一、DDT資料驅動
1、DDT安裝
windows、mac os系統,在CMD或者終端內輸入:pip install ddt
2、DDT使用實體
import ddt
import unittest
@ddt.ddt
class TestDDT(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
@ddt.data(1,2,3)
def test_01(self, a):
self.assertEqual(a,2)
運行結果如圖:
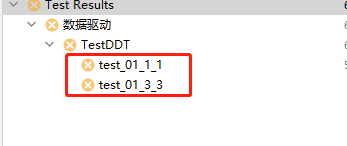
3、DDT中data所可以使用的資料型別
單引數可以傳int, str
@ddt.data('1','2','3')
def test_01(self, a):
self.assertEqual(a,2)
運行結果如圖:
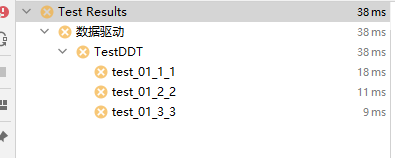
多引數可以傳tuple, list, dict
@ddt.data([1,2], [2, 3])
@ddt.unpack
def test_01(self, a, b):
self.assertEqual(a,b)
@ddt.data({'a':'1', 'b':'2'}, {'a':'1', 'b':'2'}, {'a':'1', 'b':'2'})
@ddt.unpack
def test_02(self, a, b):
self.assertEqual(b, a)
運行結果如圖:
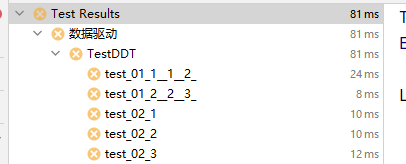
我們通過觀察上面單引數和多引數,可以總結出一些特點和步驟:
步驟:
第一步:需要使用ddt的檔案,先要匯入ddt包,import ddt
第二步,在測驗類上面,使用ddt裝飾器,
第三步,在需要大量資料進行驗證的測驗方法上面使用@ddt.data()
注意:ddt.data()這個方法是緊挨著要使用資料的測驗用例的,
特點:
(1)DDT傳遞資料型別,與測驗用例中有幾個引數密切相關
(2)測驗用例特點,單引數、串列、元組用例型別類似,字典引數需要單獨記錄,如:
單引數:方法名_編號_引數1
多引數:方法名_編號_引數1_引數2_… …
字典型別引數: 方法名_編號
(3)unpack使用時機:當引數為多個的時候,需要使用@ddt.unpack, 可以理解為將資料包拆分
4、如何批量傳遞資料,并自動生成希望的變數格式
以excel批量傳遞測驗資料為例:
(1)讀取excel方法
# 引入一個新包,pip install pandas
import pandas as pd
class readExcelMethod():
"""
:fileName: 檔案路徑
:sheetName: sheet頁的名稱
"""
def __init__(self, fileName: str, sheetName='Sheet1'):
self.fileName = fileName # 檔案路徑
self.sheetName = sheetName # excel sheet頁的名稱
super(readExcelMethod, self).__init__()
def readExcel(cls):
df = pd.read_excel(cls.fileName, sheet_name=cls.sheetName)
df = df.T
testData = []
for i in range(len(df)):
testData.append(list(df[i]))
return testData
excel表格內容如圖:
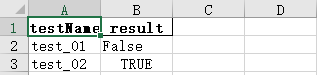
代碼運行結果如圖:

(2)如何將資料放入ddt.data()中,非常簡單,代碼如圖:
data = readExcelMethod(fileName='').readExcel()
@ddt.data(*data)
僅需要在讀取出的excel資料前增加一個【*】,便可以了,
二、unittest用例關聯
為什么單獨講一下unittest的用例關聯,是因為unittest沒有現成的用例關聯模塊可以進行呼叫,另外,用例與用例之間往往存在較強關聯性,舉例:登錄與退出的用例,退出用例的前提便是需要先要登錄成功才會驗證退出,結果登錄已經失敗了,其實很多情況便沒有必要在去執行退出的操作了,
因此需要單獨設計用例依賴的方法
其實用例設計依賴的核心思想,在于將依賴用例的執行狀態存起來
因此這個存,便非常有講究了
1、存在哪里?怎么存?
(1)借助輔助工具,如資料庫,excel,redis等媒介進行存盤
(2)存在本地快取,python 有現成的快取方法,在functools包下,如:lru_cache, 引入方法:from functools import lru_cache
(3)存在迭代器中,如List, dict中
知道了往哪里存, 怎么存了,但是存什么那?
2、存什么?怎么處理?
精細存:存具體用例失敗的原因,比如:例外原因,或者失敗的原因,根據具體例外,去存盤對應的資訊
粗略存:捕捉失敗原因,正確存True,錯誤存False, 根據例外存盤True or False
3、如何管理用例
首先跳過測驗的方法需要用到unittest.TestCase().SkipTest(),該方法為unittest框架中,內部跳過測驗用例的方法
(1)第一種:如果A與D是有關聯的,這時候,執行A,A通過與否都去執行D用例,不需要等到D用例執行,跳過B,C用例,直接執行D用例
(2)第二種:如果A與D是有關聯的,這時候,執行A用例,只需要將A用例的測驗結果存在臨時地方,然后待D執行的時候,在去獲取A的結果,來判斷D是否執行
1)通過輔助工具
2)通過快取
3)利用迭代器
4、本博主原創設計的2種用例關聯的方法:
(1)利用迭代器的做法,效果可以自己體驗
from functools import wraps
import unittest
testCaseName = {}
class decRelation:
"""
:name:被依賴的用例名稱
:depend:依賴的用例名稱
=======example=======
@decRelation(name='test_01')
def test_01(self):
self.assertEqual(2, 2)
@decRelation(depend='test_01')
def test_02(self):
self.assertEqual(1, 2)
"""
def __init__(self, name=None, depend=None):
self.depend = depend
self.name = name
super(decRelation, self).__init__()
def __call__(self, func):
@wraps(func)
def decoration(*args, **kwargs):
try:
if self.name:
if self.depend and testCaseName[self.depend] is True:
func(*args, **kwargs)
testCaseName[self.name] = True
elif self.depend is None:
func(*args, **kwargs)
testCaseName[self.name] = True
if self.depend and testCaseName[self.depend] is not True:
unittest.TestCase().skipTest(reason="%s 測驗用例執行失敗,相關依賴用例跳過!!!" % (self.depend))
testCaseName[func.__name__] = 'Skip'
else:
result = func(*args, **kwargs)
testCaseName[func.__name__] = True
return result
except Exception as e:
if self.name and self.name not in testCaseName.keys():
testCaseName[self.name] = False
if self.depend and self.depend not in testCaseName.keys():
testCaseName[self.depend] = False
raise e
return decoration
(2)利用excel做中間器的方式,適合excel存放大批量測驗用例的方式
讀取excel與保存excel方法封裝
class dealExcelMethod():
"""
:fileName: 檔案路徑
:sheetName: sheet頁的名稱
"""
def __init__(self, fileName:str, sheetName='Sheet1'):
self.fileName = fileName # 檔案路徑
self.sheetName = sheetName # excel sheet頁的名稱
super(dealExcelMethod, self).__init__()
# 讀取資料
def readExcelDDt(cls):
df = pd.read_excel(cls.fileName, sheet_name=cls.sheetName, keep_default_na=False)
listNum = len(df)
df = df.T
testData = []
for i in range(listNum):
testData.append(list(df[i]))
return testData
# 寫入資料
def saveExcel(cls, testMethod:str, statusCode:str, testCaseNum:int):
df = pd.read_excel(cls.fileName, sheet_name=cls.sheetName, keep_default_na=False)
df.loc[testCaseNum, 'testName'] = testMethod
df.loc[testCaseNum, 'result'] = statusCode
writer = pd.ExcelWriter(cls.fileName)
df.to_excel(excel_writer=writer, index=False)
writer.save()
return df
這里的欄位,需要根據自己實際所需要的欄位進行填寫,我只是這個作為例子,進行演示一下excel設計的方法
實際測驗用例使用部分代碼
from inspect import stack
# 通過輔助工具做用例關聯
# example: excel
from webUI.readExcel import dealExcelMethod
import unittest
def readExcel():
fileName = ''
data = dealExcelMethod(fileName=fileName, sheetName='Sheet1').readExcelDDt()
return data
def saveExcel(testMethod,statusCode,testCaseNum):
fileName = ''
dealExcelMethod(fileName=fileName, sheetName='Sheet1').saveExcel(testMethod,statusCode,testCaseNum)
class TestExcel(unittest.TestCase):
def test_01(self):
try:
self.assertEqual(1,2)
saveExcel(testMethod=stack()[0][3], statusCode='True', testCaseNum=0)
except Exception as e:
saveExcel(testMethod=stack()[0][3], statusCode='False', testCaseNum=0)
raise e
def test_02(self):
try:
print(readExcel())
if readExcel()[1][1]:
self.assertEqual(2,2)
else:
self.skipTest(reason='該條測驗用例跳過')
except Exception as e:
raise e
excel的方法,僅作為拋轉引玉,為大家提供一個思路,
其實第一種方法,那個方法在很多情況,可以解決當前所需要的用例關聯問題,并且代碼簡潔清晰,若是大家需要做用例關聯的話,建議用第一種方法,另外,希望大家覺得我的方法還可以,希望大家能給點個贊,加個關注,后續我有好的方法,我會繼續分享的~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/227536.html
標籤:python