事故時間特征序列分析匯總
- 引言
- 1 資料讀取和時間特征轉化
- 1.1 先將時間的欄位組合成為統一的形式
- 1.2 再將標準形式的日期欄位轉化為datetime
- 1.3 提取年、月、日欄位資訊
- 1.4 查看日期是在第幾周
- 1.5 查看日期是在周幾
- 2 特定欄位的資料提取
- 2.1 字串extract方法使用
- 2.2 apply/map結合正則表達使用
- 3 單欄位多特征進行計數統計
- 3.1 將所有的特征都添加到串列中,轉化為Series資料進行計數
- 3.2 使用字典計數的方式進行統計
- 3.3 使用pd.explode()方法提取多特征轉化為Series進行計數
- 4 繪制時間序列事故圖
- 4.1 按照年份進行繪制
- 4.2 按照季度進行繪制
- 4.3 按照月份進行繪制
- 4.4 按照小時進行繪制
手動反爬蟲: 原博地址
知識梳理不易,請尊重勞動成果,文章僅發布在CSDN網站上,在其他網站看到該博文均屬于未經作者授權的惡意爬取資訊
如若轉載,請標明出處,謝謝
引言
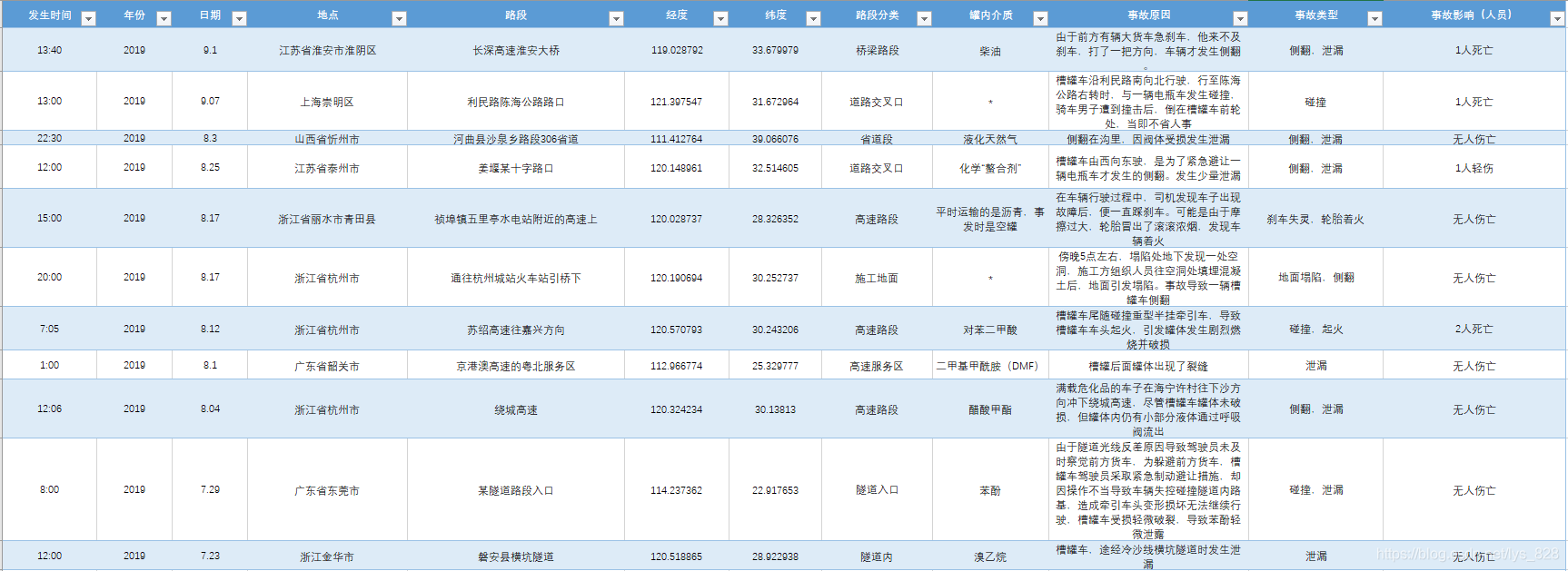
在進行實際的的業務處理程序中,常常會和時間特征打交道,這里就進行真實資料的的時間序列處理,并將整個業務的基本流程梳理一下,資料為2012-2019 年的槽罐車事故的統計資料,已上傳至資源(包含全部運行之后的ipynb檔案),內容樣式如下:
1 資料讀取和時間特征轉化
在進行資料匯入之前先加載常用的模塊,和設定繪制圖形的字體,然后再匯入要操作的資料,代碼如下
import warnings
warnings.filterwarnings('ignore')
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
data_load = pd.read_excel('2012-2019tank_data.xlsx')
data_load.head()
輸出結果為:
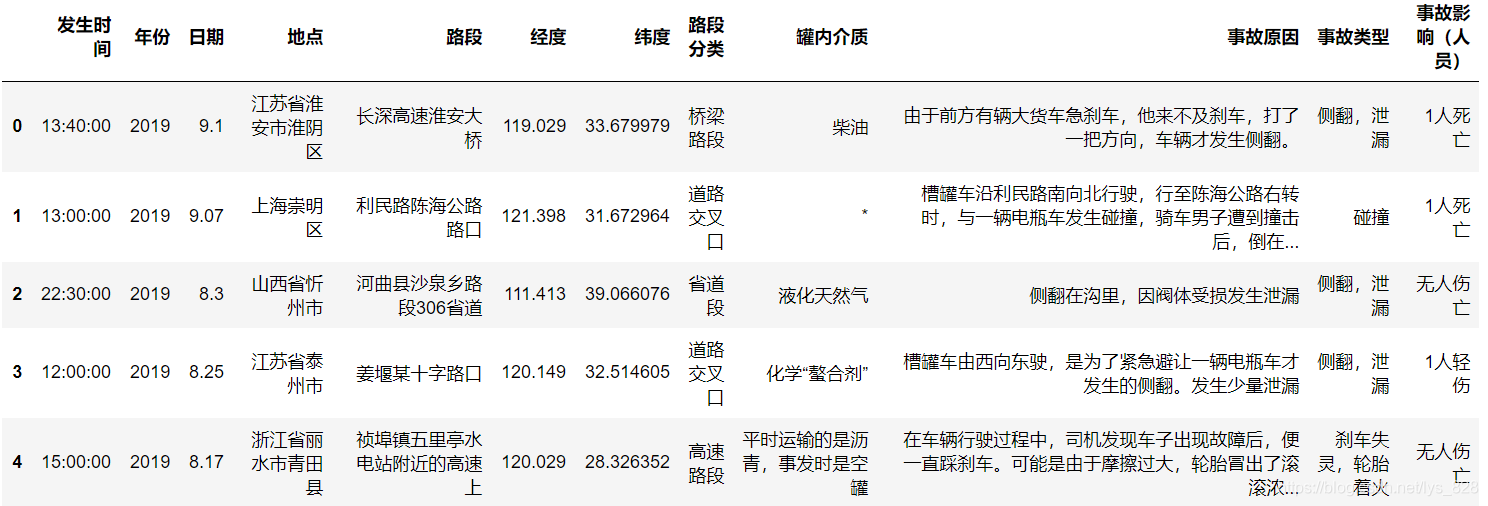
觀察前三列可以發現關于時間特征有年份、日期和時間,那么習慣的操作就是將默認讀取的“時間”資料轉化為datetime資料型別,方便提取具體的年、月、榷訓者進一步的提取事故時間所在一周第幾天,方便統計周末的事故情況
★★★ 處理方式:
統一的將時間的欄位轉化為‘xx-xx-xx’形式(‘年-月-日’),然后使用pd.to_datetime()方法轉化為datetime資料型別,比如這里的年份和日期進行組合(發生時間已經是具體的時間型別了,不需要轉化了)
1.1 先將時間的欄位組合成為統一的形式
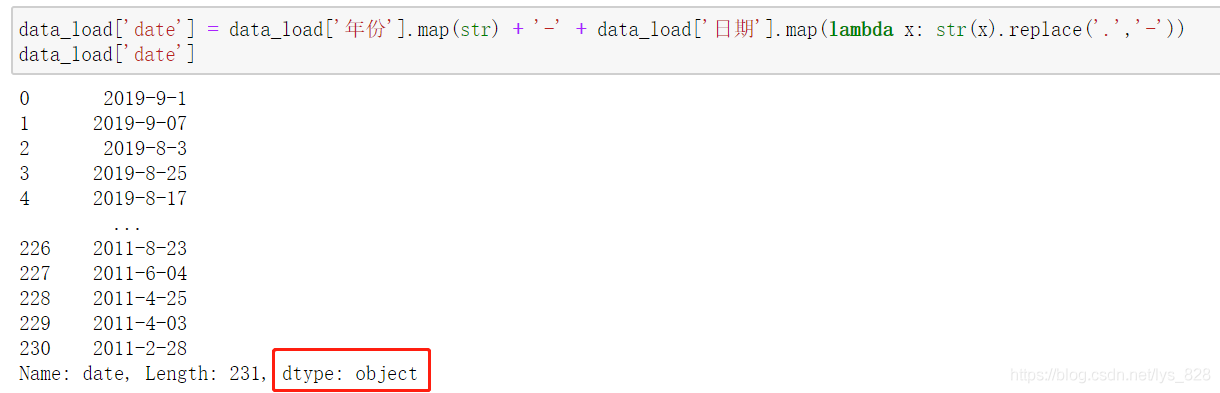
data_load['date'] = data_load['年份'].map(str) + '-' + data_load['日期'].map(lambda x: str(x).replace('.','-'))
data_load['date']
輸出結果為:(這里轉化為統一格式后,資料的型別是object)
1.2 再將標準形式的日期欄位轉化為datetime
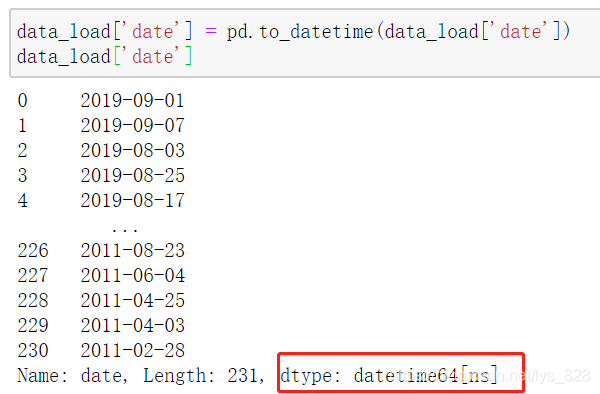
data_load['date'] = pd.to_datetime(data_load['date'])
data_load['date']
輸出結果為:(這里轉化為統一格式后,資料的型別就是目標型別datetime64)
1.3 提取年、月、日欄位資訊
由于經常和時間特征打交道,這里直接就封裝一個函式,只要把剛剛處理完畢的日期欄位傳遞到函式中,就可以獲得對應的年、月、日欄位資訊了,代碼如下
def get_year_month_day(df,time_col):
'''Extract the year, month, and day of the time field data'''
df[time_col] = pd.to_datetime(df[time_col])
df['year'] = df[time_col].dt.year
df['month'] = df[time_col].dt.month
df['day'] = df[time_col].dt.day
return df
其中第一個引數匯入的資料對應的DataFrame資料,第二個引數就是DataFrame資料里面的時間欄位,使用方式如下
df = get_year_month_day(data_load,'date')
df.head()
輸出結果為:(至此就完成了時間特征的提取)
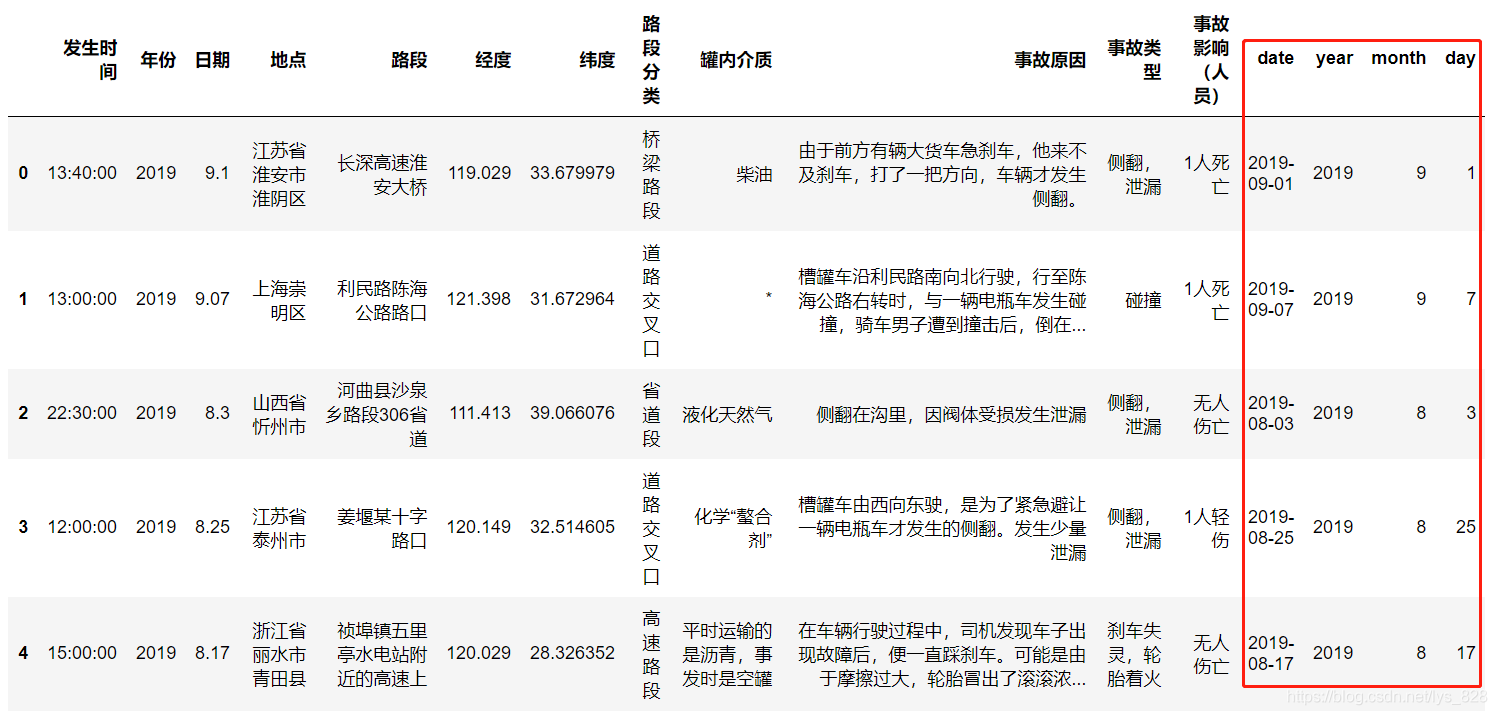
提取時間資訊的函式還可以自己根據需求進行添加,比如你要獲取所在日期所在的第幾周,或者是一周的第幾天等,如下
1.4 查看日期是在第幾周
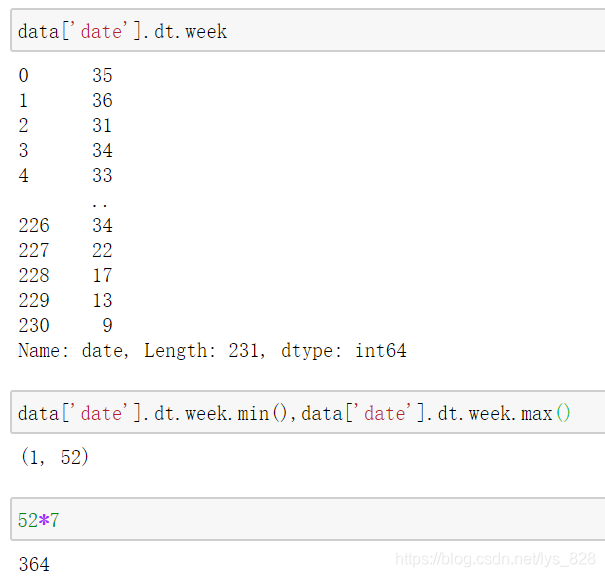
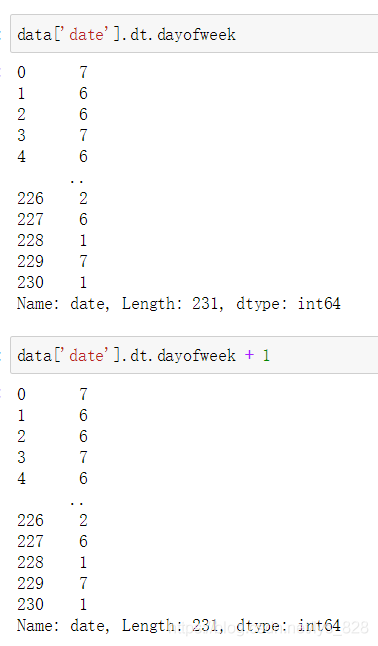
1.5 查看日期是在周幾
這里需要注意一下,回傳的結果是0-6之間的數字,為了和大家普遍的理解認知相符,建議對結果+1,這樣1就代表周一,7就代表周日了,方便理解,
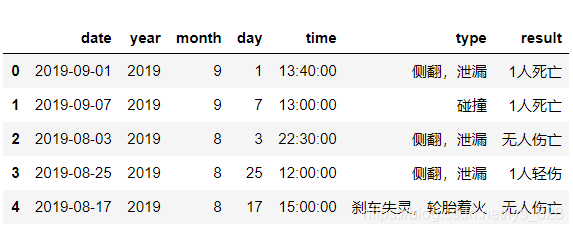
2 特定欄位的資料提取
提取需要的目標欄位進行分析,其余的資料就暫時不進行處理,習慣上會將所有的欄位重新使用英文來命令,方便之后的操作(不用再切換輸入法了)
df['time'] = df['發生時間']
df['type'] = df['事故型別']
df['result'] = df['事故影響(人員)']
data = df[['date','year','month','day','time','type','result']]
data.head()
輸出結果為:
2.1 字串extract方法使用
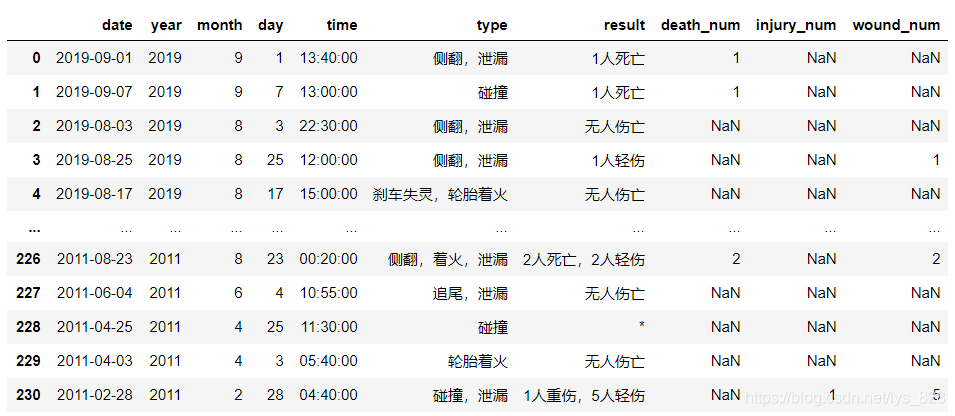
比如對于事故造成的影響,需要提取里面的死亡人數,重傷人數和輕傷人數,如果單純的使用excel表格處理,也是可以做的,但是作業量還是有點大,采用python操作就很簡單三行代碼搞定了,這一部分使用了正則運算式提取資料的方式,可以參考一下:正則運算式的分組及在pandas中的實用操作
data['death_num'] = data['result'].str.extract('(?P<death_num>\d+)人死亡')
data['injury_num'] = data['result'].str.extract('(?P<injury_num>\d+)人重傷')
data['wound_num'] = data['result'].str.extract('(?P<wound_num>\d+)人輕傷')
data
輸出結果為:(當然也可以自定一個函式,然后使用apply的方式進行資料提取)
2.2 apply/map結合正則表達使用
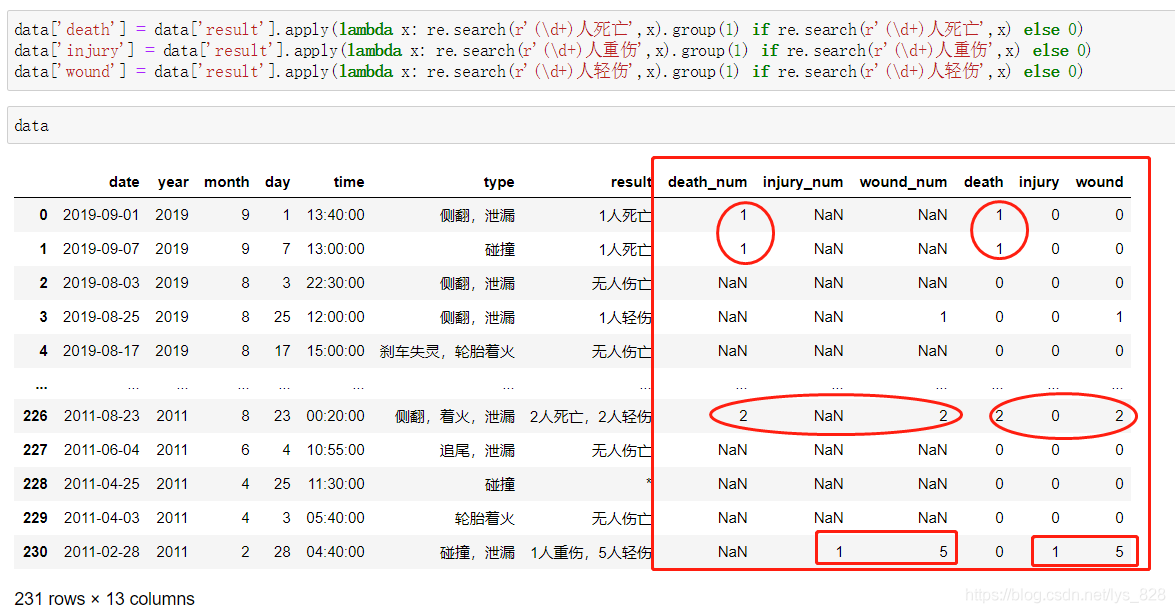
如果使用apply或者map的方式,代碼如下
data['death'] = data['result'].apply(lambda x: re.search(r'(\d+)人死亡',x).group(1) if re.search(r'(\d+)人死亡',x) else 0)
data['injury'] = data['result'].apply(lambda x: re.search(r'(\d+)人重傷',x).group(1) if re.search(r'(\d+)人重傷',x) else 0)
data['wound'] = data['result'].apply(lambda x: re.search(r'(\d+)人輕傷',x).group(1) if re.search(r'(\d+)人輕傷',x) else 0)
data
輸出結果如下:(使用apply)
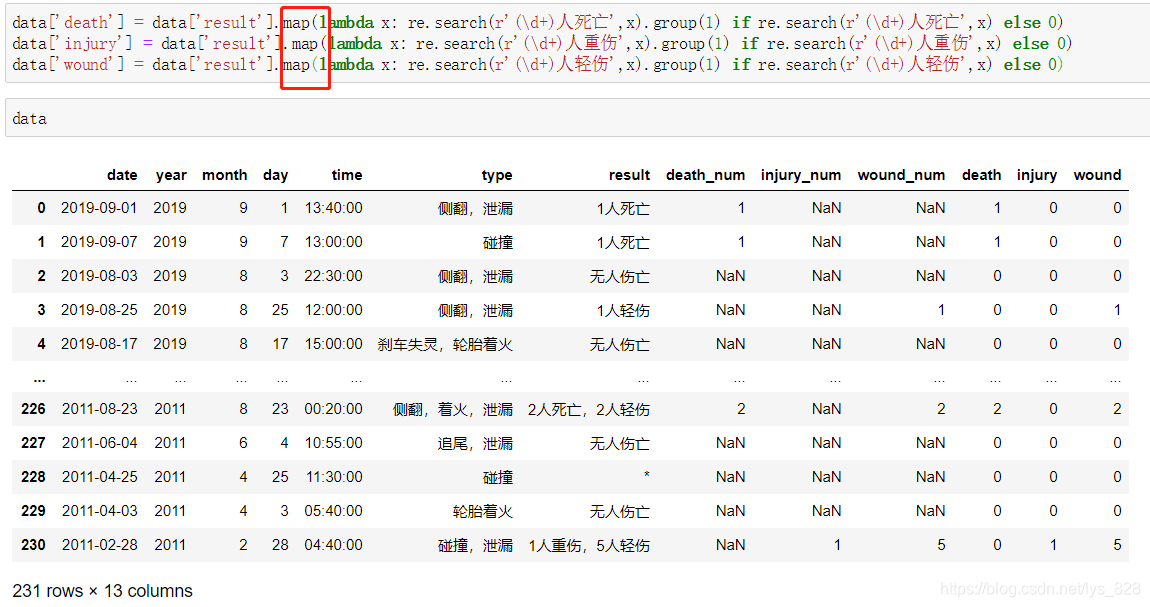
輸出結果如下:(使用map方法,個人感覺這兩種方法對我來說使用上沒有差別,選擇一種就可以了)
3 單欄位多特征進行計數統計
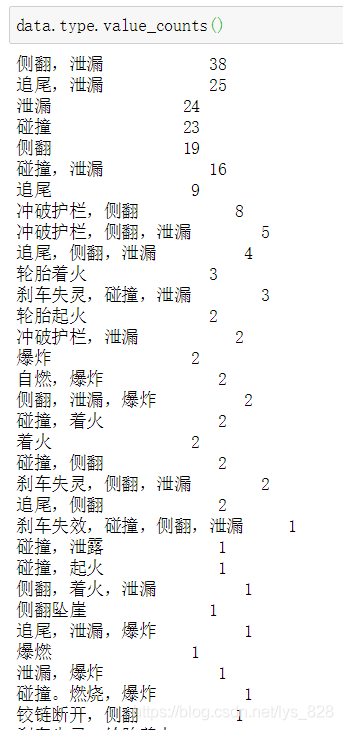
比如這里的type事故型別欄位,pandas里面有個value_counts方法計數,這個功能是很好用的,但是當單欄位中出現了多個特征的時候,這個方法不會默認給我們進行多特征的切分統計,示例如下
data.type.value_counts()
輸出結果為:(這里就會把單元格中的資料作為一次的統計標準,只要是出現全部一樣,就統計一次計數)
這種情況下直接進行value_counts()就沒有辦法滿足要求了, 因此需要對這個欄位的資料進行處理,處理的方式,有三種,但是根本的方式都是轉化為串列,然后再進行統計計數
3.1 將所有的特征都添加到串列中,轉化為Series資料進行計數
基本步驟是首先創建一個空串列保存資料,接著就是遍歷欄位中所有的內容,按照特定的字符進行split切分,將切分的結果再extend到空串列中儲存,最后把這個串列轉化為Series資料進行計數,
ls = []
for item in data.type:
ls.extend(item.split(','))
pd.Series(ls).value_counts()
輸出結果為:(可以發現基本上滿足要求,但是有一些噪音資料需要進一步處理,這種情況是沒有辦法避免的,因為資料都是人為上報的,多多少少會存在著手動錄入的錯誤,這里的泄露也是人為錄入的錯誤)

處理里面的噪音資料后再進行統計計數,代碼如下
ls = []
for item in data.type.str.replace(',',',').str.replace('露','漏'):
ls.extend(item.split(','))
pd.Series(ls).value_counts()
輸出結果為:(結果實作了單欄位多特征的統計計數,接下來直接就可以進行plot繪圖)
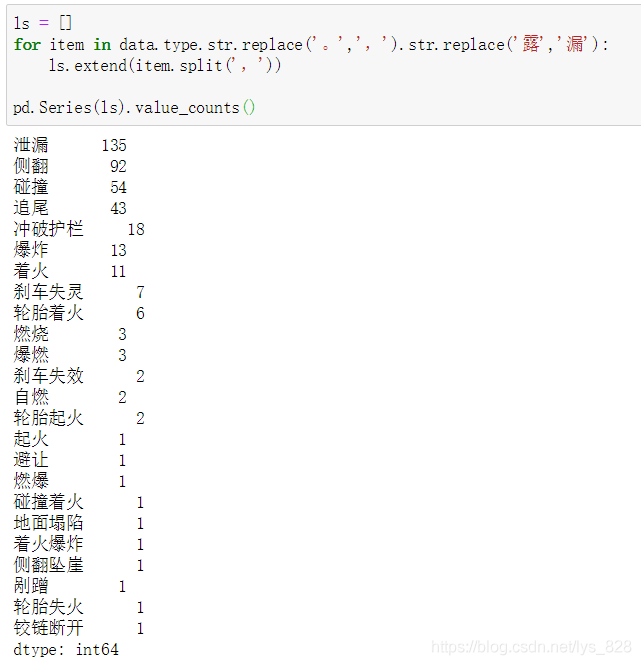
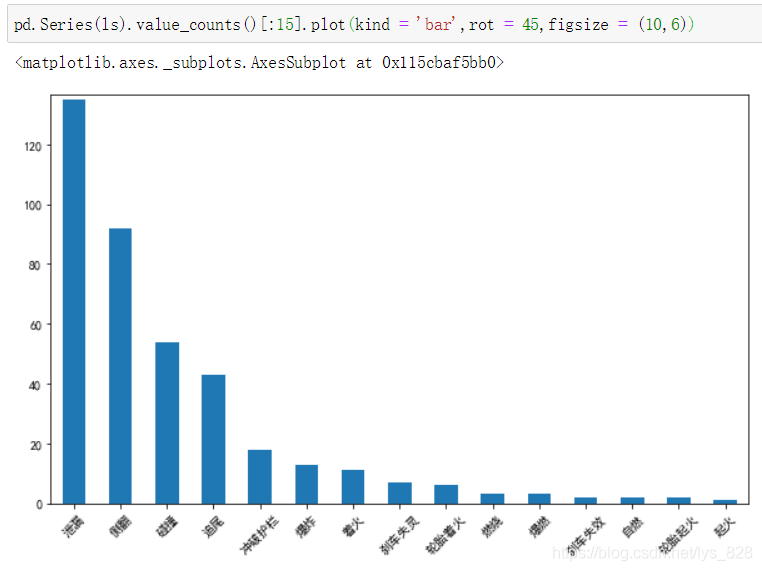
比如簡單的進行柱狀圖繪制,選取前15條資料
3.2 使用字典計數的方式進行統計
使用字典中的get方式就可以實作對串列中的資料進行計數,代碼如下
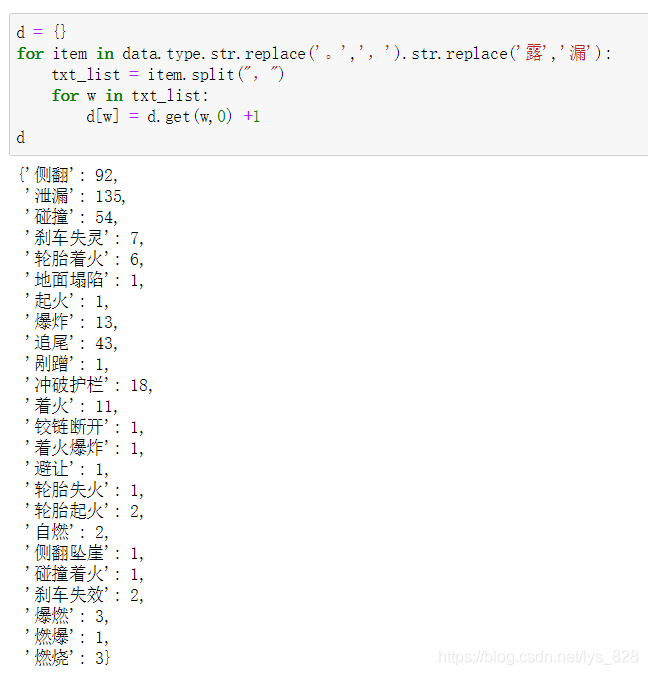
d = {}
for item in data.type.str.replace(',',',').str.replace('露','漏'):
txt_list = item.split(",")
for w in txt_list:
d[w] = d.get(w,0) +1
d
輸出結果為:(這樣直接就形成了一個字典對應的資料集)
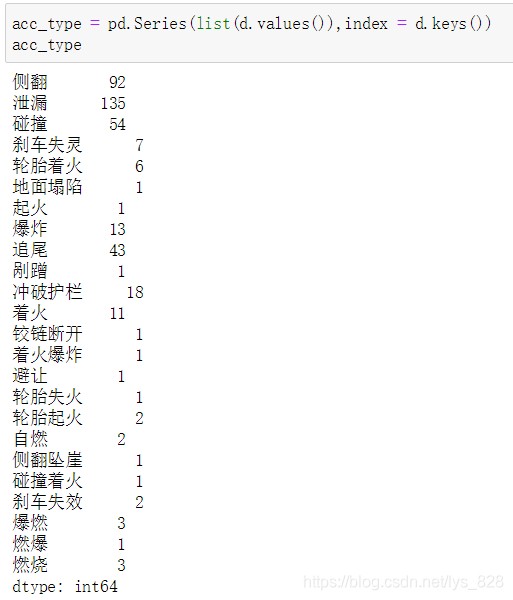
這里的d變數也可以直接轉化為Series資料,代碼如下
acc_type = pd.Series(list(d.values()),index = d.keys())
acc_type
輸出結果為:(通過字典來構造Series資料)
3.3 使用pd.explode()方法提取多特征轉化為Series進行計數
這種方法要求pandas的版本在0.25.0以上,可以參考前面的博客關于explode方法的使用詳解,這里就直接進行操作,代碼如下,一些常用的處理資料的程序,習慣直接封裝為函式,下次再使用的時候呼叫傳入相應的引數就可以了,這里封裝的介面就是直接傳入要統計的欄位名稱即可
def explode_acc(df_col):
df = df_col.value_counts().to_frame().reset_index()
df['index'] = df['index'].apply(lambda x: x.split(',') if type(x) == str else str(x))
df = df.explode('index').groupby('index').sum()
return df
explode_acc(data.type.str.replace(',',',').str.replace('露','漏'))
輸出結果為:(至此使用三種方式進行單欄位多特征的統計計數就完成了)

4 繪制時間序列事故圖
比如這里選擇呈現的是不同時間的事故起數和死亡人數,直接將程序的處理封裝為函式,然后進行相應引數的傳遞即可,但是注意一下欄位的資料型別,都應該是數值型別
def accident_count(df,column_1,column_2):
df_ = df.groupby(column_1).agg({column_1:'count',column_2:'sum'})
df_['account'] = (df_[column_1] / df_[column_1].sum()).map(lambda x:f'{round(x*100,2)}%')
return df_
4.1 按照年份進行繪制
直接就是傳入資料欄位和要統計的死亡人數欄位,代碼如下,后兩個引數就對應欄位的名稱,但是對應欄位的數字型別應該是為數值型
data.death_num = data.death_num.astype(int)
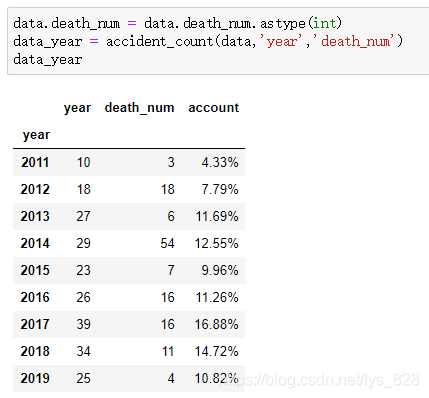
data_year = accident_count(data,'year','death_num')
data_year
輸出結果為:(這樣輸出結果的第一列就是事故起數,第二列就為死亡人數,最后一列為事故占比)
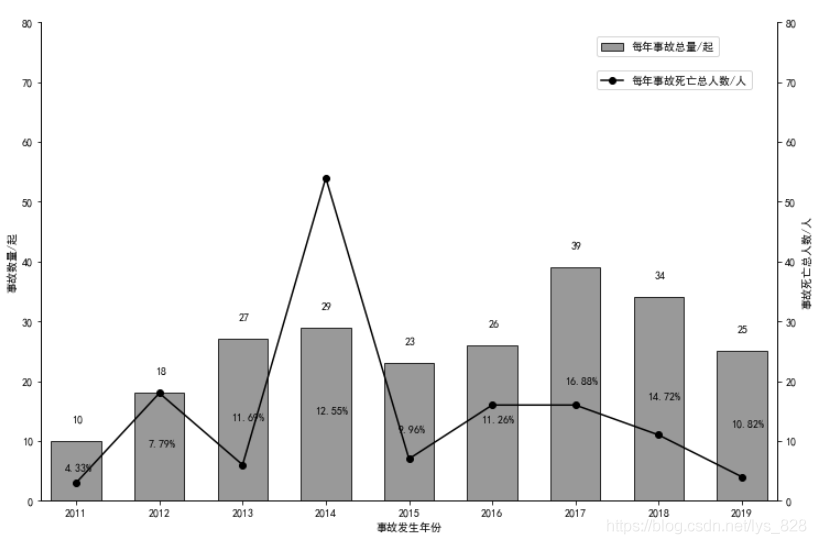
既然資料已經統計出來了,接著就是進行資料的繪圖操作,代碼如下
fig,ax = plt.subplots(figsize = (12,8))
ax.set_ylim(0,80)
ax.bar(data_year.index,data_year.year,width=0.6,edgecolor='k',color='gray',alpha = 0.8,label = '每年事故總量/起')
ax.legend(loc=(0.754,0.93))
ax.set_xlabel('事故發生年份')
ax.set_ylabel('事故數量/起')
ax.spines['top'].set_visible(False)
for i,j,k in zip(data_year.index,data_year.year.values,data_year.account.values):
ax.text(i-0.13,j/2-0.1,k,fontsize = 10)
ax.text(i-0.05,j+3,"%.0f" %j,fontsize = 10)
ax1 = ax.twinx()
ax1.spines['top'].set_visible(False)
ax1.set_ylim(0,80)
ax1.plot(data_year.index,data_year.death_num.values,label = '每年事故傷亡總人數/人',color = 'k',marker ='o')
ax1.legend(loc=(0.754,0.86))
ax1.set_ylabel('事故死亡總人數/人')
plt.savefig(r'1.png',dpi =200)
輸出結果為:(繪圖基本上就是這個程序,也是可以直接封裝函式的,方便后續的呼叫)
但是有一點就是在封裝的程序中遇到一個問題就是,y軸坐標顯示的問題,為了解決這個問題,先設計一個簡單的演算法進行y軸最大值的計算,這樣保證繪制出來的圖形比較合理,演算法函式如下
#為了方便自主出圖,設計個演算法進行自動去縱軸坐標值
def ceil_up(num):
'''
個位數的值小于5的直接取5,大于5的向上取10
十位數的值個位小于5的直接取5,個位大于5的,十位進1
百位數的值十位小于5的直接取5,十位大于5的,百位進1
千位數的值百位小于5的直接取5,百位大于5的,千位進1
萬位數的值千位小于5的直接取5,千位大于5的,萬位進1
'''
if num < 10:
if num <= 5:
num = 5
else:
num =10
elif num<100:
if int(str(num)[-1]) < 5:
num = int(str(num)[0])*10 + 10
else:
num = (int(str(num)[0]) + 1)*10
elif num<1000:
if int(str(num)[-2]) < 5:
num = int(str(num)[0])*100 + 50
else:
num = (int(str(num)[0])+1)*100
elif num <10000:
if int(str(num)[-3]) < 5:
num = int(str(num)[0])*1000 + 500
else:
num = (int(str(num)[0])+1)*1000
elif num <100000:
if int(str(num)[-4]) < 5:
num = int(str(num)[0])*10000 + 5000
else:
num = (int(str(num)[0])+1)*10000
return num
最后就是直接把出圖的程序封裝為函式,方便呼叫,同時保留幾個引數傳入的介面,這里使用的是表示時間的欄位和要保存圖片的路徑,方便直接一步到位,代碼如下
def plot_accident_figure(df_time,period,dir_path):
import os
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
fig,ax = plt.subplots(figsize = (12,8))
y1_max_data = df_time.iloc[:,0].max()
ax.set_ylim(0,ceil_up(y1_max_data)) #根據直接的要求調整y軸的顯示
# ax.set_yticks(range(0,ceil_up(y1_max_data)+1,50))
ax.bar(df_time.index,df_time.iloc[:,0],width=0.6,edgecolor='k',color='gray',alpha = 0.8,label = f'每{period}事故總量/起')
# ax.legend(loc=(0.754,0.93))
ax.set_xlabel(f'事故發生{period}')
ax.set_ylabel('事故數量/起')
ax.spines['top'].set_visible(False)
if all(type(x)==int for x in df_time.index.tolist()):
for i,j,k in zip(df_time.index,df_time.iloc[:,0].values,df_time.account.values):
ax.text(i-0.13,j/2-0.1,k,fontsize = 10)
ax.text(i-0.05,j+1,"%.0f" %j,fontsize = 10)
else:
for i,j,k in zip(range(0,len(df_time.index)),df_time.iloc[:,0].values,df_time.account.values):
ax.text(i-0.13,j/2-0.1,k,fontsize = 10)
ax.text(i-0.05,j+1,"%.0f" %j,fontsize = 10)
ax1 = ax.twinx()
ax1.spines['top'].set_visible(False)
y2_max_data = df_time.iloc[:,1].max()
ax1.set_ylim(0,ceil_up(y2_max_data)) #根據直接的要求調整y軸的顯示
# ax1.set_yticks(range(0,ceil_up(y2_max_data)+10,50))
ax1.plot(df_time.index,df_time.death_num.values,label = f'每{period}事故傷亡總人數/人',color = 'r',marker ='o')
# ax1.legend(loc=(0.754,0.86))
ax1.set_ylabel('事故傷亡總人數/人')
plt.savefig(os.path.join(dir_path,f'每{period}事故統計圖.png'),dpi =200)
關于這個函式中,除了剛剛講到的y軸最大值的處理外,還有一個問題就是文本標記的設定,其中如果標簽值是數字時候,那么做文本標記的時候就相對于簡單,但是如果是文本資料時候,就出現問題了,所以這里需要進行兩種判斷,最后按照標簽的資料型別進行文本標記
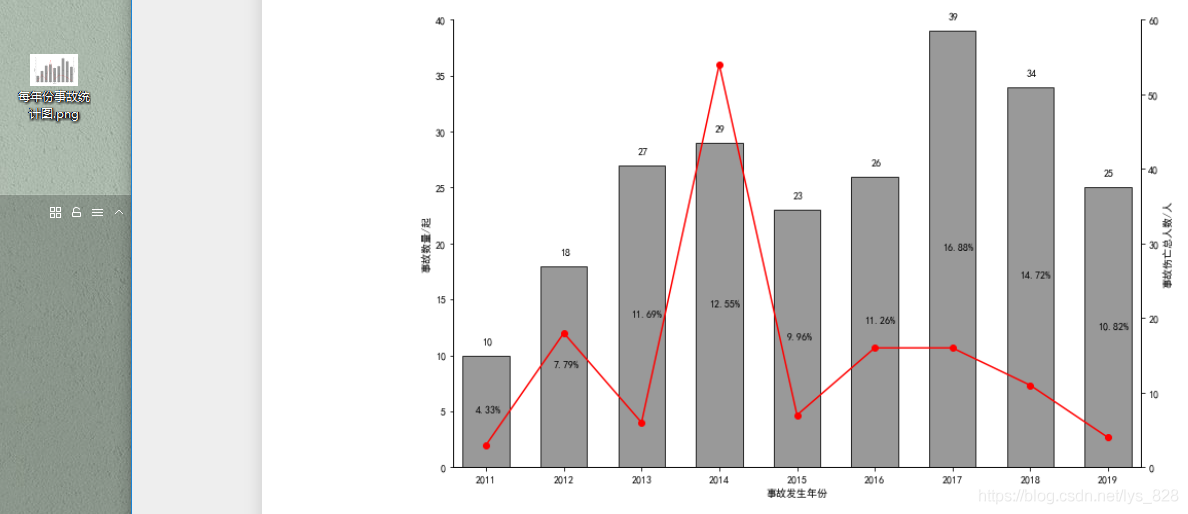
使用這個封裝的函式試一下繪圖如何,代碼如下
path = r'C:\Users\86177\Desktop'
plot_accident_figure(data_year,'年份',path)
輸出結果為:(可以發現兩側的y軸的最大值會跟著資料的最大值變化,而不需要人為指定)
4.2 按照季度進行繪制
前面已經封裝好函式了,這里只需要進行季度資料的獲取即可,代碼如下
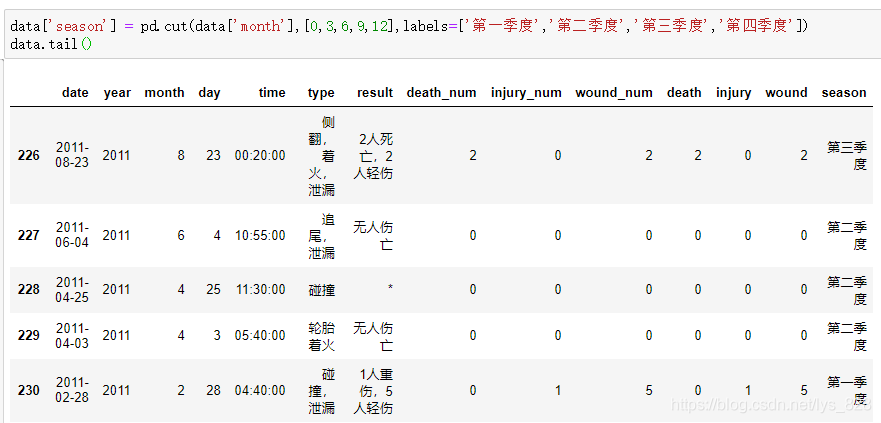
data['season'] = pd.cut(data['month'],[0,3,6,9,12],labels=['第一季度','第二季度','第三季度','第四季度'])
data.tail()
輸出結果為:(對月份欄位進行cut切割就可以得到季度的資料)
然后將季度的欄位傳到封裝好的函式中去,代碼如下
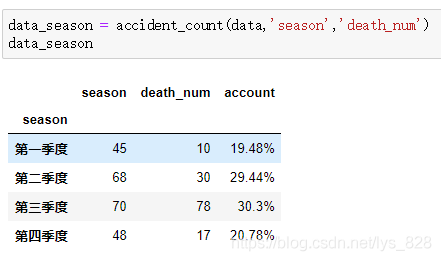
data_season = accident_count(data,'season','death_num')
data_season
輸出結果為:
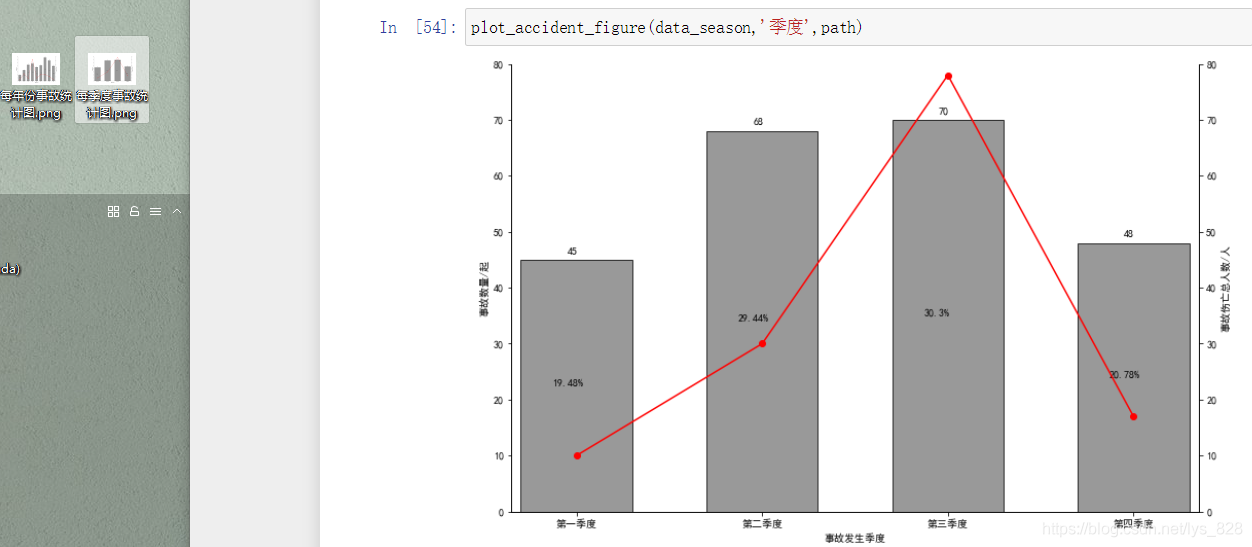
plot_accident_figure(data,'季度',path)
輸出結果為:
4.3 按照月份進行繪制
月份資料之前已經提取完畢了,這里就方便多了,直接就可以拿過來用,呼叫兩個函式就完成資料結果和繪圖輸出
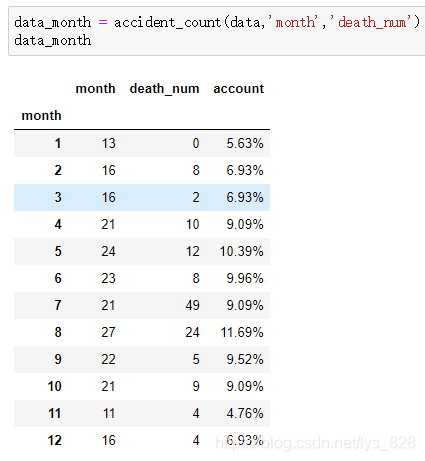
data_month = accident_count(data,'month','death_num')
data_month
輸出結果為:
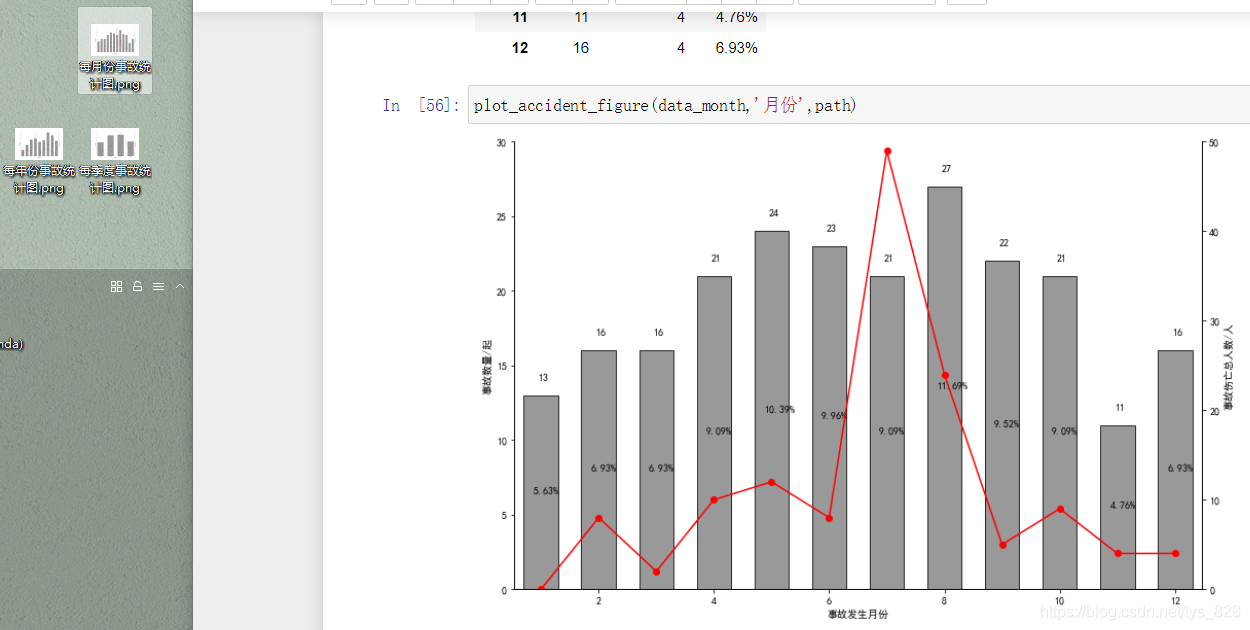
呼叫繪圖函式直接繪制影像
plot_accident_figure(data_month,'月份',path)
輸出結果為:
4.4 按照小時進行繪制
這一部分就是對小時的欄位進行處理了,難度還是有一點,代碼如下
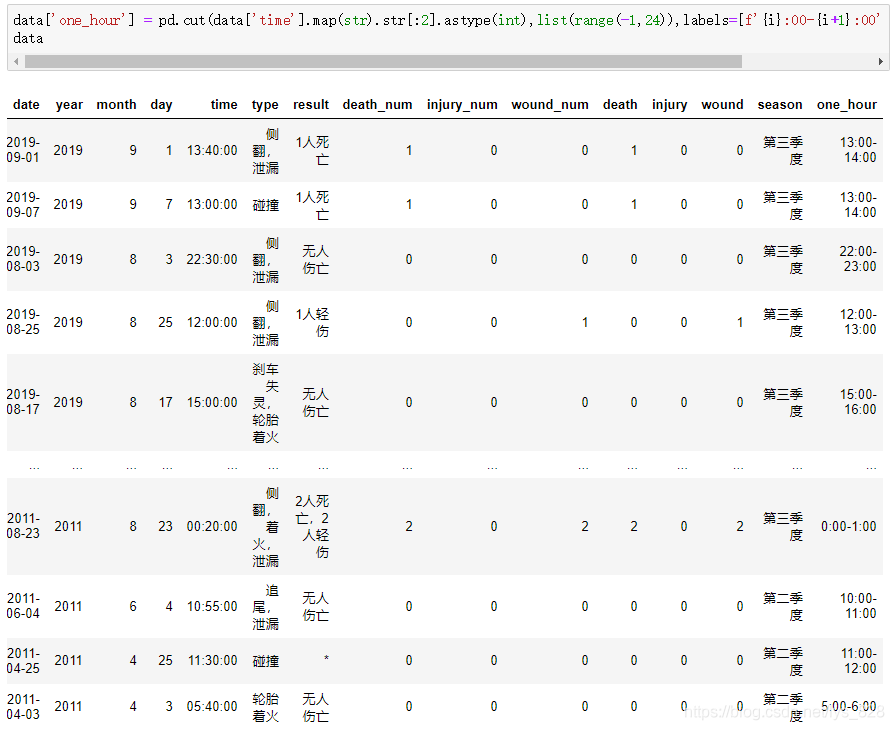
data['one_hour'] = pd.cut(data['time'].map(str).str[:2].astype(int),list(range(-1,24)),labels=[f'{i}:00-{i+1}:00' for i in range(24)])
data
輸出結果為:(就是提取前兩個字符然后轉化為數字,按照數字的取值進行cut切分,最后就可以設定對應的labels)
那么兩小時的欄位處理也就類似了
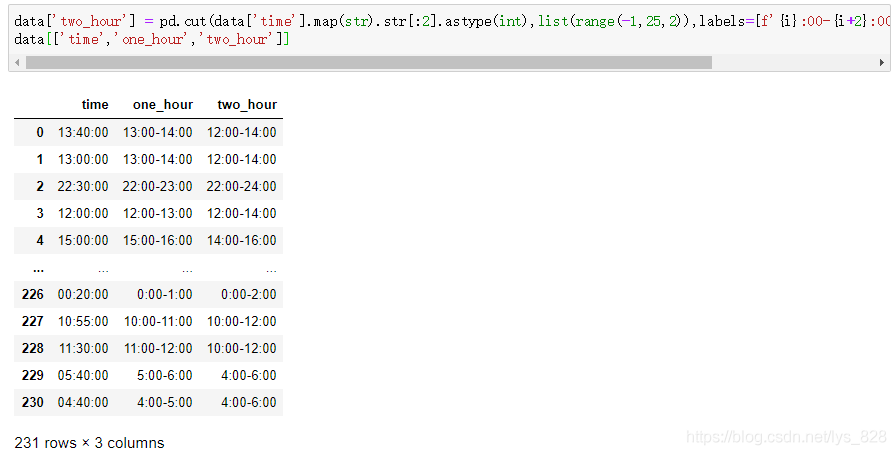
data['two_hour'] = pd.cut(data['time'].map(str).str[:2].astype(int),list(range(-1,25,2)),labels=[f'{i}:00-{i+2}:00' for i in range(0,24,2)])
data[['time','one_hour','two_hour']]
輸出結果為:
采用兩小時的欄位資料進行統計和繪圖,操作如下
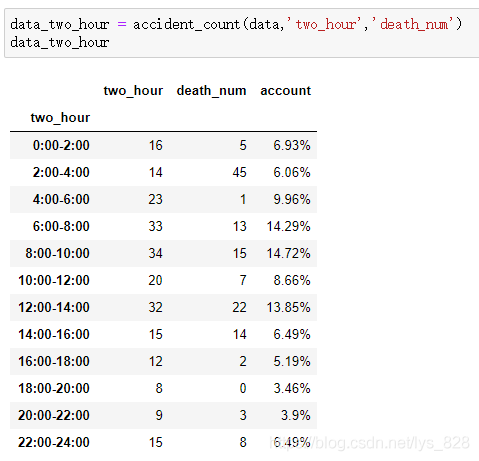
data_two_hour = accident_count(data,'two_hour','death_num')
data_two_hour
輸出結果為:
最后就是繪圖了
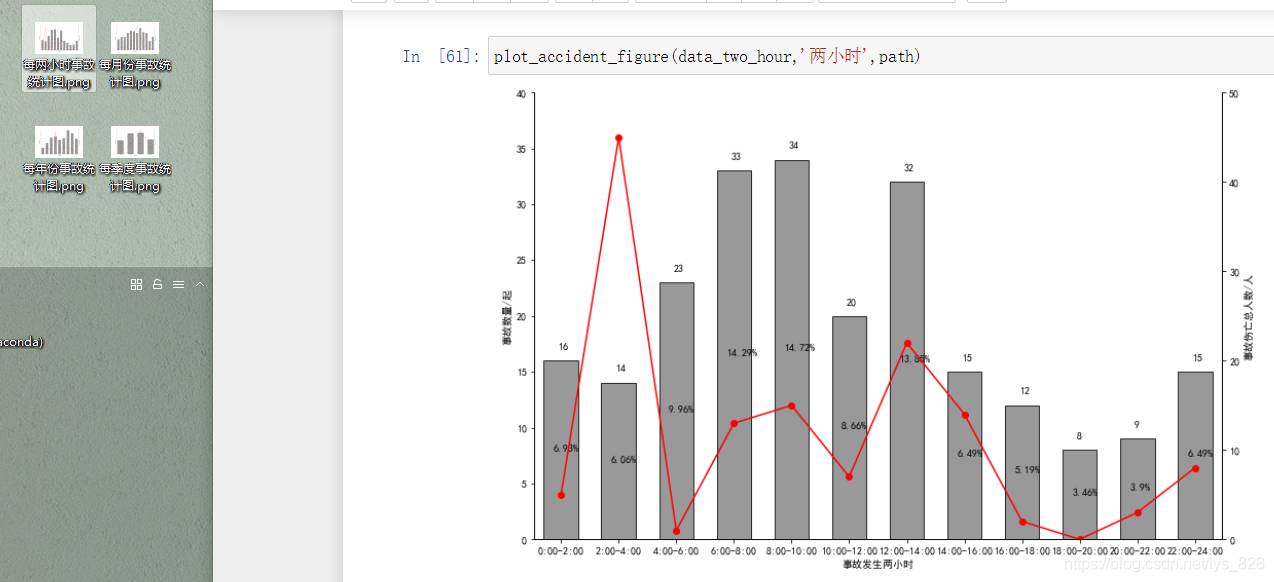
至此全部就梳理完畢了,撒花~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/212870.html
標籤:python
上一篇:Python資料分析期末復習歸納