大家動手開發,直接拿來用就好了,所以有些同學也會覺得作為應用層開發的同學沒有學習的必要去學習底層,
但我想通過本文的實際案例告訴大家,哪怕不直接接觸記憶體底層操作,就只是用一些開源的工具,如果你能理解底層的作業原理,你也能夠用到極致,
用戶訪問歷史讀寫需求
假如現在有這樣一個業務需求,用戶每次重繪都需要獲得要消費的新資料,但是不能和之前訪問過的歷史重復,你可以把它和你經常在用的今日頭條之類的資訊流app聯系起來,每次都要看到新的新聞,但是你肯定不想看到過去已經看過的文章, 這樣在功能實作的時候,就必要保存用戶的訪問歷史,當用戶再來重繪的時候,首先得獲取用戶的歷史記錄,要保證推給用戶的資料和之前的不重復,當推薦完成的時候,也需要把這次新推薦過的資料id記錄到歷史里,
為了適當降低實作復雜度,我們可以規定每個用戶只要不和過去的一萬條記錄重復就可以了,這樣每個用戶最多只需要保存一萬條歷史id,如果存滿了就把最早的歷史記錄擠掉,我們進一步具體化一下這個需求的幾個關鍵點:
- 每個資料id是一個int整數來表示
- 每個用戶要保存1萬條id
- 每次用戶重繪開始的時候需要將這1萬條歷史全部讀取出來過濾一遍
- 每次用戶重繪結束的時候需要將新訪問過的10條寫入一遍,如果超過1萬需將最早的記錄擠掉
可見,每次用戶訪問的時候,會涉及到一個1萬規模的資料集上的一次讀取和一次寫入操作,
好了,需求描述完了,我們怎么樣進行我們的技術方案的設計呢?相信你也能想到很多實作方案,我們今天來對比兩個基于Redis下的存盤方案在性能方面的優劣,
方案一:用Redis的list來存盤
首先能想到的第一個辦法就是用Redis的List來保存,因為這個資料結構設計的太適合上面的場景了,
List下的lrange命令可以實作一次性讀取用戶的所有資料id的需求,
$redis->lrange('TEST_KEY', 0,9999);
lpush命令可以實作新的資料id的寫入,ltrim可以保證將用戶的記錄數量不超過1萬條,
$redis->lpush('TEST_KEY', 1,2,3,4,5,6,7,8,9,10);
$redis->ltrim('TEST_KEY', 0,9999);
我們準備一個用戶,提前存好一萬條id,寫入的時候每次只寫入10條新的id,讀取的時候通過lrange一次全部讀取出來,進行一下性能耗時測驗,結果如下,
Write repeats:10000 time consume:0.65939211845398 each 6.5939211845398E-5
Rrite repeats:10000 time consume:42.383342027664 each 0.0042383342027664
方案二:用Redis的string來存盤
我能想到的另外一個技術方案就是直接用String來存,我們可以把1萬個int表示的資料id拼接成一個字串,用一個特殊的字符把他們分割開,例如:"100000_100001_10002"這種, 存盤的時候,拼接一下,然后把這個大字串寫到Redis里,讀取的時候,把大字串整體讀取出來,然后再用字符切割成陣列來使用,
由于用string存盤的時候,保存前多了一個拼接字串的操作,讀取后多了一步將字串分割成陣列的操作,在測驗string方案的時候,為了公平起見,我們把需要把這兩步的開銷也考慮進來,
核心代碼如下:
$userItems = array(......);
//寫入
for($i=0; $i<$repeats; $i++){
$redis->set('TEST_KEY', implode('_', $userItems));
}
//讀取
for($i=0; $i<10000; $i++){
$items = explode("_", $redis->get('TEST_KEY'));
}
耗時測驗結果如下
Write repeats:10000 time consume:6.4061808586121 each 0.00064061808586121
Read repeats:10000 time consume:4.9698271751404 each 0.00049698271751404
結論
我們再直觀對比下兩個技術方案的性能資料,
| 寫入耗時 | 讀取耗時 | 總耗時 | |
|---|---|---|---|
| list | 0.066ms | 4.238ms | 4.304ms |
| string | 0.640ms | 0.496ms | 1.136ms |
基于list的方案里,寫入速度非常快,只需要0.066ms,因為僅僅只需要寫入新添加的10條記錄就可以了,再加一次鏈表的截斷操作,但是讀取性能可就要慢很多了,超過了4ms,原因之一是因為讀取需要整體遍歷,但其實還有第二個原因,我們本案例中的資料量過大,所以Redis在內部實際上是用雙端鏈表來實作的,.
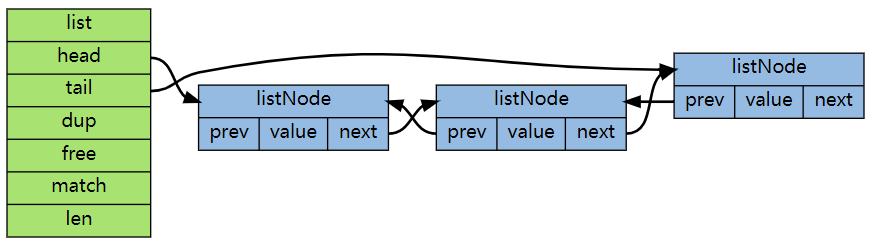
通過上圖你可能看出來,鏈表是通過指標串起來的,大量的node之間極大可能是隨機地分布在記憶體的各個位置上,這樣你遍歷整個鏈表的時候,實際上大概率會導致記憶體的隨機模式下作業,
基于string方案在寫入的時候耗時比list要高,因為每次都得需要將1萬條全部寫入一遍,但是讀取性能卻比list高了10倍,總體上耗時加起來大約只有方案一的1/4左右,為什么?我們再來看下redis string資料結構的記憶體布局
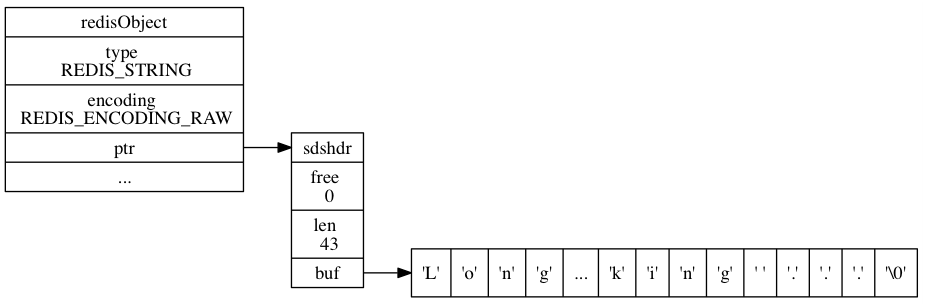
可見,如果用string來存盤的話,不管用戶的資料id有多少,訪問將全部都是順序IO,順序IO的好處有兩點:
- 1.一記憶體的順序IO的耗時大約只是隨機IO的1/3-1/4左右,
- 2.對于讀取來說,順序訪問將極大地提升CPU的L1、L2、L3的cache命中率
所以如果你深入了記憶體的作業原理,哪怕你不能直接去操作記憶體,即使只是用一些開源的軟體,你也能夠將它的性能發揮到極致~

開發內功修煉之記憶體篇專輯:
- 1.帶你深入理解記憶體對齊最底層原理
- 2.記憶體隨機也比順序訪問慢,帶你深入理解記憶體IO程序
- 3.從DDR到DDR4,記憶體核心頻率其實基本上就沒太大的進步
- 4.實際測驗記憶體在順序IO和隨機IO時的訪問延時差異
- 5.揭穿記憶體廠家“謊言”,實測記憶體帶寬真實表現
- 6.NUMA架構下的記憶體訪問延遲區別!
- 7.PHP7記憶體性能優化的思想精髓
- 8.一次記憶體性能提升的專案實踐
- 9.挑戰Redis單實體記憶體最大極限,“遭遇”NUMA陷阱!
我的公眾號是「開發內功修煉」,在這里我不是單純介紹技術理論,也不只介紹實踐經驗,而是把理論與實踐結合起來,用實踐加深對理論的理解、用理論提高你的技術實踐能力,歡迎你來關注我的公眾號,也請分享給你的好友~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/200872.html
標籤:其他
上一篇:PHP7記憶體性能優化的思想精髓