前言
如今的京東、淘寶、天貓等等已經不同往日了, 在用戶不登錄的情況下, 很難通過技術手段來大規模獲取到我們關注的商品資訊. 關于京東等購物網站的自動登錄也有很多人在做, 但是大廠的反爬能力確實很強, 目前能查閱到的自動登錄技識訓本都過時了. 本文干脆跳過這一程序, 換一個思路.
在不登錄的情況下獲取商品的編號
我們登錄京東的網址jd.com后可以在不登錄的情況下直接搜索商品, 比如搜索手機
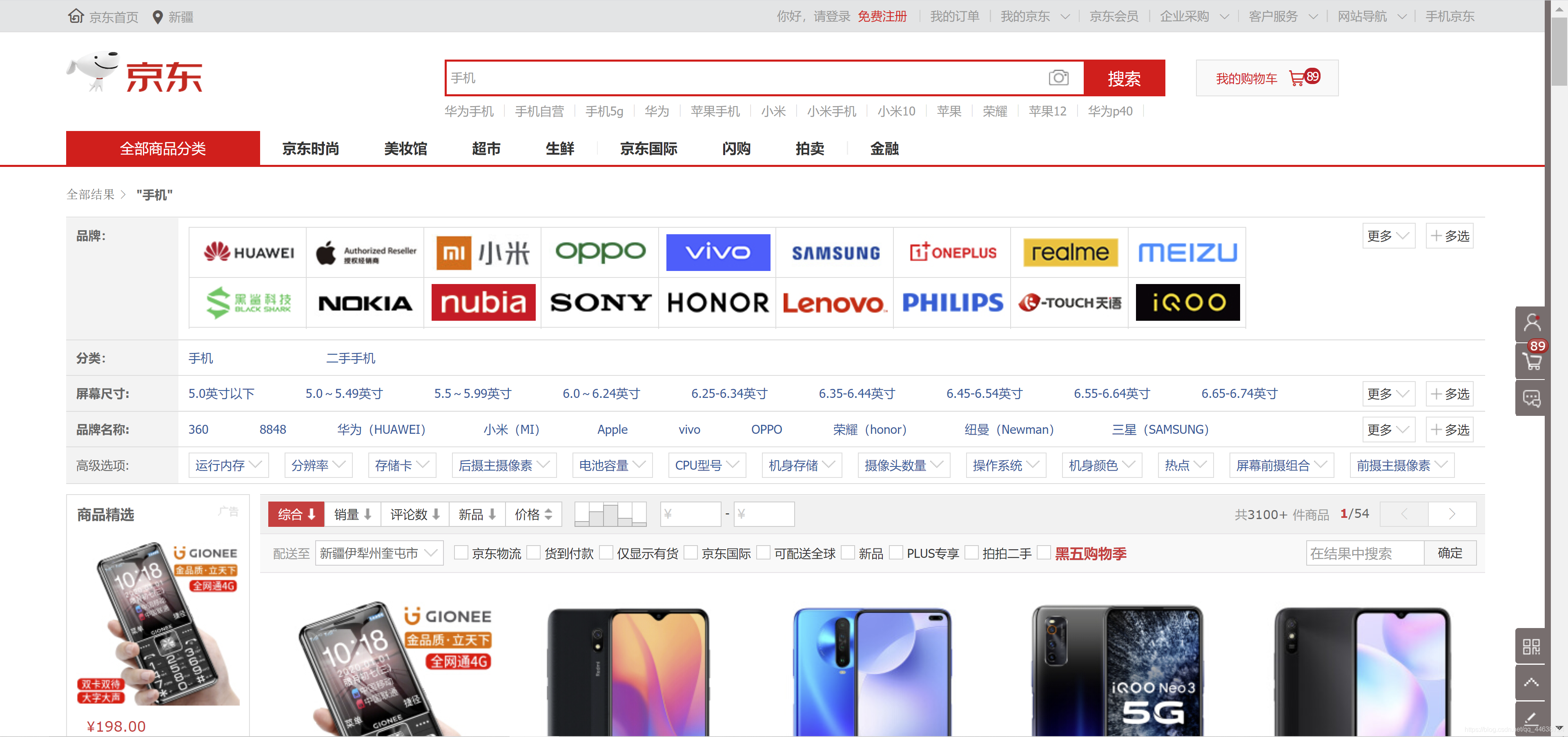
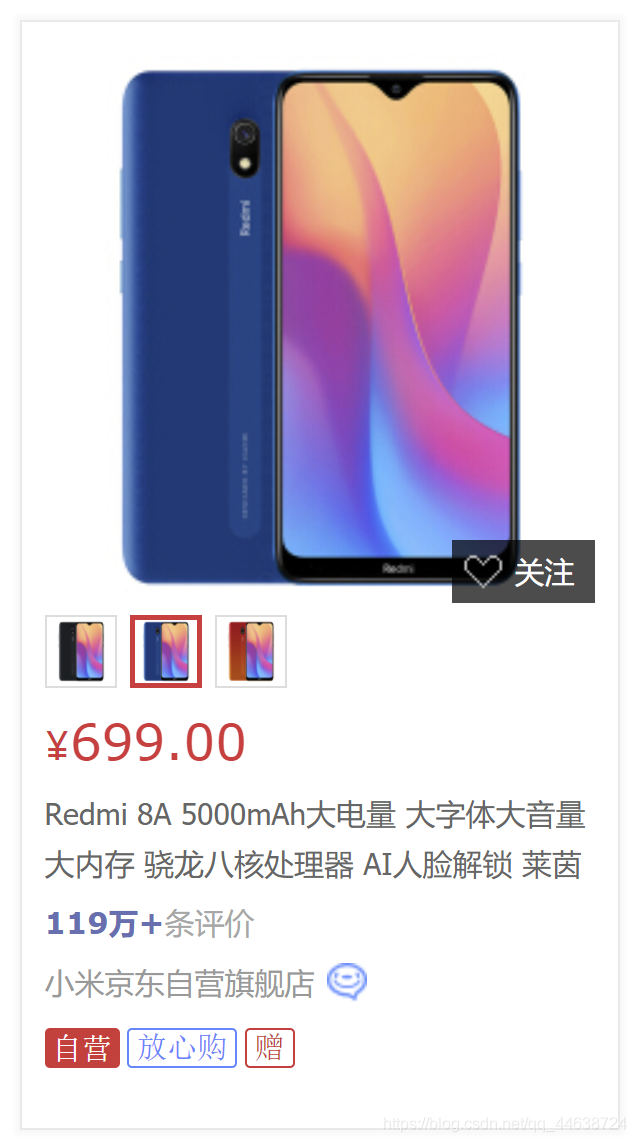
可以看到, 其實這一頁面就已經列出商品的名稱, 售價, 評價量等等. 遺憾的是這個頁面的內容不能直接爬取, 但是我們點開其中一個商品, 并找到它的商品介紹
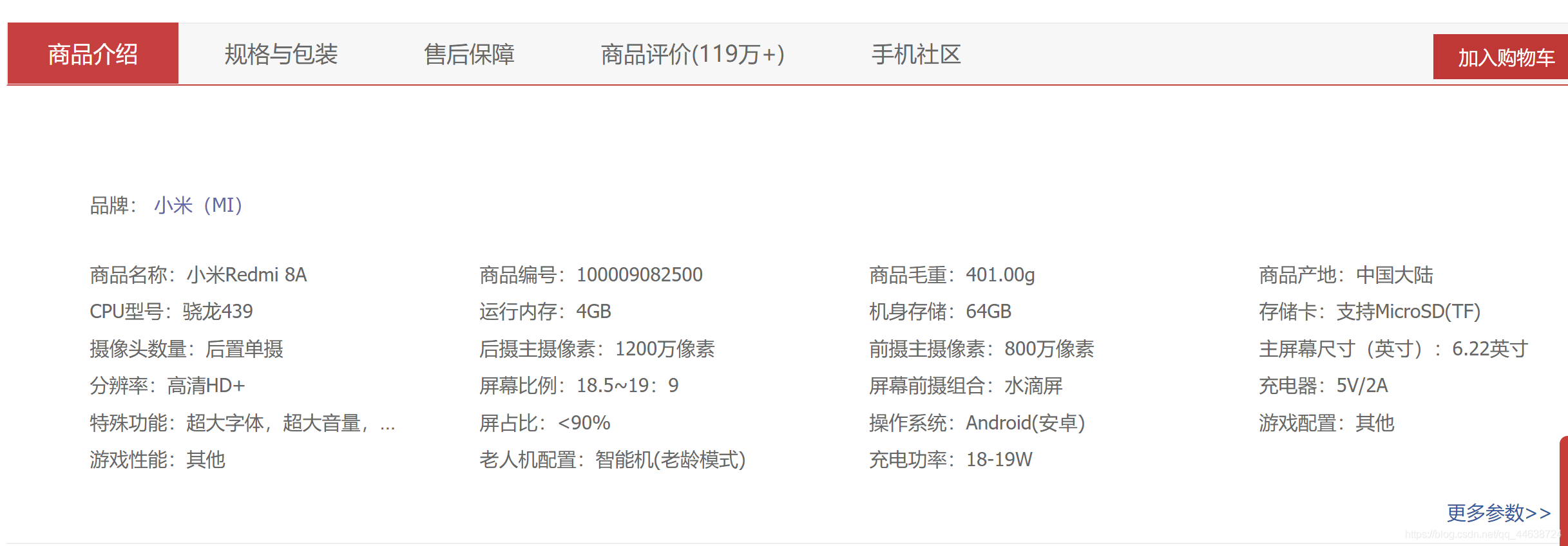
不難發現, 不同的設備在型號、引數、性能上可能會存在著重復,但是在京東商城的商品編號是唯一的, 更方便的一點是, 商品編號就是這一商品的url. 例如上述小米手機的地址為https://item.jd.com/100009082500.html. 那么我們一旦獲取了足夠多的商品編號后就可以對手機的資訊進行爬取了. 接下來我們分析商品串列頁面中是否保存著商品編號資訊.
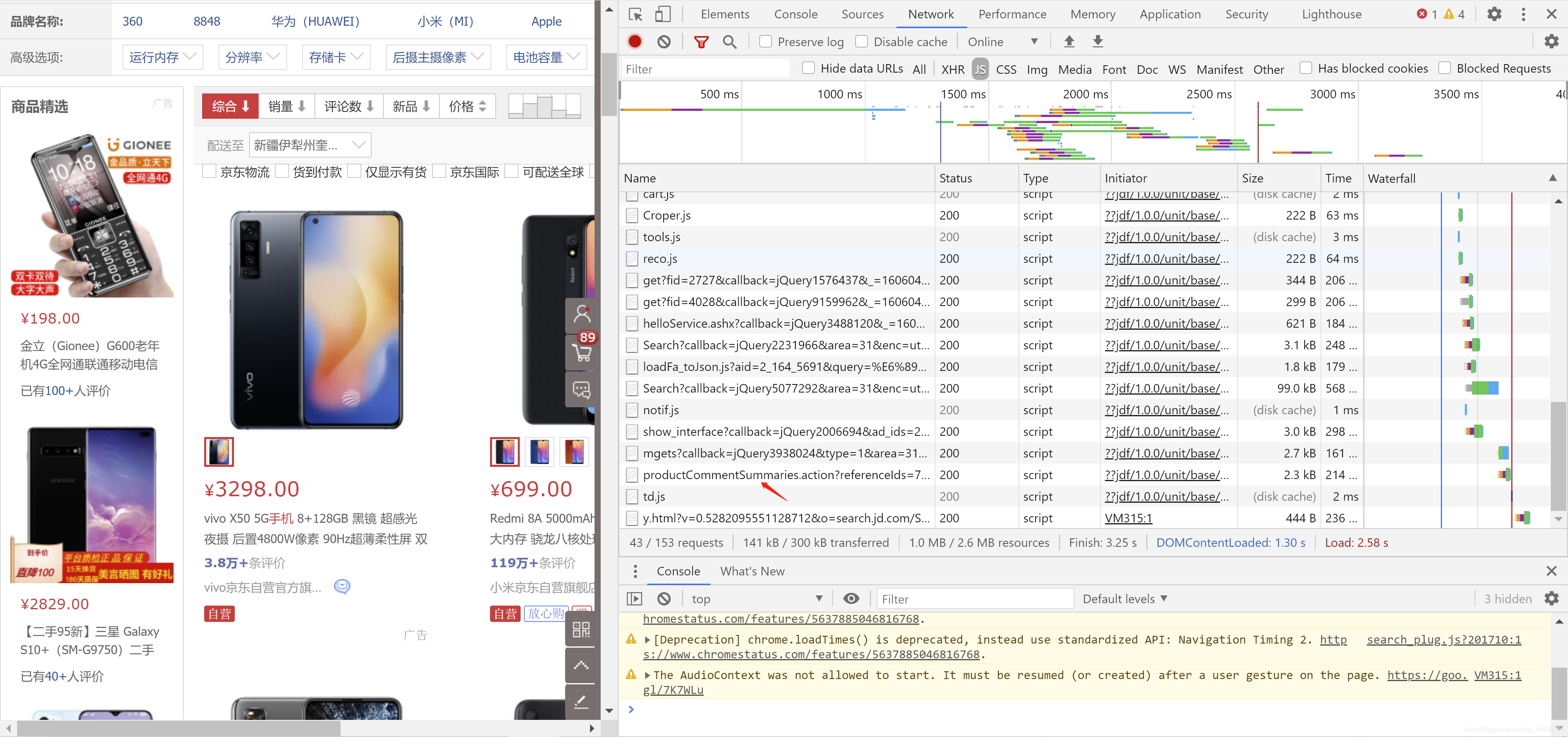
我們打開開發者工具, 選擇Network, 可以很容易的發現一條資訊, productcommentsummaries, 那么它很有可能會包含商品的編號.
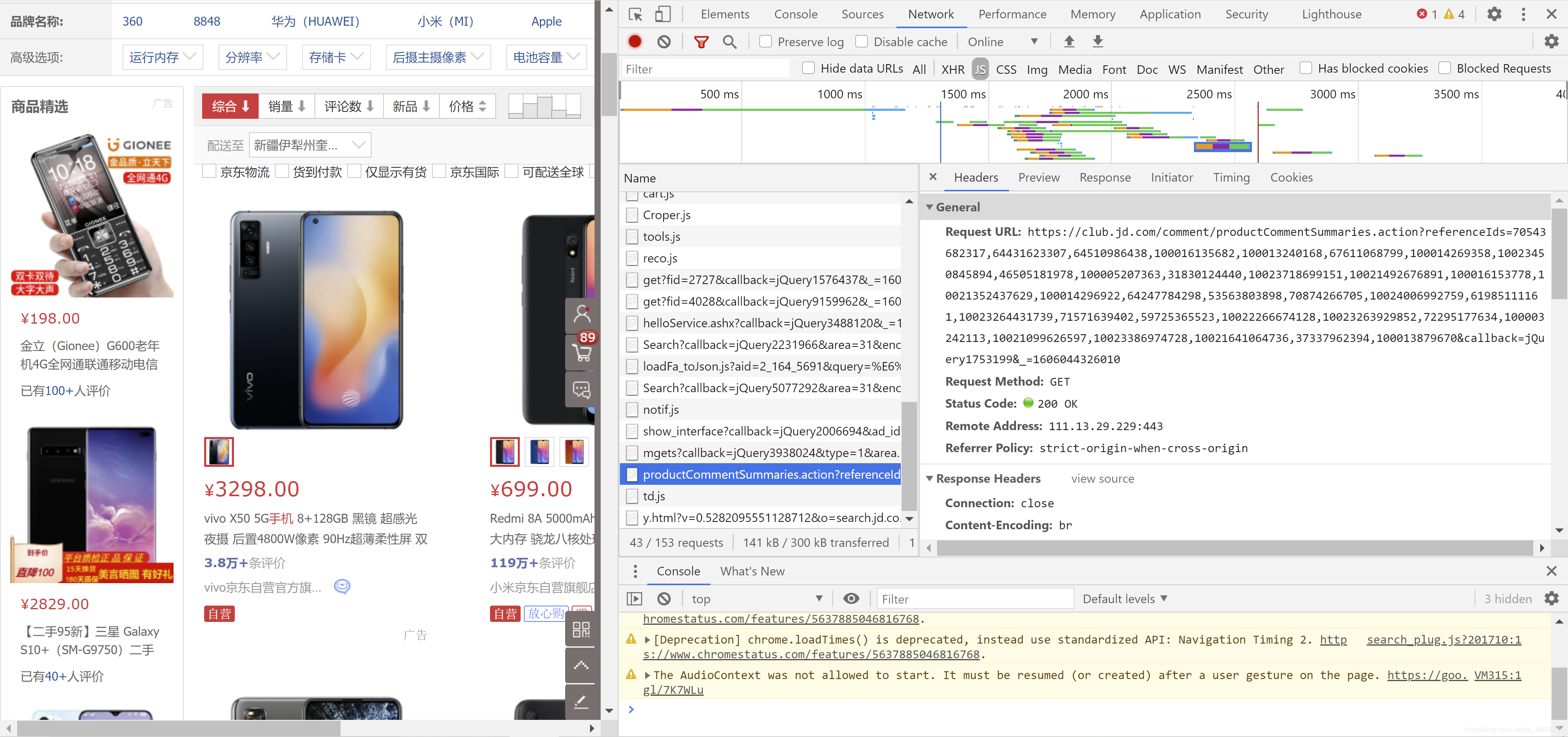
進一步打開它可以發現有很多數字串, 其實這些就是在keyword=手機條件下的商品編號, 如果我們需要大規模爬取, 可以手動多點幾頁, 就獲取很多這樣的內容. 為進行測驗, 本文截取了少量編號
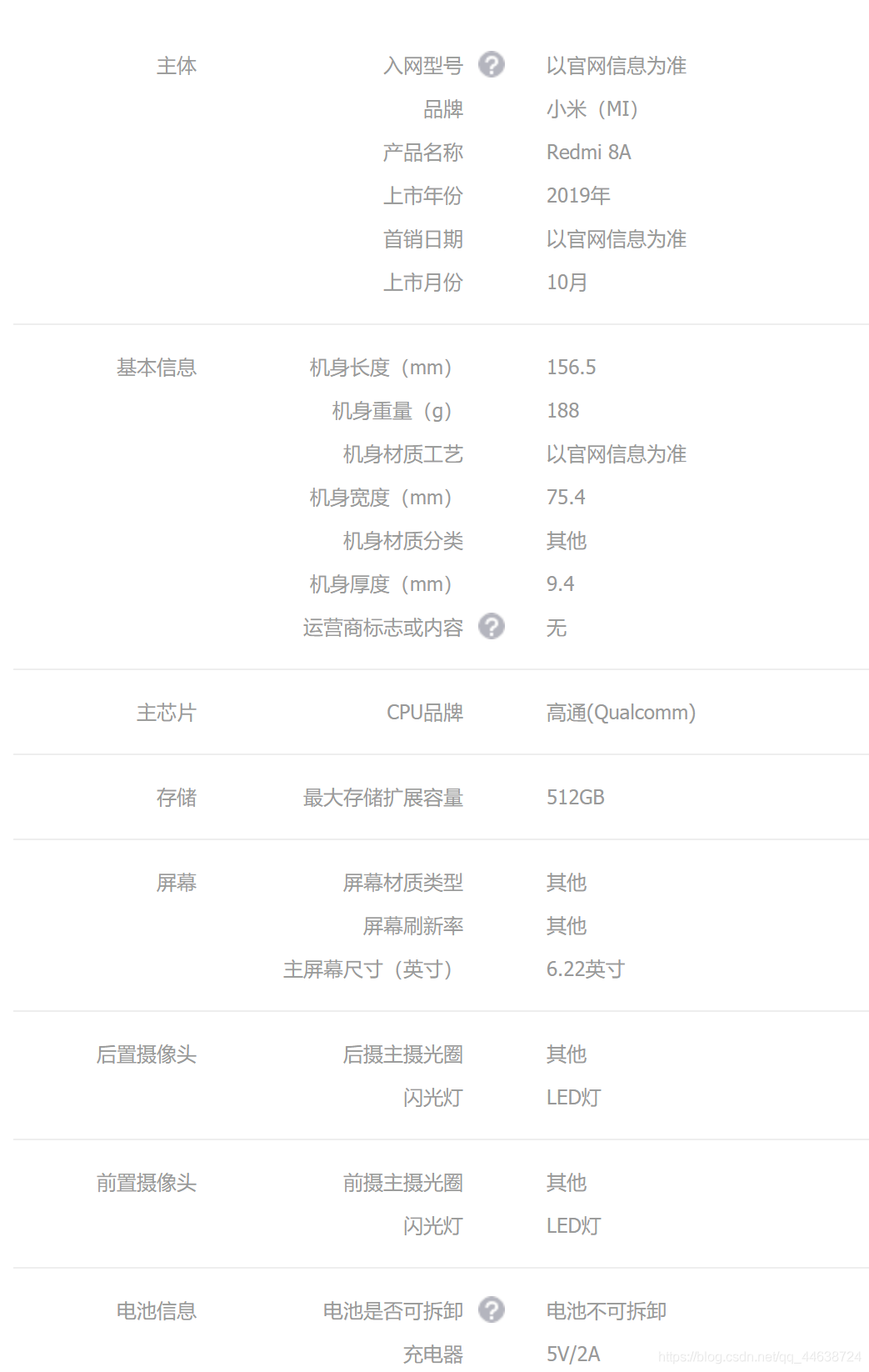
一旦獲取了商品編號, 那么商品的資訊就很好獲取了, 假如我們想要獲取某一款手機的詳細配置, 如下圖
可以嘗試如下的代碼, 先通過簡單的讀取txt檔案將單一的商品編號轉變為可訪問的url
import csv
import pandas as pd
import time
import os
import requests
from bs4 import BeautifulSoup
def get_url(dir):
commo_list = []
List = []
col = 0
with open(dir,"r") as f:
for line in f.readlines():
line = line.strip("\n")
List = list(eval(line))
col = col + 1
print("第{0}行".format(col))
for i in range(len(List)):
commo_list.append(List[i])
print(line)
print("---商品編號總計:{0}個---".format(len(commo_list)))
return commo_list
dir = 'D:/Desktop/commodity.txt'
commodity_list = get_url(dir)
結果如下
通過request庫來獲取url
def get_page(commo):
page_list = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
} #定義頭部
#https://item.jd.com/100014589194.html http example
#for i in range(len(commo)): #設定爬取量
for i in range(10): #為提高效率, 本示例中僅爬取10個商品
url = "https://item.jd.com/" + str(commo[i]) + ".html"
page = requests.get(url,headers=headers)
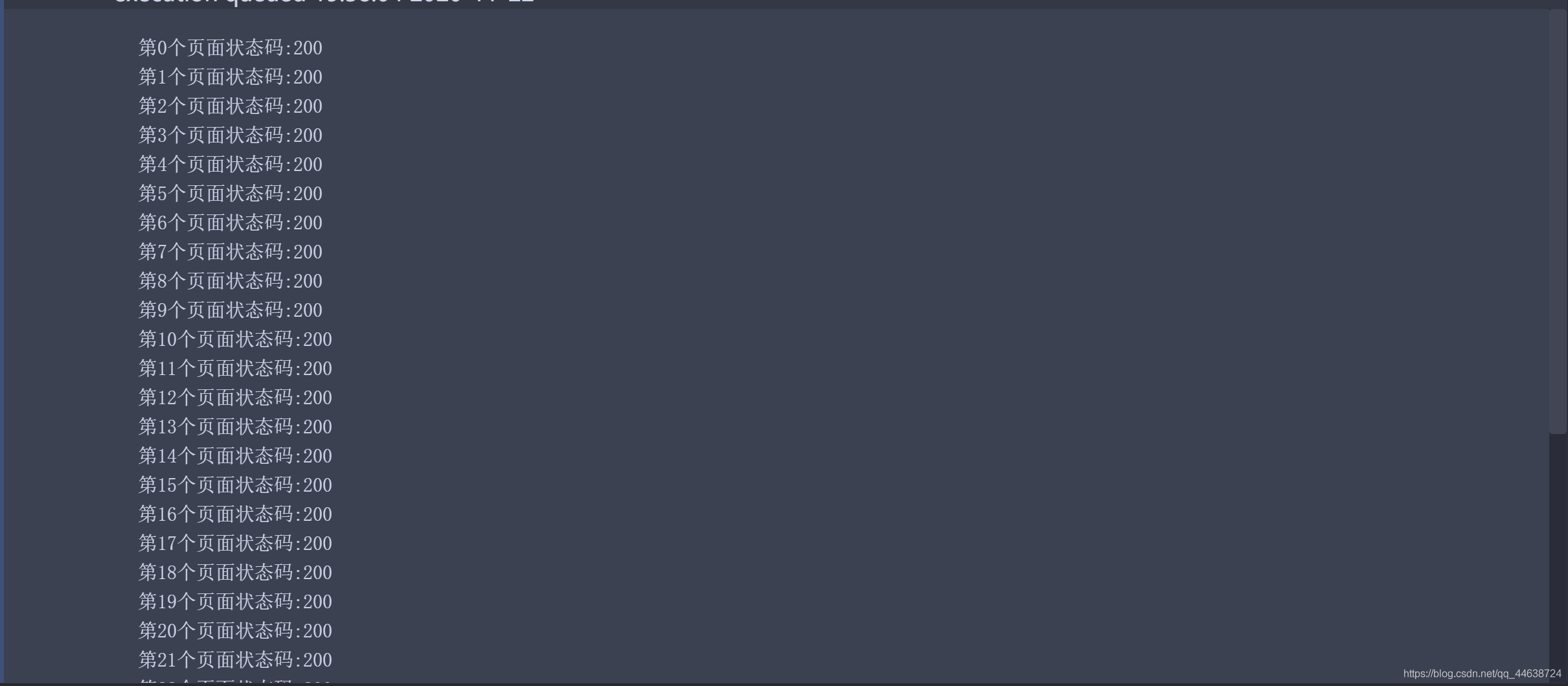
print("第{0}個頁面狀態碼:{1}".format(i,page.status_code))
time.sleep(1.5) #程式掛起, 防止反爬蟲
#page = requests.get()
page_list.append(page)
print("獲取完畢")
return page_list
#Page = get_page(commodity_list)
在代碼運行的程序中加入頁面的狀態碼, 這樣可以很快的向我們反映哪些地址被成功訪問了, 而哪些沒有. 同時引入time.sleep()函式能夠有效的防止因訪問過快而被封ip. 運行結果如下
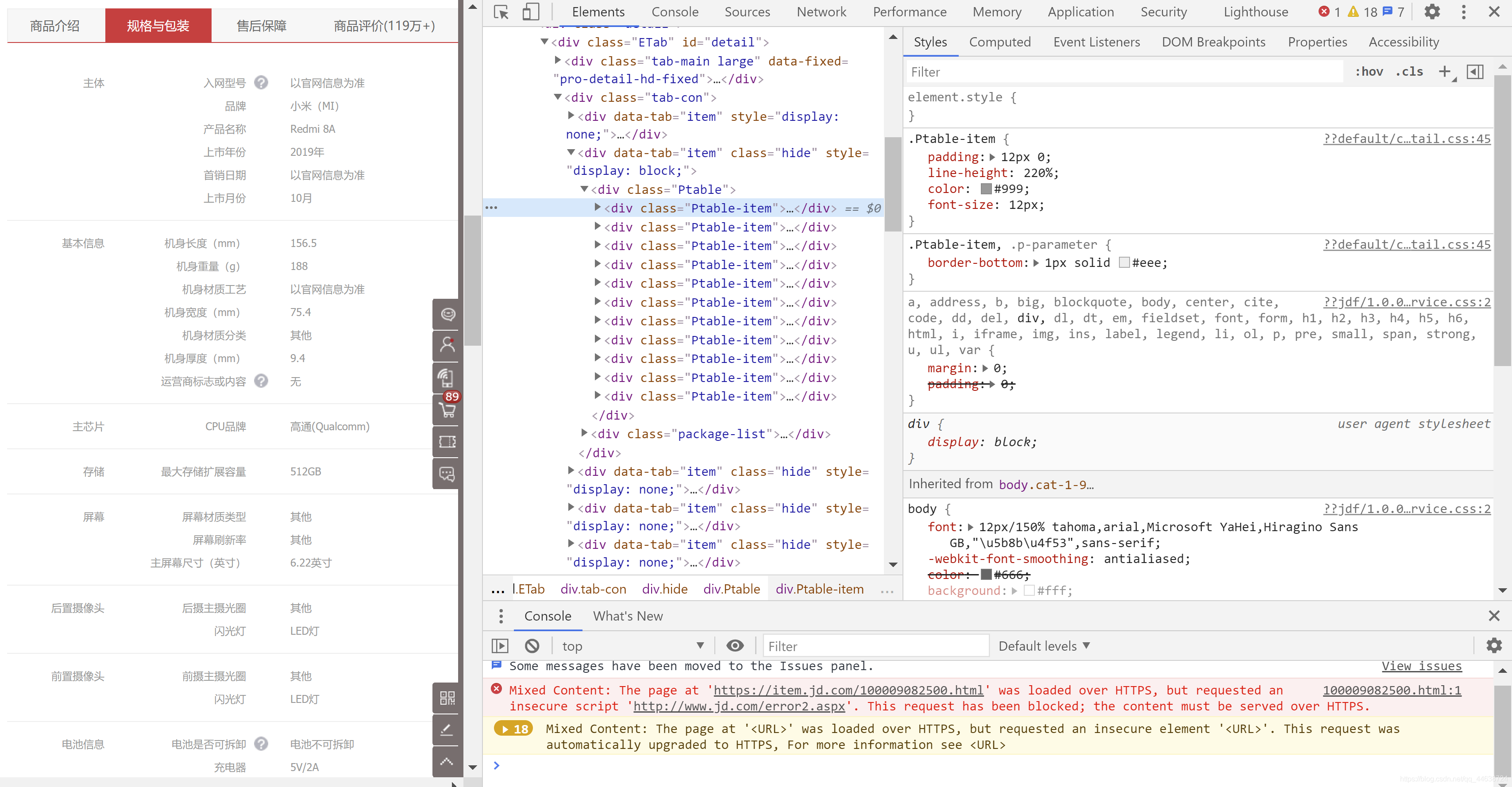
通過簡單的查看手機相信相信頁的標簽結果, 很容易能發現這些有價值的資訊都被存在div:class=Ptable-item標簽中
用BeautifulSoup庫決議頁面
def analysis_page(analysis, head):
Soup = []
Dt = []
Dd = []
Div = []
Dl = []
DD = []
DT = []
pro = 1
for i in range(len(analysis)):
soup = BeautifulSoup(analysis[i].text,"html.parser")
#print(soup)
div = soup.find_all('div',attrs={"class":['Ptable-item']}) #回傳div為串列
print(div)
Dt = []
Dd = []
for ll in div:
dl = ll.find_all('dl',{'class':['clearfix']})
for i in range(len(dl)):
if dl[i].dd.attrs == {'class': ['Ptable-tips']}:
#print(dl[i].dt.text, ":", dl[i].dd.next_sibling.next_sibling.string)
Dt.append(dl[i].dt.text)
Dd.append(dl[i].dd.next_sibling.next_sibling.string)
else:
#print(dl[i].dt.string, ":", dl[i].dd.string)
Dt.append(dl[i].dt.string)
Dd.append(dl[i].dd.string)
DT.append(Dt)
DD.append(Dd)
print("\r" + "{0:.2f}".format(pro/len(analysis)),end = "")
pro = pro + 1
return Dl, DT, DD
result = analysis_page(Page, 2)
這樣, div標簽中的資訊就被保存到result中了, 我們來查看一下
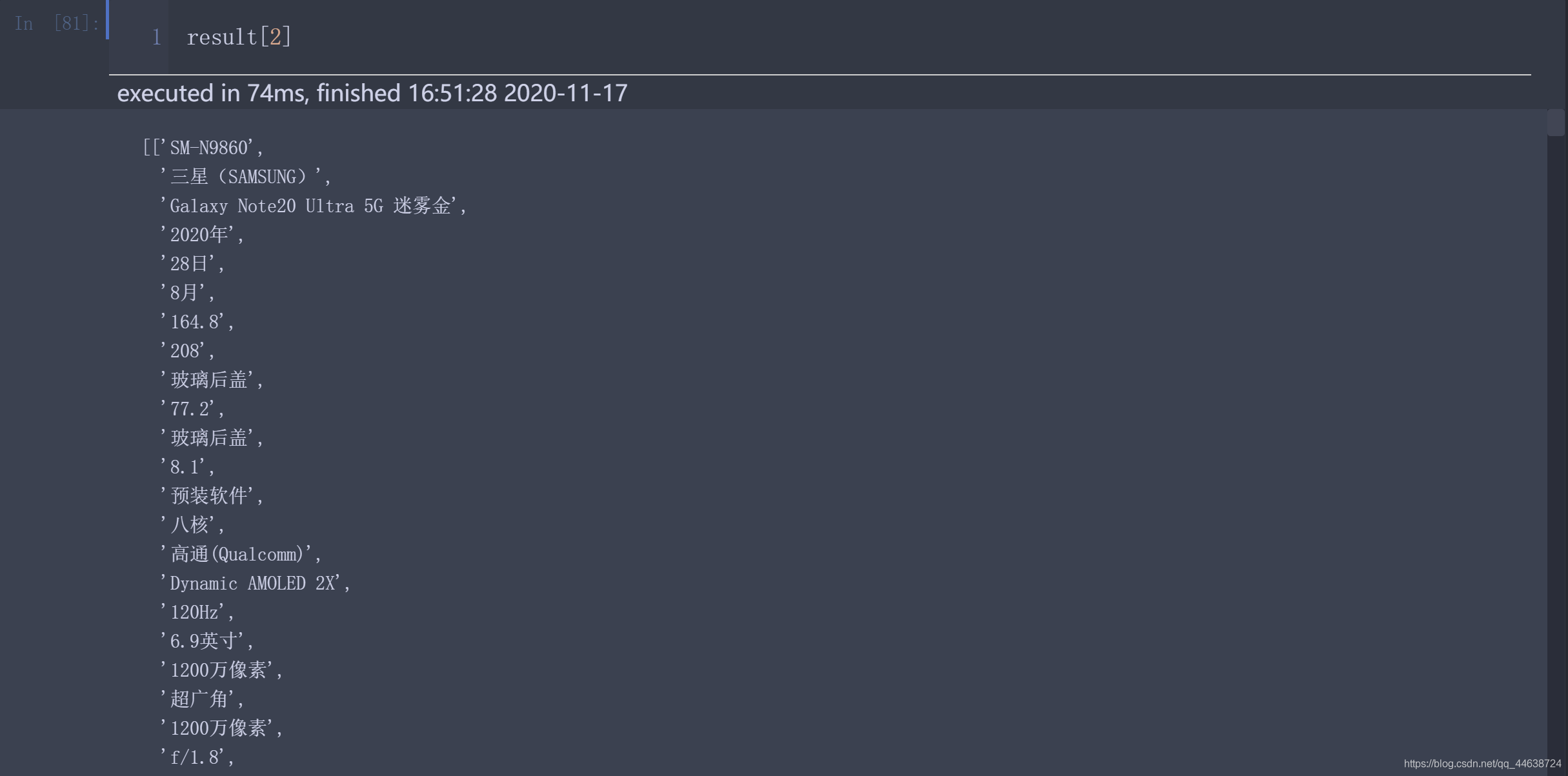
商品資訊顯示正常沒有亂碼, 也沒有冗余資訊
保存為CSV格式
df = pd.DataFrame(result[2])
df.replace("\n",'',inplace=True,regex=True)
df.to_csv("D://Desktop/result2.csv")
但從保存的結果來看, 似乎程式的輸出是正常的, 但csv檔案卻顯示不正常

可以通過如下辦法解決:
1.用記事本打開
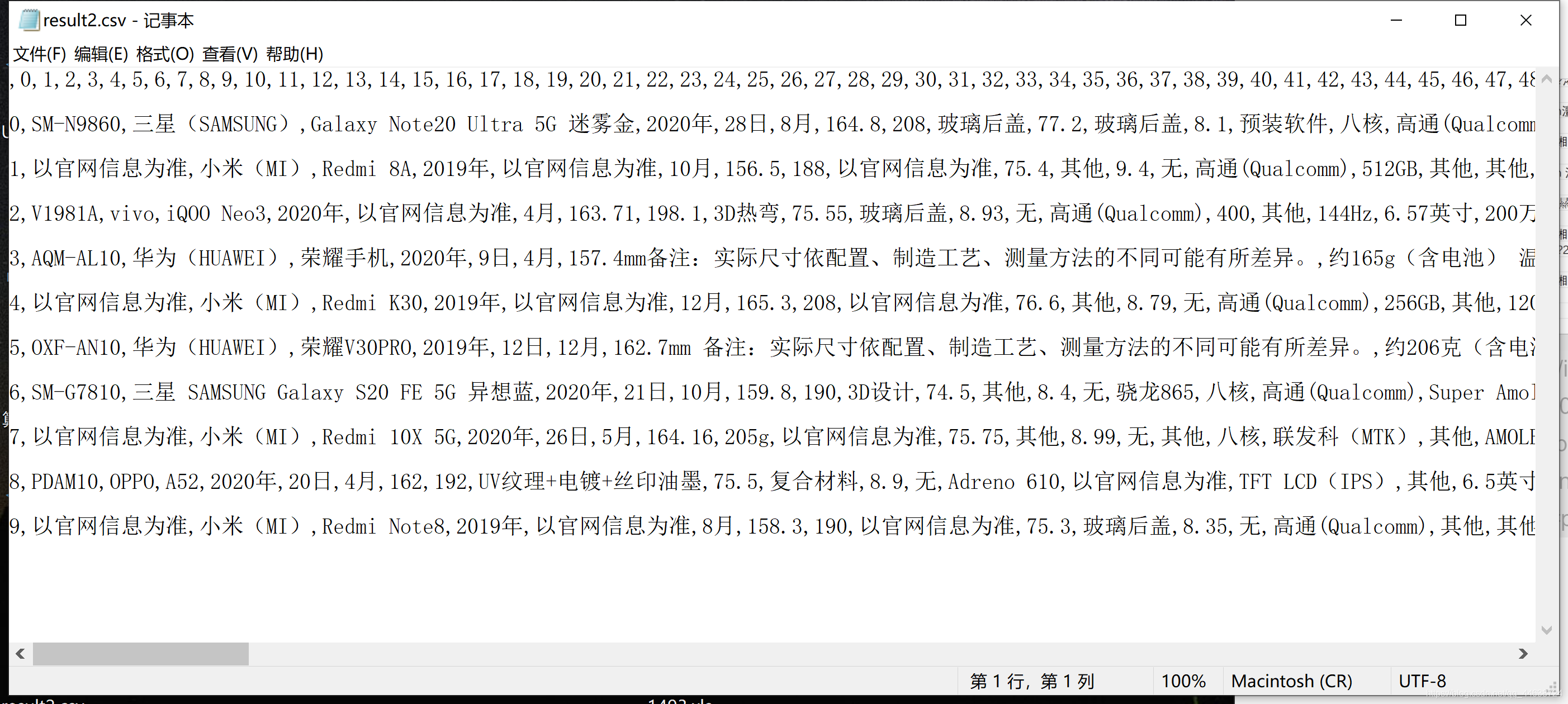
2.另存為帶有BOM的UTF-8檔案
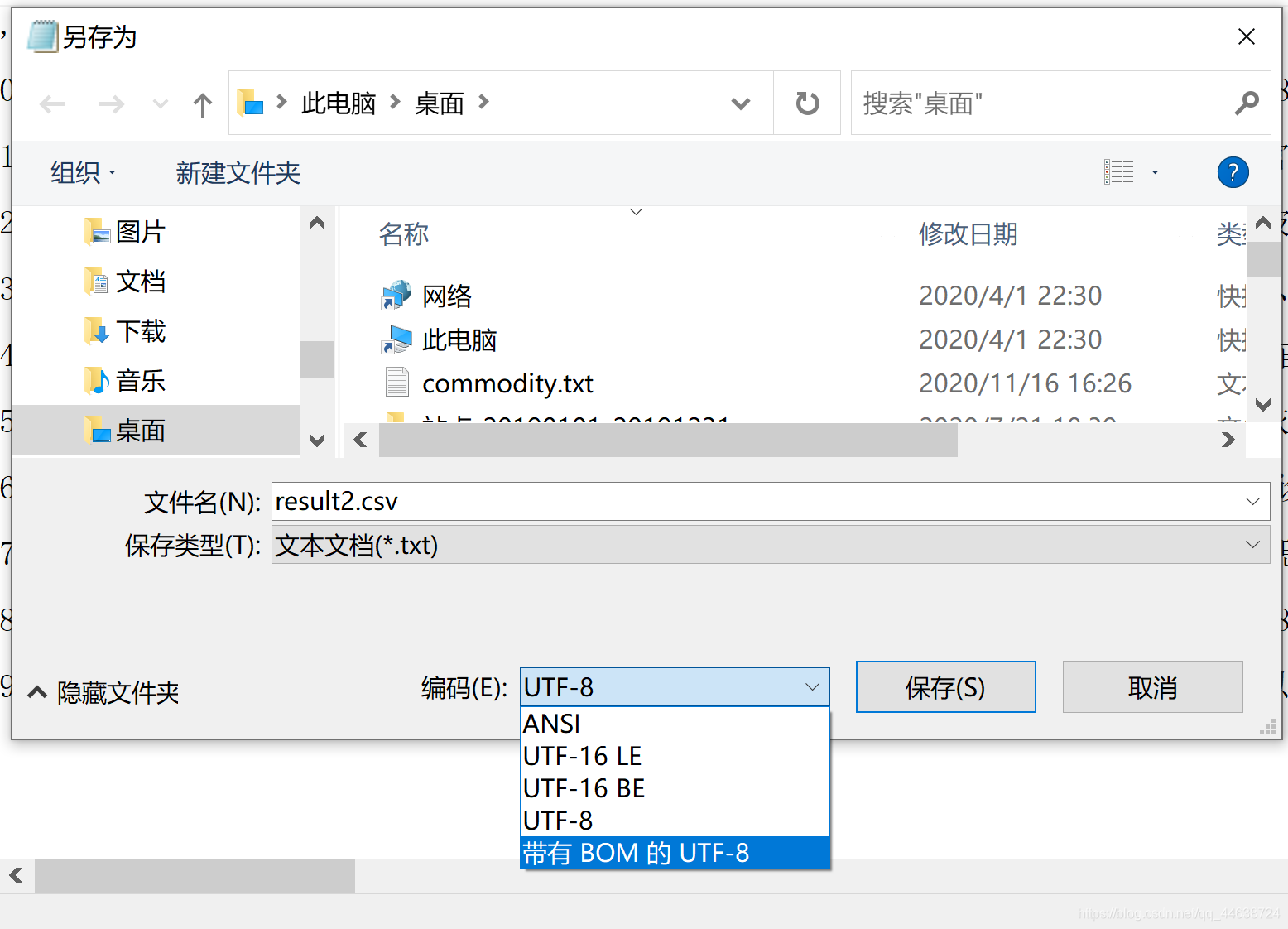
3. 再次打開csv檔案

可以看到中文顯示正常了, 但其中穿插著很多的空行. 解決辦法:選中第一列后點擊篩選
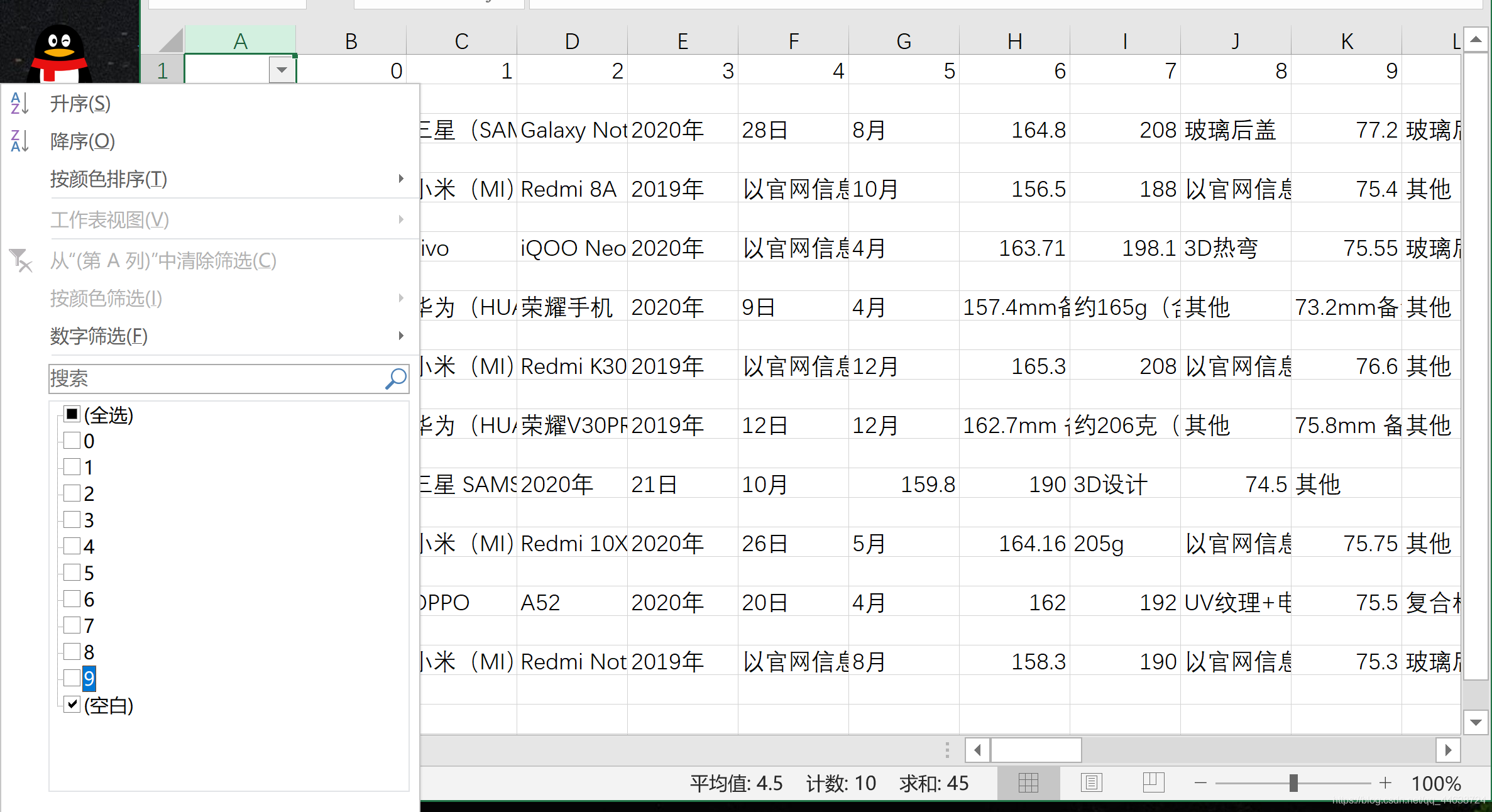
只選中空白行
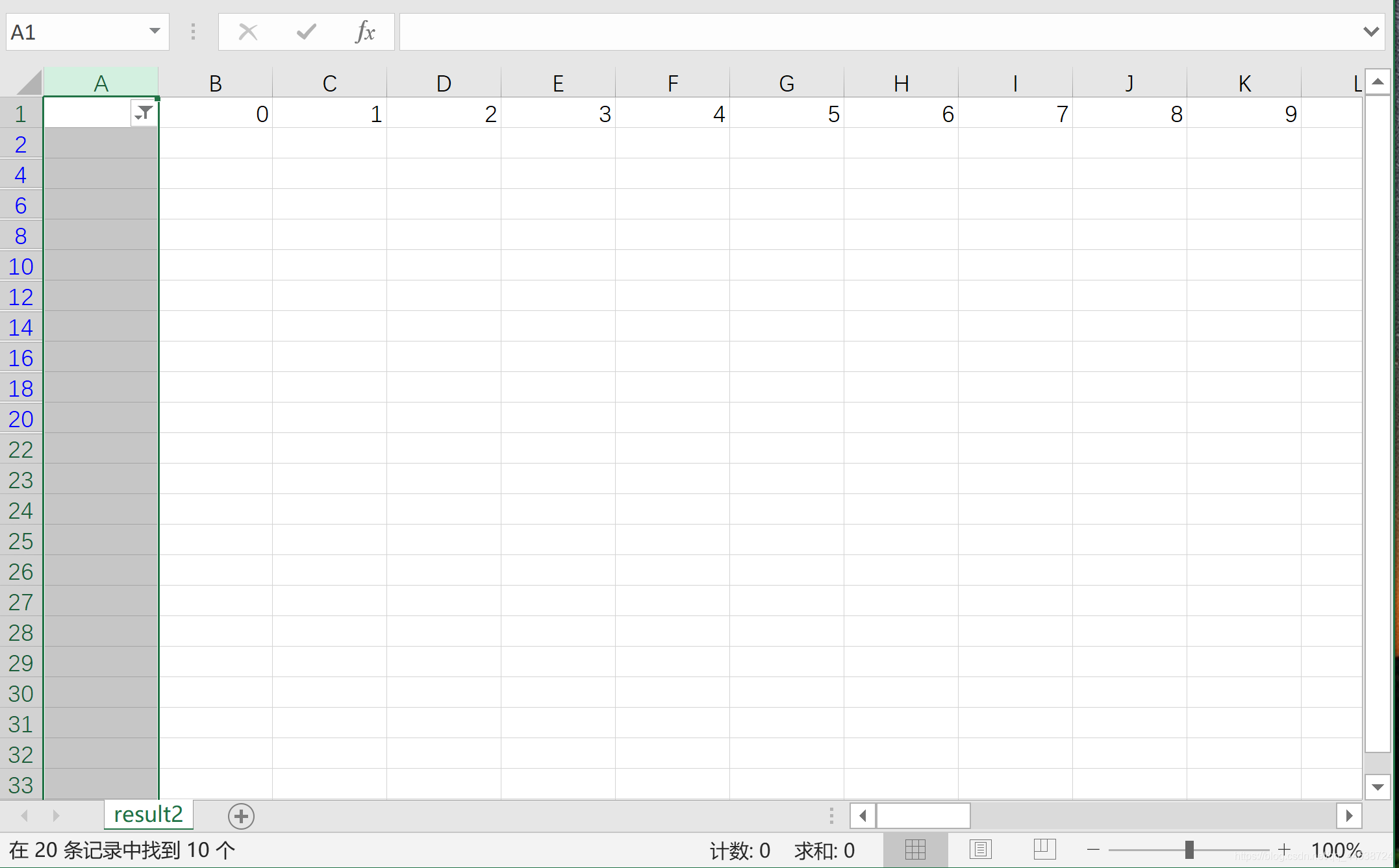
此時可以看到空白行已經用藍色標識出, 將其洗掉即可
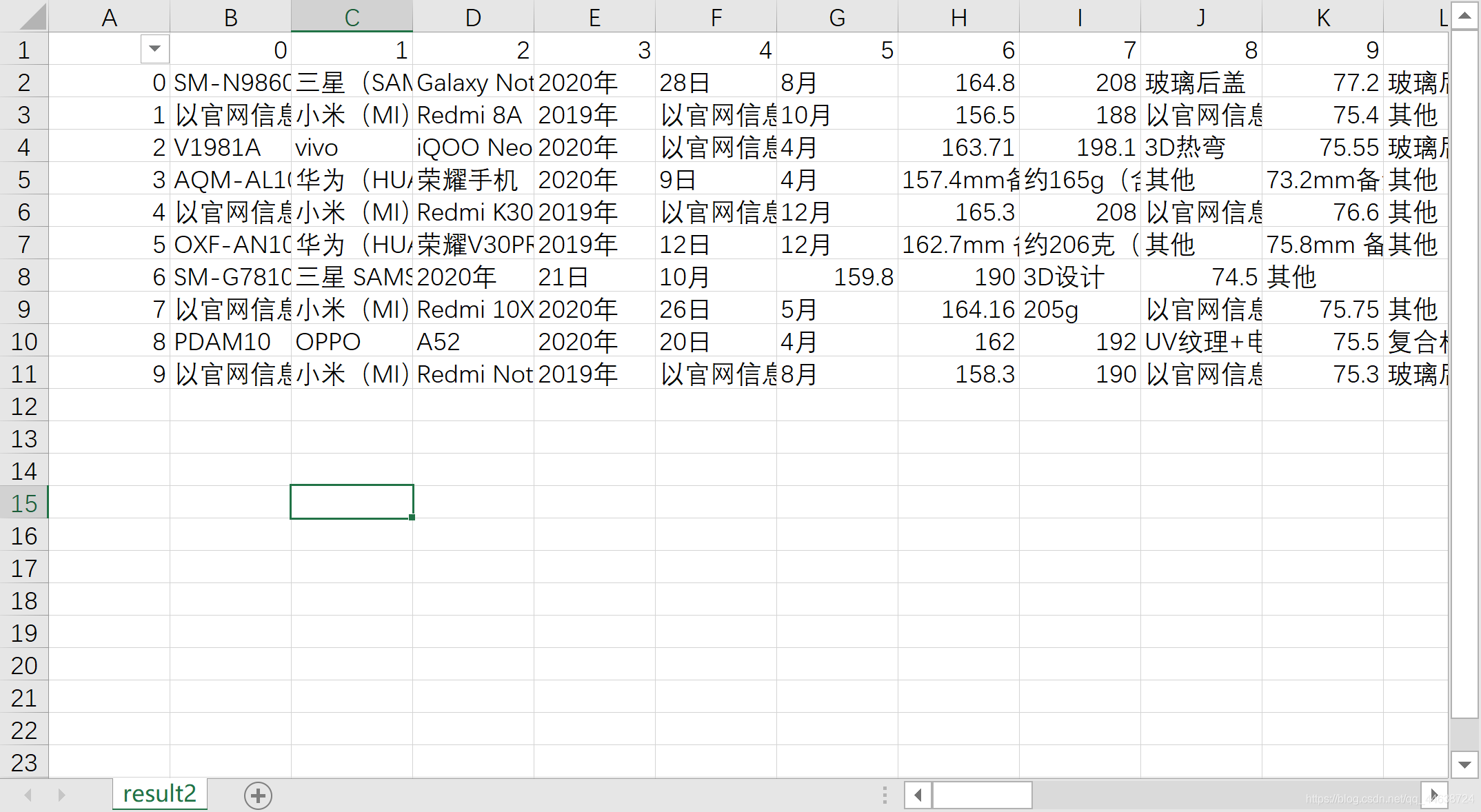
一些思考
實際上, 本文的代碼效率并不高, 再加上反爬蟲需要對程式掛起就更消耗時間和記憶體, 還需要進一步考慮多執行緒爬蟲和提高代碼效率.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/226869.html
標籤:python