本文學習 Golang 的 Map 資料結構,以及map buckets 的資料組織結構,
hash 表是什么
從大學的課本里面,我們學到:hash 表其實就是將key 通過hash演算法映射到陣列的某個位置,然后把對應的val存放起來,
如果出現了hash沖突(也就是說,不同的key被映射到了相同的位置上時),就需要解決hash沖突,解決hash沖突的方法還是比較多的,比如說開放定址法,再哈希法,鏈地址法,公共溢位區等(復習下大學的基本知識),
其中鏈地址法比較常見,下面是一個鏈地址法的常見模式:
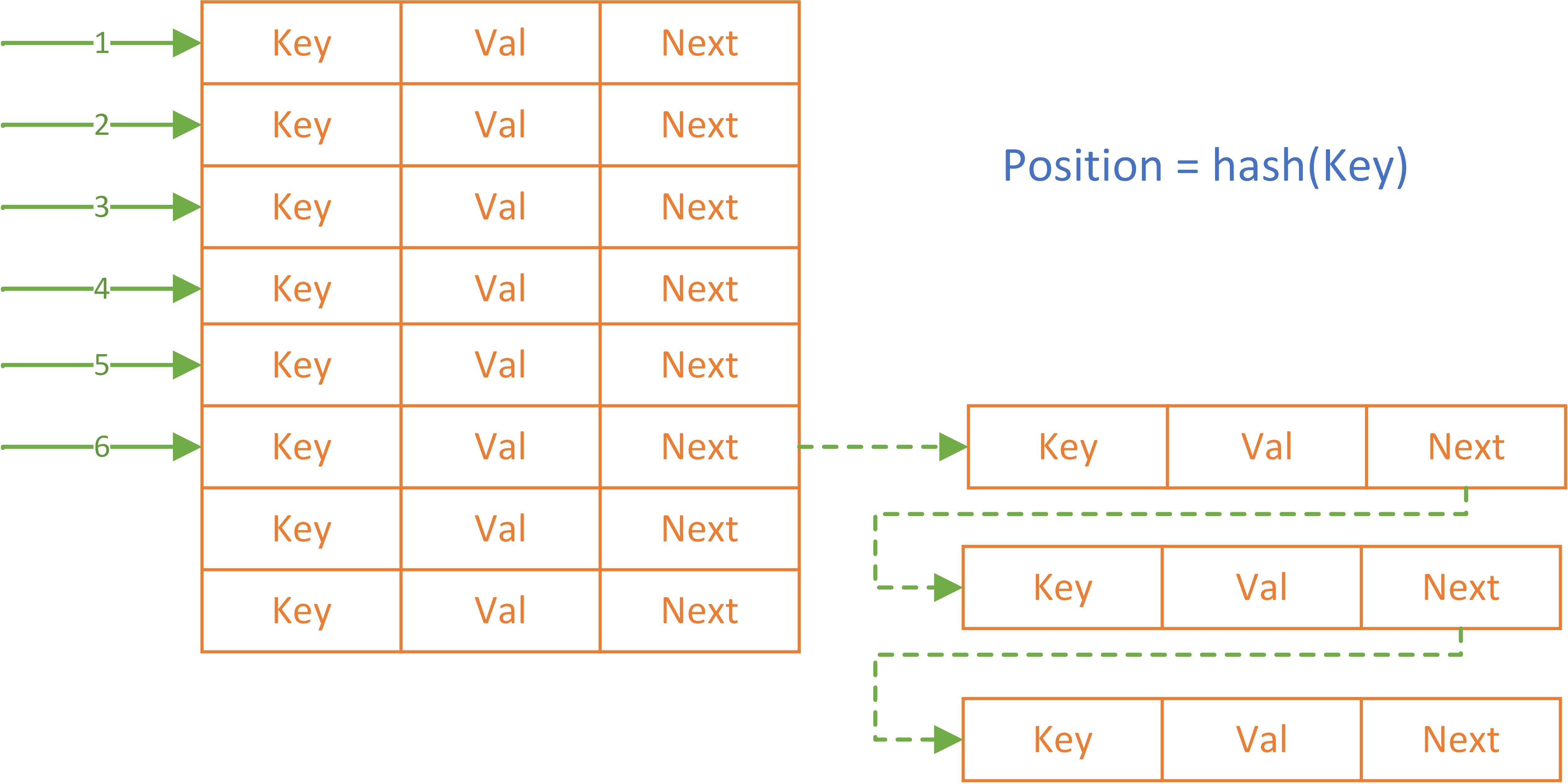
Position 指通過Key 計算出的陣列偏移量,例如當 Position = 6 的位置已經填滿KV后,再次插入一條相同Position的資料將通過鏈表的方式插入到該條位置之后,
在php的Array 中是這么實作的,golang中也基本是這么實作,下面我們學習下Golang中map的實作,
Golang Map 實作的資料結構
Golang的map中,首先把kv 分在了N個桶中,每個桶中的資料有8條(bucketCnt),如果一個桶滿了(overflow),也會采用鏈地址法解決hash 的沖突,
下面是定義一個hashmap的結構體:
type hmap struct {
// 長度
count int
// map 的標識, 下方做了定義
flags uint8
// 實際buckets 的長度為 2 ^ B
B uint8
// 從bucket中溢位的數量,(存在extra 里面)
noverflow uint16
// hash 種子,做key 哈希的時候會用到
hash0 uint32
// 存盤 buckets 的地方
buckets unsafe.Pointer
// 遷移時oldbuckets中存放部分buckets 的資料
oldbuckets unsafe.Pointer
// 遷移的數量
nevacuate uintptr
// 一些額外的欄位,在做溢位處理以及資料增長的時候會用到
extra *mapextra
}
const (
// 有一個迭代器在使用buckets
iterator = 1
// 有一個迭代器在使用oldbuckets
oldIterator = 2
// 并發寫,通過這個標識報panic
hashWriting = 4
sameSizeGrow = 8
)
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
type bmap struct {
tophash [bucketCnt]uint8
}
表中除了對基本的hash資料結構做了定義外,還對資料遷移、擴容等操作做了定義,這里我們可以忽略,等學習到時我們再深入了解,
深入 桶串列 (buckets)
buckets 欄位中是存盤桶資料的地方,正常會一次申請至少2^N長度的陣列,陣列中每個元素就是一個桶,N 就是結構體中的B,這里面要注意以下幾點:
- 為啥是2的冪次方 為了做完hash后,通過掩碼的方式取到陣列的偏移量, 省掉了不必要的計算,
- B 這個數是怎么確定的 這個和我們map中要存放的資料量是有很大關系的,我們在創建map的時候來詳述,
- bucket 的偏移是怎么計算的 hash 方法有多個,在 runtime/alg.go 里面定義了,不同的型別用不同的hash演算法,算出來是一個uint32的一個hash 碼,通過和B取掩碼,就找到了bucket的偏移了,下面是取對應bucket的例子:
// 根據key的型別取相應的hash演算法
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
// 根據B拿到一個掩碼
m := bucketMask(h.B)
// 通過掩碼以及hash指,計算偏移得到一個bucket
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
深入 桶 (bucket)
一個桶的示意圖如下:
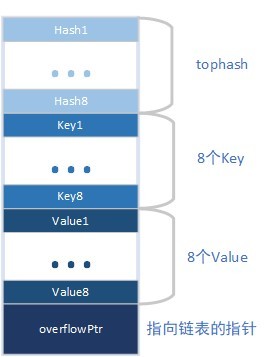
每個桶里面,可以放8個k,8個v,還有一個overflow指標(就是上面的next),用來指向下一個bucket 的地址,在每個bucket的頭部,還會放置一個tophash,也就是bmap 結構體,這個陣列里面存放的是key的hash值,用來對比我們key生成的hash和存出的hash是否一致(當然除了這個還有其他的用途,后面講資料訪問的時候會講到), tophash中的資料,是從計算的hash值里面截取的,獲取bucket 是用的低bit位的hash,tophash 使用的是高bit位的hash值(8位)
- 為啥bucket 一次要存8個kv,而不是一個kv放一個bucket,然后鏈地址法做處理就OK了 據我分析,有幾點原因: a, 一次分配8個kv的空間,可以減少記憶體的分配頻次; b,減少了overflow指標的記憶體占用,比如說8個kv,采用一個一個存盤的話,需要8 * 8B (64位機) = 64B的資料存下一個的地址,而采用go實作的這種方式,只需要 8B + 8B (bmap的大小) = 16B 的資料就可以了,
- 為啥需要用tophash 一般的hash 實作邏輯是直接和key比較,如果比較成功,這找到相應key的資料,但是這里用到了tophash,好處是可以減少key的比較成本(畢竟key 不一定都是整數形式存在的)
- 為啥是8個 8 * 8B = 64B 整好是64位機的一個最小尋址空間,不過可以通過修改原始碼自定義吧,
- 為什么key 和val 要分開放 這個也比較好理解,key 和val 都是用戶可以自定義的,如果key是定長的(比如是數字,或者 指標之類的,大概率是這樣,)記憶體是比較整齊的,利于尋址吧,
技術總結
golang 實作的map比樸素的hashmap 在很多方面都有優化,
- 使用掩碼方式獲取偏移,減少判斷,
- bucket 存盤方式的優化,
- 通過tophash 先進行一次比較,減少key 比較的成本,
- 當然,有一點是不太明白的,為啥 overflow 指標要放在 kv 后面? 放在tophash 之后的位置豈不是更完美?
今天的作業就交完了,下一篇將學習golang map的資料初始化實作,
參考
[1] 深入理解 Go map:初始化和訪問
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/20851.html
標籤:Go
上一篇:arcgis矢量化
下一篇:Golang Map 實作(二)