一、二叉樹補充、多叉樹
1、二叉樹(非遞回實作遍歷)
(1)前提
前面一篇介紹了 二叉樹、順序二叉樹、線索二叉樹、哈夫曼樹等樹結構,
可參考:https://www.cnblogs.com/l-y-h/p/13751459.html#_label5_1
(2)二叉樹遍歷
【遞回與非遞回實作:】 使用遞回實作時,系統隱式的維護了一個堆疊 用于操作節點,雖然遞回代碼易理解,但是對于系統的性能會造成一定的影響, 使用非遞回代碼實作,可以主動去維護一個堆疊 用于操作節點,非遞回代碼相對于遞回代碼,其性能可能會稍好(資料大的情況下), 注: 堆疊是先進后出(后進先出)結構,即先存放的節點后輸出(后存放的節點先輸出), 所以使用堆疊時,需要明確每一步需要壓入的樹節點, 遞回實作二叉樹 前序、中序、后序遍歷,可參考:https://www.cnblogs.com/l-y-h/p/13751459.html#_label5_2
(3)非遞回實作前序遍歷
【非遞回實作前序遍歷:】 前序遍歷順序:當前節點(父節點)、左子節點、右子節點, 實作思路: 首先明確一點,每次出堆疊的樹節點即為當前需要輸出的節點(第一個輸出的節點為 根節點), 每次首先輸出的為 當前節點(父節點),所以父節點先入堆疊、再出堆疊, 出堆疊之后,需要重新選擇出下一次需要輸出的父節點,從當前節點的 左、右子節點中選擇, 而左子節點需要在 右子節點前輸出,所以右子節點需要先進堆疊,然后左子節點再進堆疊, 左子節點入堆疊后,再次出堆疊即為當前節點,然后重復上面操作,依次取出堆疊頂元素即可, 步驟: Step1:根節點入堆疊, Step2:根節點出堆疊,此時為當前節點,輸出或者保存, Step2.1:若當前節點存在右子節點,則壓入堆疊, Step2.2:若當前節點存在左子節點,則壓入堆疊, Step3:重復 Step2,依次取出堆疊頂元素并輸出,堆疊為空時,則樹遍歷完成, 【非遞回前序遍歷代碼實作:】 package com.lyh.tree; import java.util.ArrayList; import java.util.List; import java.util.Stack; public class BinaryTreeSort<K> { /** * 前序遍歷(非遞回實作、使用堆疊模擬遞回) */ public List<K> prefixList(TreeNode9<K> root) { // 使用集合保存最終結果 List<K> result = new ArrayList<>(); // 根節點不存在時,回傳空集合 if (root == null) { return result; } // 使用堆疊模擬遞回 Stack<TreeNode9<K>> stack = new Stack<>(); // 根節點入堆疊 stack.push(root); // 堆疊非空時,依次取出堆疊頂元素,此時堆疊頂元素為當前節點,輸出,并將當前節點 左、右子節點入堆疊 // 左子節點 先于 右子節點出堆疊,所以左子節點在 右子節點入堆疊之后再入堆疊 while(!stack.isEmpty()) { // 取出堆疊頂元素(當前節點) TreeNode9<K> tempNode = stack.pop(); // 保存(或者輸出)當前節點 result.add(tempNode.data); // 存在右子節點,則壓入堆疊 if (tempNode.right != null) { stack.push(tempNode.right); } // 存在左子節點,則壓入堆疊 if (tempNode.left != null) { stack.push(tempNode.left); } } return result; } public static void main(String[] args) { // 構建二叉樹 TreeNode9<String> root = new TreeNode9<>("0"); TreeNode9<String> treeNode = new TreeNode9<>("1"); TreeNode9<String> treeNode2 = new TreeNode9<>("2"); TreeNode9<String> treeNode3 = new TreeNode9<>("3"); TreeNode9<String> treeNode4 = new TreeNode9<>("4"); root.left = treeNode; root.right = treeNode2; treeNode.left = treeNode3; treeNode.right = treeNode4; // 前序遍歷 System.out.print("前序遍歷: "); System.out.println(new BinaryTreeSort<String>().prefixList(root)); System.out.println("\n====================="); } } class TreeNode9<K> { K data; // 保存節點資料 TreeNode9<K> left; // 保存節點的 左子節點 TreeNode9<K> right; // 保存節點的 右子節點 public TreeNode9(K data) { this.data =https://www.cnblogs.com/l-y-h/p/ data; } @Override public String toString() { return "TreeNode9{ data= "https://www.cnblogs.com/l-y-h/p/+ data +"}"; } } 【輸出結果:】 前序遍歷: [0, 1, 3, 4, 2]
(4)非遞回實作中序遍歷
【非遞回實作中序遍歷:】 中序遍歷順序:左子節點、當前節點、右子節點, 實作思路: 首先明確一點,每次出堆疊的樹節點即為當前需要輸出的節點(第一次輸出的節點為 最左側節點), 由于每次都要先輸出當前節點的最左側節點,所以需要遍歷找到這個節點, 而在遍歷的程序中,每次經過的樹節點均為 父節點,可以使用堆疊保存起來, 此時,找到并輸出最左側節點后,就可以出堆疊獲得父節點,然后根據父節點可以找到其右子節點, 將右子節點入堆疊,同理找到其最左子節點,并重復上面操作,依次取出堆疊頂元素即可, 注: 為了防止重復執行父節點遍歷左子節點的操作,可以使用輔助變數記錄當前操作的節點, 步驟: Step1:記當前節點為根節點,從根節點開始,遍歷找到最左子節點,并依次將經過的樹節點入堆疊, Step2:取出堆疊頂元素,此時為最左子節點(當前節點),輸出或者保存, Step2.1:若存在右子節點,則當前節點為 父節點,將右子節點入堆疊,并修改新的當前節點為 右子節點,遍歷當前節點,同理找到最左子節點,并依次將經過的節點入堆疊, Step2.2:若不存在右子節點,則當前節點為 左子節點,下一次取得的堆疊頂元素即為 父節點, Step3:重復上面程序,輸出順序即為 左、根、右, 【非遞回中序遍歷代碼實作:】 package com.lyh.tree; import java.util.ArrayList; import java.util.List; import java.util.Stack; public class BinaryTreeSort<K> { /** * 中序遍歷(非遞回實作,使用堆疊模擬遞回) */ public List<K> infixList(TreeNode9<K> root) { // 使用集合保存遍歷結果 List<K> result = new ArrayList<>(); if (root == null) { return result; } // 保存當前節點 TreeNode9<K> currentNode = root; // 使用堆疊模擬遞回實作 Stack<TreeNode9<K>> stack = new Stack<>(); while(!stack.isEmpty() || currentNode != null) { // 找到當前節點的左子節點,并依次將經過的節點入堆疊 while(currentNode != null) { stack.push(currentNode); currentNode = currentNode.left; } // 取出堆疊頂元素 TreeNode9<K> tempNode = stack.pop(); // 保存堆疊頂元素 result.add(tempNode.data); // 存在右子節點,則右子節點入堆疊, if (tempNode.right != null) { currentNode = tempNode.right; } } return result; } public static void main(String[] args) { // 構建二叉樹 TreeNode9<String> root = new TreeNode9<>("0"); TreeNode9<String> treeNode = new TreeNode9<>("1"); TreeNode9<String> treeNode2 = new TreeNode9<>("2"); TreeNode9<String> treeNode3 = new TreeNode9<>("3"); TreeNode9<String> treeNode4 = new TreeNode9<>("4"); root.left = treeNode; root.right = treeNode2; treeNode.left = treeNode3; treeNode.right = treeNode4; // 前序遍歷 System.out.print("中序遍歷: "); System.out.println(new BinaryTreeSort<String>().infixList(root)); System.out.println("\n====================="); } } class TreeNode9<K> { K data; // 保存節點資料 TreeNode9<K> left; // 保存節點的 左子節點 TreeNode9<K> right; // 保存節點的 右子節點 public TreeNode9(K data) { this.data =https://www.cnblogs.com/l-y-h/p/ data; } @Override public String toString() { return "TreeNode9{ data= "https://www.cnblogs.com/l-y-h/p/+ data +"}"; } } 【輸出結果:】 中序遍歷: [3, 1, 4, 0, 2]
(5)非遞回實作后序遍歷
【非遞回實作后序遍歷:】 后序遍歷順序:左子節點、右子節點、當前節點, 實作思路: 首先明確一點,每次出堆疊的樹節點即為當前需要輸出的節點(第一次輸出的節點為最左側節點), 這里與 中序遍歷還是有點類似的,同樣是先輸出最左側節點,區別在于,后序遍歷先輸出 右子節點,再輸出父節點, 同樣使用一個變數,用來輔助遍歷,防止父節點重復遍歷子節點, 此處的變數,可以理解成上一次節點所在位置,而堆疊頂取出的當前節點為上一次節點的父節點, 步驟: Step1:根節點入堆疊, Step2:取出堆疊頂元素(當前節點),判斷其是否存在子節點, Step2.1:存在左子節點,且未被訪問過,左子節點入堆疊(此處為遍歷找到最左子節點), Step2.2:存在右子節點,且未被訪問過,右子節點入堆疊, Step2.3:不存在 或者 已經訪問過 左、右子節點,輸出當前節點, Step3:重復以上操作,直至堆疊空, 【非遞回后序遍歷代碼實作:】 package com.lyh.tree; import java.util.ArrayList; import java.util.List; import java.util.Stack; public class BinaryTreeSort<K> { /** * 后序遍歷(非遞回實作,使用堆疊模擬遞回) */ public List<K> suffixList(TreeNode9<K> root) { // 使用集合保存遍歷結果 List<K> result = new ArrayList<>(); if (root == null) { return result; } // 保存當前節點 TreeNode9<K> currentNode = root; // 使用堆疊模擬遞回實作 Stack<TreeNode9<K>> stack = new Stack<>(); // 根節點入堆疊 stack.push(root); // 依次取出堆疊頂元素 while(!stack.isEmpty()) { // 取出堆疊頂元素 TreeNode9<K> tempNode = stack.peek(); // 若當前節點 左子節點 存在,且未被訪問,則入堆疊 if (tempNode.left != null && currentNode != tempNode.left && currentNode != tempNode.right) { stack.push(tempNode.left); } else if (tempNode.right != null && currentNode != tempNode.right){ // 若當前節點 右子節點存在,且未被訪問,則入堆疊 stack.push(tempNode.right); } else { // 當前節點不存在 左、右子節點 或者 左、右子節點已被訪問,則取出堆疊頂元素, // 并標注當前節點位置,表示當前節點已被訪問 result.add(stack.pop().data); currentNode = tempNode; } } return result; } public static void main(String[] args) { // 構建二叉樹 TreeNode9<String> root = new TreeNode9<>("0"); TreeNode9<String> treeNode = new TreeNode9<>("1"); TreeNode9<String> treeNode2 = new TreeNode9<>("2"); TreeNode9<String> treeNode3 = new TreeNode9<>("3"); TreeNode9<String> treeNode4 = new TreeNode9<>("4"); root.left = treeNode; root.right = treeNode2; treeNode.left = treeNode3; treeNode.right = treeNode4; // 前序遍歷 System.out.print("后序遍歷: "); System.out.println(new BinaryTreeSort<String>().suffixList(root)); System.out.println("\n====================="); } } class TreeNode9<K> { K data; // 保存節點資料 TreeNode9<K> left; // 保存節點的 左子節點 TreeNode9<K> right; // 保存節點的 右子節點 public TreeNode9(K data) { this.data =https://www.cnblogs.com/l-y-h/p/ data; } @Override public String toString() { return "TreeNode9{ data= "https://www.cnblogs.com/l-y-h/p/+ data +"}"; } } 【輸出結果:】 后序遍歷: [3, 4, 1, 2, 0]
2、多叉樹、B樹
(1)平衡二叉樹可能存在的問題
平衡二叉樹雖然效率高,但是當資料量非常大時(資料存放在 資料庫 或者 檔案中,需要經過磁盤 I/O 操作),此時構建平衡二叉樹會消耗大量時間,影響程式執行速度,同時會出現大量的樹節點,導致平衡二叉樹的高度非常大,此時再去進行查找操作 性能也不是很高,
平衡二叉樹中,每個節點有 一個資料項,以及兩個子節點,那么能否增加 節點的子節點數 以及 資料項 來提高程式性能呢?從而引出了 多路查找樹 的概念,
注:
前面介紹了平衡二叉樹,可參考:https://www.cnblogs.com/l-y-h/p/13751459.html#_label5_9
即平衡二叉樹只允許每個節點最多出現兩個分支,而此處的多路查找樹指的是允許出現多個分支(且分支有序),
(2)多叉樹、多路查找樹
多叉樹 允許每個節點 可以有 兩個以上的子節點以及資料項,
多路查找樹 即 平衡的多叉樹(資料有序),
常見多路查找樹 有:2-3 樹、B 樹(B-樹)、B+樹、2-3-4 樹 等,
(3)B 樹(B-樹)
B 樹 即 Balanced-tree,簡稱 B-tree(B 樹、B-樹是同一個東西),是一種平衡的多路查找樹,
樹節點的子節點最多的數目稱為樹的階,比如:2-3 樹的階為 3,2-3-4 樹的階為 4,
【一顆 M 階的 B 樹特點:(M 階指的是最大節點的子節點個數)】 每個節點最多有 M 個子節點(子樹), 根節點存在 0 個或者 2 個以上子節點, 非葉子節點 若存在 j 個子節點,那么該非葉子節點保存 j - 1 個資料項,且按照遞增順序存盤, 所有的葉子節點均在同一層, 注: B 樹是一個平衡多路查找樹,具有與 平衡二叉樹 類似的特點, 區別在于 B 樹分支更多,從而構建出的樹高度低, 當然 B 樹也不能無限制的增大 樹的階,階約大,則非葉子節點保存的資料項越多(變成了一個有序陣列,增加查找時間),
(4)2-3 樹
2-3 樹是最簡單的 B 樹,是一顆平衡多路查找樹,
其節點可以分為 2 節點、3 節點,且 所有葉子節點均在同一個層,
【2-3 樹特點:】 對于 2 節點: 只能包含一個資料項 和 兩個子節點(或者沒有子節點), 左子節點值 小于 當前節點值,右子節點值 大于 當前節點值, 不存在只有一個子節點的情況, 對于 3 節點: 包含一大一小兩個資料項(從小到大排序) 和 三個子節點(或者沒有子節點), 左子節點值 小于 當前節點資料項最小值,右子節點值 大于 當前節點資料項最大值,中子節點值 在 當前節點資料項值之間, 不存在有 1 子節點、2 個子節點的情況,
根據 {16, 24, 12, 32, 14, 26, 34, 10, 8, 28, 38, 20, 33} 構建的 2-3 樹如下:
可使用 https://www.cs.usfca.edu/~galles/visualization/Algorithms.html 構建,
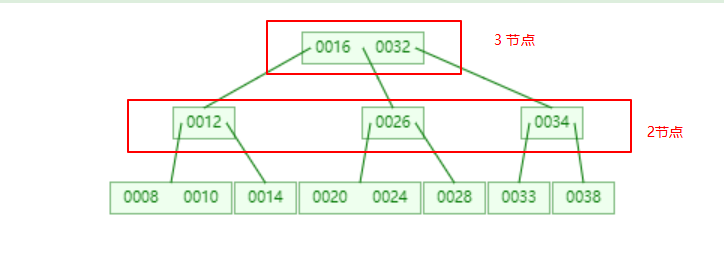
(5)B+ 樹
B+ 樹是 B 樹的變種,
區別在于 B+ 樹資料存盤在葉子節點,資料最終只能在 葉子節點 中找到,而 B 樹可以在 非葉子節點 找到,
B+ 樹性能可以等價于 對 全部葉子節點(所有關鍵字)進行一次 二分查找,
【B+ 樹特點:】
所有 資料項(關鍵字) 均存放于 葉子節點,
每個葉子節點 存放的 資料項(關鍵字)是有序的,
所有葉子節點使用鏈表相連(即進行范圍查詢時,只需要查找到 首尾節點、然后遍歷鏈表 即可),
注:
所有資料項(關鍵字) 均存放與 葉子節點組成的鏈表中,且資料有序,可以視為稠密索引,
非葉子節點 相當于 葉子節點的索引,可以視為 稀疏索引,
根據 {16, 24, 12, 32, 14, 26, 34, 10, 8, 28, 38, 20, 33} 構建的 B+ 樹(3階、2-3 樹)如下:
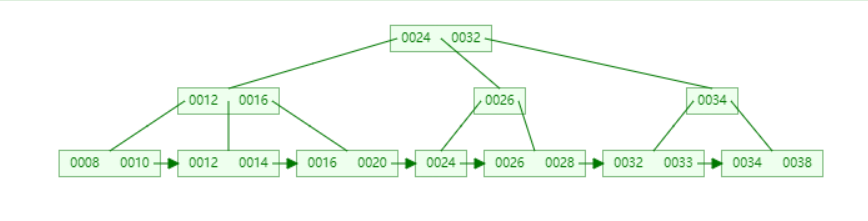
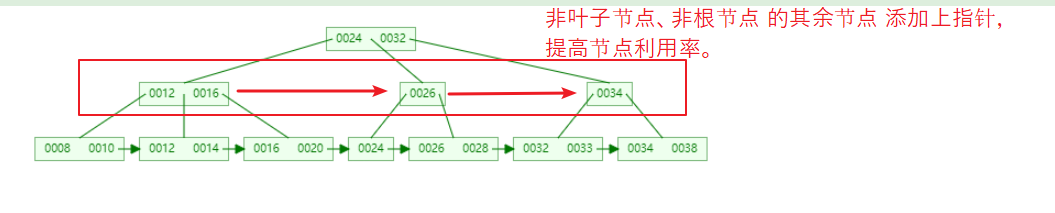
(6)B* 樹
B* 樹 是 B+ 樹的變體,
其在 B+樹 基礎上,在除 非根節點、非葉子節點 之外的其余節點之間增加指標,提高節點利用率,
【B* 樹與 B+ 樹 節點分裂的區別:】 對于 B+ 樹: B+ 樹 節點的最低使用率是 1/2,其非葉子節點關鍵字(資料項)個數至少為 (1/2)*M,M 為 B+ 樹的階, 當一個節點存放滿時,會增加一個節點,并將原節點 1/2 的資料移動到新的節點,然后在 父節點 添加新的節點, B+ 樹 只影響 原節點 以及 父節點,不會影響兄弟節點,兄弟之間不需要指標, 對于 B* 樹: B* 樹 節點的最低使用率為 2/3,其非葉子節點關鍵字(資料項)個數至少為 (2/3)*M, 當一個節點存放滿時,若其下一個兄弟節點未滿,則將一部分資料移到兄弟節點中,在原節點 添加新節點,然后修改 父節點 中的節點(兄弟節點發生改變), 若其下一個兄弟已滿,則在 兩個兄弟之間 增加一個新節點,并分別從兩個兄弟節點中 移動 1/3 的資料到新節點,然后在 父節點 添加新的節點, B* 樹 影響了 兄弟節點,所以需要指標將兄弟節點連接起來, 總的來說,B* 樹分配新節點的概率比 B+ 樹低,B* 樹的節點利用率更高, 注: 相關內容參考:https://blog.csdn.net/wyqwilliam/article/details/82935922
下圖不一定正確,大概理解意思就行,
(7)B-樹、B+樹、B*樹總結
【B 樹 或者 B- 樹:】 平衡的多路查找樹,非葉子節點至少存盤 (1/2)*M 個關鍵字(資料項), 關鍵字升序存盤,且僅出現一次, 進行查找匹配操作時,可以在 非葉子節點 成功匹配, 【B+ 樹:】 B 樹的變種,僅在 葉子節點 保存資料項,且葉子節點之間 通過鏈表存盤, 整體 資料項 有序存盤, 非葉子節點 作為 葉子節點 的索引存在,匹配時通過 非葉子節點 快速定位到 葉子節點,然后在 葉子節點 處進行匹配操作,相當于進行 二分查找, 【B* 樹:】 B+ 樹的變種,給 非葉子節點 也加上指標,非葉子節點 至少存盤 (2/3)*M 個關鍵字, 將節點利用率 從 1/2 提高到 2/3 ,
二、延伸一下 MySQL 索引底層資料結構
1、索引(Index)
(1)索引是什么?
索引是一種有序的、快速查找的資料結構,
索引 由 若干個 索引項組成,每個索引項 由 資料的關鍵字 以及 其相對應的記錄(比如:記錄對應在磁盤中的 地址資訊)組成,
索引的查找,就是根據 索引項中的關鍵字 去關聯 其相應的記錄 的程序,
(2)資料庫為什么使用索引?
為了提高資料查詢效率,資料庫在維護資料的同時維護一個滿足特定查找演算法的資料結構,這個資料結構以某種方式指向資料、或者存盤資料的參考,通過這個資料結構實作高級查找演算法,這樣就可以快速查找資料,
而這種資料結構就是索引,
索引按照結構劃分為:線性索引、樹形索引、多級索引,
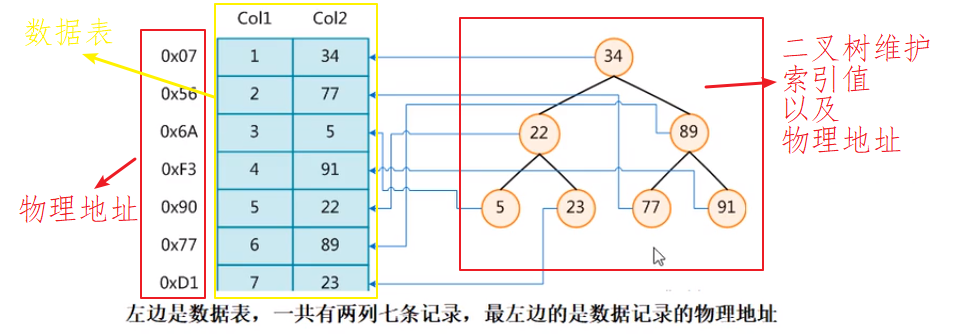
如下圖所示資料結構:(樹形索引,僅供參考,圖片來源于網路)
使用二叉樹維護資料的索引值以及資料的物理地址,使用二叉樹可以在一定的時間復雜度內查找到資料,然后根據該資料的物理地址找到存盤在表中的資料,從而實作快速查找,
2、線性索引(稠密索引、稀疏索引)
(1)什么是線性索引?
線性索引 指的是 將索引項組合成線性結構,也可稱為索引表,
常見分類:稠密索引(密集索引)、稀疏索引(分塊索引)、倒排索引,
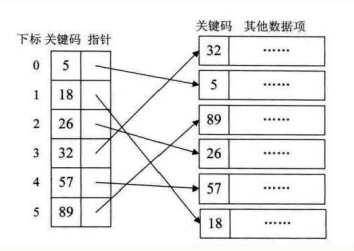
(2)稠密索引(密集索引)
稠密索引 指的線性結構是:每個索引項 對應一個資料集(記錄),記錄在資料區(磁盤)中可以是無序的,但是所有索引項 是有序的(方便查找),
但由于每個索引項占用的空間較大,若資料量較大時(每個索引項對應一個記錄),占用空間會很大(可能無法一次在記憶體中讀取,需要多次磁盤 I/O,降低查找性能),
即 占用空間大、查找效率高,
如下圖(圖片來源于網路):
左邊索引表 中的索引項 按照關鍵碼有序,可以使用 二分查找 或者其他高效查找演算法,快速定位到對應的索引項,然后找到對應的 記錄,
注:
前面介紹的 B+ 樹的所有葉子節點可以看成是 稠密索引,其所有葉子節點 由鏈表連接,且葉子節點有序,可以應用上 稠密索引,
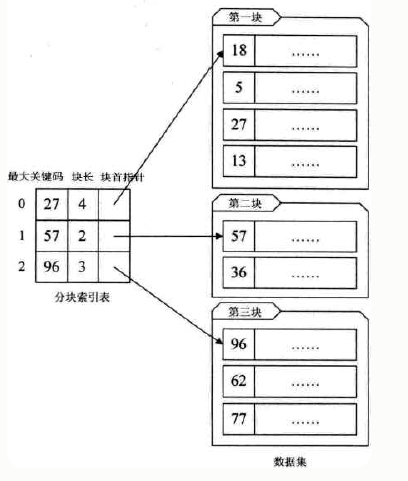
(3)稀疏索引(分塊索引)
稠密索引 其每個索引項 對應一個記錄,占用空間大,
稀疏索引 指的線性結構是:將資料集按照某種方式 分成若干個資料塊,每個索引項 對應一個資料塊,每個資料塊可以包含多個資料(記錄),這些資料之間可以是無序的,但 資料塊之間是有序的(索引項有序),
索引項無需保存 所有記錄,只需要記錄關鍵字即可,占用空間小,且索引項有序,可以快速定位到資料塊,但是 資料塊內沒要求是有序的(維護有序序列需要付出一些代價),所以資料塊中可能順序查找(資料量較大時,查找效率較低),
即 占用空間小、查找效率可能較低,
如下圖(圖片來源于網路):
左邊索引表 按照關鍵碼有序,可以通過 二分查找 等演算法快速定位到 資料塊,然后在資料塊中查找資料,
注:
前面介紹的 B+ 樹中 非葉子節點 與 葉子節點 之間可以看成 稀疏索引,非葉子節點 僅保存 葉子節點的索引,葉子節點 保存 資料塊,且此時 多個資料塊之間 有序、每個資料塊 之內也有序,
3、MySQL 索引底層資料結構
(1)底層資料結構
MySQL 底層資料結構,一般回答都是 B+ 樹,
那么為什么選擇 B+ 樹?哈希、二叉樹、B樹 等結構不可以嗎?
(2)為什么不使用 哈希表 作為索引?
【常用快速查找的資料結構有兩種:】 哈希表: 比如 HashMap,其查找、添加、洗掉、修改的平均時間復雜度均為 O(1) 樹: 比如 平衡二叉樹,其查詢、添加、洗掉、修改的平均時間復雜度均為O(logn) 【什么是哈希表?】 哈希表(Hash table 、散串列),是根據鍵(Key)直接訪問資料(Value)的一種資料結構, 規則: 使用某種方式(映射函式)將鍵值(Key)映射到陣列中的某個位置,并在此位置存放記錄,用于加快查詢速度, 映射函式 也稱為 散列函式,存放記錄的陣列 稱為 散串列, 理解: 使用 散列函式,將 鍵值(Key)轉換為一個 整型數字, 然后再對數字進行轉換(取模、與運算等),將其轉為 陣列對應的下標,并將 value 存盤在該下標對應的存盤空間中, 而進行查詢操作時,再次對 Key 進行運算,轉換為對應的陣列下標,即可定位并獲取 value 值(時間復雜度為 O(1)), 【為什么不使用 哈希表?】 對于 單次寫操作或者讀操作 來說,哈希的速率比樹快,但是為什么不用哈希表呢? 可以想一下如果是排序或者范圍查詢的情況下,執行哈希是什么情況,很顯然,哈希無法很快的進行范圍查找(其資料都是無序的),查找范圍 0~n 的情況下,會執行 n 次查找,也即時間復雜度為 O(n), 而樹(AVL樹、B樹、B+樹等)是有序的(1、2 次查找即可),其時間復雜度仍可以保證在 O(logn), 相比較之下,哈希肯定沒有樹的效率高,因此不會使用哈希這種資料結構作為索引, 【平衡二叉樹時間復雜度 O(logn) 怎么來的?】 在樹中查找一個數字時,第一次在樹的第一層(根節點)判斷,第二次在樹的第二層判斷,依次類推,樹有多少層,就會進行多少次判斷,即對于 k 層的樹,最壞時間復雜度為O(k), 所以只需要知道 n 個節點的樹有多少層即可, 若為滿二叉樹(除葉子節點外,每個節點均有兩個節點),則對于第一層,有一個節點(2^0),對于第二層有兩個節點(2^1),依次類推對于第 k 層有 2^k-1(2 的 k-1 次方), 所以 n = 2^0 + 2^1 + ... + 2^k-1,從而 k = log(n + 1), 所以時間復雜度為 O(k) = O(logn) k 為樹 層數,n 為樹 節點數,
(3)為什么不使用二叉查找樹(BST)、平衡二叉樹(AVL)?
通過上面分析,可以使用樹作為 索引(解決了范圍、排序等問題),但是樹有很多種類,比如:二叉查找樹(BST)、平衡二叉樹(AVL)、B 樹、B+樹等,應該選擇哪種樹作為索引呢?
對于二叉查找樹,由于左子節點小于當前節點,右子節點大于當前節點,當一個資料是有序的時候,即資料要么遞增,要么遞減,此處二叉樹出現如下圖所示情況,相當于所有節點組成了鏈式結構,此時時間復雜度從 O(logn) 變為 O(n),隨著資料量增大,n 肯定非常大,這種情況下肯定不可取,舍棄,
二叉查找樹可參考:https://www.cnblogs.com/l-y-h/p/13751459.html#_label5_8
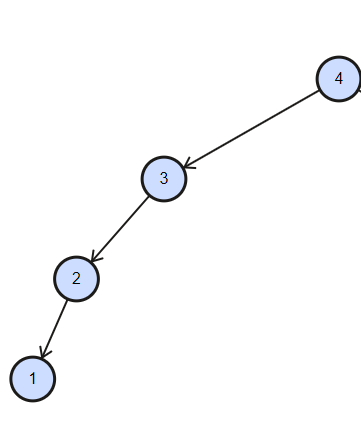
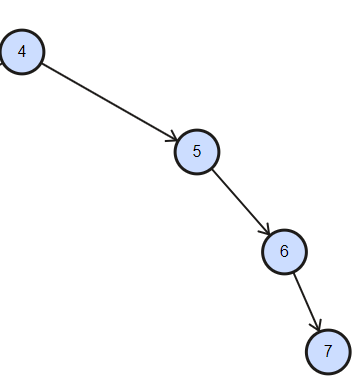
為了降低樹的高度,引出了 平衡二叉樹,其可以動態的維護樹的高度,使任意一個節點左右子樹高度差絕對值不大于 1,
對于平衡二叉查找樹(AVL),新增節點時,會不斷的調整節點位置以及樹的高度,但隨著資料量增大,樹的高度也會增大,高度增大導致比較次數增多,若資料 無法一次讀取到記憶體中,則每次比較前都得通過磁盤 IO 讀取外存資料,導致磁盤 IO 增大,影響性能,
二叉平衡樹可參考:https://www.cnblogs.com/l-y-h/p/13751459.html#_label5_9
通過上面分析,二叉查找樹可能出現 只有左子樹或者只有右子樹的情況,當 資料量過大時,樹的高度會變得很高,此時時間復雜度從 O(logn) 變為 O(n),n 為 樹的高度,
為了解決這種情況,可以使用平衡二叉查找樹,其會在左右子樹高度差大于 1 時對樹節點進行旋轉,保證樹之間的高度差,從而解決二叉查找樹的問題,但是資料量過大時,樹的高度依舊會很大,增大磁盤 IO,影響性能,
所以為了解決樹的高度問題,既然 二叉平衡樹 不能滿足需求,那就采用多叉平衡樹,讓一個節點保存多個資料(兩個以上子樹),進一步降低樹的高度,從而引出 B 樹、B+樹,
(4)AVL 樹、B樹、B+樹 舉例:
構建樹,并按照順序插入 1 - 10,若查找 10 這個數,需要比較幾次?
AVL 樹構建如下:
樹總高度為 4,而 10 在葉子節點,所以需要比較 4 次,
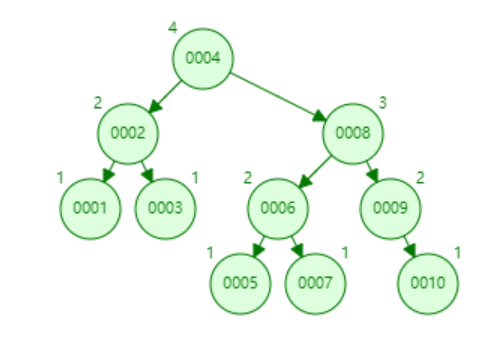
B 樹構建如下:
樹高度為 3 ,10 在葉子節點,此時只需要比較 3 次即可,
但對于 AVL,需要比較 4 次,隨著資料量增大,B 樹 明顯比 AVL 高度低,
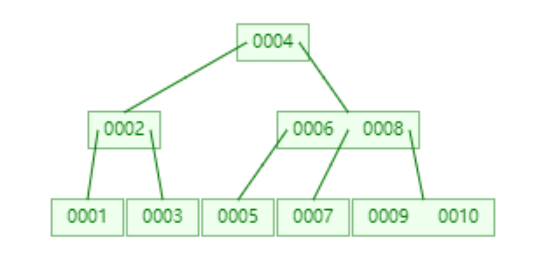
B+ 樹構建如下:
樹高度為 4,10 在葉子節點,此時需要比較 4 次,
B+ 樹比 B 樹更適合范圍查找,
(5)為什么不使用 B 樹 而使用 B+ 樹?
通過上面分析,可以知道 平衡二叉樹不能 滿足實際的需求(資料量大時,樹高度太大,且可能需要與磁盤進行多次 I/O 操作,查詢效率低),
那么 B 樹能否滿足需求呢?B 樹的定義參考前面的分析,
理論上,B 樹可以增加 每個節點保存的資料項 以及 節點的子節點數,并達到平衡樹的條件,從而降低樹的高度,但是不能無限制的 增大,B 樹階越大,那么每個節點 就可能成為 有序陣列,則每次查找時效率反而會降低,
在 InnoDB 中,索引是存盤元素的,一個表的資料 行數、列數 越多,那么相對應的索引檔案就會很大,其不可能一次存放在記憶體中,需要經過多次磁盤 I/O,所以考慮 資料結構時,需要判斷哪種資料結構更適合從磁盤中讀取資料,減少磁盤 I/O 次數,從而提高磁盤 I/O 效率,
假定每次讀取樹的節點 都是 一次 磁盤 I/O,那么樹的高度 將是決定 磁盤 I/O 的關鍵因素,
通過上面 AVL樹、B樹、B+樹 的舉例,可以看到 AVL 樹由于每個節點只能存盤兩個元素,資料量大時,樹的高度將會很大,
那么 B樹、B+樹 如何選擇呢?
B 樹由于 非葉子節點也會存放完整資料,則 B樹 每個非葉子節點 存放的 元素總數 受到資料的影響,也即 每個非葉子節點 存放的 元素 較少,從而導致樹的高度 也會很大,
B+ 樹由于 非葉子節點 不存放完整資料(存放主鍵 + 指標),其完整資料存放在 葉子節點中,也即 非葉子節點 可以存放 更多的 元素,從而樹的高度可以 很低,
通過上面分析,可以知道 B+ 樹的高度很低,可以減少磁盤 I/O 的次數,提高執行效率,且 B+ 樹所有葉子節點之間通過鏈表連接,其可以提高范圍查詢的效率,
所以 一般采用 B+ 樹作為索引結構,
(6)總結
使用 B+ 樹作為索引結構可以 減少磁盤 I/O 次數,提高查找效率,
B+ 樹實際應用場景一般高度為 3(見下面分析,若一條記錄為 1 KB,那么高度為 3 的 B+樹 可以存盤 2000 多萬條資料),
4、區域性原理、磁盤預讀、B+樹每個節點適合存多少資料
(1)區域性原理 與 磁盤預讀
區域性原理 指的是 當一個資料被使用時,那么其附近的資料通常也會被使用,
在 InnoDB 中,資料存盤在磁盤上,而直接操作磁盤 I/O 操作會很耗時(比操作記憶體中的資料慢),降低效率,
為了提高效率、降低磁盤 I/O 次數,在真正處理資料前 先要將資料 從磁盤中讀取并加載到 記憶體中,
若每次只從 磁盤 讀一條資料到 記憶體中,那么效率肯定很低,所以作業系統一般采用 磁盤預讀的形式,一次讀取 指定長度的資料進入記憶體(即使不需要使用到這么多資料,區域性原理),此處指定長度稱為 頁,是作業系統操作資料的基本單位,作業系統中 頁的大小一般為 4KB,
(2)B+樹中 一個節點存盤多少資料合適?
進行磁盤預讀時,將資料劃分成若干個頁,以 頁 作為 磁盤 與 記憶體 互動的基本單位,InnoDB 默認頁大小是 16 KB(類似于作業系統頁的定義,若作業系統頁大小為 4KB,那么 InnoDB 中 1頁 等于 作業系統 4頁),即每次最少從磁盤中讀取 16KB 資料到記憶體,最少從 記憶體寫入 16KB 資料到磁盤,
B+ 樹每個節點 存放 一頁、或者 頁的倍數比較合適,(假設每次讀取節點均會經過磁盤 I/O)
以一頁為例,如果節點存盤小于 一頁,那么讀取這個節點時仍然會讀出一頁,從而造成資源的浪費,而如果節點存盤大于 一頁小于二頁,那么讀取這個節點時將會讀出 二頁,同樣也會造成資源的浪費,所以,一般 B+樹 節點存放資料為 一頁 或者 頁的倍數,
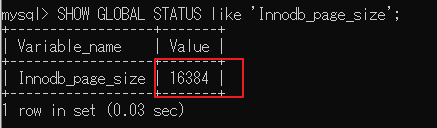
【查看 InnoDB 默認頁大小:】
SHOW GLOBAL STATUS like 'Innodb_page_size';
(3)為什么 InnoDB 設定默認頁大小為 16KB?而不是 32KB?
【首先明確一點:】 B+ 樹 非葉子節點存盤的是 主鍵(關鍵字)+ 指標(指向葉子節點), B+ 樹 葉子節點存盤的是 資料(真實的資料記錄), 假設每次讀取一個節點均會執行一次磁盤 I/O,即每個節點大小為頁的大小, 【以節點大小為 16KB 為例:】 假設一行資料大小為 1KB,那么一個葉子節點能保存 16 條記錄, 假設非葉子節點主鍵為 bigint 型別,那么長度為 8B,而指標在 InnoDB 中大小為 6B,即一個非葉子節點能保存 16KB / 14B = 1170 個資料(主鍵 + 指標), 那么對于 高度為 2 的 B+樹,能存盤記錄數為: 1170 * 16 = 18720 條, 對于 高度為 3 的 B+樹,能存盤記錄數為:1170 * 1170 * 16 = 21902400 條, 也就是說,若頁大小為 16KB,那么高度為 3 的 B+ 樹就能支持 2千萬的資料存盤, 當然若頁大小更大,樹的高度也會低,但是一般沒有必要去修改, 讀取一個節點需要經過一次磁盤 I/O,那么根據主鍵 只需要 1-3 次磁盤 I/O 即可查詢到資料,能滿足絕大部分需求,
5、MySQL 表存盤引擎 MyISAM 與 InnoDB 區別?
(1)MySQL 采用 插件式的表存盤引擎 管理資料,基于表而非基于資料庫,在 MySQL 5.5 版本前默認使用 MyISAM 為默認存盤引擎,在 5.5 版本后采用 InnoDB 作為默認存盤引擎,
(2)MyISAM 不支持外鍵、不支持事務,支持表級鎖(即每次操作均會對整個表加鎖,不適合高并發操作),會存盤表的總行數,占用表空間小,多用于 讀操作多 的場合,只快取索引但不快取真實資料,
(3)InnoDB 支持外鍵、支持事務,支持行級鎖,不存盤表的總行數,占用表空間大,多用于 寫操作多 的場合,快取索引的同時快取真實資料,對記憶體要求較高(記憶體大小影響性能),
(4)底層索引實作:
MyISAM 使用 B+樹作為 索引結構,但是其 索引檔案 與 資料檔案是 分開的,其葉子節點 存放的是 資料記錄的地址,也即根據索引檔案 找到 對應的資料記錄的地址后,再去獲取相應的資料,
InnoDB 使用 B+樹作為 索引結構,但是其 索引檔案本身就是 資料檔案,其葉子節點 存放的就是 完整的資料記錄,InnoDB 必須要有主鍵,如果沒有顯示指定,系統會默認選擇一個能夠唯一標識資料記錄的列作為主鍵,如果不存在這樣的鍵,系統會給表生成一個隱含欄位作為主鍵,
注:
InnoDB 中一般使用 自增的 id 作為主鍵,每插入一條記錄,相當于增加一個節點,如果主鍵是順序的,那么直接添加在上一個記錄后即可,若當前頁滿后,在新的頁中繼續存盤,
若主鍵無序,那么在插入資料的程序中,可能或出現在 所有葉子節點任意位置,若出現在所有葉子節點頭部,那么將會導致所有葉子節點均向后移一位,涉及到 頁的分裂以及資料的移動,是一種耗時操作、且造成大量記憶體碎片,影響效率,
6、索引的代價 與 選擇
(1)索引的代價:
空間上:
一個索引 對應一顆 B+ 樹,樹的每個節點都是一個資料頁,一個資料頁占用大小為 16KB 的存盤空間,資料量越大,占用的空間也就越大,
時間上:
索引會根據資料進行排序,當對資料表資料進行 增、刪、改 操作時,相應的 B+ 樹索引也要去維護,會消耗時間 進行 記錄移動、頁面分裂、頁面回收 等操作,并維護 資料有序,
(2)索引的選擇:
索引的選擇性:
指的是 不重復索引值(基數)與 表記錄總數 的比值(選擇性 = 不重復索引值 / 表記錄總數),
范圍為 (0, 1],選擇性 越大,即不重復索引值 越多,則建立索引的價值越大,
選擇性越小,即 重復索引值 越多,那么索引的意義不大,
索引選擇:
索引列 型別應盡量小,
主鍵自增,
三、圖
1、圖的基本介紹
(1)圖是什么?
圖用來描述 多對多關系 的一種資料結構,
上一篇介紹了 一對一 的資料結構(比如:單鏈表、佇列、堆疊等)以及 一對多的資料結構(比如:樹),參考鏈接:https://www.cnblogs.com/l-y-h/p/13751459.html ,
為了解決 多對多 關系,此處引入了 圖 這種資料結構,
(2)圖的基本概念
圖是一種資料結構,其每個節點可以具有 零個 或者 多個相鄰的元素,
兩個節點之間的連接稱為邊(edge),節點可稱為頂點(vertex),
從一個節點到另一個節點 所經過的邊稱為 路徑,
即 圖由若干個頂點以及 頂點之間的邊 組合而成,
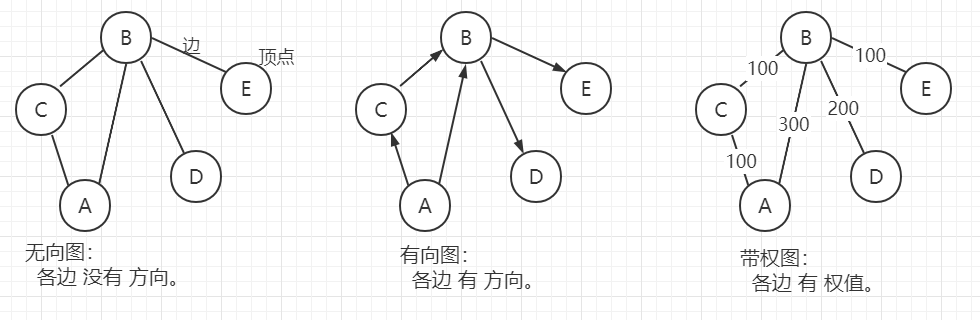
圖按照邊可以分為:
無向圖,指的是 頂點之間的連接(邊) 沒有方向的圖,
有向圖,指的是 邊 有方向的圖,
帶權圖,指的是 邊 帶有權值的圖,
(3)圖的表示方式
圖的表示形式一般有兩種:鄰接矩陣(二維陣串列示)、鄰接表(鏈表),
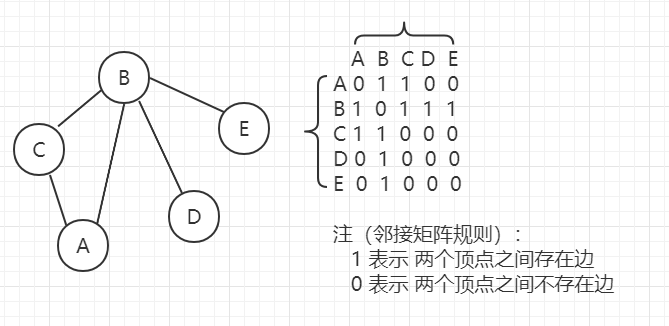
鄰接矩陣:
使用 一維陣列 記錄圖中 頂點資料,使用 二維陣列 記錄圖中 頂點之間的相鄰關系(邊),對于 n 個頂點的圖,使用 n*n 的二維陣列記錄 邊的關系,
鄰接表:
使用 陣列 + 鏈表的形式 記錄 各頂點 以及頂點之間的 相鄰關系(只記錄存在的邊),
使用 一維陣列 記錄圖中 頂點資料,使用鏈表記錄 存在的邊,
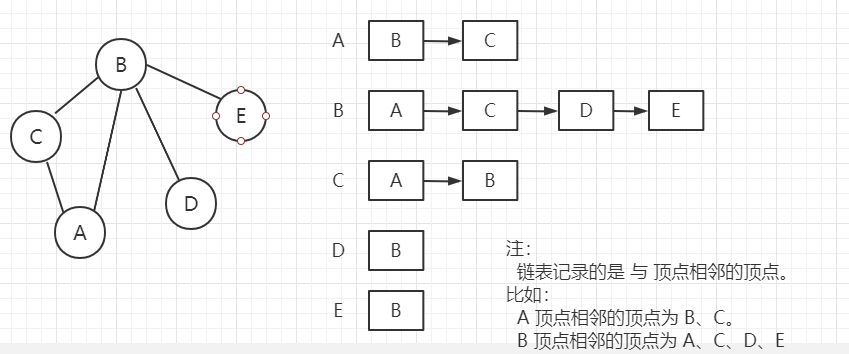
鄰接表 與 鄰接矩陣區別:
鄰接矩陣中 需要為 每個頂點 記錄 n 個邊,其中很多邊不存在(無需記錄),造成空間的浪費,
鄰接表只 記錄存在的邊,不會造成空間的浪費,
(4)使用 鄰接矩陣 形式構建 無向圖:
【構建思路:】 使用 一維陣列 記錄 圖的頂點資料, 使用 二維陣列 記錄 圖的各頂點的聯系(邊,其中 1 表示存在邊,0 表示不存在邊), 【代碼實作:】 package com.lyh.chart; import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * 使用 鄰接矩陣 形式構建無向圖 */ public class UndirectedGraph { private List<String> vertexs; // 用于保存 無向圖 的頂點資料(可以使用一維陣列) private int[][] edges; // 用于保存 無向圖 中各頂點之間的關系,1 表示兩頂點之間存在邊,0 表示不存在邊 private int numberOfEdges; // 用于記錄 無向圖中邊的個數 /** * 根據 頂點個數 進行初始化 * @param number 頂點個數 */ public UndirectedGraph(int number) { vertexs = new ArrayList<>(number); // 用于記錄頂點 edges = new int[number][number]; // 用于記錄頂點之間的關系 numberOfEdges = 0; // 用于記錄邊的個數 } /** * 添加頂點 * @param vertex 頂點 */ public void insertVertex(String vertex) { vertexs.add(vertex); } /** * 添加邊 * @param row 行 * @param column 列 * @param value 值(1 表示存在邊,0表示不存在邊) */ public void insertEdge(int row, int column, int value) { edges[row][column] = value; // 設定邊 edges[column][row] = value; // 設定邊,對稱 numberOfEdges++; // 邊總數加 1 } /** * 回傳邊的總數 * @return 邊的總數 */ public int getNumberOfEdges() { return numberOfEdges; } /** * 回傳頂點的總數 * @return 頂點總數 */ public int getNumberOfVertex() { return vertexs.size(); } /** * 回傳 下標對應的頂點資料 * @param index 頂點下標 * @return 頂點資料 */ public String getValueByIndex(int index) { return vertexs.get(index); } /** * 輸出鄰接矩陣 */ public void showGraph() { for (int[] row : edges) { System.out.println(Arrays.toString(row)); } } public static void main(String[] args) { // 初始化無向圖 UndirectedGraph undirectedGraph = new UndirectedGraph(5); // 插入頂點資料 String[] vertexs = new String[]{"A", "B", "C", "D", "E"}; for (String vertex : vertexs) { undirectedGraph.insertVertex(vertex); } // 插入邊 undirectedGraph.insertEdge(0, 1, 1); // A-B undirectedGraph.insertEdge(0, 2, 1); // A-C undirectedGraph.insertEdge(1, 2, 1); // B-C undirectedGraph.insertEdge(1, 3, 1); // B-D undirectedGraph.insertEdge(1, 4, 1); // B-E // 輸出 System.out.println("無向圖頂點總數為: " + undirectedGraph.getNumberOfVertex()); System.out.println("無向圖邊總數為: " + undirectedGraph.getNumberOfEdges()); System.out.println("無向圖第 3 個頂點為: " + undirectedGraph.getValueByIndex(2)); System.out.println("無向圖 鄰接矩陣為: "); undirectedGraph.showGraph(); } } 【輸出結果為:】 無向圖頂點總數為: 5 無向圖邊總數為: 5 無向圖第 3 個頂點為: C 無向圖 鄰接矩陣為: [0, 1, 1, 0, 0] [1, 0, 1, 1, 1] [1, 1, 0, 0, 0] [0, 1, 0, 0, 0] [0, 1, 0, 0, 0]
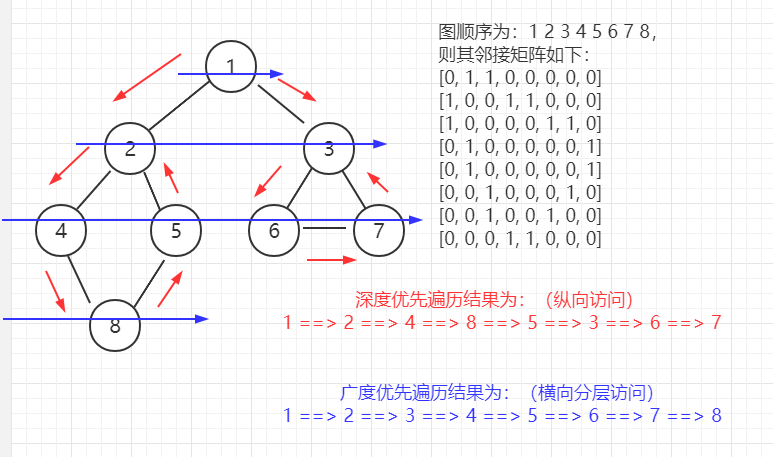
(5)圖的遍歷方式:
圖的遍歷,即對頂點的訪問,一般遍歷頂點有兩種策略:DFS、BFS,
DFS 為深度優先遍歷,可以聯想到 樹的 先序、中序、后序 遍歷,即 縱向訪問 節點,
BFS 為廣度優先遍歷,可以聯想到 樹的 順序(層序)遍歷,即 橫向分層 訪問 節點,
2、深度優先遍歷(DFS)
(1)DFS
DFS 指的是 Depth First Search,即 深度優先搜索,
其從一個節點出發,優先訪問該節點的第一個鄰接節點,并將此鄰接節點作為新的節點,繼續訪問其第一個鄰接節點(為了防止重復訪問同一節點,可以將節點分為 已訪問、未訪問 兩種狀態,若節點已訪問,則跳過該節點),
深度優先搜索是一個遞回的程序(可以使用堆疊模擬遞回實作),每次訪問當前節點的第一個鄰接節點,
(2)DFS 步驟 與 代碼實作:
【步驟:】 Step1:訪問初始節點 start,標記該節點 start 已訪問, Step2:查找節點 start 的第一個鄰接節點 neighbor, Step2.1:若 neighbor 不存在,則回傳 Step1,且從 start 下一個節點繼續執行, Step2.2:若 neighbor 存在,且未被訪問,則回傳 Step1,且將 neighbor 視為新的 start 執行, Step2.3:若 neighbor 存在,且已被訪問,則回傳 Step2,且從 neighbor 下一個節點繼續執行, 【舉例:】 圖的 鄰接矩陣表示如下:,圖各頂點 按照順序為 A B C D E, A B C D E A [0, 1, 1, 0, 0] B [1, 0, 1, 1, 1] C [1, 1, 0, 0, 0] D [0, 1, 0, 0, 0] E [0, 1, 0, 0, 0] 注: 1 表示兩個頂點間存在邊,0 表示不存在邊, 則遍歷程序如下:(整個程序是縱向的) Step1:從 A 開始遍歷,將 A 標記為 已訪問,找到 A 的 第一個鄰接節點 B, Step2:B 未被訪問,將 B 視為新的節點開始遍歷,將 B 標記為已訪問,找到 B 的第一個鄰接節點 A, Step3:A 被訪問過,繼續查找 B 下一個鄰接節點為 C, Step4:C 未被訪問過,將 C 視為新節點開始遍歷,將 C 標記為已訪問,找到 C 的第一個鄰接節點 A, Step5:A 被訪問,繼續查找 C 下一個鄰接節點為 B,B 也被訪問,繼續查找,C 沒有鄰接節點,回退到上一層 B, Step6:繼續查找 B 下一個鄰接節點為 D,將 D 標記已訪問,同理可知 D 沒有 未被訪問的鄰接頂點,回退到上一層 B, Step7:查找 B 下一個鄰接節點為 E,將 E 標記已訪問,至此遍歷完成, 即順序為:A -> B -> C -> D -> E 【代碼實作:】 package com.lyh.chart; import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * 使用 鄰接矩陣 形式構建無向圖 */ public class UndirectedGraph { private List<String> vertexs; // 用于保存 無向圖 的頂點資料(可以使用一維陣列) private int[][] edges; // 用于保存 無向圖 中各頂點之間的關系,1 表示兩頂點之間存在邊,0 表示不存在邊 private int numberOfEdges; // 用于記錄 無向圖中邊的個數 private boolean[] isVisit; // 用于記錄 頂點是否被訪問,true 表示已訪問 /** * 根據 頂點個數 進行初始化 * @param number 頂點個數 */ public UndirectedGraph(int number) { vertexs = new ArrayList<>(number); // 用于記錄頂點 edges = new int[number][number]; // 用于記錄頂點之間的關系 numberOfEdges = 0; // 用于記錄邊的個數 isVisit = new boolean[number]; // 用于記錄頂點是否被訪問 } /** * 添加頂點 * @param vertex 頂點 */ public void insertVertex(String vertex) { vertexs.add(vertex); } /** * 添加邊 * @param row 行 * @param column 列 * @param value 值(1 表示存在邊,0表示不存在邊) */ public void insertEdge(int row, int column, int value) { edges[row][column] = value; // 設定邊 edges[column][row] = value; // 設定邊,對稱 numberOfEdges++; // 邊總數加 1 } /** * 回傳邊的總數 * @return 邊的總數 */ public int getNumberOfEdges() { return numberOfEdges; } /** * 回傳頂點的總數 * @return 頂點總數 */ public int getNumberOfVertex() { return vertexs.size(); } /** * 回傳 下標對應的頂點資料 * @param index 頂點下標 * @return 頂點資料 */ public String getValueByIndex(int index) { return vertexs.get(index); } /** * 輸出鄰接矩陣 */ public void showGraph() { for (int[] row : edges) { System.out.println(Arrays.toString(row)); } } /** * 獲取下一個頂點的下標 * @param row 行 * @param column 列 * @return 下一個鄰接頂點的下標(-1 表示不存在下一個鄰接頂點) */ public int getNeighborVertexIndex(int row, int column) { for (int index = column + 1; index < vertexs.size(); index++) { if (edges[row][index] != 0) { return index; } } return -1; } /** * 回傳當前頂點 的第一個鄰接頂點的下標 * @param index 當前頂點下標 * @return 第一個鄰接頂點的下標(-1 表示不存在鄰接頂點) */ public int getFirstVertextIndex(int index) { return getNeighborVertexIndex(index, -1); } /** * 深度優先遍歷 */ public void dfs() { // 未被訪問的頂點,進行深度優先遍歷 for (int index = 0; index < vertexs.size(); index++) { if (!isVisit[index]) { dfs(index); } } } /** * 深度優先遍歷 * @param index 頂點下標 */ private void dfs(int index) { // 輸出當前頂點資料 System.out.print(getValueByIndex(index) + " ==> "); // 標記當前頂點為 已訪問 isVisit[index] = true; // 獲取當前頂點第一個鄰接頂點下標 int neighborIndex = getFirstVertextIndex(index); // 當下一個鄰接頂點存在時 while(neighborIndex != -1) { // 若鄰接頂點未被訪問,則遞回遍歷 if (!isVisit[neighborIndex]) { dfs(neighborIndex); } else { // 若鄰接頂點已被訪問,則訪問當前鄰接頂點的下一個鄰接頂點 neighborIndex = getNeighborVertexIndex(index, neighborIndex); } } } public static void main(String[] args) { // 初始化無向圖 UndirectedGraph undirectedGraph = new UndirectedGraph(5); // 插入頂點資料 String[] vertexs = new String[]{"A", "B", "C", "D", "E"}; for (String vertex : vertexs) { undirectedGraph.insertVertex(vertex); } // 插入邊 undirectedGraph.insertEdge(0, 1, 1); // A-B undirectedGraph.insertEdge(0, 2, 1); // A-C undirectedGraph.insertEdge(1, 2, 1); // B-C undirectedGraph.insertEdge(1, 3, 1); // B-D undirectedGraph.insertEdge(1, 4, 1); // B-E // 輸出 System.out.println("無向圖頂點總數為: " + undirectedGraph.getNumberOfVertex()); System.out.println("無向圖邊總數為: " + undirectedGraph.getNumberOfEdges()); System.out.println("無向圖第 3 個頂點為: " + undirectedGraph.getValueByIndex(2)); System.out.println("無向圖 鄰接矩陣為: "); undirectedGraph.showGraph(); System.out.println("深度優先遍歷結果為: "); undirectedGraph.dfs(); } } 【輸出結果:】 無向圖頂點總數為: 5 無向圖邊總數為: 5 無向圖第 3 個頂點為: C 無向圖 鄰接矩陣為: [0, 1, 1, 0, 0] [1, 0, 1, 1, 1] [1, 1, 0, 0, 0] [0, 1, 0, 0, 0] [0, 1, 0, 0, 0] 深度優先遍歷結果為: A ==> B ==> C ==> D ==> E ==>
3、廣度優先遍歷(BFS)
(1)BFS
BFS 指的是 Broad First Search,即廣度優先搜索,
其類似于 分層搜索的程序,依次訪問各層 的節點,可以使用佇列來記錄 訪問過的節點的順序,用于按照該順序來訪問 這些節點的鄰接節點,
(2)BFS 步驟、代碼實作
【步驟:】 Step1:訪問初始節點 start,并標記為 已訪問,start 入佇列, Step2:回圈取出佇列,若佇列為空,則結束回圈,否則執行下面步驟, Step3:取得佇列頭部節點,即為 first,并查找 first 的第一個鄰接節點 neighbor, Step3.1:若 neighbor 不存在,則回傳 Step2,再取出佇列 新的頭節點, Step3.2:若 neighbor 存在,且未被訪問,則將其標記為 已訪問并入佇列, Step3.3:若 neighbor 存在,且已被訪問,則回傳 Step3,并查找 neighbor 的下一個節點, 注: Step3 將某一層 未訪問的節點 入佇列,當該層頂點全部被訪問時,執行 Step2, 從佇列中取出 頭部節點,即為 新的層,并開始查找未被訪問的節點入佇列, 【舉例:】 圖的 鄰接矩陣表示如下:,圖各頂點 按照順序為 A B C D E, A B C D E A [0, 1, 1, 0, 0] B [1, 0, 1, 1, 1] C [1, 1, 0, 0, 0] D [0, 1, 0, 0, 0] E [0, 1, 0, 0, 0] 注: 1 表示兩個頂點間存在邊,0 表示不存在邊, 則遍歷程序如下:(整個程序是橫向分層的) Step1:從 A 開始,將其標記為 已訪問,將 A 存入佇列末尾, Step2:取出佇列頭部元素為 A,查找其鄰接節點為 B,B 未被訪問將其入佇列、并標記為 已訪問, Step3:繼續查找 A 下一個鄰接節點為 C,C 為被訪問將其入佇列、并標記為 已訪問, Step4:A 層遍歷結束,取出佇列頭部為元素為 B,即開始訪問 B 層, Step5:B 層未被訪問的節點 依次入佇列并標記為已訪問,即 D、E 入佇列, Step6:同理依次取出佇列頭部元素 C、D、E,直至遍歷完成, 即順序為:A -> B -> C -> D -> E 【代碼實作:】 package com.lyh.chart; import java.util.ArrayList; import java.util.Arrays; import java.util.LinkedList; import java.util.List; /** * 使用 鄰接矩陣 形式構建無向圖 */ public class UndirectedGraph { private List<String> vertexs; // 用于保存 無向圖 的頂點資料(可以使用一維陣列) private int[][] edges; // 用于保存 無向圖 中各頂點之間的關系,1 表示兩頂點之間存在邊,0 表示不存在邊 private int numberOfEdges; // 用于記錄 無向圖中邊的個數 private boolean[] isVisit; // 用于記錄 頂點是否被訪問,true 表示已訪問 /** * 根據 頂點個數 進行初始化 * @param number 頂點個數 */ public UndirectedGraph(int number) { vertexs = new ArrayList<>(number); // 用于記錄頂點 edges = new int[number][number]; // 用于記錄頂點之間的關系 numberOfEdges = 0; // 用于記錄邊的個數 isVisit = new boolean[number]; // 用于記錄頂點是否被訪問 } /** * 添加頂點 * @param vertex 頂點 */ public void insertVertex(String vertex) { vertexs.add(vertex); } /** * 添加邊 * @param row 行 * @param column 列 * @param value 值(1 表示存在邊,0表示不存在邊) */ public void insertEdge(int row, int column, int value) { edges[row][column] = value; // 設定邊 edges[column][row] = value; // 設定邊,對稱 numberOfEdges++; // 邊總數加 1 } /** * 回傳邊的總數 * @return 邊的總數 */ public int getNumberOfEdges() { return numberOfEdges; } /** * 回傳頂點的總數 * @return 頂點總數 */ public int getNumberOfVertex() { return vertexs.size(); } /** * 回傳 下標對應的頂點資料 * @param index 頂點下標 * @return 頂點資料 */ public String getValueByIndex(int index) { return vertexs.get(index); } /** * 輸出鄰接矩陣 */ public void showGraph() { for (int[] row : edges) { System.out.println(Arrays.toString(row)); } } /** * 獲取下一個頂點的下標 * @param row 行 * @param column 列 * @return 下一個鄰接頂點的下標(-1 表示不存在下一個鄰接頂點) */ public int getNeighborVertexIndex(int row, int column) { for (int index = column + 1; index < vertexs.size(); index++) { if (edges[row][index] != 0) { return index; } } return -1; } /** * 回傳當前頂點 的第一個鄰接頂點的下標 * @param index 當前頂點下標 * @return 第一個鄰接頂點的下標(-1 表示不存在鄰接頂點) */ public int getFirstVertextIndex(int index) { return getNeighborVertexIndex(index, -1); } /** * 廣度優先遍歷 */ public void bfs() { // 未被訪問的頂點,進行廣度優先遍歷 for (int index = 0; index < vertexs.size(); index++) { if (!isVisit[index]) { bfs(index); } } } /** * 廣度優先遍歷 * @param index 頂點下標 */ private void bfs(int index) { // 輸出當前頂點資料 System.out.print(getValueByIndex(index) + " ==> "); // 用于記錄訪問的頂點 LinkedList<Integer> queue = new LinkedList<>(); int firstIndex; // 用于記錄佇列的頭部節點 int neighborIndex; // 用于記錄鄰接節點 isVisit[index] = true; // 標記當前節點已被訪問 queue.addLast(index); // 當前節點入佇列 // 佇列不空時 while(!queue.isEmpty()) { // 取出佇列頭節點 firstIndex = queue.removeFirst(); // 找到鄰接節點 neighborIndex = getFirstVertextIndex(index); while(neighborIndex != -1) { if(!isVisit[neighborIndex]) { // 輸出當前頂點資料 System.out.print(getValueByIndex(neighborIndex) + " ==> "); isVisit[neighborIndex] = true; queue.addLast(neighborIndex); } else { neighborIndex = getNeighborVertexIndex(firstIndex, neighborIndex); } } } } public static void main(String[] args) { // 初始化無向圖 UndirectedGraph undirectedGraph = new UndirectedGraph(5); // 插入頂點資料 String[] vertexs = new String[]{"A", "B", "C", "D", "E"}; for (String vertex : vertexs) { undirectedGraph.insertVertex(vertex); } // 插入邊 undirectedGraph.insertEdge(0, 1, 1); // A-B undirectedGraph.insertEdge(0, 2, 1); // A-C undirectedGraph.insertEdge(1, 2, 1); // B-C undirectedGraph.insertEdge(1, 3, 1); // B-D undirectedGraph.insertEdge(1, 4, 1); // B-E // 輸出 System.out.println("無向圖頂點總數為: " + undirectedGraph.getNumberOfVertex()); System.out.println("無向圖邊總數為: " + undirectedGraph.getNumberOfEdges()); System.out.println("無向圖第 3 個頂點為: " + undirectedGraph.getValueByIndex(2)); System.out.println("無向圖 鄰接矩陣為: "); undirectedGraph.showGraph(); System.out.println("廣度優先遍歷結果為: "); undirectedGraph.bfs(); } } 【輸出結果:】 無向圖頂點總數為: 5 無向圖邊總數為: 5 無向圖第 3 個頂點為: C 無向圖 鄰接矩陣為: [0, 1, 1, 0, 0] [1, 0, 1, 1, 1] [1, 1, 0, 0, 0] [0, 1, 0, 0, 0] [0, 1, 0, 0, 0] 廣度優先遍歷結果為: A ==> B ==> C ==> D ==> E ==>
四、常用五種演算法
1、二分查找演算法(遞回與非遞回)
(1)二分查找
二分查找是一個效率較高的查找方法,其要求必須采用 順序存盤結構 且 存盤資料有序,
每次查找資料時 根據 待查找資料 將總資料 分為兩部分(一部分小于 待查找資料,一部分大于 待查找資料),設折半次數為 x,則 2^x = n,即折半次數為 x = logn,時間復雜度為 O(logn),
(2)遞回、非遞回實作 二分查找
【代碼實作:】 package com.lyh.algorithm; /** * 二分查找、遞回 與 非遞回 實作 */ public class BinarySearch { public static void main(String[] args) { // 構建升序序列 int[] arrays = new int[]{13, 27, 38, 49, 65, 76, 97}; // 設定待查找資料 int key = 27; // 遞回二分查找 int index = binarySearch(arrays, 0, arrays.length - 1, key); if (index != -1) { System.out.println("查找成功,下標為: " + index); } else { System.out.println("查找失敗"); } // 非遞回二分查找 int index2 = binarySearch2(arrays, 0, arrays.length - 1, key); if (index2 != -1) { System.out.println("查找成功,下標為: " + index2); } else { System.out.println("查找失敗"); } } /** * 折半查找,回傳元素下標(遞回查找,陣列升序) * @param arrays 待查找陣列 * @param left 最左側下標 * @param right 最右側下標 * @param key 待查找資料 * @return 查找失敗回傳 -1,查找成功回傳元素下標 0 ~ n */ public static int binarySearch(int[] arrays, int left, int right, int key) { if (left <= right) { // 獲取中間下標 int middle = (left + right) / 2; // 查找成功回傳資料 if (arrays[middle] == key) { return middle; } // 待查找資料 小于 中間資料,則從 左半部分資料進行查找 if (arrays[middle] > key) { return binarySearch(arrays, left, middle - 1, key); } // 待查找資料 大于 中間資料,則從 右半部分資料進行查找 if (arrays[middle] < key) { return binarySearch(arrays, middle + 1, right, key); } } return -1; } /** * 折半查找,回傳元素下標(非遞回查找,陣列升序) * @param arrays 待查找陣列 * @param left 最左側下標 * @param right 最右側下標 * @param key 待查找資料 * @return 查找失敗回傳 -1,查找成功回傳元素下標 0 ~ n */ public static int binarySearch2(int[] arrays, int left, int right, int key) { while(left <= right) { // 獲取中間下標 int middle = (left + right) / 2; // 查找成功回傳資料 if (arrays[middle] == key) { return middle; } // 待查找資料 小于 中間資料,則從 左半部分資料進行查找 if (arrays[middle] > key) { right = middle - 1; } else { // 待查找資料 大于 中間資料,則從 右半部分資料進行查找 left = middle + 1; } } return -1; } } 【輸出結果:】 查找成功,下標為: 1 查找成功,下標為: 1
2、分治演算法(漢諾塔問題)
(1)分治演算法:
分治法 簡單理解就是 分而治之,其將一個復雜的問題 分成 兩個或者 若干個 相同或者 類似的 子問題,子問題 又可進一步劃分為 若干個更小的子問題,直至 子問題可以很簡單的求解,然后將 所有簡單的子問題解合并,即可得到原問題的解,
【分治演算法常見實作:】
歸并排序、快速排序、漢諾塔問題等,
【分治演算法基本步驟:】
Step1:分解,將原問題 分解成 若干個 規模小、相互獨立、與原問題類似的 子問題,
Step2:求解,對于簡單的子問題直接求解,否則遞回求解各個子問題,
Step3:合并,將各個子問題的解合并為原問題的解,
(2)漢諾塔代碼實作
【漢諾塔問題:】 有 3 根柱子及 N 個不同大小的穿孔圓盤,盤子可以滑入任意一根柱子, 開始時所有盤子 按照自上而下按升序依次套在第一根柱子上(即每一個盤子只能放在更大的盤子上面), 將所有盤子 從 第一根柱子上 移動到 第三根柱子上, 移動圓盤時受到以下限制: 每次只能移動一個盤子; 盤子只能從柱子頂端滑出移到下一根柱子; 盤子只能疊在比它大的盤子上, 【漢諾塔分析:】 假設三個柱子分為為:A B C,盤子最開始放置在 A,需要從 A 將其移動到 C, 若只有一個盤子: 直接從 A 移動到 C, 若有 2 個盤子: 則先將第一個盤子從 A 移動到 B, 再將第二個盤子從 A 移動到 C, 最后再將 第一個盤子從 B 移動到 C, 若有 3 個盤子: 先將第 1 個盤子從 A 移動到 C 再將第 2個盤子從 A 移動到 B 再將第 1 個盤子從 C 移動到 B 再將第 3個盤子從 A 移動到 C 再將第 1 個盤子從 B 移動到 A 再將第 2個盤子從 B 移動到 C 最后第 1 個盤子從 A 移動到 C 同理,第 4、5...n 個盤子, 可以將 盤子分為兩部分,一部分為 最底下的盤子(最大的盤子),一部分為 其余盤子, 先將其余盤子從 A 移動到 B 柱子上,再將 最大盤子從 A 移動到 C 柱子上,最后將 其余盤子從 B 移動到 C 柱子上, 注: 由于其余盤子數量可能大于 2,所以需要遞回進行分治處理, 比如: 3 個盤子,原柱子為 A,目標柱子為 C,可借助中間柱子 B,將其視為 (A, B, C), 將盤子從上到下分為兩部分,第 1、2 個盤子為其余盤子,第 3 個盤子為最大盤子, 若其余盤子數量大于 2,又可以拆分成更小的盤子進行操作, 首先將 其余盤子 從 A 移動到 B,原柱子為 A,目標為 B,可借助中間柱子 C,將其視為 (A, C, B), 然后將 最大盤子 從 A 移動到 C,直接移動, 最后將 其余盤子 從 B 移動到 C,原柱子為 B,目標為 C,可借助中間柱子 A,將其視為 (B, A, C), 【代碼實作:】 package com.lyh.algorithm; import java.util.ArrayList; import java.util.List; public class HanoiTower { public static void main(String[] args) { // 列印漢諾塔盤子移動程序 hanoiTower(3, "A", "B", "C"); System.out.println("===========================\n"); // 列印漢諾塔結果 List<Integer> origin = new ArrayList<>(); origin.add(2); origin.add(1); origin.add(0); List<Integer> middle = new ArrayList<>(); List<Integer> target = new ArrayList<>(); System.out.println("原漢諾塔為: "); System.out.println("原柱子: " + origin); System.out.println("中間柱子: " + middle); System.out.println("目標柱子: " + target); hanoiTower(origin, middle, target); System.out.println("移動后的漢諾塔為: "); System.out.println("原柱子: " + origin); System.out.println("中間柱子: " + middle); System.out.println("目標柱子: " + target); } /** * 漢諾塔問題,將盤子從原始柱子 A 移動到 目標柱子 C,可借助中間柱子 B, * 列印出移動流程, * @param num 盤子總數 * @param a A 原始柱子 * @param b B 中間柱子 * @param c C 目標柱子 */ public static void hanoiTower(int num, String a, String b, String c) { // 只剩 1 個盤子時,直接從 A 移動到 C if (num == 1) { System.out.println("第 1 個盤子從 " + a + " 移動到 " + c); return; } // 盤子數 大于 2 時,將盤子視為兩個部分,一個為 最大的盤子,另一個為 其余盤子 // 先將其余盤子 移動到中間柱子上,即從 A 移動到 B,移動程序中使用到 C,此時 原始柱子為 A,目標柱子為 B,中間柱子為 C hanoiTower(num - 1, a, c, b); // 再將最大的盤子從 A 移動到 C System.out.println("第 " + num + "個盤子從 " + a + " 移動到 " + c); // 最后將其余盤子 從中間柱子移動到目標柱子上,即從 B 移動到 C,移動程序中使用到 A,此時 原始柱子為 B,目標柱子為 C,中間柱子為 A hanoiTower(num - 1, b, a, c); } /** * 將盤子從 origin 移動到 target * @param origin 原始柱子 * @param middle 中間柱子 * @param target 目標柱子 */ public static void hanoiTower(List<Integer> origin, List<Integer> middle, List<Integer> target) { move(origin.size(), origin, middle, target); } private static void move(int num, List<Integer> origin, List<Integer> middle, List<Integer> target) { // 只剩 1 個盤子時,直接從原始柱子 origin 移動到目標柱子 target if (num == 1) { target.add(origin.remove(origin.size() - 1)); return; } // 將 其余盤子從原始柱子 origin 移動到中間柱子 middle 上,此時可將 target 視為中間柱子 move(num - 1, origin, target, middle); // 將 最大盤子從原始柱子 origin 直接移動到 目標柱子 target 上, target.add(origin.remove(origin.size() - 1)); // 將 其余盤子從中間柱子 middle 移動到目標柱子 target 上,此時可將 origin 視為中間柱子 move(num - 1, middle, origin, target); } /** * 取巧思路,非演算法實作(博大家一笑) * @param origin 原柱子 * @param middle 中間柱子 * @param target 目標柱子 */ public static void hanoiTower2(List<Integer> origin, List<Integer> middle, List<Integer> target) { target.addAll(origin); origin.clear(); } } 【輸出結果:】 第 1 個盤子從 A 移動到 C 第 2個盤子從 A 移動到 B 第 1 個盤子從 C 移動到 B 第 3個盤子從 A 移動到 C 第 1 個盤子從 B 移動到 A 第 2個盤子從 B 移動到 C 第 1 個盤子從 A 移動到 C =========================== 原漢諾塔為: 原柱子: [2, 1, 0] 中間柱子: [] 目標柱子: [] 移動后的漢諾塔為: 原柱子: [] 中間柱子: [] 目標柱子: [2, 1, 0]
3、KMP 演算法(字串匹配問題)
(1)字串匹配問題
現有一個目標字串 A,一個待匹配字串(模式串) B,如何判斷 A 中是否存在 B 字串?
一般方法有兩種:
暴力匹配:一個一個字符進行匹配,
KMP 演算法:改進的字串匹配,核心是 跳過無用匹配,減少匹配次數,
(2)暴力匹配
【思路:】 假設當前目標字串 A 已經匹配到了 i 位置,待匹配字串 B 已匹配到了 j 位置, 則 如果字符匹配成功,即 A[i] == B[j],則進行下一個字符匹配,即 i++,j++, 如果字符匹配失敗,即 A[i] != B[j],則進行回溯,回到 A 開始匹配字符,并對下一個字符重新進行匹配,即 i = i - j + 1, j = 0, 注: 使用暴力匹配可能會 執行大量的回溯程序,造成時間的浪費, 時間復雜度為 O(n*m),n 為目標字串長度,m 為模式串長度, 【舉例:】 現有目標字串 ABDABC,待匹配字串為 ABC, 第一次匹配: ABDABC ABC 匹配失敗, 第二次匹配: ABDABC ABC 匹配失敗, 第三次匹配: ABDABC ABC 匹配失敗, 同理挨個字符向后匹配, 【代碼實作:】 package com.lyh.algorithm; /** * 字串匹配 */ public class StringMatch { public static void main(String[] args) { String target = "BBC ABCDAB ABCDABCDABDE"; String current = "ABCDABD"; System.out.println("直接呼叫 String 的 contains 方法結果為: " + contains(target, current)); System.out.println("暴力匹配,子字串第一次出現的下標為: " + forceMatch(target, current)); } /** * 暴力匹配 * @param a 目標字串 * @param b 待匹配字串 * @return 匹配失敗回傳 -1,否則回傳第一次出現的下標 */ public static int forceMatch(String a, String b) { char[] target = a.toCharArray(); // 將 目標字串 轉為 字符陣列 char[] current = b.toCharArray(); // 將 待匹配字串 轉為 字符陣列 // i 用于記錄 目標字串 當前匹配的下標,j 用于記錄 待匹配字串 當前匹配的下標 int i = 0, j = 0; // 挨個字符進行匹配 while (i < target.length && j < current.length) { // 匹配成功,則匹配下一個字符 if (target[i] == current[j]) { i++; j++; } else { // 匹配失敗,回退到開始字符的下一個位置重新進行匹配 i = i - j + 1; j = 0; } } // 當 j 為待匹配字串長度時,匹配成功 if (j == current.length) { return i - j; } return -1; } /** * 一個取巧的方法,直接呼叫 String 的 contains 方法進行匹配(無法回傳第一次出現的位置) * @param target 目標字串 * @param current 待匹配字串 * @return 匹配成功回傳 true */ public static boolean contains(String target, String current) { return target.contains(current); } } 【輸出結果:】 直接呼叫 String 的 contains 方法結果為: true 暴力匹配,子字串第一次出現的下標為: 15
(3)KMP 演算法
KMP 指的是 Knuth-Morris-Pratt,三個人名拼接而成,用于在一個文本串 S 中 查找一個模式串 P 出現的位置,
暴力匹配 是 挨個匹配 字符,而 KMP 是利用現有模式串資訊,跳過一些無用的匹配操作,省去大量回溯時間,即暴力匹配程序中,若匹配失敗,主串會發生回溯,而 KMP 演算法匹配失敗,主串不發生回溯,移動模式串去匹配,
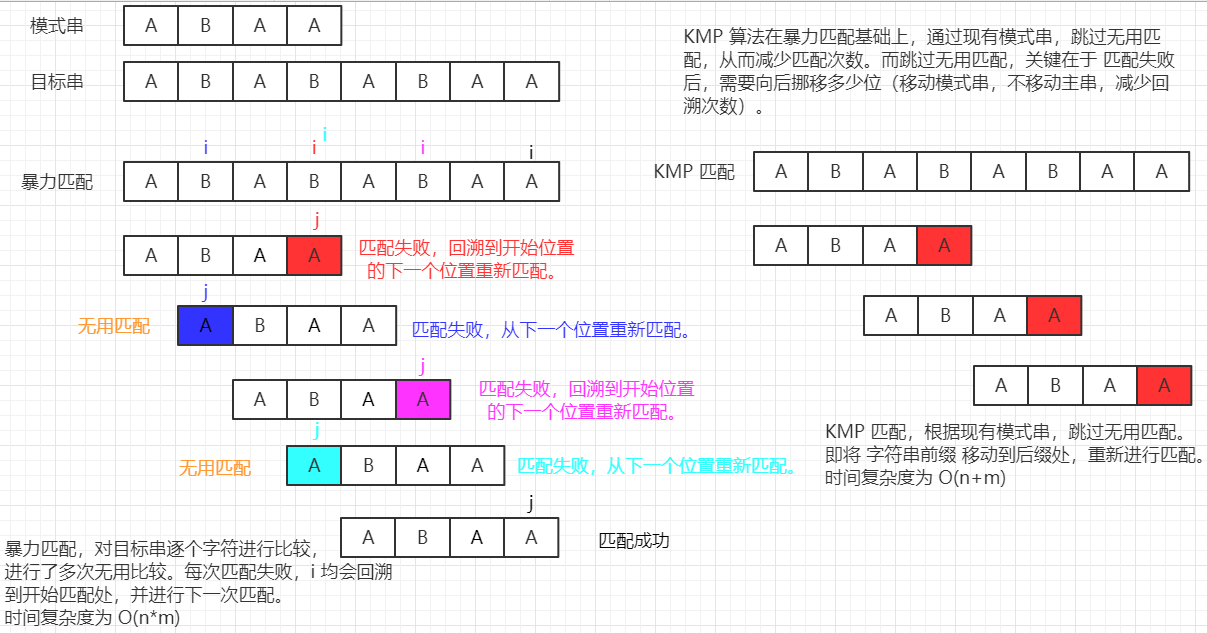
【KMP 核心:】 KMP 核心是通過 現有的模式串,跳過無用的匹配,減少回溯次數,從而提高匹配效率, KMP 演算法為了減少無用匹配,根據模式串前后綴關系,將模式串從前綴位置移動到與其相同的后綴位置,從而跳過一些無用匹配, 并根據前后綴關系,得到一個 next 陣列,用于記錄模式串下標 i 匹配失敗后,應該從 next[i] 處與當前主串重新開始比較, next[i] 存盤的是前 i 個字符(即 0 ~ i - 1)組成的字串中 最大相等前后綴的長度值, 相當于將模式串向后移動 i - next[i] 個位置(使前綴移動到后綴處),并與主串進行比較, 【推導程序:】 如何減少無用匹配(以主串:ABABABAA,模式串:ABAA 為例): 第一次匹配時: ABABABAA ABAA 發現 ABAB ABAA 前三個字符是一致的(ABA), 暴力匹配時,主串會回溯到開始字符的下一個位置進行比較,如下: ABABABAA ABAA 此時不匹配,繼續匹配 ABABABAA ABAA 可以發現,又出現了 ABAB ABAA 的情況,如果繼續暴力處理,那么會多出很多無用操作, 那么能否根據現有的 模式串,作出一些處理,從而跳過一些無用的操作呢? 這里先介紹一下 字串前綴、后綴(以字串 ABAA 為例): 前綴:{A, AB, ABA},含頭不含尾的子字串, 后綴:{BAA, AA, A},含尾不含頭的子字串, 通過觀察 ABAB ABAA 前三個字符 ABA,可以發現 ABA 前綴為 {A, AB},后綴為 {BA, A},其最大公共串為 {A}, 而在暴力匹配時可以發現 ABA 的相同前綴、后綴 中間的匹配操作 均為無用操作, 即下面匹配操作是無用操作,可以直接跳過, ABABABAA ABAA 即可以直接將 模式串 從前綴處 移動到 相同后綴處,并重新開始比較(劃重點), 那么能否 根據 模式串的 前、后綴 總結出一個規律呢?(以 ABAA 為例) 將 ABAA 按照位置關系視為 0 ~ 3 位(此處使用),當然也可以視為 1 ~ 4 位, 即 0 1 2 3 或者 0 1 2 3 4 A B A A A B A A 進行匹配時,若模式串第 0 位就匹配失敗,則模式串移動到 當前主串位置的下一個位置開始匹配: 即 主串: C B A A A 模式串: A B A A 模式串第 0 位匹配失敗后,下一次匹配時 模式串的第 0 位 從當前主串位置的下一個位置開始(當前主串位置下標為 0): 主串: C B A A A 模式串: A B A A 進行匹配時,若模式串第 1 位匹配失敗,且此時模式串 第 0 位(A)沒有 前綴、后綴,則模式串移動到 當前主串位置開始匹配, 即 主串: A C A A A 模式串: A B A A 模式串第 1 位匹配失敗后,下一次匹配時 模式串的第 0 位 從當前主串位置開始(當前主串下標為 1)比較, 主串: A C A A A 模式串: A B A A 進行匹配時,若模式串第 2 位匹配失敗,其此時模式串 第 0 ~ 1 位(AB)的 前綴、后綴 中沒有最大公共串,則模式串移動到 當前主串位置開始匹配, 即 主串: A B C A A 模式串:A B A A 模式串第 2 位匹配失敗后,下一次匹配時 模式串的第 0 位 從當前主串位置開始(當前主串下標為 2)比較, 主串: A B C A A 模式串: A B A A 進行匹配時,若模式串第 3 位匹配失敗,其此時模式串 第 0 ~ 2 位(ABA)的前綴、后綴 最大公共串為 1(A),則模式串移動到 當前主串位置開始匹配, 即 主串: A B A C A 模式串: A B A A 模式串第 3 位匹配失敗后,下一次匹配時 模式串的第 1 位 從當前主串位置開始(當前主串下標為 3)比較, 主串: A B A C A 模式串: A B A A 通過上面對模式串 ABAA 的分析, 當模式串第 0 位匹配失敗時,模式串需要移動 1 位,且主串需要向后移動 1 位,使得模式串下一次第 0 位 與 主串當前位置下一個位置開始比較,記此時為 -1, 當模式串第 1 位匹配失敗時,模式串前 0 位沒有最大公共前、后綴串,此時模式串向后移動 1 位,主串不移動,使得模式串下一次第 0 位 與 主串當前位置開始比較,記此時為 0, 當模式串第 2 位匹配失敗時,模式串前 1 位沒有最大公共前、后綴串,此時模式串向后移動 2 位,主串不移動,使得模式串下一次第 0 位 與 主串當前位置開始比較,記此時為 0, 當模式串第 3 位匹配失敗時,模式串前 2 位存在最大公共串且長度為 1,此時模式串向后移動 2 位,主串不移動,使得模式串下一次第 1 位 與 主串當前位置開始比較,記此時為 1, 可以得到一個規律, 模式串第 i 為匹配失敗時,模式串下一次匹配從 第 j 位開始與主串比較, 第 j 位指的是 模式串 第 0 ~ i-1 串的 最大前、后綴長度, 而模式串需要移動的位數則為: i - j,即將模式串前綴 移動到 最長公共 后綴處, 也即 KMP 中的 next 陣列(不同人定義的 next 可能有些許區別,但大體操作類似), next 陣列元素表示 當前模式串下標 匹配失敗后,下一次模式串中 需要與 主串進行匹配的 下標位置(即最長公共前、后綴的前綴的下一個位置), 而模式串需要移動的位數則為: i - next[i], 所以可以得到 ABAA 的 next 陣列如下: 0 1 2 3 模式串: A B A A next陣列: -1 0 0 1 移動位數: 1 1 2 2 如果將 ABAA 視為 1~4 位,則每次加 1 即可,即 第 j 位指的是 模式串 第 0 ~ i-1 串的 最大前、后綴長度 加 1, 0 1 2 3 4 模式串: A B A A next陣列: 0 1 1 2 移動位數: 1 1 2 2
(4)KMP 演算法的 next 陣列代碼實作(模式串自匹配)
【如何使用代碼實作 KMP 的 next 陣列:】 通過上面分析, next 陣列的求解是 KMP 關鍵之一,那么如何求解呢? 注意,此處的 next 每個元素表示的是 模式串當前元素下標 與 主串 匹配失敗后,下一次 模式串 開始匹配的下標值, 即 next[j] 表示 模式串下標為 j 的元素 與 主串匹配失敗后,下一次模式串 開始匹配的下標位置(即 0 ~ j-1 表示的 字串中 最長公共前、后綴的 前綴的下一個位置,也即最長前后綴長度), 可參考上述推導程序推理 next 的計算, 假設現在模式串 str 長度為 n, i 表示當前模式串下標(0 ~ n-1),j 表示最大前綴的下一個位置的下標, 由于模式串第 0 位前面沒有字符,此處設定為 next[0] = -1, 而模式串第 1 位前面有一個字符,但是沒有前、后綴,此處設定為 next[1]= 0, 所以 模式串只需從第 2 位開始計算,記初始 i = 2, j = 0,(i 永遠比 j 大) 強調一下: 此處 next[i] 指的是 前 i 個字符(即 0 ~ i - 1 所表示的字串)中最大相等前后綴長度, i - 1 表示當前最大相等后綴的下一個位置,j 表示當前最大相等前綴的下一個位置, 也就是說前 j 個(0 ~ j-1)字符是當前最大的相等前綴, 而 下標為 j 與 i - 1 所在字符 分別表示下一次需要比較的前綴 與 后綴,即比較 str[j] 與 str[i - 1] 是否相等即可, 若 str[j] == str[i - 1],那么最大相等前后綴長度又可以增加一位,此時 j++,i++, 若 str[j] != str[i - 1],則說明當前 0 ~ j 所表示的前綴 與 (i - j - 1) ~ (i - 1) 所表示的后綴不匹配,則需要從 0 ~ (j - 1) 所表示的前綴中 查找最大的前后綴 重新與 (i - j ) ~ (i - 1) 所表示的后綴匹配, 而 0 ~ (j - 1) 中最大前后綴長度即 next[j] 的值,所以此時 j = next[j],若 j 仍然不匹配,則繼續呼叫 j = next[j] 進行回退,直至 j 退回到模式串第 0 個位置, 注: 由于 next[0] 不存在前 0 位字串,所以定義其為 -1,表示當前模式串第 0 位與主串當前位置下一位開始比較, i 如果從 1 開始定義,則 j 初始值可以設定為 -1,i 為 1 時,下標為 0 的字符為待匹配的后綴,但是不存在前綴,可以假定前面有一位待匹配的前綴,假定下標為 -1, i 如果從 2 開始定義,則 j 初始值可以設定為 0,i 為 2 時,下標為 1 的字符為待匹配的后綴,下標為 0 為待匹配的前綴, 【代碼實作為:(next 陣列第一種寫法)】 /** * next 陣列第一種寫法, * KMP 實質上是根據字串前后綴的特點,將前綴字符移動到后綴位置,經過一系列推導根據 最大相等前后綴長度 得到一個 next 陣列, * * next 陣列存盤的是 當前模式串匹配失敗后,下一次與主串匹配的模式串的下標值(也可以理解為 模式串根據前后綴關系需要移動的位置), * 即 next[j] 表示的是 模式串中下標為 j 的元素與主串匹配失敗后,下一次從 模式串中下標為 next[j] 的元素開始與 主串匹配, * 也即相當于將 模式串移動 j - next[j] 個位置,然后重新與主串進行匹配, * 而 next[j] 實際存盤的 模式串 前 j 個字符 最大的相等的 前后綴的長度, * * 比如: * 模式串為 ABAA * 則其 next[3] 存盤的是 ABA 的最大相等前后綴的長度,即 next[3] = 1. * * 注(以 ABAA 為例): * 字串前綴為其 含頭不含尾的 子字串,比如:ABA 前綴為 {A, AB}. * 字串后綴為其 含尾不含頭的 子字串,比如:ABA 前綴為 {BA, A}. * 記 next[0] = -1,next[1] = 0,均表示模式串向后挪一個位置(j - next[j]), * next[0] 表示前 0 位字串(不存在),記為 -1. * next[1] 表示前 1 位字串(即 A 沒有前后綴),記為 0. * next[2] 表示前 2 位字串(即 AB,沒有最大相等的前后綴),記為 0. * next[3] 表示前 3 位字串(即 ABA,最大相等前后綴為 A,長度為 1),記為 1. * * @param pattern 模式串 * @return next 陣列 */ private static int[] getNext(String pattern) { // 用于保存 next 陣列 int[] next = new int[pattern.length()]; // 規定模式串第 0 位匹配失敗后,下一次模式串第 0 位與 主串當前位置下一個位置 進行匹配,記此時為 -1 next[0] = -1; // 模式串第 1 位匹配失敗后,下一次模式串第 0 位與 主串當前位置進行匹配,記此時為 0 next[1] = 0; // 遍歷模式串,依次得到 模式串 第 i 位匹配失敗后,下一次模式串需要從第 next[i] 位開始與主串進行匹配 // i 表示模式串當前下標,j 表示模式串最大相等前后綴的 前綴的下一個位置的下標 // i >= 2 時,模式串前 2 個字符才存在 前后綴,此時 next 求解才有意義 for (int i = 2, j = 0; i < pattern.length(); i++) { // 模式串自匹配,為了求解 next[i],需在模式串前 i 個元素中找到 最大前后綴 // j 表示的是當前最大前綴的下標,i-1 表示的是最大后綴的下標,若兩者所在字符不匹配,則需要找到更小的前綴進行匹配,也即 j 需要回退 // 而 j 所在下標表示 0 ~ j-1 之前屬于最長前綴,現在需要從 0~j-1 中找到新的最長前綴,而 next[j] 保存的正好是該值, // 所以在此推出 j = next[j] while(j > 0 && pattern.charAt(i - 1) != pattern.charAt(j)) { j = next[j]; } // 如果匹配,則說明當前最大前綴又可以增加一位,j 表示最長前綴的下一個位置(也即前綴長度),即 j++ if (pattern.charAt(i - 1) == pattern.charAt(j)) { j++; } // 保存模式串下標為 i 匹配失敗后,下一次從模式串開始匹配的下標位置 next[i] = j; } return next; } 【舉例:】 A B C D A B C E F next[0] = -1, next[1] = 1. i = 2 時,j = 0,此時 str[i - 1] != str[j],即 next[2] = 0. i = 3 時,j = 0,此時 str[i - 1] != str[j],即 next[3] = 0. i = 4 時,j = 0,此時 str[i - 1] != str[j],即 next[4] = 0. i = 5 時,j = 0,此時 str[i - 1] == str[j],則 j++,即 next[5] = 1. i = 6 時,j = 1,此時 str[i - 1] == str[j],則 j++,即 next[6] = 2. i = 7 時,j = 2,此時 str[i - 1] == str[j],則 j++,即 next[7] = 3. i = 8 時,j = 3,此時 str[i - 1] != str[j],則 j = next[j] = 0 即 next[8] = 0. 【代碼實作為:(next 陣列第二種寫法)】 /** * next 陣列第二種寫法, * 上面第一種解法是 每次計算 前 i 個字符(i 從 2 開始, j 從 0 開始)的模式串的最大相等前后綴,并將最大前綴下標的下一個位置賦值給 next[i], * 而第二種解法是,每次計算 前 i + 1 個字符(i 從 1 開始,j 從 -1 開始)的模式串的最大相等前后綴,并將其值賦值給 next[i+1], * 雖然寫法稍有不同,但是原理都是類似的, * @param pattern 模式串 * @return next 陣列 */ private static int[] getNext2(String pattern) { // 用于保存 next 陣列 int[] next = new int[pattern.length()]; // 規定模式串第 0 位匹配失敗后,下一次模式串第 0 位與 主串當前位置下一個位置 進行匹配,記此時為 -1 next[0] = -1; // i 表示模式串下標, j 表示最長前綴下一個位置的下標 int i = 0, j = -1; // 遍歷求解 next 陣列 while(i < pattern.length() - 1) { // 計算出模式串以當前下標為后綴的 最大相等前后綴長度,并將其值賦給 下一個 next, // 也即相當于 next[i] 保存的時 前 i 個字符(0 ~ i-1) 的最大前后綴長度 if (j == -1 || pattern.charAt(i) == pattern.charAt(j)) { next[++i] = ++j; } else { j = next[j]; } } return next; }


(5)改進的 KMP 演算法(改進 next 陣列求解)
【改進的 next 陣列求解:】 next 陣列求解優化,即改進的 KMP 演算法, 與 第二個求解 next 陣列方式類似,區別在于 j 回退位置, 比如: 主串 ABACABAA 模式串 ABAB 由于模式串最后一個字符匹配失敗,按照之前的 next 陣列求法,得到 ABAA 的 next 陣列為 [-1, 0, 0, 1], 則此時下一次匹配如下: 主串 ABACABAA 模式串 ABAB 可以很明顯的看到此時的匹配無效,與上次匹配失敗的字符相同, 此時應該直接一步到位,省去這次無用匹配,也即 模式串下標為 j 的字符回退時 若遇到相同的 字符,應該繼續回退, 即第一次匹配失敗后,直接進行如下匹配: 主串 ABACABAA 模式串 ABAB 即 模式串下標為 j 與 next[j] 字符相同時,應該繼續求解 next[next[j]] 的值, 比如: 模式串: ABAB,可以得到 next 陣列為 [-1, 0, 0, 1] 下標為 0 匹配失敗時,初值為 -1,固定不變, 下標為 1 匹配失敗時,下標為 1 的字符為 B、下標為 next[1] 的字符為 A,字符并不同,所以 next[1] = 0,與原 next 求解相同, 下標為 2 匹配失敗時,下標為 2 的字符為 A、下標為 next[2] 的字符為 A,字符相同,所以 next[2] = next[next[2]] = next[0] = -1. 下標為 3 匹配失敗時,下標為 3 的字符為 B,下標為 next[3] 的字符為 B,字符相同,所以 next[3] = next[next[3]] = next[1] = 0. 即改進后的 ABAB 得到的 next 陣列為 [-1, 0, -1, 0], 此時再次匹配: 主串 ABACABAA 模式串 ABAB 則下一次匹配為(跳過了無用的匹配): 主串 ABACABAA 模式串 ABAB 【代碼實作:】 /** * next 陣列求解優化,即改進的 KMP 演算法, * 與 第二個求解 next 陣列方式類似,區別在于 j 回退位置, * 比如: * 主串 ABACABAA * 模式串 ABAB * 由于模式串最后一個字符匹配失敗,按照之前的 next 陣列求法,得到 ABAA 的 next 陣列為 [-1, 0, 0, 1], * 則此時下一次匹配如下: * 主串 ABACABAA * 模式串 ABAB * 可以很明顯的看到此時的匹配無效,與上次匹配失敗的字符相同, * 此時應該直接一步到位,省去這次無用匹配,也即 模式串下標為 j 的字符回退時 若遇到相同的 字符,應該繼續回退, * * 即 模式串下標為 j 與 next[j] 字符相同時,應該繼續求解 next[next[j]] 的值, * 比如: * 模式串: ABAB,可以得到 next 陣列為 [-1, 0, 0, 1] * 下標為 0 匹配失敗時,初值為 -1,固定不變, * 下標為 1 匹配失敗時,下標為 1 的字符為 B、下標為 next[1] 的字符為 A,字符并不同,所以 next[1] = 0,與原 next 求解相同, * 下標為 2 匹配失敗時,下標為 2 的字符為 A、下標為 next[2] 的字符為 A,字符相同,所以 next[2] = next[next[2]] = next[0] = -1. * 下標為 3 匹配失敗時,下標為 3 的字符為 B,下標為 next[3] 的字符為 B,字符相同,所以 next[3] = next[next[3]] = next[1] = 0. * 即改進后的 ABAB 得到的 next 陣列為 [-1, 0, -1, 0], * * 此時再次匹配: * 主串 ABACABAA * 模式串 ABAB * 則下一次匹配為(跳過了無用的匹配): * 主串 ABACABAA * 模式串 ABAB * * @param pattern 模式串 * @return next 陣列 */ private static int[] getNext3(String pattern) { int[] next = new int[pattern.length()]; next[0] = -1; int i = 0, j = -1; while(i < pattern.length() - 1) { if (j == -1 || pattern.charAt(i) == pattern.charAt(j)) { // next[++i] = ++j; if (pattern.charAt(++i) == pattern.charAt(++j)) { next[i] = next[j]; } else { next[i] = j; } } else { j = next[j]; } } return next; }
(6)完整的 KMP 演算法如下:
包括兩種求解 next 陣列的方式,以及 next 陣列優化后的方式,以及 kmp 根據 next 陣列進行匹配,
【代碼實作:】 package com.lyh.algorithm; import java.util.Arrays; /** * 字串匹配 */ public class StringMatch2 { public static void main(String[] args) { String target = "BBC ABCDAB ABCDABCDABDE"; String pattern = "ABCDABD"; System.out.println(Arrays.toString(getNext("ABAB"))); System.out.println(Arrays.toString(getNext("ABCDABCEF"))); System.out.println(Arrays.toString(getNext2("ABAB"))); System.out.println(Arrays.toString(getNext2("ABCDABCDEF"))); System.out.println(Arrays.toString(getNext3("ABAB"))); System.out.println(Arrays.toString(getNext3("ABCDABCDEF"))); System.out.println(kmp(target, pattern)); } /** * KMP 演算法,根據模式串生成 next 陣列,減少無用匹配次數, * @param target 主串 * @param pattern 模式串 * @return 匹配失敗回傳 -1,否則回傳相應的下標 */ public static int kmp(String target, String pattern) { // 獲取 next 陣列,用于模式串匹配失敗后,下一次與主串匹配的位置, int[] next = getNext(pattern); int i = 0, j = 0; // 開始匹配 // i 表示主串所處下標,j 表示模式串所處下標(j 同時也表示的是最長前綴的下一個位置) while (i < target.length() && j < pattern.length()) { // j == -1 表示下一次模式串 第 -1 位 與 當前主串位置進行比較,也即下一次 為模式串第 0 位 與 當前主串位置下一位置進行比較, 所以 i++,j++ // target.charAt(i) == pattern.charAt(j) 表示模式串下標為 j 的字符與 主串匹配,也即當前 模式串 0~j 均可以作為最長前綴, // 也即下一次 模式串從下標為 j + 1 處 與 主串下一個位置開始比較,所以 i++,j++, if (j == -1 || target.charAt(i) == pattern.charAt(j)) { i++; j++; } else { // 此時屬于 target.charAt(i) != pattern.charAt(j) 的情況,模式串需要進行回退, // next[j] 表示的是模式串下標為 j 的字符匹配失敗后,下一次模式串中 應該與 主串當前位置進行 匹配的字符下標 j = next[j]; } } // 匹配成功 if (j == pattern.length()) { return i - j; } // 匹配失敗 return -1; } /** * next 陣列第一種寫法, * KMP 實質上是根據字串前后綴的特點,將前綴字符移動到后綴位置,經過一系列推導根據 最大相等前后綴長度 得到一個 next 陣列, * * next 陣列存盤的是 當前模式串匹配失敗后,下一次與主串匹配的模式串的下標值(也可以理解為 模式串根據前后綴關系需要移動的位置), * 即 next[j] 表示的是 模式串中下標為 j 的元素與主串匹配失敗后,下一次從 模式串中下標為 next[j] 的元素開始與 主串匹配, * 也即相當于將 模式串移動 j - next[j] 個位置,然后重新與主串進行匹配, * 而 next[j] 實際存盤的 模式串 前 j 個字符 最大的相等的 前后綴的長度, * * 比如: * 模式串為 ABAA * 則其 next[3] 存盤的是 ABA 的最大相等前后綴的長度,即 next[3] = 1. * * 注(以 ABAA 為例): * 字串前綴為其 含頭不含尾的 子字串,比如:ABA 前綴為 {A, AB}. * 字串后綴為其 含尾不含頭的 子字串,比如:ABA 前綴為 {BA, A}. * 記 next[0] = -1,next[1] = 0,均表示模式串向后挪一個位置(j - next[j]), * next[0] 表示前 0 位字串(不存在),記為 -1. * next[1] 表示前 1 位字串(即 A 沒有前后綴),記為 0. * next[2] 表示前 2 位字串(即 AB,沒有最大相等的前后綴),記為 0. * next[3] 表示前 3 位字串(即 ABA,最大相等前后綴為 A,長度為 1),記為 1. * * @param pattern 模式串 * @return next 陣列 */ private static int[] getNext(String pattern) { // 用于保存 next 陣列 int[] next = new int[pattern.length()]; // 規定模式串第 0 位匹配失敗后,下一次模式串第 0 位與 主串當前位置下一個位置 進行匹配,記此時為 -1 next[0] = -1; // 模式串第 1 位匹配失敗后,下一次模式串第 0 位與 主串當前位置進行匹配,記此時為 0 next[1] = 0; // 遍歷模式串,依次得到 模式串 第 i 位匹配失敗后,下一次模式串需要從第 next[i] 位開始與主串進行匹配 // i 表示模式串當前下標,j 表示模式串最大相等前后綴的 前綴的下一個位置的下標 // i >= 2 時,模式串前 2 個字符才存在 前后綴,此時 next 求解才有意義 for (int i = 2, j = 0; i < pattern.length(); i++) { // 模式串自匹配,為了求解 next[i],需在模式串前 i 個元素中找到 最大前后綴 // j 表示的是當前最大前綴的下標,i-1 表示的是最大后綴的下標,若兩者所在字符不匹配,則需要找到更小的前綴進行匹配,也即 j 需要回退 // 而 j 所在下標表示 0 ~ j-1 之前屬于最長前綴,現在需要從 0~j-1 中找到新的最長前綴,而 next[j] 保存的正好是該值, // 所以在此推出 j = next[j] while(j > 0 && pattern.charAt(i - 1) != pattern.charAt(j)) { j = next[j]; } // 如果匹配,則說明當前最大前綴又可以增加一位,j 表示最長前綴的下一個位置(也即前綴長度),即 j++ if (pattern.charAt(i - 1) == pattern.charAt(j)) { j++; } // 保存模式串下標為 i 匹配失敗后,下一次從模式串開始匹配的下標位置 next[i] = j; } return next; } /** * next 陣列第二種寫法, * 上面第一種解法是 每次計算 前 i 個字符(i 從 2 開始, j 從 0 開始)的模式串的最大相等前后綴,并將最大前綴下標的下一個位置賦值給 next[i], * 而第二種解法是,每次計算 前 i + 1 個字符(i 從 1 開始,j 從 -1 開始)的模式串的最大相等前后綴,并將其值賦值給 next[i+1], * 雖然寫法稍有不同,但是原理都是類似的, * @param pattern 模式串 * @return next 陣列 */ private static int[] getNext2(String pattern) { // 用于保存 next 陣列 int[] next = new int[pattern.length()]; // 規定模式串第 0 位匹配失敗后,下一次模式串第 0 位與 主串當前位置下一個位置 進行匹配,記此時為 -1 next[0] = -1; // i 表示模式串下標, j 表示最長前綴下一個位置的下標 int i = 0, j = -1; // 遍歷求解 next 陣列 while(i < pattern.length() - 1) { // 計算出模式串以當前下標為后綴的 最大相等前后綴長度,并將其值賦給 下一個 next, // 也即相當于 next[i] 保存的時 前 i 個字符(0 ~ i-1) 的最大前后綴長度 if (j == -1 || pattern.charAt(i) == pattern.charAt(j)) { next[++i] = ++j; } else { j = next[j]; } } return next; } /** * next 陣列求解優化,即改進的 KMP 演算法, * 與 第二個求解 next 陣列方式類似,區別在于 j 回退位置, * 比如: * 主串 ABACABAA * 模式串 ABAB * 由于模式串最后一個字符匹配失敗,按照之前的 next 陣列求法,得到 ABAA 的 next 陣列為 [-1, 0, 0, 1], * 則此時下一次匹配如下: * 主串 ABACABAA * 模式串 ABAB * 可以很明顯的看到此時的匹配無效,與上次匹配失敗的字符相同, * 此時應該直接一步到位,省去這次無用匹配,也即 模式串下標為 j 的字符回退時 若遇到相同的 字符,應該繼續回退, * * 即 模式串下標為 j 與 next[j] 字符相同時,應該繼續求解 next[next[j]] 的值, * 比如: * 模式串: ABAB,可以得到 next 陣列為 [-1, 0, 0, 1] * 下標為 0 匹配失敗時,初值為 -1,固定不變, * 下標為 1 匹配失敗時,下標為 1 的字符為 B、下標為 next[1] 的字符為 A,字符并不同,所以 next[1] = 0,與原 next 求解相同, * 下標為 2 匹配失敗時,下標為 2 的字符為 A、下標為 next[2] 的字符為 A,字符相同,所以 next[2] = next[next[2]] = next[0] = -1. * 下標為 3 匹配失敗時,下標為 3 的字符為 B,下標為 next[3] 的字符為 B,字符相同,所以 next[3] = next[next[3]] = next[1] = 0. * 即改進后的 ABAB 得到的 next 陣列為 [-1, 0, -1, 0], * * 此時再次匹配: * 主串 ABACABAA * 模式串 ABAB * 則下一次匹配為(跳過了無用的匹配): * 主串 ABACABAA * 模式串 ABAB * * @param pattern 模式串 * @return next 陣列 */ private static int[] getNext3(String pattern) { int[] next = new int[pattern.length()]; next[0] = -1; int i = 0, j = -1; while(i < pattern.length() - 1) { if (j == -1 || pattern.charAt(i) == pattern.charAt(j)) { // next[++i] = ++j; if (pattern.charAt(++i) == pattern.charAt(++j)) { next[i] = next[j]; } else { next[i] = j; } } else { j = next[j]; } } return next; } } 【輸出結果:】 [-1, 0, 0, 1] [-1, 0, 0, 0, 0, 1, 2, 3, 0] [-1, 0, 0, 1] [-1, 0, 0, 0, 0, 1, 2, 3, 4, 0] [-1, 0, -1, 0] [-1, 0, 0, 0, -1, 0, 0, 0, 4, 0] 15
4、貪心演算法(集合覆寫問題)
(1)貪心演算法
貪心演算法 指的是 在對問題求解時,可以將問題簡化成 若干類似的小問題,其每次解決小問題 的方式均是 當前情況下的最優選擇(即 區域最優),最終得到原問題的最優解,
注:
貪心演算法其雖然每一步都能保證最優解,但是其最終結果并不一定是最優的(接近最優解的結果),
(2)集合覆寫問題
【問題:】 現有 K1 - K5 五輛公交車,其能經過的站臺(A - H)如下所示: 公交車 站臺 K1 "A", "B", "C" K2 "D", "A", "E" K3 "F", "B", "G" K4 "B", "C" K5 "G", "H" 如何選擇最少的 公交車,能經過所有的公交站臺, 【思路:】 窮舉法 不切實際,肯定不能采取, 可以使用貪心演算法,每次選擇 當前覆寫最多公交站 的公交,可以快速選擇到所有公交站臺, 貪心法步驟: Step1:首先獲取到所有的公交站臺資訊 allStation, Step2:遍歷所有公交車,根據公交車 站臺資訊 與 allStation 比較,從中找到一個 覆寫最多公交站 的公交, 記錄此時的公交車,并將當前公交車經過的 站臺 從 allStation 中去除, Step3:重復 Step2,直至 allStation 為空,也即經過所有公交站臺 最少公交車 已經找到, 【舉例分析:】 Step1:首先獲取到所有公交站臺資訊,allStation = ["A", "B", "C", "D", "E", "F", "G", "H"]; Step2:遍歷 K1 - K5 公交車,發現 K1、K2、K3 均能覆寫 3 個站臺,K4、K5 能覆寫 2 個站臺, 按照順序,先記錄 K1 公交車,并去除 allStation 中相應的站臺,此時 allStation = ["D", "E", "F", "G", "H"]; Step3:再次遍歷 K1 - K5(跳過 K1 亦可),此時 K2、K3、K5 能覆寫 2 個站臺,K1、K4 能覆寫 1 個站臺, 按照順序,先記錄 K2 公交車,并去除 allStation 中相應的站臺,此時 allStation = ["F", "G", "H"]; Step4:再次遍歷 K1 - K5,此時 K3、K5 能覆寫 2 個站臺,K1、K2、K4 能覆寫 1 個站臺, 按照順序,先記錄 K3 公交車,并去除 allStation 中相應的站臺,此時 allStation = ["H"]; Step5:再次遍歷 K1 - K5,此時 K5 能覆寫 1 個站臺,K1 - K4 能覆寫 0 個站臺, 記錄 K5,并去除 allStation 中相應的站臺,此時 allStation = []; Step6:allStation 為空,即所有公交站臺均可訪問,此時公交為 [K1, K2, K3, K5] 注: 若第一次選擇的并非 K1,而是 K2,則可能的結果為:[K2, k3, K5, K4]. 可以發現,可能存在多個解,即 貪心法得到的結果不一定是最優解,但一定近似最優解, 【代碼實作:】 package com.lyh.algorithm; import java.util.ArrayList; import java.util.HashMap; import java.util.HashSet; import java.util.List; public class Greedy { public static void main(String[] args) { greedy(); } /** * 貪心演算法求解 集合覆寫問題, * 每次選取當前情況下的最優解,從而最終得到結果(結果不一定為最優解,但是近似最優解) */ public static void greedy() { // 設定公交經過的站臺 HashSet<String> k1 = new HashSet<>(); k1.add("A"); k1.add("B"); k1.add("C"); HashSet<String> k2 = new HashSet<>(); k2.add("D"); k2.add("A"); k2.add("E"); HashSet<String> k3 = new HashSet<>(); k3.add("F"); k3.add("B"); k3.add("G"); HashSet<String> k4 = new HashSet<>(); k4.add("B"); k4.add("C"); HashSet<String> k5 = new HashSet<>(); k5.add("G"); k5.add("H"); // 保存所有公交 以及 公交站臺資訊 HashMap<String, HashSet<String>> bus = new HashMap<>(); bus.put("K1", k1); bus.put("K2", k2); bus.put("K3", k3); bus.put("K4", k4); bus.put("K5", k5); // 保存所有站臺資訊 HashSet<String> allStation = new HashSet<>(); for (String k : bus.keySet()) { allStation.addAll(bus.get(k)); } // 用于記錄最終結果 List<String> result = new ArrayList<>(); // 站臺非空時,記錄經過 最多 站臺的 公交 while(!allStation.isEmpty()) { // 用于記錄經過 最多站臺 的公交 String maxKey = null; // 遍歷各公交 for (String k : bus.keySet()) { // 獲取公交經過的站臺資訊 HashSet<String> temp = bus.get(k); // 取當前 公交經過的 所有站臺 與 總站臺 的交集,并將交集 賦給 當前公交,用于記錄當前公交所經過的最多站臺數量 temp.retainAll(allStation); // 用于記錄當前場合下,經過 最多站臺 的公交(區域最優) if (maxKey == null || temp.size() > bus.get(maxKey).size()) { maxKey = k; } } if (maxKey != null) { // 記錄當前經過 最多站臺的 公交 result.add(maxKey); // 從所有公交站臺中 移除 已經可以被經過的 公交站臺 allStation.removeAll(bus.get(maxKey)); } } System.out.println("經過所有站臺所需最少公交為:" + result); } } 【輸出結果:】 經過所有站臺所需最少公交為:[K1, K2, K3, K5]
3、動態規劃(0/1 背包問題)
(1)動態規劃
動態規劃(Dynamic Programming)核心思想與 分治演算法類似,都是將 大問題劃分為若干個小問題求解,從子問題的解中得到原問題的答案,
但不同之處在于 分治法 適用于 子問題相互獨立的 情況,而動態規劃 適用于 子問題不相互獨立的情況,即 動態規劃求解 建立在 上一個子問題的解的基礎上,可以采用填表的方式,逐步推算得到最優解,
【動態規劃關注點:】
最優子結構:每個階段的狀態可以從之前某個階段直接得到,
狀態轉移:如何從一個狀態 轉移 到另一個狀態,
注:
動態規劃是以 空間 換 時間,其將每個子問題的計算結果保存,需要時直接取出,減少了重復計算子問題的時間,
(2)0/1 背包問題
【問題描述:】 背包問題是 給定一個容量的背包,以及若干個 具有一定 價值 以及 容量的物品, 在 保證 背包的容量下,選擇物品放入背包,使得背包價值 最大, 注: 背包問題可以分為:0/1 背包、完全背包, 0/1 背包指的是 同一物品只能存在一個在背包中, 完全背包指的是 有多個相同的物品可以放入背包中, 【0/1 背包分析:】 假設有 n 個物品,背包重量為 m, 使用一維陣列 weight[i] 表示 第 i 個物品的 重量, 使用一維陣列 value[i] 表示 第 i 個物品的 價值, 使用二維陣列 maxValue 用于記錄物品放入背包的結果,maxValue[i][j] 表示前 i 個物品能裝入容量為 j 的背包的最大價值,則 maxValue[n][m] 即為背包所能存放的最大價值, 對于 第 i-1 個物品,裝入容量為 j 的背包,則其裝入背包總價值為 maxValue[i-1][j], 對于 第 i 個物品, 若其重量大于背包重量,即 weight[i] > j,則該物品肯定不能放入背包,此時背包最大價值仍為上一次的最大值,即 maxValue[i][j] = maxValue[i-1][j], 若其重量小于等于背包重量,即 weight[i] <= j,則該物品可以放入背包,將物品放入背包,并重新計算當前最大價值, 物品放入背包,去除 當前物品容量時 背包的最大價值 并加上當前物品價值,即可得到當前物品存入背包后的最大價值,即 maxValue[i][j] = maxValue[i-1][j - weight[i]] + value[i] 計算原有價值以及 新價值的最大值作為當前背包最大價值(狀態轉移),即 Math.max(maxValue[i-1][j], maxValue[i-1][j-weight[i]] + value[i])) 注: 由于每次都將子問題解記錄,所以可以避免重復計算子問題解, 若想輸出放入背包的物品,可以根據 maxValue[i][j] 、maxValue[i-1][j] 反推, maxValue[i][j] 大于 maxValue[i-1][j] 時,第 i 個物品肯定進入背包, 【舉例:】 現有 3 個物品,價值為 {1500, 3000, 2000},重量為 {1, 4, 3},背包容量為 4. 則使用 二維陣列 記錄各容量背包下物品存放最大價值如下表: 1 2 3 4 0 0 0 0 0 1 0 1500 1500 1500 1500 2 0 1500 1500 1500 3000 3 0 1500 1500 2000 3500 注: 行表示物品,串列示背包容量,行列組合起來表示 某背包容量下 物品存放的最大價值, 比如: 第一行,存放第一個物品,重量為 1,在背包容量為 1~4 的情況下,均能存放,則其最大價值為 1500. 第二行,存放第二個物品,重量為 4,在背包容量為 1~3 的情況下,不能存放,則其最大價值為 1500(只能存放第一個物品), 但其在背包容量為 4 時可以存放,此時最大價值為 3000,且去除了第一個物品,只存放第二個物品, 第三行,存放第三個物品,重量為 3,在背包容量為 1~2 的情況下,不能存放,則其最大價值為 1500, 而其在背包容量為 3 時可以存放,此時最大價值為 2000,只存放第三個物品, 在背包容量為 4 時也可以存放,此時最大價值為 3500,存放第三個物品 和 第一個物品, 【代碼實作:】 package com.lyh.algorithm; import java.util.ArrayList; import java.util.List; /** * 0/1 背包問題 */ public class Knapsack { public static void main(String[] args) { int[] value = https://www.cnblogs.com/l-y-h/p/new int[]{1500, 3000, 2000}; // 設定物品價值 int[] weight = new int[]{1, 4, 3}; // 設定物品容量 int m = 4; // 設定背包容量 int n = value.length; // 設定物品總數量 knapsack(value, weight, n, m); } /** * 0/1 背包 * @param value 物品價值 * @param weight 物品重量 * @param count 物品總數 * @param capacity 背包總容量 */ public static void knapsack(int[] value, int[] weight, int count, int capacity) { // 背包存放最大價值,maxValue[i][j] 表示第 i 個物品存放在 容量為 j 的背包中的最大價值 // 其中第一行、第一列均為 0,便于計算, int[][] maxValue = https://www.cnblogs.com/l-y-h/p/new int[count + 1][capacity + 1]; // 依次求解各個容量背包下物品存放的最大價值 // i 表示第 i 個物品,j 表示 容量為 j 的背包 for (int i = 1; i < count + 1; i++) { for (int j = 1; j < capacity + 1; j++) { // 若背包容量小于當前物品,則當前物品肯定不能存進背包,直接賦值上一個求解值即可 // 由于 i 從 1 開始計數,所以訪問第一個物品重量時為 weight[i - 1],訪問第一個物品價值為 value[i -1],保證從下標為 0 開始訪問, if (j < weight[i - 1]) { maxValue[i][j] = maxValue[i - 1][j]; } else { // 背包容量 大于等于當前物品,則當前物品可以存入背包,則重新計算最大價值 // 當前物品存入背包價值為: 去除 當前物品容量時 背包的最大價值 與 當前物品價值 之和 int currentValue = https://www.cnblogs.com/l-y-h/p/maxValue[i - 1][j - weight[i - 1]] + value[i - 1]; // 計算當前物品價值 與 之前價值 最大值,并記錄 maxValue[i][j] = Math.max(currentValue, maxValue[i - 1][j]); } } } /** * 遍歷輸出各個容量下 背包存放物品的價值 */ System.out.println("各容量背包下,存放物品的最大值如下: "); for (int i = 0; i < count + 1; i++) { for (int j = 0; j < capacity + 1; j++) { System.out.print(maxValue[i][j] + " "); } System.out.println(); } System.out.println("容量為: " + capacity + " 的背包存放最大物品價值為: " + maxValue[count][capacity]); // 反推出 存入 背包的物品 int j = capacity; // 記錄背包容量 List<Integer> list = new ArrayList<>(); // 記錄物品下標 for (int i = count; i > 0; i--) { // maxValue[i][j] 大于 maxValue[i - 1][j],則第 i 個物品肯定進入背包了 if (maxValue[i][j] > maxValue[i - 1][j]) { list.add(i - 1); // 記錄物品下標 j -= weight[i - 1]; // 查找去除當前物品下標后的背包存盤的物品 } if (j == 0) { break; // 背包中物品都已取出 } } System.out.println("存入背包的物品為: "); for (int i = 0; i < list.size(); i++) { System.out.println("第 " + (list.get(i) + 1) + " 個物品,價值為: " + value[list.get(i)] + " ,重量為: " + weight[list.get(i)]); } } } 【輸出結果:】 各容量背包下,存放物品的最大值如下: 0 0 0 0 0 0 1500 1500 1500 1500 0 1500 1500 1500 3000 0 1500 1500 2000 3500 容量為: 4 的背包存放最大物品價值為: 3500 存入背包的物品為: 第 3 個物品,價值為: 2000 ,重量為: 3 第 1 個物品,價值為: 1500 ,重量為: 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/220554.html
標籤:Java