python資料分析期末復習歸納(更新中)
文章目錄
- python資料分析期末復習歸納(更新中)
- 前言
- 一、python語言基礎
- 二、內建資料結構、函式、檔案(重點)
- 元組
- 串列
- 內建序列函式
- 字典
- 函式
- 三、Numpy基礎(重點)
- 四、pandas入門(重點)
- Series
- DataFrame
- 五、資料載入
- 六、資料清洗與準備
- 七、資料規整:連接、聯合與重塑
- 八、繪圖與可視化
- GOOD LUCK !
前言
可以通過《利用Python進行資料分析》的GitHub倉庫獲得本書的資料檔案和相關材料,
鏈接:GitHub倉庫地址
提示:以下是本篇文章正文內容
一、python語言基礎
分值:1~2分
- python使用縮進來組織代碼,而不是其他語言比如R、C++、java和Perl那樣用大括號,
- 你見到的python陳述句都不是以分號結尾,而分號也是可以用于在一行內將多條陳述句進行分隔:
a = 5;b = 6;c = 7
- python語言的一個重要特征就是物件模型的一致性,每一個數值、字串、資料結構、函式、類、模塊以及所有存在于python解釋器中的事物都是python的物件,每一個物件都會關聯到一種資料型別和內部資料,
- 檢查兩個參考是否指向同一個物件可以用 is 關鍵字,is not 在你檢查兩個關鍵字是不是相同物件時也是有效的,
In []: a = [1, 2, 3]
In []: b = a
In []: c = list(a)
In []: a is b
Out[]: True
In []: a is not c
Out[]: True
'''因為list函式總是創建一個新的Python串列(即一份拷貝),我們可以確定c與a是不同的,
is和==是不同的,因為在這種情況下我們可以得到:'''
In []: a == c
Out[]: True
#is 和 is not的常用之處是檢查一個變數是否為None,因為None只有一個實體:
In []: a = None
In []: a is None
Out[]: True
- 可變物件與不可變物件,Python中的大部分物件,例如串列、字典、Numpy陣列都是可變物件,大多數用戶定義的型別(類)也是可變的,可變物件中包含的物件和值是可以被修改的,還有其他的物件是不可變的,比如字串、元組,
- 數值型別,基礎的python數字型別就是int 和 float,int 可以存盤任意大小的數字,float表示浮點數,每一個浮點數都是雙精度64位數值,
- 字串,字串是Unicode字符的序列,因此可以被看作是除了串列和元組外的一種序列,
In []: s = 'python'
In []: list(s)
Out[]: ['p','y','t','h','o','n']
In []: s[:3]
Out[]: 'pyt'
二、內建資料結構、函式、檔案(重點)
元組
定義元組
In []: tup = 4,5,6
In []: tup
Out[]: (4, 5, 6)
使用tuple函式將任意序列或迭代器轉換為元組:
In []: tuple([4, 0, 2])
Out[]: (4, 0, 2)
In []: tup = tuple('string')
In []: tup
Out[]: ('s', 't', 'r', 'i', 'n', 'g')
In []: (4,None,'foo')+(6,0)+('bar',)
Out[]: (4, None, 'foo', 6, 0, 'bar')
In []: ('foo','bar')*4
Out[]: ('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar')
串列
創建串列
In []: alist = []
In []: list(range(10))
Out[]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In []: tup
Out[]: ('foo', 'bar', 'baz')
In []: b_list(tup)
In []: b_list
Out[]: ['foo', 'bar', 'baz']
In []: b_list.append('dasf')
In []: b_list
Out[]: ['foo', 'bar', 'baz', 'dasf']
insert()、pop()、remove()方法
In []: b_list.insert(2,'hug')
In []: b_list
Out[]: ['foo', 'bar', 'hug', 'baz', 'dasf']
In []: b_list.pop(3)
Out[]: 'baz'
In []: b_list
Out[]: ['foo', 'bar', 'hug', 'dasf']
In []: b_list.remove('dasf')
In []: b_list
Out[]: ['foo', 'bar', 'hug']
連接兩個串列
In []: ['hj',6,(2,3)]+['re',7]
Out[]: ['hj', 6, (2, 3), 're', 7]
#extend()方法消耗更小
In []: x=['hj',6,(2,3)]
In []: x.extend(['re',7])
In []: x
Out[]: ['hj', 6, (2, 3), 're', 7]
排序
In []: a=[4,6,1,9,2,8]
In []: a.sort()
In []: a
Out[]: [1, 2, 4, 6, 8, 9]
In []: a = [4, 6, 1, 9, 2, 8]
In []: sorted(a)
Out[]: [1, 2, 4, 6, 8, 9]
In []: a
Out[]: [4, 6, 1, 9, 2, 8]
In []: b=['df','rewg','fsdvsfdvsdv','d','gfg']
In []: b.sort(key=len)
In []: b
Out[]: ['d', 'df', 'gfg', 'rewg', 'fsdvsfdvsdv']
切片
In []: seq
Out[]: [7, 2, 3, 6, 3, 5, 6, 0, 1]
In []: seq[4:3]
Out[]: []
In []: seq[3:4]
Out[]: [6]
In [35]: seq[3:4]=[6,3]
In []: seq
Out[]: [7, 2, 3, 6, 3, 3, 5, 6, 0, 1]
In []: seq[-6:-2]
Out[]: [3, 3, 5, 6]
內建序列函式
zip可以將串列、元組或者其他序列的元素配對,新建一個元組構成的串列
In []: seq1 = ['foo', 'bar', 'baz']
In []: seq2 = ['one', 'two', 'three']
In []: zipped = zip(seq1, seq2)
In []: list(zipped)
Out[]: [('foo', 'one'), ('bar', 'two'), ('baz', 'three')]
reversed()將序列的元素倒序排列
In []: list(reversed(range(10)))
Out[]: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
字典
創建字典
In []: d1={'a':'some value','b':[1,2,3,4]}
In []: d1
Out[]: {'a': 'some value', 'b': [1, 2, 3, 4]}
#向字典中添加元素
In []: d1[7]=0
In []: d1
Out[]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 0}
In []: d1[4] = 'banace'
In []: d1
Out[]: {'a': 'some value', 'b': [1, 2, 3, 4], 7: 0, 4: 'banace'}
In []: 'b' in d1
Out[]: True
In []: list(d1.keys())
Out[]: ['a', 'b', 7, 4]
In []: list(d1.values())
Out[]: ['some value', [1, 2, 3, 4], 0, 'banace']
使用update()方法將兩個字典合并
In [55]: d1.update({'r':'goo','h':'integer'})
In [56]: d1
Out[56]:
{'a': 'some value',
'b': [1, 2, 3, 4],
7: 0,
4: 'banace',
'r': 'goo',
'h': 'integer'}
從序列生成字典
In []: mapping={}
In []: mapping = dict(zip(range(5),reversed(range(5))))
In []: mapping
Out[]: {0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
有效的字典型別
盡管字典的值可以是任何Python物件,但鍵必須是不可變的物件,比如標量型別(整數、浮點數、字串)或元組(且元組內物件也必須是不可變物件)
In []: x={[3,4]:54} #key值為一個可變物件串列,報錯 unhashable
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-61-abe1ff6f266b> in <module>
----> 1 x={[3,4]:54}
TypeError: unhashable type: 'list'
函式
三、Numpy基礎(重點)
生成ndarray
In []: data2=[[4,5,2],[3,4,5]]
In []: arr1=np.array(data2)
In []: arr1
Out[]:
array([[4, 5, 2],
[3, 4, 5]])
In []: arr1.ndim
Out[]: 2
In []: arr1.shape
Out[]: (2, 3)
In []: arr1.dtype
Out[]: dtype('int32')
In []: np.zeros(10)
Out[]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In []: np.zeros((3,7))
Out[]:
array([[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.]])
In []: arr2=np.array([1,2,3],dtype=np.int64)
In []: arr2
Out[]: array([1, 2, 3], dtype=int64)
In []: arr2.dtype
Out[]: dtype('int64')
Numpy陣列算數
四、pandas入門(重點)
pandas采用了很多NumPy的代碼風格,但最大的不同在于pandas是用來處理表格型或異質型資料的,而NumPy則相反,它更適合處理同質型的數值類陣列資料,
Series
In []: obj = pd.Series([4, 7, -5, 3])
In []: obj
Out[]:
0 4
1 7
2 -5
3 3
dtype: int64
In []: obj.values
Out[]: array([ 4, 7, -5, 3], dtype=int64)
In []: obj.index #與range(4)類似
Out[]: RangeIndex(start=0, stop=4, step=1)
In []: obj2 = pd.Series([4, 7, -5, 3],index=['d','b','a','c'])
In []: obj2
Out[]:
d 4
b 7
a -5
c 3
dtype: int64
In []: obj2.index
Out[]: Index(['d', 'b', 'a', 'c'], dtype='object')
如果已經有資料包含在Python字典中,你可以使用字典生成一個Series:
In []: sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
In []: obj3=Series(sdata)
In []: obj3
Out[]:
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
DataFrame
#嵌套字典
In []: pop
Out[]: {'Nevada': {2001: 2.4, 2002: 2.9}, 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
In []: frame3=DataFrame(pop)
In []: frame3
Out[]:
Nevada Ohio
2001 2.4 1.7
2002 2.9 3.6
2000 NaN 1.5
轉置操作
In []: frame3.T
Out[]:
2001 2002 2000
Nevada 2.4 2.9 NaN
Ohio 1.7 3.6 1.5
生成時指定索引
In []: pd.DataFrame(pop,index=[2000,2001,2002])
Out[]:
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
DataFrame的values屬性
In []: frame3.values
Out[]:
array([[2.4, 1.7],
[2.9, 3.6],
[nan, 1.5]])
fill方法會把值前向填充
In []: obj3 = Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
In []: obj3.reindex(range(6), method='ffill')
Out[]:
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object
reindex()
In []: frame = DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'],
...: columns=['Ohio', 'Texas', 'California'])
In []: frame
Out[]:
Ohio Texas California
a 0 1 2
c 3 4 5
d 6 7 8
In []: frame2 = frame.reindex(['a', 'b', 'c', 'd'])
In []: frame2
Out[]:
Ohio Texas California
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0
In []: states = ['Texas', 'Utah', 'California']
In []: frame.reindex(columns=states)#使用column關鍵字重建索引
Out[]:
Texas Utah California
a 1 NaN 2
c 4 NaN 5
d 7 NaN 8
drop()
#Series中使用
In []: obj=pd.Series(np.arange(5.),index=['a','b','c','d','e'])
In []: obj
Out[]:
a 0.0
b 1.0
c 2.0
d 3.0
e 4.0
dtype: float64
In []: new_obj=obj.drop(['a','c'])
In []: new_obj
Out[]:
b 1.0
d 3.0
e 4.0
dtype: float64
#DataFrame中使用
In []: data = DataFrame(np.arange(16).reshape((4, 4)),^M
...: index=['Ohio', 'Colorado', 'Utah', 'New York'],^M
...: columns=['one', 'two', 'three', 'four'])
In []: data
Out[]:
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
In []: data.drop(['Colorado', 'Ohio'])
Out[]:
one two three four
Utah 8 9 10 11
New York 12 13 14 15
In []: data.drop(['two','four'],axis=1)
Out[]:
one three
Ohio 0 2
Colorado 4 6
Utah 8 10
New York 12 14
普通的python切片是不包含尾部的,Series的切片與之不同
In []: obj[2:4] #普通切片
Out[]:
c 2.0
d 3.0
dtype: float64
In []: obj['b':'d'] #按索引切片
Out[]:
b 1.0
c 2.0
d 3.0
dtype: float64
In []: data
Out[]:
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
In []: data['two']
Out[]:
Ohio 1
Colorado 5
Utah 9
New York 13
Name: two, dtype: int32
In []: data[['three','one']]
Out[]:
three one
Ohio 2 0
Colorado 6 4
Utah 10 8
New York 14 12
In []: data[:2]
Out[]:
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
使用軸標簽(loc)和整數標簽(iloc)選擇資料
In []: data.loc['Colorado', ['two', 'three']]
Out[]:
two 5
three 6
Name: Colorado, dtype: int32
In []: data.iloc[1,[1,2]]
Out[]:
two 5
three 6
Name: Colorado, dtype: int32
In []: data.iloc[[1,2], [3, 0, 1]]
Out[]:
four one two
Colorado 7 4 5
Utah 11 8 9
In []: ser[:2]
Out[]:
0 0.0
1 1.0
dtype: float64
In []: ser.iloc[:2]
Out[]:
0 0.0
1 1.0
dtype: float64
In []: ser.loc[:2]
Out[]:
0 0.0
1 1.0
2 2.0
dtype: float64
了解廣播機制
#NumPy
In []: arr=np.arange(12.).reshape((3,4))
In []: arr
Out[]:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
In []: arr[0]
Out[]: array([0., 1., 2., 3.])
In []: arr-arr[0]
Out[]:
array([[0., 0., 0., 0.],
[4., 4., 4., 4.],
[8., 8., 8., 8.]])
#DataFrame與Series之間也是類似的
In []: frame = DataFrame(np.arange(12.).reshape((4, 3)), columns=list('bde'),
...: index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In []: series=frame.iloc[0]
In []: frame
Out[]:
b d e
Utah 0.0 1.0 2.0
Ohio 3.0 4.0 5.0
Texas 6.0 7.0 8.0
Oregon 9.0 10.0 11.0
In []: series
Out[]:
b 0.0
d 1.0
e 2.0
Name: Utah, dtype: float64
In []: frame - series
Out[]:
b d e
Utah 0.0 0.0 0.0
Ohio 3.0 3.0 3.0
Texas 6.0 6.0 6.0
Oregon 9.0 9.0 9.0
五、資料載入
考察點:資料讀入與寫入
#資料讀入
In []: !cat examples/ex1.csv
In []: df = pd.read_csv('examples/ex1.csv')
In []: pd.read_table('examples/ex1.csv', sep=',') #指定分隔符
In []: !cat examples/csv_mindex.csv
In []: parsed = pd.read_csv('examples/csv_mindex.csv',
index_col=['key1', 'key2'])
#資料寫入
In []: data = pd.read_csv('examples/ex5.csv')
In []: data
In []: data.to_csv('examples/out.csv')
In []: !cat examples/out.csv
六、資料清洗與準備
分值:6分
處理缺失值
In [56]: string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
In []: string_data
Out[]:
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
In []: string_data.isnull()
Out[]:
0 False
1 False
2 True
3 False
dtype: bool
In []: from numpy import nan as NA
In []: data = pd.Series([1, NA, 3.5, NA, 7])
In []: data.dropna()
Out[]:
0 1.0
2 3.5
4 7.0
dtype: float64
In []: data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],
...: [NA, NA, NA], [NA, 6.5, 3.]])
In []: cleaned = data.dropna()
In []: data
Out[]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
In []: cleaned
Out[]:
0 1 2
0 1.0 6.5 3.0
#傳入how='all'時,將洗掉所有值均為NA的行
In []: data.dropna(how='all')
Out[]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
In []: data[4]=NA
In []: data
Out[]:
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
In []: data.dropna(axis=1,how='all')
Out[]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
使用fillna()方法補全缺失值
In []: df
Out[]:
0 1 2
0 0.291028 NaN NaN
1 -0.247507 NaN NaN
2 -0.846066 NaN 1.815868
3 -2.644441 NaN -1.593109
4 0.687419 -0.576368 -1.207267
5 1.028088 -0.199093 1.090297
6 -1.356587 2.840271 0.588919
In []: df.fillna(0)
Out[]:
0 1 2
0 0.291028 0.000000 0.000000
1 -0.247507 0.000000 0.000000
2 -0.846066 0.000000 1.815868
3 -2.644441 0.000000 -1.593109
4 0.687419 -0.576368 -1.207267
5 1.028088 -0.199093 1.090297
6 -1.356587 2.840271 0.588919
#可以使用字典,為不同列設定不同的填充值
In []: df.fillna({1: 0.5, 2: 0})
Out[]:
0 1 2
0 0.291028 0.500000 0.000000
1 -0.247507 0.500000 0.000000
2 -0.846066 0.500000 1.815868
3 -2.644441 0.500000 -1.593109
4 0.687419 -0.576368 -1.207267
5 1.028088 -0.199093 1.090297
6 -1.356587 2.840271 0.588919
In []: df
Out[]:
0 1 2
0 -0.749045 0.120431 -0.524772
1 -1.170878 0.449045 -0.009419
2 -1.522980 NaN -0.932252
3 0.245718 NaN -0.584712
4 -0.611673 NaN NaN
5 0.205112 NaN NaN
In []: df.fillna(method='ffill')
Out[]:
0 1 2
0 -0.749045 0.120431 -0.524772
1 -1.170878 0.449045 -0.009419
2 -1.522980 0.449045 -0.932252
3 0.245718 0.449045 -0.584712
4 -0.611673 0.449045 -0.584712
5 0.205112 0.449045 -0.584712
In []: df.fillna(method='ffill', limit=1) #limit引數表示處理范圍
Out[]:
0 1 2
0 -0.749045 0.120431 -0.524772
1 -1.170878 0.449045 -0.009419
2 -1.522980 0.449045 -0.932252
3 0.245718 NaN -0.584712
4 -0.611673 NaN -0.584712
5 0.205112 NaN NaN
#替代值
In []: data
Out[]:
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64
In []: data.replace(-999,NA)
Out[]:
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
In []: data.replace([-999,-1000],[NA,0])
Out[]:
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
#引數也可通過字典傳遞
In []: data.replace({-999:NA,-1000:0})
Out[]:
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
七、資料規整:連接、聯合與重塑
分值:6分
分層索引
In []: data = pd.Series(np.random.randn(9),^M
...: index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],^M
...: [1, 2, 3, 1, 3, 1, 2, 2, 3]])
In []: data
Out[]:
a 1 -1.218316
2 -0.331598
3 1.511461
b 1 0.443087
3 0.080628
c 1 0.088635
2 -2.549623
d 2 -0.793741
3 -0.266901
dtype: float64
#使用DataFrame的列進行索引
In [109]: frame = pd.DataFrame(np.arange(12).reshape((4, 3)),^M
...: index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
...: columns=[['Ohio', 'Ohio', 'Colorado'],
...: ['Green', 'Red', 'Green']])
In []: frame
Out[]:
Ohio Colorado
Green Red Green
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
In []: frame.columns.names=['state','color']
In []: frame
Out[]:
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
In []: frame['Ohio']
Out[]:
color Green Red
key1 key2
a 1 0 1
2 3 4
b 1 6 7
2 9 10
重排序與層級排序
In []: frame.swaplevel('key1', 'key2')
Out[]:
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2
2 a 3 4 5
1 b 6 7 8
2 b 9 10 11
In []: frame.sort_index(level=1)
Out[]:
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
b 1 6 7 8
a 2 3 4 5
b 2 9 10 11
In []: frame.swaplevel(0, 1).sort_index(level=0)
Out[]:
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2
b 6 7 8
2 a 3 4 5
b 9 10 11
使用DataFrame的列進行索引
In []: frame = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),
...: 'c': ['one', 'one', 'one', 'two', 'two',
...: 'two', 'two'],
...: 'd': [0, 1, 2, 0, 1, 2, 3]})
In []: frame
Out[]:
a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3
In []: frame2=frame.set_index(['c','d'])
In []: frame2
Out[]:
a b
c d
one 0 0 7
1 1 6
2 2 5
two 0 3 4
1 4 3
2 5 2
3 6 1
#默認情況下,設定為索引的列會從DateFrame中移除,但是也可以留在DataFrame中
In []: frame2=frame.set_index(['c','d'],drop=False)
In []: frame2
Out[]:
a b c d
c d
one 0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
two 0 3 4 two 0
1 4 3 two 1
2 5 2 two 2
3 6 1 two 3
八、繪圖與可視化
分值:6~10分
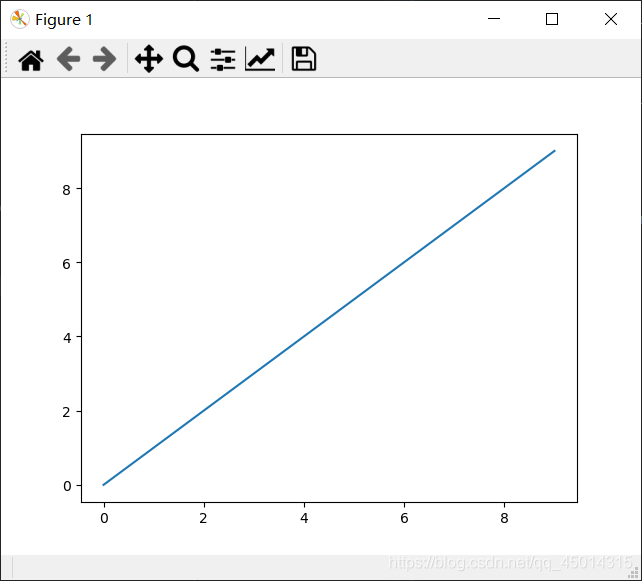
In []: import matplotlib.pyplot as plt
In []: import numpy as np
In []: data=np.arange(10)
In []: data
Out[]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In []: plt.plot(data)
Out[]: [<matplotlib.lines.Line2D at 0x283375ca160>]
GOOD LUCK !
author : Haoyu
school : CSUFT
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/212869.html
標籤:python