最近要換新作業了,借著新老作業交替的這段視窗放松了下,所以專欄拖更了,不過我心里毫無愧疚,畢竟沒人催更, 不過話說回來天天追劇 刷綜藝的日子也很是枯燥,羨慕你們這些正常上班的人,每天都有正經作業內容,感覺你們過的很充實,[狗頭]
計算機領域有很多種資料結構,資料結構的存在要么是為了節省時間、要么是為了節省空間,或者二者兼具,所以就有部分資料結構有時間換空間,空間換時間之說,其實還有某些以犧牲準確性來達到節省時間空間的資料結構,像我之間講過的bloomfilter就是其中的典型,而今天要講的skiplist也是一種概率性資料結構,它以一種隨機概率降資料組織成多級結構,方便快速查找,
跳表
究竟何為跳表?我們先來考慮下這個場景,假設你有個有序鏈表,你想看某個特定的值是否出現在這個鏈表中,那你是不是只能遍歷一次鏈表才能知道,時間復雜度為O(n),

可能有人會問為什么不直接用連續存盤,我們還能用二分查找,用鏈表是想繼續保留它修改時間復雜度低的優勢,那我們如何優化單次查找的速度?其實思路很像是二分查找,但單鏈表無法隨機訪問的特性限制了我們,但二分逐漸縮小范圍的思路啟發了我們,能不能想什么辦法逐漸縮小范圍?
我是不是可以在原鏈表之上新建一個鏈表,新鏈表是原鏈表每隔一個節點取一個,假設原鏈表為L0,新鏈表為L1,L1中的元素是L0中的第1、3、5、7、9……個節點,然后再建立L1和L0中各個節點的指標,這樣L1就可以將L0中的范圍縮小一半,同理對L1再建立新鏈表L2……,更高level的鏈表劃分更大的區間,確定值域的大區間后,逐級向下縮小范圍,如下圖,
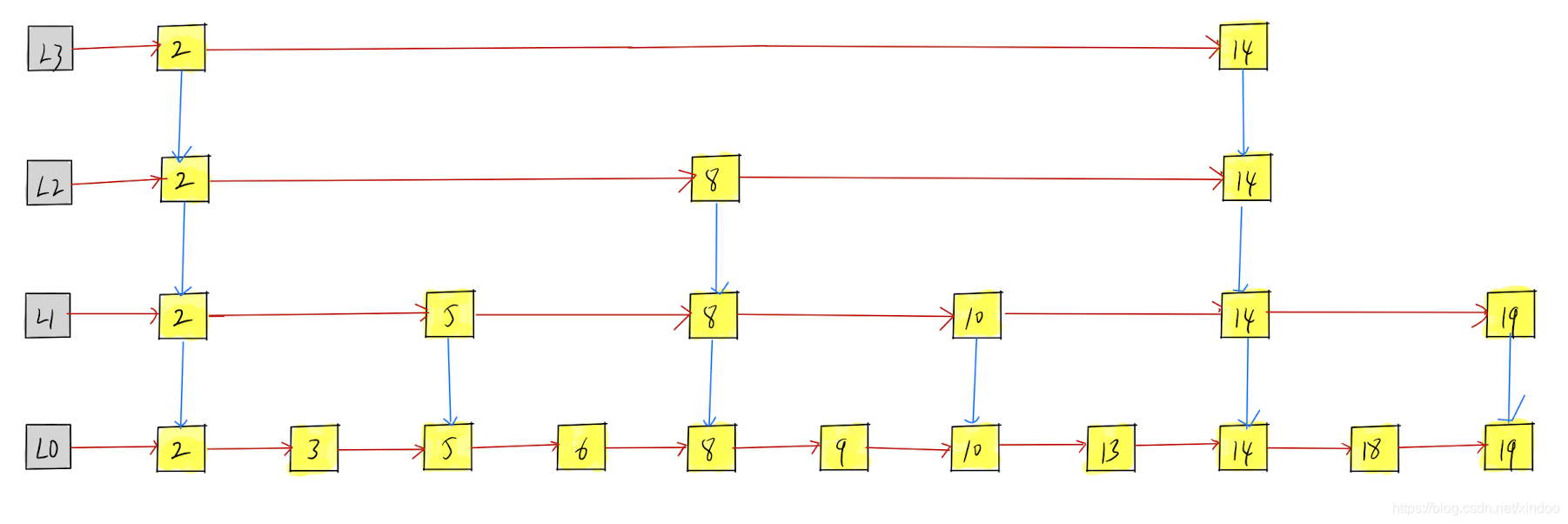
假設我們想找13,我們可以在L3中確定2-14的范圍,在L2中確定8-14的范圍,在L1中確定10-14的范圍,在L0中找到13,整體尋找路徑如下圖紅色路徑,是不是比直接在L0中找13的綠色路徑所經過的節點數少一些,
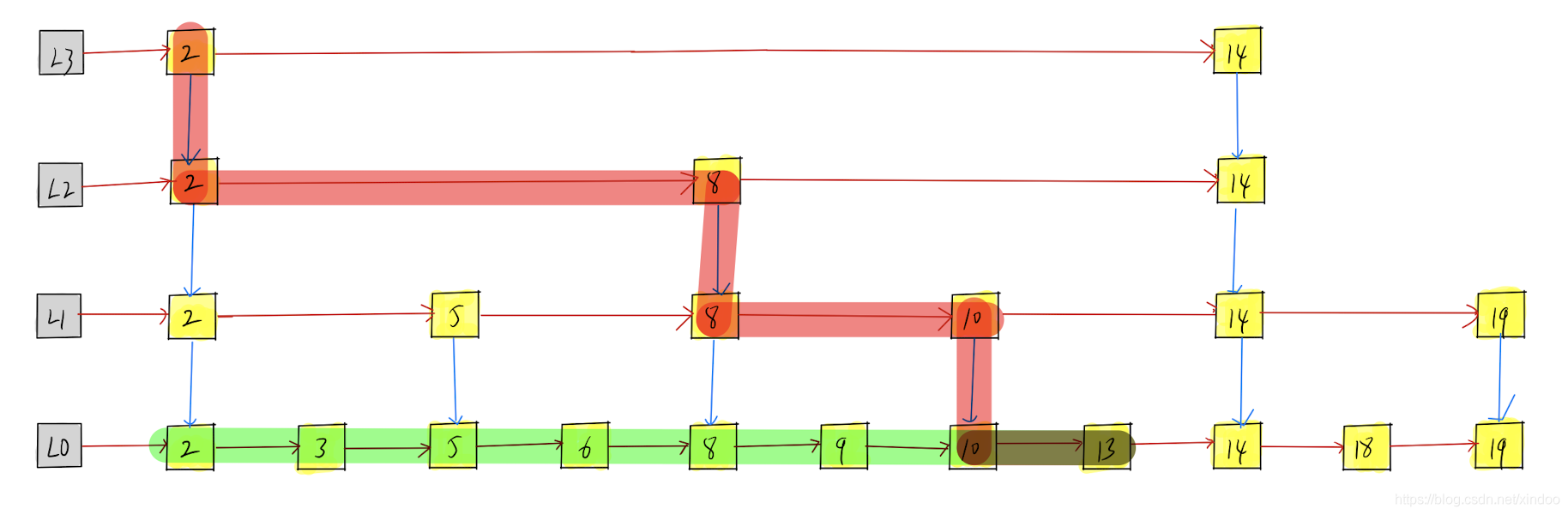
其實這種實作很像二分查找,只不過事先將二分查找的中間點存盤下來了,用額外的空間換取了時間,很容易想到其時間復雜度和二分查找一致,都是O(logn),
小伙子很牛X嗎,發明了這么牛逼的資料結構,能把有序鏈表的查找時間復雜度從O(n)降低到O(logn),但是我有個問題,如果鏈表中插入或者洗掉了某個節點怎么辦?,是不是每次資料變動都要重建整個資料結構?
其實不必,我們不需要嚴格保證兩兩層級之間的二分之一的關系,只需要概率上為二分之一就行,洗掉一個節點好說,直接把某個層級中對應的改節點刪掉,插入節點時,新節點以指數遞減的概率往上層鏈表插入即可, 比如L0中100%插入,L1中以1/2的概率插入,如果L1中插入了,L2中又以1/2的概率插入…… 注意,只要高Level中有的節點,低Level中一定有,但高Level鏈表中出現的概率會隨著level指數遞減,最終跳表可能會長這個樣子,
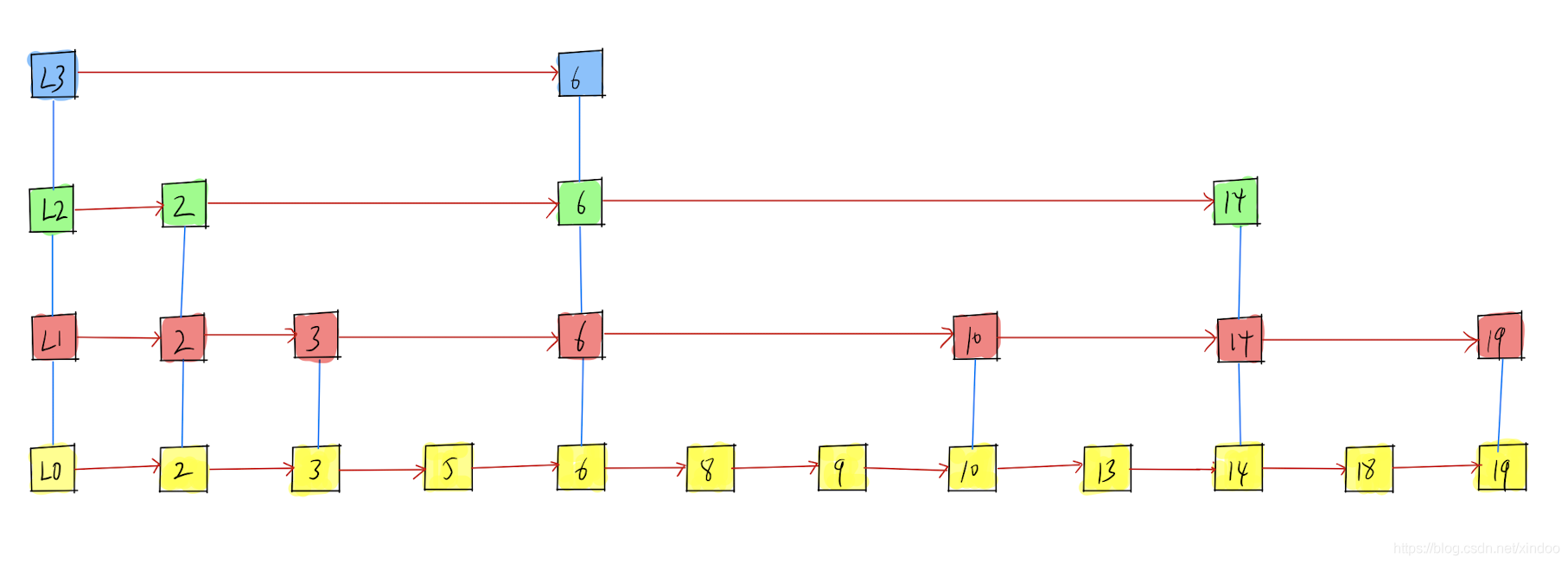
我們就這樣重新發明了skiplist,
Redis中的跳表
Redis為了提供了有序集合(sorted set)相關的操作(比如zadd、zrange),其底層實作就是skiplist,我們接下來看下redis是如何實作skiplist的,
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 頭尾指標
unsigned long length; // skiplist的長度
int level; // 最高多少級鏈表
} zskiplist;
我們先來看下redis中zskiplist的定義,沒啥內容,就頭尾指標、長度和級數,重點還是在zskiplistNode中,zskiplistNode中是有前向指標的,所以Level[0]其實是個雙向鏈表,
typedef struct zskiplistNode {
sds ele; // 節點存盤的具體值
double score; // 節點對應的分值
struct zskiplistNode *backward; // 前向指標
struct zskiplistLevel {
struct zskiplistNode *forward; // 每一層的后向指標
unsigned long span; // 到下一個節點的跨度
} level[];
} zskiplistNode;
redis中的skiplist實作稍微和我們上文中講的不大一樣,它并不是簡單的多級鏈表的形式,而是直接在zskiplistNode中的level[]將不同level的節點的關聯關系組織起來,zskiplist的結構可視化如下,
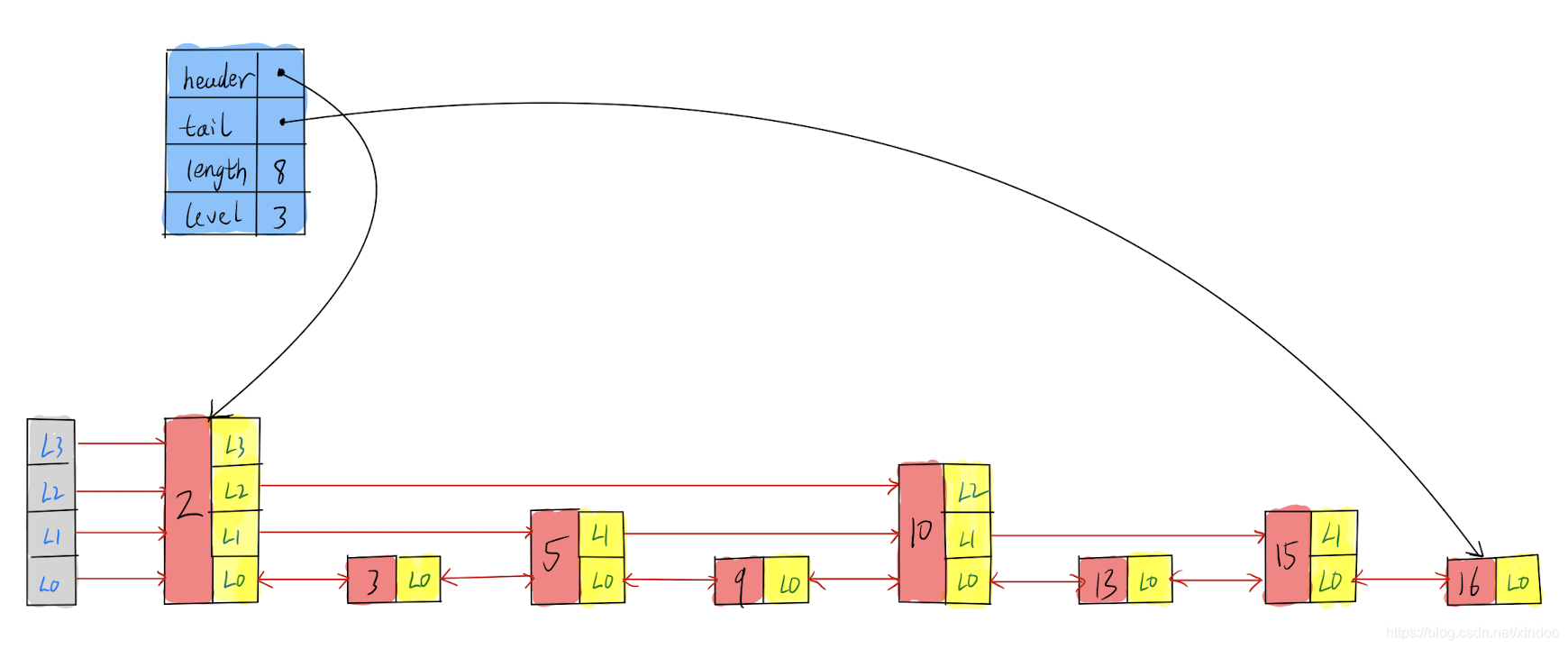
跳表的操作
知道了zskiplist的構造,我們來看下其幾個主要操作,
新建跳表
/* 創建跳表 */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL); // 創建頭節點
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
創建跳表就比較簡單了,直接創建一個空的節點做為頭節點,
/* 在跳表中插入一個新的節點, */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* skiplist中不會出現重復的元素,但我們允許重復的分值,因為如果是呼叫zslInsert()的話,不會出現重復插入兩
* 個相同的元素,因為在zslInsert()中已經判斷了hash表中是否存在*/
level = zslRandomLevel(); // 生成一個隨機值,確定最高需要插入到第幾級鏈表里
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele); // 為插入的資料創建新節點
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/*插入新節點后需要更新前后節點對應的span值 */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* 為其他level增加span值,因為在原有倆節點之間插入了一個新節點 */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) // ZSKIPLIST_P == 0.25
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
資料插入就稍微復雜些,需要新建節點,然后確定需要在哪些level中插入新節點,還要更新前節點中各個level的span值,這里額外注意下zslRandomLevel,zslRandomLevel是以25%的概率決定是否將單個節點放置到下一層,而不是50%,
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1; //洗掉節點需要修改span的值
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
/*從skiplist中洗掉ele,如果洗掉成功回傳1,否則回傳0.
*
* 如果節點是null,需要呼叫zslFreeNode()釋放掉該節點,否則只是把指向sds的指標置空,這樣
* 后續其他的節點還可以繼續使用這個sds*/
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* 可能有多個節點有相同的socre,都必須找出來并洗掉 */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
資料的洗掉也很簡單,很類似于單鏈表的洗掉,但同時需要更新各個level上的資料,
其余代碼就比較多,知道了skiplist的具體實作,其他相關操作的代碼也就比較容易想到了,我這里就不在羅列了,有興趣可以查閱下t_zset.c
Redis為什么使用skiplist而不是平衡樹
Redis中的skiplist主要是為了實作sorted set相關的功能,紅黑樹當然也能實作其功能,為什么redis作者當初在實作的時候用了skiplist而不是紅黑樹、b樹之類的平衡樹? 而且顯然紅黑樹比skiplist更節省記憶體啊! Redis的作者antirez也曾經親自回應過這個問題,原文見https://news.ycombinator.com/item?id=1171423

我大致翻譯下:
- skiplist并不是特別耗記憶體,只需要調整下節點到更高level的概率,就可以做到比B樹更少的記憶體消耗,
- sorted set可能會面對大量的zrange和zreverange操作,跳表作為單鏈表遍歷的實作性能不亞于其他的平衡樹,
- 實作和除錯起來比較簡單, 例如,實作O(log(N))時間復雜度的ZRANK只需要簡單修改下代碼即可,
本文是Redis原始碼剖析系列博文,同時也有與之對應的Redis中文注釋版,有想深入學習Redis的同學,歡迎star和關注,
Redis中文注解版倉庫:https://github.com/xindoo/Redis
Redis原始碼剖析專欄:https://zxs.io/s/1h
如果覺得本文對你有用,歡迎一鍵三連,
本文來自https://blog.csdn.net/xindoo
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/226403.html
標籤:Java