Java版本:8u261,
1 簡介
ScheduledThreadPoolExecutor即定時執行緒池,是用來執行延遲任務或周期性任務的,相比于Timer的單執行緒,定時執行緒池在遇到任務拋出例外的時候不會關閉整個執行緒池,更加健壯(需要提一下的是:ScheduledThreadPoolExecutor和ThreadPoolExecutor一樣,如果執行任務的程序中拋例外的話,這個任務是會被丟棄的,所以在任務的執行程序中需要對例外做捕獲處理,有必要的話需要做補償措施),
傳進來的任務會被包裝為ScheduledFutureTask,其繼承于FutureTask,提供異步執行的能力,并且可以回傳執行結果,同時實作了Delayed介面,可以通過getDelay方法來獲取延遲時間,
相比于ThreadPoolExecutor,ScheduledThreadPoolExecutor中使用的佇列是DelayedWorkQueue,是一個無界的佇列,所以在定時執行緒池中,最大執行緒數是沒有意義的(最大執行緒數會固定為int的最大值,且不會作為定時執行緒池的引數),在ThreadPoolExecutor中,如果當前執行緒數小于核心執行緒數就直接創建核心執行緒來執行任務,大于等于核心執行緒數的話才往阻塞佇列中放入任務;而在ScheduledThreadPoolExecutor中卻不是這種邏輯,ScheduledThreadPoolExecutor中上來就會把任務放進延遲佇列中,然后再去等待執行,
1.1 小頂堆
DelayedWorkQueue的實作有些特殊,是基于小頂堆構建的(與DelayQueue和PriorityQueue類似),因為要保證每次從延遲佇列中拿取到的任務是距現在最近的一個,所以使用小頂堆結構來構建是再適合不過了(堆結構也常常用來解決前N小和前N大的問題),小頂堆保證每個節點的值不小于其父節點的值,而不大于其孩子節點的值,而對于同級節點來說則沒有什么限制,這樣在小頂堆中值最小的點永遠保證是在根節點處,如果用陣列來構建小頂堆的話,值最小的點就在陣列中的第一個位置處,
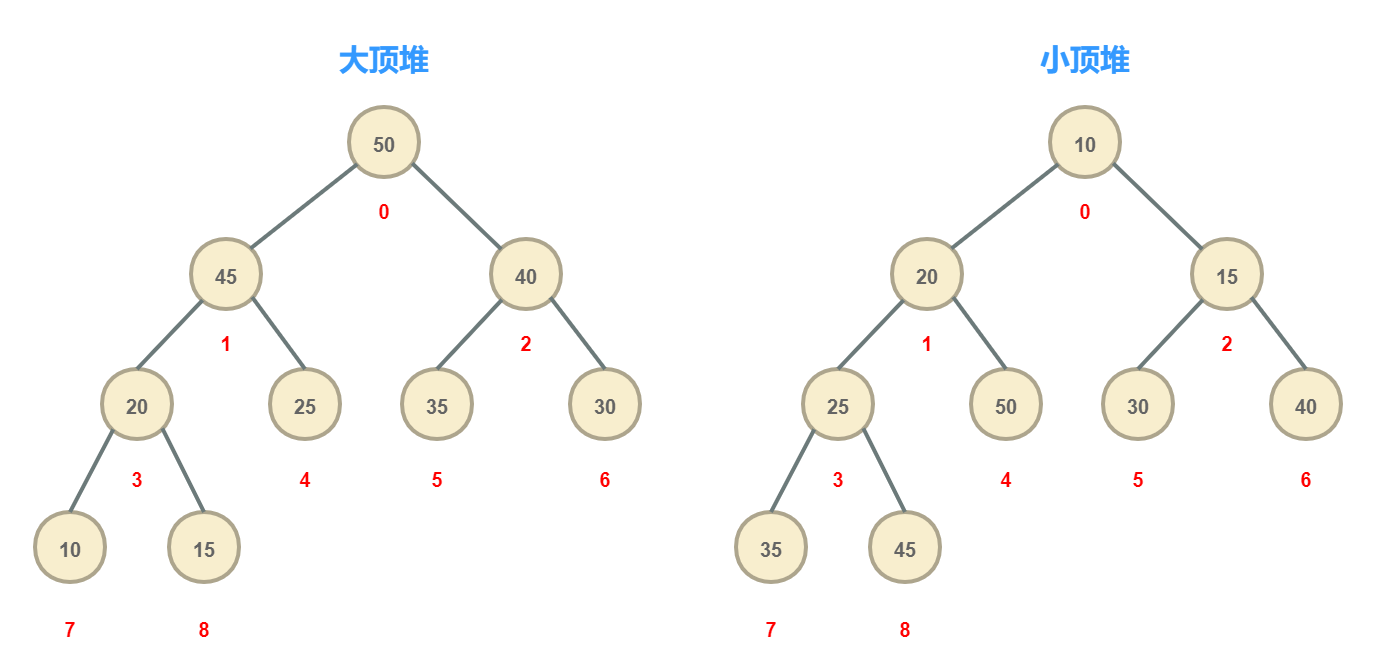
圖中紅色的數字代表節點在陣列中的索引位置,由此可以看出堆的另一條性質是:假設當前節點的索引是k,那么其父節點的索引是:(k-1)/2;左孩子節點的索引是:k2+1;而右孩子節點的索引是k2+2,
構建堆的兩個核心方法是siftUp和siftDown,siftUp方法用于添加節點時的上溯程序;而siftDown方法用于洗掉節點時的下溯程序,具體的實作原始碼會在下面進行分析,這里就畫圖來理解一下(下面只會分析經典的小頂堆添加和洗掉節點的實作,而在原始碼中的實作略有不同,但核心都是一樣的):
1.1.1 添加節點
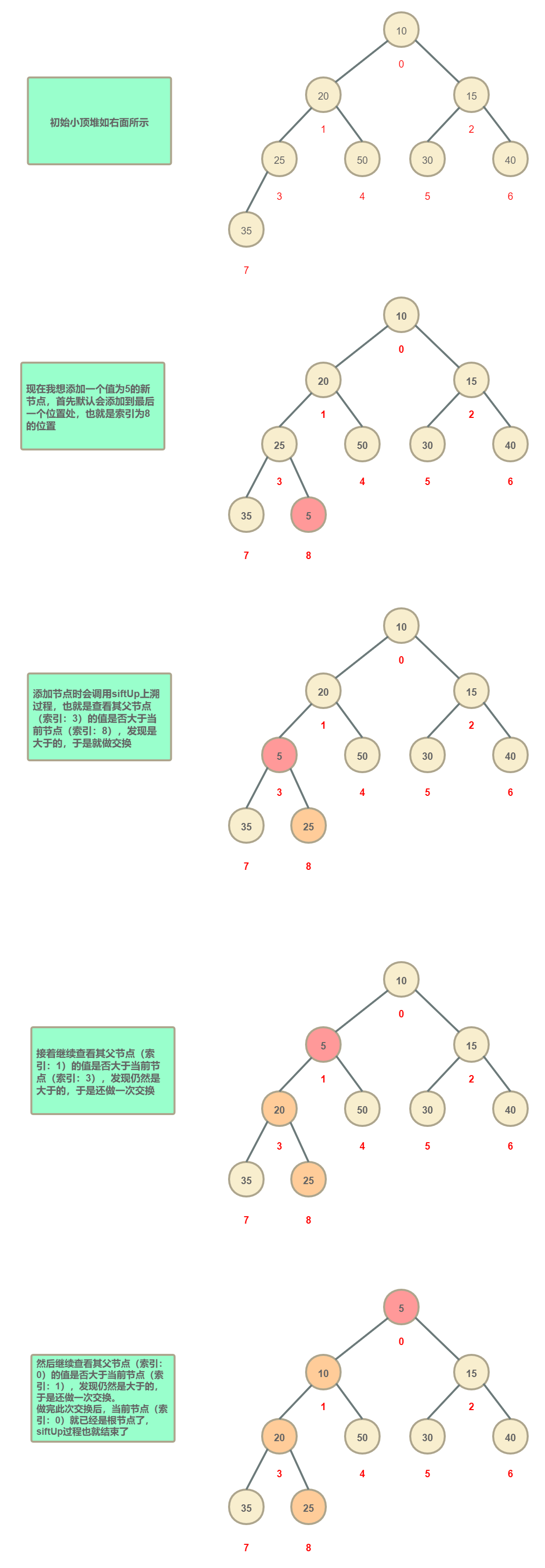
如果在上面的siftUp程序中,發現某一次當前節點的值就已經大于了父節點的值,siftUp程序也就會提前終止了,同時可以看出:在上面的siftUp以及下面將要講的siftDown操作程序中,每次都只會比較并交換當前節點和其父子節點的值,而不是整個堆都發生變動,降低了時間復雜度,
1.1.2 洗掉節點
洗掉節點分為三種情況,首先來看一下洗掉根節點的情況:
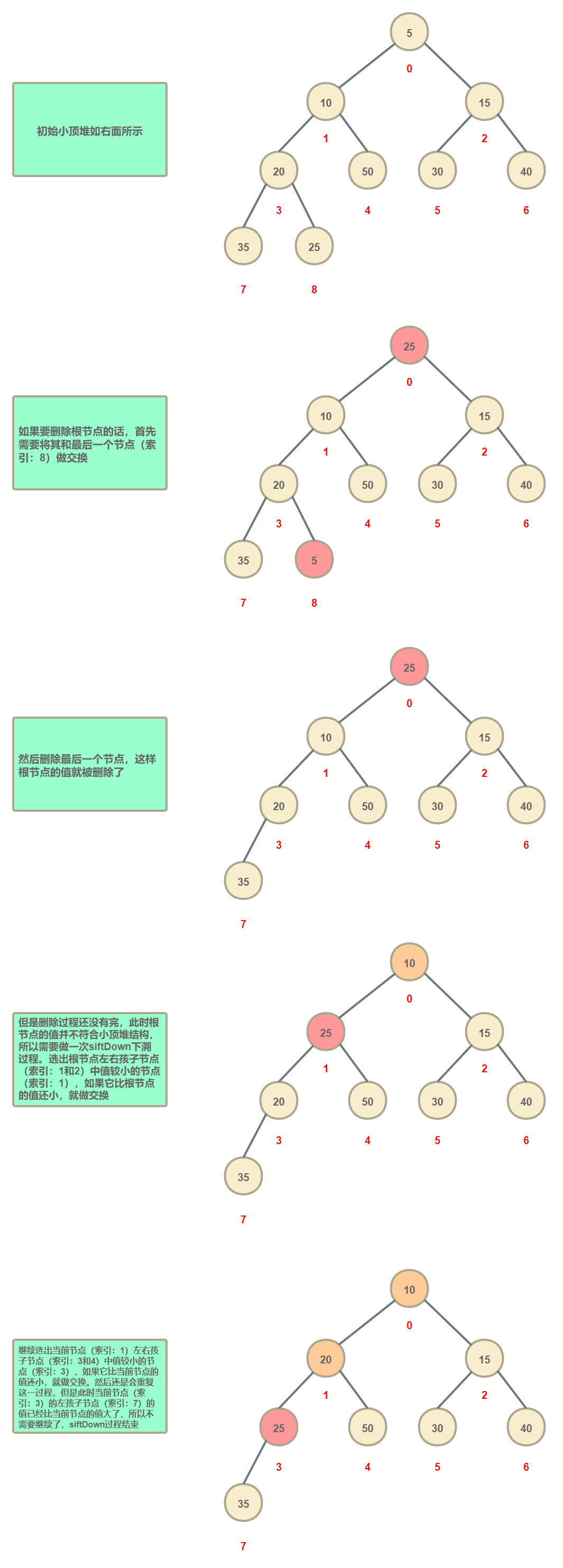
然后是洗掉最后一個節點的情況,洗掉最后一個節點是最簡單的,只需要進行洗掉就行了,因為這并不影響小頂堆的結構,不需要進行調整,這里就不再展示了(注意:洗掉除了最后一個節點的其他葉子節點并不屬于當前這種情況,而是屬于下面第三種情況,也就是說洗掉這些葉子節點并不能簡單地洗掉它們就完了的,因為堆結構首先得保證是一顆完全二叉樹),
最后是洗掉既不是根節點又不是最后一個節點的情況:
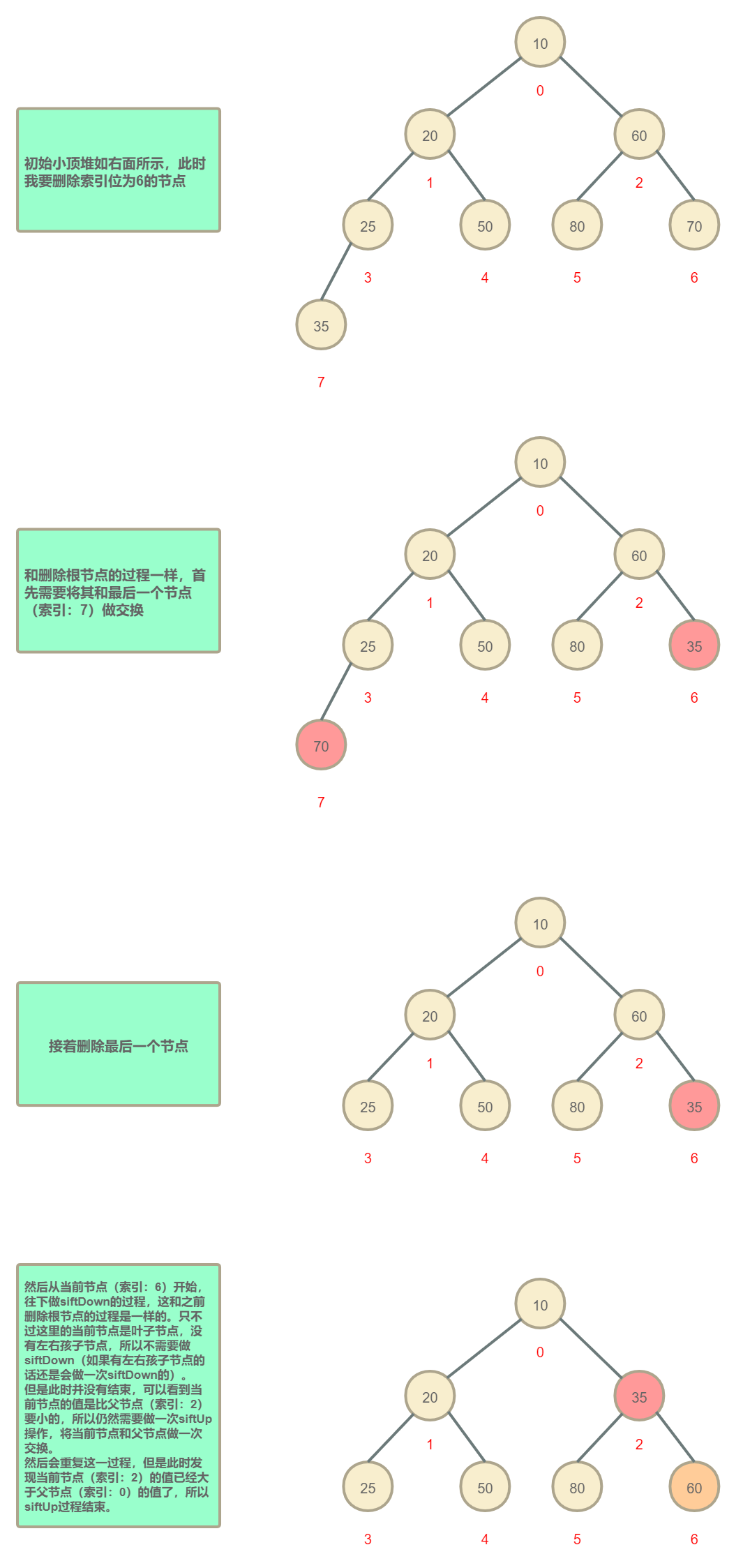
在洗掉既不是根節點又不是最后一個節點的時候,可以看到執行了一次siftDown并伴隨了一次siftUp的程序,但是這個siftUp程序并不是會一定觸發的,只有滿足最后一個節點的值比要洗掉節點的父節點的值還要小的時候才會觸發siftUp操作(這個很好推理:在小頂堆中如果最后一個節點值比要洗掉節點的父節點值要小的話,那么要洗掉節點的左右孩子節點值也必然是都大于最后一個節點值的(不考慮值相等的情況),那么此時就不會發生siftDown操作;而如果發生了siftDown操作,就說明最后一個節點值至少要比要洗掉節點的左右孩子節點中的一個要大(如果有左右孩子節點的話),而孫子節點值是肯定要大于爺爺節點值的(不考慮值相等的情況),所以也就是說發生了siftDown操作的時候,最后一個節點值是比要洗掉節點的父節點值大的,這個時候孫子節點和最后一個節點siftDown交換后,依然是滿足小頂堆性質的,所以就不需要附加的siftUp操作;還有一種情況是最后一個節點值是介于要洗掉節點的父節點值和要洗掉節點的左右孩子節點值中的較小者,那么這個時候既不會發生siftDown,也不會發生siftUp),
而原始碼中的實作和上面的經典實作最大的不同就是不會有節點彼此交換的操作,在siftUp和siftDown的經典實作中,如果需要變動節點時,都會來一次父子節點的互相交換操作(包括洗掉節點時首先做的要洗掉節點和最后一個節點之間的交換操作也是如此),如果仔細思考的話,就會發現這其實是多余的,在需要交換節點的時候,只需要siftUp操作時的父節點或siftDown時的孩子節點重新移到當前需要比較的節點位置上,而比較節點是不需要移動到它們的位置上的,此時直接進入到下一次的判斷中,重復siftUp或siftDown程序,直到最后找到了比較節點的插入位置后,才會將其插入進去,這樣做的好處是可以省去一半的節點賦值的操作,提高了執行的效率,同時這也就意味著,需要將要比較的節點作為引數保存起來,而原始碼中也正是這么實作的,
1.2 Leader-Follower模式
ScheduledThreadPoolExecutor中使用了Leader-Follower模式,這是一種設計思想,假如說現在有一堆等待執行的任務(一般是存放在一個佇列中排好序),而所有的作業執行緒中只會有一個是leader執行緒,其他的執行緒都是follower執行緒,只有leader執行緒能執行任務,而剩下的follower執行緒則不會執行任務,它們會處在休眠中的狀態,當leader執行緒拿到任務后執行任務前,自己會變成follower執行緒,同時會選出一個新的leader執行緒,然后才去執行任務,如果此時有下一個任務,就是這個新的leader執行緒來執行了,并以此往復這個程序,當之前那個執行任務的執行緒執行完畢再回來時,會判斷如果此時已經沒任務了,又或者有任務但是有其他的執行緒作為leader執行緒,那么自己就休眠了;如果此時有任務但是沒有leader執行緒,那么自己就會重新成為leader執行緒來執行任務,
不像ThreadPoolExecutor是需要立即執行任務的,ScheduledThreadPoolExecutor中的任務是延遲執行的,而拿取任務也是延遲拿取的,所以并不需要所有的執行緒都處于運行狀態延時等待獲取任務,而如果這么做的話,最后也只會有一個執行緒能執行當前任務,其他的執行緒還是會被再次休眠的(這里只是在說單任務多執行緒的情況,但對于多任務來說也是一樣的,總結來說就是Leader-Follower模式只會喚醒真正需要“干事”的執行緒),這是很沒有必要的,而且浪費資源,所以使用Leader-Follower模式的好處是:避免沒必要的喚醒和阻塞的操作,這樣會更加有效,且節省資源,
2 構造器
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public ScheduledThreadPoolExecutor(int corePoolSize) {
5 super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
6 new DelayedWorkQueue());
7 }
8
9 /**
10 * ThreadPoolExecutor:
11 */
12 public ThreadPoolExecutor(int corePoolSize,
13 int maximumPoolSize,
14 long keepAliveTime,
15 TimeUnit unit,
16 BlockingQueue<Runnable> workQueue) {
17 this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
18 Executors.defaultThreadFactory(), defaultHandler);
19 }
可以看到:ScheduledThreadPoolExecutor的構造器是呼叫了父類ThreadPoolExecutor的構造器來實作的,而父類的構造器以及之中的所有引數我在之前分析ThreadPoolExecutor的原始碼文章中講過,這里就不再贅述了,
3 schedule方法
execute方法和submit方法內部都是呼叫的schedule方法,所以來看一下其實作:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public ScheduledFuture<?> schedule(Runnable command,
5 long delay,
6 TimeUnit unit) {
7 //非空校驗
8 if (command == null || unit == null)
9 throw new NullPointerException();
10 //包裝任務
11 RunnableScheduledFuture<?> t = decorateTask(command,
12 new ScheduledFutureTask<Void>(command, null,
13 triggerTime(delay, unit)));
14 //延遲執行
15 delayedExecute(t);
16 return t;
17 }
18
19 /**
20 * 第13行代碼處:
21 * 延遲操作的觸發時間
22 */
23 private long triggerTime(long delay, TimeUnit unit) {
24 //delay非負處理
25 return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));
26 }
27
28 long triggerTime(long delay) {
29 /*
30 now方法內部就一句話:“System.nanoTime();”,也就是獲取當前時間,這里也就是獲取
31 當前時間加上延遲時間后的結果,如果延遲時間超過了上限,會在overflowFree方法中處理
32 */
33 return now() +
34 ((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
35 }
36
37 private long overflowFree(long delay) {
38 //獲取隊頭節點(不移除)
39 Delayed head = (Delayed) super.getQueue().peek();
40 if (head != null) {
41 //獲取隊頭的剩余延遲時間
42 long headDelay = head.getDelay(NANOSECONDS);
43 /*
44 能走進本方法中,就說明delay是一個接近long最大值的數,此時判斷如果headDelay小于0
45 就說明延遲時間已經到了或過期了但是還沒有執行,并且delay和headDelay的差值小于0,說明headDelay
46 和delay的差值已經超過了long的范圍
47 */
48 if (headDelay < 0 && (delay - headDelay < 0))
49 //此時更新一下delay的值,確保其和headDelay的差值在long的范圍內,同時delay也會重新變成一個正數
50 delay = Long.MAX_VALUE + headDelay;
51 }
52 return delay;
53 }
54
55 /**
56 * 第39行代碼處:
57 * 呼叫DelayedWorkQueue中覆寫的peek方法來獲取隊頭節點
58 */
59 public RunnableScheduledFuture<?> peek() {
60 final ReentrantLock lock = this.lock;
61 lock.lock();
62 try {
63 return queue[0];
64 } finally {
65 lock.unlock();
66 }
67 }
68
69 /**
70 * 第42行代碼處:
71 * 可以看到本方法就是獲取延遲時間和當前時間的差值
72 */
73 public long getDelay(TimeUnit unit) {
74 return unit.convert(time - now(), NANOSECONDS);
75 }
4 包裝任務
上面第11行和第12行代碼處會進行任務的包裝:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 ScheduledFutureTask(Runnable r, V result, long ns) {
5 //呼叫父類FutureTask的構造器
6 super(r, result);
7 //這里會將延遲時間賦值給this.time
8 this.time = ns;
9 //period用來表示任務的型別,為0表示延遲任務,否則表示周期性任務
10 this.period = 0;
11 //這里會給每一個任務賦值一個唯一的序列號,當延遲時間相同時,會以該序列號來進行判斷,序列號小的會出隊
12 this.sequenceNumber = sequencer.getAndIncrement();
13 }
14
15 /**
16 * schedule方法第11行代碼處:
17 * 包裝任務,這里只是回傳task而已,子類可以覆寫本方法中的邏輯
18 */
19 protected <V> RunnableScheduledFuture<V> decorateTask(
20 Runnable runnable, RunnableScheduledFuture<V> task) {
21 return task;
22 }
5 delayedExecute方法
在schedule方法的第15行代碼處會執行延遲任務,添加任務和補充作業執行緒:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 private void delayedExecute(RunnableScheduledFuture<?> task) {
5 if (isShutdown())
6 /*
7 這里會呼叫父類ThreadPoolExecutor的isShutdown方法來判斷當前執行緒池是否處于關倍訓正在關閉的狀態,
8 如果是的話就執行具體的拒絕策略
9 */
10 reject(task);
11 else {
12 //否則就往延遲佇列中添加當前任務
13 super.getQueue().add(task);
14 /*
15 添加后繼續判斷當前執行緒池是否處于關倍訓正在關閉的狀態,如果是的話就判斷此時是否還能繼續執行任務,
16 如果不能的話就洗掉上面添加的任務
17 */
18 if (isShutdown() &&
19 !canRunInCurrentRunState(task.isPeriodic()) &&
20 remove(task))
21 //同時會取消此任務的執行
22 task.cancel(false);
23 else
24 //否則,說明執行緒池是可以繼續執行任務的,就去判斷此時是否需要補充作業執行緒
25 ensurePrestart();
26 }
27 }
28
29 /**
30 * 第19行代碼處:
31 * 傳進來的periodic表示任務是否是周期性任務,如果是的話就是true(通過“period != 0”進行判斷)
32 */
33 boolean canRunInCurrentRunState(boolean periodic) {
34 return isRunningOrShutdown(periodic ?
35 //關閉執行緒池時判斷是否需要繼續執行周期性任務
36 continueExistingPeriodicTasksAfterShutdown :
37 //關閉執行緒池時判斷是否需要繼續執行延遲任務
38 executeExistingDelayedTasksAfterShutdown);
39 }
40
41 /**
42 * ThreadPoolExecutor:
43 */
44 final boolean isRunningOrShutdown(boolean shutdownOK) {
45 //獲取當前執行緒池的運行狀態
46 int rs = runStateOf(ctl.get());
47 //如果是RUNNING狀態的,或者是SHUTDOWN狀態并且是能繼續執行任務的,就回傳true
48 return rs == RUNNING || (rs == SHUTDOWN && shutdownOK);
49 }
50
51 /**
52 * ScheduledThreadPoolExecutor:
53 * 上面第20行代碼處的remove方法會呼叫ThreadPoolExecutor的remove方法,而該方法我在之前的
54 * ThreadPoolExecutor的原始碼分析文章中已經分析過了,但是其中會呼叫延遲佇列覆寫的remove邏輯,
55 * 也就是本方法(同時第130行代碼處也會呼叫到這里)
56 */
57 public boolean remove(Object x) {
58 final ReentrantLock lock = this.lock;
59 //加鎖
60 lock.lock();
61 try {
62 //獲取當前節點的堆索引位
63 int i = indexOf(x);
64 if (i < 0)
65 //如果找不到的話,就直接回傳false
66 return false;
67
68 //將當前節點的索引位設定為-1,因為下面要進行洗掉了
69 setIndex(queue[i], -1);
70 //size-1
71 int s = --size;
72 //獲取小頂堆的最后一個節點,用于替換
73 RunnableScheduledFuture<?> replacement = queue[s];
74 //將最后一個節點置為null
75 queue[s] = null;
76 //如果要洗掉的節點本身就是最后一個節點的話,就可以直接回傳true了,因為不影響小頂堆的結構
77 if (s != i) {
78 /*
79 否則執行一次siftDown下溯程序,將最后一個節點的值重新插入到小頂堆中
80 這其中會洗掉i位置處的節點(siftDown方法后面會再次呼叫,到時候再來詳細分析該方法的實作)
81 */
82 siftDown(i, replacement);
83 /*
84 經過上面的siftDown的操作后,如果最后一個節點的延遲時間本身就比要洗掉的節點的小的話,
85 那么就會直接將最后一個節點放在要洗掉節點的位置上,此時從洗掉節點到其下面的節點都是滿足
86 小頂堆結構的,但是不能保證replacement也就是當前洗掉后的替換節點和其父節點之間滿足小頂堆
87 結構,也就是說可能出現replacement節點的延遲時間比其父節點的還小的情況
88 */
89 if (queue[i] == replacement)
90 //那么此時就呼叫一次siftUp上溯操作,再次調整replacement節點其上的小頂堆的結構即可
91 siftUp(i, replacement);
92 }
93 return true;
94 } finally {
95 //釋放鎖
96 lock.unlock();
97 }
98 }
99
100 /**
101 * 第63行代碼處:
102 */
103 private int indexOf(Object x) {
104 if (x != null) {
105 if (x instanceof ScheduledFutureTask) {
106 //如果當前節點是ScheduledFutureTask型別的,就獲取它的堆索引位
107 int i = ((ScheduledFutureTask) x).heapIndex;
108 //大于等于0和小于size說明當前節點還在小頂堆中,并且當前節點還在延遲佇列中的話,就直接回傳該索引位
109 if (i >= 0 && i < size && queue[i] == x)
110 return i;
111 } else {
112 //否則就按照普通遍歷的方式查找是否有相等的節點,如果有的話就回傳索引位
113 for (int i = 0; i < size; i++)
114 if (x.equals(queue[i]))
115 return i;
116 }
117 }
118 //找不到的話就回傳-1
119 return -1;
120 }
121
122 /**
123 * 第22行代碼處:
124 */
125 public boolean cancel(boolean mayInterruptIfRunning) {
126 //呼叫FutureTask的cancel方法來嘗試取消此任務的執行
127 boolean cancelled = super.cancel(mayInterruptIfRunning);
128 //如果取消成功了,并且允許洗掉節點,并且當前節點存在于小頂堆中的話,就洗掉它
129 if (cancelled && removeOnCancel && heapIndex >= 0)
130 remove(this);
131 return cancelled;
132 }
133
134 /**
135 * ThreadPoolExecutor:
136 * 第25行代碼處:
137 */
138 void ensurePrestart() {
139 //獲取當前執行緒池的作業執行緒數
140 int wc = workerCountOf(ctl.get());
141 if (wc < corePoolSize)
142 /*
143 如果小于核心執行緒數,就添加一個核心執行緒,之前我在分析ThreadPoolExecutor的原始碼文章中講過,
144 addWorker方法的執行中會同時啟動運行執行緒,這里傳入的firstTask引數為null,因為不需要立即執行任務,
145 而是從延遲佇列中拿取任務
146 */
147 addWorker(null, true);
148 else if (wc == 0)
149 //如果當前沒有作業執行緒,就去添加一個非核心執行緒,然后運行它,保證至少要有一個執行緒
150 addWorker(null, false);
151 /*
152 從這里可以看出,如果當前的作業執行緒數已經達到了核心執行緒數后,就不會再創建作業執行緒了
153 定時執行緒池最多只有“核心執行緒數”個執行緒,也就是通過構造器傳進來的引數大小
154 */
155 }
6 添加任務
因為延遲佇列是用小頂堆構建的,所以添加的時候會涉及到小頂堆的調整:
1 /**
2 * ScheduledThreadPoolExecutor:
3 * 這里會呼叫DelayedWorkQueue的add方法
4 */
5 public boolean add(Runnable e) {
6 return offer(e);
7 }
8
9 public boolean offer(Runnable x) {
10 //非空校驗
11 if (x == null)
12 throw new NullPointerException();
13 //強轉型別
14 RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>) x;
15 final ReentrantLock lock = this.lock;
16 //加鎖
17 lock.lock();
18 try {
19 //獲取當前的任務數量
20 int i = size;
21 //判斷是否需要擴容(初始容量為16)
22 if (i >= queue.length)
23 grow();
24 //size+1
25 size = i + 1;
26 if (i == 0) {
27 //如果當前是第一個任務的話,就直接放在小頂堆的根節點位置處就行了(佇列第一個位置)
28 queue[0] = e;
29 //同時設定一下當前節點的堆索引位為0
30 setIndex(e, 0);
31 } else {
32 //否則就用siftUp的方式來插入到應該插入的位置
33 siftUp(i, e);
34 }
35 //經過上面的插入程序之后,如果小頂堆的根節點還是當前新添加節點的話,說明新添加節點的延遲時間是最短的
36 if (queue[0] == e) {
37 //那么此時不管有沒有leader執行緒,都得將其置為null
38 leader = null;
39 /*
40 并且重新將條件佇列上的一個節點轉移到CLH佇列中(如果當前只有一個節點的時候也會進入到signal方法中
41 但無妨,因為此時條件佇列中還沒有節點,所以并不會做什么)需要提一點的是:如果真的看過signal方法內部實作
42 的話就會知道,signal方法在常規情況下并不是在做喚醒執行緒的作業,喚醒是在下面的unlock方法中實作的
43 */
44 available.signal();
45 }
46 } finally {
47 /*
48 釋放鎖(注意,這里只會喚醒CLH佇列中的head節點的下一個節點,可能是上面被鎖住的添加任務的其他執行緒、
49 也可能是上次執行完任務后準備再次拿取任務的執行緒,還有可能是等待被喚醒的follower執行緒,又或者有其他的
50 情況,但不管是哪個,只要能保證喚醒動作是一直能被傳播下去的就行,ReentrantLock和阻塞佇列的執行細節
51 詳見我之前對AQS原始碼進行分析的文章)
52 */
53 lock.unlock();
54 }
55 return true;
56 }
57
58 /**
59 * 第23行代碼處:
60 */
61 private void grow() {
62 int oldCapacity = queue.length;
63 //可以看到這里的擴容策略是*1.5的方式
64 int newCapacity = oldCapacity + (oldCapacity >> 1);
65 //如果擴容后的新容量溢位了,就將其恢復為int的最大值
66 if (newCapacity < 0)
67 newCapacity = Integer.MAX_VALUE;
68 //使用Arrays.copyOf(System.arraycopy)的方式來進行陣列的拷貝
69 queue = Arrays.copyOf(queue, newCapacity);
70 }
71
72 /**
73 * 第30行、第99行和第109行代碼處:
74 * 設定f節點在小頂堆中的索引位為idx,這樣在最后的洗掉節點時可以通過index是否大于0來判斷當前節點是否仍在小頂堆中
75 */
76 private void setIndex(RunnableScheduledFuture<?> f, int idx) {
77 if (f instanceof ScheduledFutureTask)
78 ((ScheduledFutureTask) f).heapIndex = idx;
79 }
80
81 /**
82 * 第33行代碼處:
83 * 堆排序的精髓就在于siftUp和siftDown方法,但本實作與常規的實作略有不同,多了一個入參key
84 * key代表當前要插入節點中的任務
85 */
86 private void siftUp(int k, RunnableScheduledFuture<?> key) {
87 //當k<=0的時候說明已經上溯到根節點了
88 while (k > 0) {
89 //獲取父節點的索引((當前節點索引位-1)/2的方式)
90 int parent = (k - 1) >>> 1;
91 //獲取父節點的任務
92 RunnableScheduledFuture<?> e = queue[parent];
93 //如果當前要插入節點中的任務延遲時間大于父節點的延遲時間的話,就停止上溯程序,說明找到了插入的位置
94 if (key.compareTo(e) >= 0)
95 break;
96 //否則就需要將父節點的內容賦值給當前節點
97 queue[k] = e;
98 //同時設定一下父節點的堆索引位為當前節點處
99 setIndex(e, k);
100 //然后將父節點賦值給當前節點,繼續下一次的上溯程序
101 k = parent;
102 }
103 /*
104 走到這里說明有兩種情況:<1>已經結束了上溯的程序,但最后一次的父節點還沒有賦值,這里就是進行賦值的操作;
105 <2>如果本方法進來的時候要添加的最后一個節點本身就滿足小頂堆條件的話,那么該處就是在給最后一個節點進行賦值
106 */
107 queue[k] = key;
108 //同時設定一下要插入節點的堆索引位
109 setIndex(key, k);
110 }
111
112 /**
113 * 第94行代碼處:
114 */
115 public int compareTo(Delayed other) {
116 //如果比較的就是當前物件,就直接回傳0相等
117 if (other == this)
118 return 0;
119 if (other instanceof ScheduledFutureTask) {
120 //如果需要比較的任務也是ScheduledFutureTask型別的話,就首先強轉一下型別
121 ScheduledFutureTask<?> x = (ScheduledFutureTask<?>) other;
122 //計算當前任務和需要比較的任務之間的延遲時間差
123 long diff = time - x.time;
124 if (diff < 0)
125 //小于0說明當前任務的延遲時間更短,就回傳-1
126 return -1;
127 else if (diff > 0)
128 //大于0說明需要比較的任務的延遲時間更短,就回傳1
129 return 1;
130 //如果兩者相等的話,就比較序列號,誰的序列號更小(序列號是唯一的),就應該先被執行
131 else if (sequenceNumber < x.sequenceNumber)
132 return -1;
133 else
134 return 1;
135 }
136 //如果需要比較的任務不是ScheduledFutureTask型別的話,就通過getDelay的方式來進行比較
137 long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
138 return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
139 }
7 拿取任務
在上面的ensurePrestart方法中會呼叫到addWorker方法,以此來補充作業執行緒,之前我對ThreadPoolExecutor原始碼進行分析的文章中說到過,addWorker方法會呼叫到getTask方法來從佇列中拿取任務:
1 /**
2 * ThreadPoolExecutor:
3 */
4 private Runnable getTask() {
5 //...
6 /*
7 這里的allowCoreThreadTimeOut默認為false(為true表示空閑的核心執行緒也是要超時銷毀的),
8 而上面說過定時執行緒池最多只有“核心執行緒數”個執行緒,所以timed為false
9 */
10 boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
11 //...
12 //因為timed為false,所以這里會走take方法中的邏輯
13 Runnable r = timed ?
14 workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
15 workQueue.take();
16 //...
17 }
18
19 /**
20 * ScheduledThreadPoolExecutor:
21 * 第15行代碼處:
22 * 上面的take方法會呼叫到DelayedWorkQueue的take方法,而該方法也就是用來實作延遲拿取任務的
23 */
24 public RunnableScheduledFuture<?> take() throws InterruptedException {
25 final ReentrantLock lock = this.lock;
26 //加鎖(回應中斷模式)
27 lock.lockInterruptibly();
28 try {
29 for (; ; ) {
30 //獲取隊頭節點
31 RunnableScheduledFuture<?> first = queue[0];
32 if (first == null)
33 /*
34 如果當前延遲佇列中沒有延遲任務,就在這里阻塞當前執行緒(通過AQS中條件佇列的方式),等待有任務時被喚醒
35 另外,當執行緒執行完任務后也會再次走到getTask方法中的本方法中,如果此時沒任務了,就會在此被阻塞休眠住
36 (我在之前AQS原始碼分析的文章中說過:await方法中會釋放掉所有的ReentrantLock鎖資源,然后才會被阻塞住)
37 */
38 available.await();
39 else {
40 //否則就獲取隊頭的剩余延遲時間
41 long delay = first.getDelay(NANOSECONDS);
42 //如果延遲時間已經到了的話,就洗掉并回傳隊頭,表示拿取到了任務
43 if (delay <= 0)
44 return finishPoll(first);
45 /*
46 這里將隊頭節點的參考置為null,如果不置為null的話,可能有多個等待著的執行緒同時持有著隊頭節點的
47 first參考,這樣如果要洗掉隊頭節點的話,因為其還有其他執行緒的參考,所以不能被及時回收,造成記憶體泄漏
48 */
49 first = null;
50 /*
51 如果leader不為null,說明有其他的執行緒已經成為了leader執行緒,正在延遲等待著
52 同時此時沒有新的延遲時間最短的節點進入到延遲佇列中
53 */
54 if (leader != null)
55 /*
56 那么當前執行緒就變成了follower執行緒,需要被阻塞住,等待被喚醒(同上,其中會釋放掉所有的鎖資源)
57 執行緒執行完任務后也會再次走到本方法中拿取任務,如果走到這里發現已經有別的leader執行緒了,
58 那么當前執行緒也會被阻塞休眠住;否則就會在下面的else分支中再次成為leader執行緒
59 */
60 available.await();
61 else {
62 /*
63 leader為null,可能是上一個leader執行緒拿取到任務后喚醒的下一個執行緒,也有可能
64 是一個新的延遲時間最短的節點進入到延遲佇列中,從而將leader置為null
65
66 此時獲取當前執行緒
67 */
68 Thread thisThread = Thread.currentThread();
69 //并將leader置為當前執行緒,也就是當前執行緒成為了leader執行緒
70 leader = thisThread;
71 try {
72 /*
73 這里也就是在做具體的延時等待delay納秒的操作了,具體涉及到AQS中條件佇列的相關操作
74 如果被喚醒的話可能是因為到達了延遲時間從而醒來;也有可能是被別的執行緒signal喚醒了;
75 還有可能是中斷被喚醒,正常情況下是等到達了延遲時間后,這里會醒來并進入到下一次回圈中的
76 finishPoll方法中,剔除隊頭節點并最侄訓傳(awaitNanos方法和await方法類似,其中會釋放掉
77 所有的鎖資源;不一樣的是在被喚醒時會把當前節點從條件佇列中“轉移”到CLH佇列中,這里可以認為
78 是轉移,因為在條件佇列中的該節點狀態已經改為了0,相當于是個垃圾節點,后續會進行洗掉)
79 */
80 available.awaitNanos(delay);
81 } finally {
82 /*
83 不管awaitNanos是如何被喚醒的,此時會判斷當前的leader執行緒是否還是當前執行緒
84 如果是的話就將leader置為null,也就是當前執行緒不再是leader執行緒了
85 */
86 if (leader == thisThread)
87 leader = null;
88 }
89 }
90 }
91 }
92 } finally {
93 //在退出本方法之前,判斷如果leader執行緒為null并且洗掉隊頭后的延遲佇列仍然不為空的話(說明此時有其他的延遲任務)
94 if (leader == null && queue[0] != null)
95 //就將條件佇列上的一個節點轉移到CLH佇列中(同時會剔除上面的垃圾條件節點)
96 available.signal();
97 /*
98 釋放鎖(同offer方法中的邏輯,這里只會喚醒CLH佇列中的head節點的下一個節點,這里就體現了
99 Leader-Follower模式:當leader執行緒拿取到任務后準備要執行時,會首先喚醒剩下執行緒中的一個,
100 它將會成為新的leader執行緒,并以此往復,保證在任何時間都只有一個leader執行緒,避免不必要的喚醒與睡眠)
101 */
102 lock.unlock();
103 }
104 }
105
106 /**
107 * 第44行代碼處:
108 */
109 private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
110 //size-1
111 int s = --size;
112 //獲取佇列中的最后一個節點
113 RunnableScheduledFuture<?> x = queue[s];
114 //并置空它,便于GC,這里也就是在洗掉最后一個節點
115 queue[s] = null;
116 //如果洗掉前延遲佇列中有不止一個節點的話,就進入到siftDown方法中,將小頂堆中的根節點洗掉,并且重新維護小頂堆
117 if (s != 0)
118 siftDown(0, x);
119 //同時設定一下洗掉前的根節點的堆索引位為-1,表示其不存在于小頂堆中了
120 setIndex(f, -1);
121 //最后將其回傳出去
122 return f;
123 }
124
125 /**
126 * 第118行代碼處:
127 * 方法引數中的key代表洗掉的最后一個節點中的任務
128 */
129 private void siftDown(int k, RunnableScheduledFuture<?> key) {
130 /*
131 這里會取陣列長度的一半half(注意這里的size是已經洗掉最后一個節點后的size),
132 而half也就是在指向最后一個非葉子節點的下一個節點
133 */
134 int half = size >>> 1;
135 //從這里可以看出下溯的終止條件是k大于等于half,也就是此時遍歷到已經沒有了非葉子節點,自然不需要進行調整
136 while (k < half) {
137 //獲取左孩子節點的索引位
138 int child = (k << 1) + 1;
139 //獲取左孩子節點的任務
140 RunnableScheduledFuture<?> c = queue[child];
141 //獲取右孩子節點的索引位
142 int right = child + 1;
143 //如果右孩子節點的索引位小于size,也就是在說當前節點含有右子樹,并且左孩子節點的任務延遲時間大于右孩子節點的話
144 if (right < size && c.compareTo(queue[right]) > 0)
145 //就將c重新指向為右孩子節點
146 c = queue[child = right];
147 /*
148 走到這里說明c指向的是左右子節點中、任務延遲時間較小的那個節點,此時判斷如果最后一個節點的
149 任務延遲時間小于等于這個較小節點的話,就可以停止下溯了,說明找到了插入的位置
150 */
151 if (key.compareTo(c) <= 0)
152 break;
153 //否則就把較小的那個節點賦值給當前節點處
154 queue[k] = c;
155 //同時設定一下延遲時間較小的那個節點的堆索引位為當前節點處
156 setIndex(c, k);
157 //然后將當前節點指向那個較小的節點,繼續下一次回圈
158 k = child;
159 }
160 /*
161 同siftUp方法一樣,走到這里說明有兩種情況:<1>已經結束了下溯的程序,但最后一次的子節點還沒有賦值,
162 這里會把其賦值為之前洗掉的最后一個節點;
163 <2>如果根節點的左右子節點中、任務延遲時間較小的那個節點本身的延遲時間就比之前洗掉節點大的話,
164 就會把根節點替換為之前洗掉的最后一個節點
165 所以本方法加上finishPoll方法,實際上并沒有將最后一個節點洗掉,最后一個節點中的任務一直都是保留著的
166 (也就是key),而是變相地將堆的根節點洗掉了(在第一種情況中根節點在第一次賦值為左右子節點中、
167 任務延遲時間較小的那個節點時,就已經被覆寫了)
168 */
169 queue[k] = key;
170 //同時設定一下最后一個節點現在新的堆索引位
171 setIndex(key, k);
172 }
8 執行延遲任務
拿取到任務之后,就是具體的執行任務了,addWorker方法具體的執行邏輯我在之前ThreadPoolExecutor的原始碼分析文章中已經講過了,其中執行任務的時候會呼叫task的run方法,也就是這里包裝為ScheduledFutureTask的run方法:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public void run() {
5 //判斷是否是周期性任務
6 boolean periodic = isPeriodic();
7 if (!canRunInCurrentRunState(periodic)) {
8 //如果此時不能繼續執行任務的話,就嘗試取消此任務的執行
9 cancel(false);
10 } else if (!periodic)
11 /*
12 如果是延遲任務,就呼叫ScheduledFutureTask父類FutureTask的run方法,
13 其中會通過call方法來最終呼叫到使用者具體寫的任務
14 */
15 ScheduledFutureTask.super.run();
16 else if (ScheduledFutureTask.super.runAndReset()) {
17 //周期性任務的執行放在下一節中進行分析
18 setNextRunTime();
19 reExecutePeriodic(outerTask);
20 }
21 }
9 scheduleAtFixedRate & scheduleWithFixedDelay方法
scheduleAtFixedRate方法是以上次的延遲時間點開始,延遲指定時間后再次執行當前任務;而scheduleWithFixedDelay方法是以上個周期任務執行完畢后的時間點開始,延遲指定時間后再次執行當前任務,因為這兩個方法的實作絕大部分都是一樣的,所以合在一起來進行分析:
1 /**
2 * ScheduledThreadPoolExecutor:
3 * scheduleAtFixedRate方法
4 */
5 public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
6 long initialDelay,
7 long period,
8 TimeUnit unit) {
9 //非空校驗
10 if (command == null || unit == null)
11 throw new NullPointerException();
12 //非負校驗
13 if (period <= 0)
14 throw new IllegalArgumentException();
15 //包裝任務
16 ScheduledFutureTask<Void> sft =
17 new ScheduledFutureTask<Void>(command,
18 null,
19 triggerTime(initialDelay, unit),
20 unit.toNanos(period));
21 RunnableScheduledFuture<Void> t = decorateTask(command, sft);
22 //把任務賦值給ScheduledFutureTask的outerTask屬性
23 sft.outerTask = t;
24 //延遲執行
25 delayedExecute(t);
26 return t;
27 }
28
29 /**
30 * scheduleWithFixedDelay方法
31 */
32 public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
33 long initialDelay,
34 long delay,
35 TimeUnit unit) {
36 //非空校驗
37 if (command == null || unit == null)
38 throw new NullPointerException();
39 //非負校驗
40 if (delay <= 0)
41 throw new IllegalArgumentException();
42 //包裝任務
43 ScheduledFutureTask<Void> sft =
44 new ScheduledFutureTask<Void>(command,
45 null,
46 triggerTime(initialDelay, unit),
47 unit.toNanos(-delay));
48 RunnableScheduledFuture<Void> t = decorateTask(command, sft);
49 //把任務賦值給ScheduledFutureTask的outerTask屬性
50 sft.outerTask = t;
51 //延遲執行
52 delayedExecute(t);
53 return t;
54 }
55
56 /**
57 * 第17行和第44行代碼處:
58 */
59 ScheduledFutureTask(Runnable r, V result, long ns, long period) {
60 super(r, result);
61 this.time = ns;
62 /*
63 可以看到這里與schedule方法中呼叫ScheduledFutureTask構造器的區別是多了一個period入參
64 在schedule方法中this.period賦值為0,而這里會賦值為周期時間,其他的代碼都是一樣的
65 如果細心的話可以看出:在上面scheduleAtFixedRate方法傳入的period是一個大于0的數,而
66 scheduleWithFixedDelay方法傳入的period是一個小于0的數,以此來進行區分
67 */
68 this.period = period;
69 this.sequenceNumber = sequencer.getAndIncrement();
70 }
10 執行周期性任務
周期性任務和延遲任務的拿取任務邏輯都是一樣的,而在下面具體運行任務時有所不同,下面就來看一下其實作的差異:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public void run() {
5 boolean periodic = isPeriodic();
6 if (!canRunInCurrentRunState(periodic))
7 cancel(false);
8 else if (!periodic)
9 ScheduledFutureTask.super.run();
10 /*
11 前面都是之前分析過的,而周期性任務會走下面的分支中
12
13 FutureTask的runAndReset方法相比于run方法來說,區別在于可以重復計算(run方法不能復用)
14 因為runAndReset方法在計算完成后不會修改狀態,狀態一直都是NEW
15 */
16 else if (ScheduledFutureTask.super.runAndReset()) {
17 //設定下次的運行時間點
18 setNextRunTime();
19 //重新添加任務
20 reExecutePeriodic(outerTask);
21 }
22 }
23
24 /**
25 * 第18行代碼處:
26 */
27 private void setNextRunTime() {
28 /*
29 這里會獲取period,也就是之前設定的周期時間,上面說過,通過period的正負就可以區分出到底呼叫的是
30 scheduleAtFixedRate方法還是scheduleWithFixedDelay方法
31 */
32 long p = period;
33 if (p > 0)
34 /*
35 如果呼叫的是scheduleAtFixedRate方法,下一次的周期任務時間點就是起始的延遲時間加上周期時間,需要注意的是:
36 如果任務執行的時間大于周期時間period的話,那么定時執行緒池就不會按照原先設計的延遲時間進行執行,而是會按照近似于
37 任務執行的時間來作為延遲的間隔(不管核心執行緒有多少個都是如此,因為任務是放在延遲佇列中的、是線性執行的)
38 */
39 time += p;
40 else
41 /*
42 triggerTime方法之前分析過是獲取當前時間+延遲時間后的結果,而此時是在執行完任務后,也就是說:
43 如果呼叫的是scheduleWithFixedDelay方法,下一次的周期任務時間點就是執行完上次任務后的時間點加上周期時間
44 由此可以看出,scheduleAtFixedRate方法和scheduleWithFixedDelay方法的區別就在于下一次time設定的不同而已
45 */
46 time = triggerTime(-p);
47 //time屬性會記錄到節點中,在小頂堆中通過compareTo方法來進行排序
48 }
49
50 /**
51 * 第20行代碼處:
52 */
53 void reExecutePeriodic(RunnableScheduledFuture<?> task) {
54 //判斷此時是否還能繼續執行任務
55 if (canRunInCurrentRunState(true)) {
56 /*
57 這里也就是重新往延遲佇列中添加任務,以此達到周期執行的效果,添加之后在getTask方法中的take方法中
58 就又可以拿到這個任務,設定下次的執行時間,然后再添加任務...周而復始
59 */
60 super.getQueue().add(task);
61 //添加后繼續判斷此時是否還能繼續執行任務,如果不能的話就洗掉上面添加的任務
62 if (!canRunInCurrentRunState(true) && remove(task))
63 //同時會取消此任務的執行
64 task.cancel(false);
65 else
66 //否則,說明執行緒池是可以繼續執行任務的,就去判斷此時是否需要補充作業執行緒
67 ensurePrestart();
68 }
69 }
注意:網上的一種說法是:scheduleAtFixedRate方法是以上一個任務開始的時間計時,period時間過去后,檢測上一個任務是否執行完畢,如果上一個任務執行完畢,則當前任務立即執行;如果上一個任務沒有執行完畢,則需要等上一個任務執行完畢后立即執行,實際上這種說法是錯誤的,盡管它的表象是對的,正確的說法是:如果任務的執行時間小于周期時間的話,則會以上次任務執行開始時間加上周期時間后,再去執行下一次任務;而如果任務的執行時間大于周期時間的話,則會等到上次任務執行完畢后立即(近似于)執行下次任務,這兩種說法的區別就在于任務的執行時間大于周期時間的時候,檢測上一個任務是否完畢的時機不同,實際上在period時間過去后,根本不會有任何的檢測機制,因為只有等上次任務執行完畢后才會往延遲佇列中添加下一次任務,從而觸發各種后續的動作,所以在period時間點時,當前執行緒還在執行任務中,而其他的執行緒因為延遲佇列中為慷訓處于休眠的狀態(假如就只有一個周期任務的話),所以根本不會有所謂的“檢測”的說法,這種說法也只能說是想當然了,還是那句話:“Talk is cheap. Show me the code.”
既然都說到這里了,那么現在就想來嘗試分析一下如果任務的執行時間大于周期時間的話,具體是怎樣的一個執行流程?
為了便于分析,假設現在是只有一個周期任務的場景,那么延遲佇列中的任務數量最多就只會有1個:拿取到任務,延遲佇列中就變為空,執行完任務的時候,就又會往佇列中放一個任務,這樣其他搶不到任務的執行緒就會被休眠住,而添加任務的時候因為每次重新添加的任務都是小頂堆的根節點(從無到有),即添加的這個任務就是此時延遲時間最短的任務,所以同時會觸發嘗試喚醒執行緒的動作,
同時在添加下一個任務前會修改下一次的時間點,在setNextRunTime方法中,scheduleAtFixedRate方法是以上一次的延遲時間點加上周期時間來作為下一次的延遲時間點的,并不是scheduleWithFixedDelay方法獲取當前時間加上周期時間的方式,在當前這種情況下周期時間是要小于任務的執行時間的,也就是說會造成下一次的延遲時間點會賦值為一個已經過期的時間,且隨著周期的增加,下一次的延遲時間點會離當前時間點越來越遠,既然下一次的延遲時間點已經過期了,那么就會去立馬執行任務,
所以總結一下:需要被喚醒的執行緒和上次執行完任務的執行緒就會去爭搶鎖資源(喚醒執行緒會把當前節點放進CLH佇列中,上次執行完任務的執行緒也會再次走到lockInterruptibly方法中(在它重新放任務的時候也會經歷一次lock),同時因為是ReentrantLock非公平鎖,這樣在呼叫unlock解鎖時就會出現在CLH佇列上的搶資源現象了),搶到的就會立馬去執行下一次的周期任務,而不會有任何的延時,造成的表象就是會以一個近似于任務執行時間為間隔的周期來執行任務,
11 shutdown方法
1 /**
2 * ScheduledThreadPoolExecutor:
3 * 可以看到,定時執行緒池的shutdown方法是使用的父類ThreadPoolExecutor的shutdown方法,
4 * 而該方法我在之前的ThreadPoolExecutor的原始碼分析文章中已經分析過了,但是其中會呼叫
5 * onShutdown的鉤子方法,也就是在ScheduledThreadPoolExecutor中的實作
6 */
7 public void shutdown() {
8 super.shutdown();
9 }
10
11 @Override
12 void onShutdown() {
13 //獲取延遲佇列
14 BlockingQueue<Runnable> q = super.getQueue();
15 //關閉執行緒池時判斷是否需要繼續執行延遲任務
16 boolean keepDelayed =
17 getExecuteExistingDelayedTasksAfterShutdownPolicy();
18 //關閉執行緒池時判斷是否需要繼續執行周期性任務
19 boolean keepPeriodic =
20 getContinueExistingPeriodicTasksAfterShutdownPolicy();
21 if (!keepDelayed && !keepPeriodic) {
22 //如果都不需要的話,就將延遲佇列中的任務逐個取消(并洗掉)
23 for (Object e : q.toArray())
24 if (e instanceof RunnableScheduledFuture<?>)
25 ((RunnableScheduledFuture<?>) e).cancel(false);
26 //最后做清理作業
27 q.clear();
28 } else {
29 for (Object e : q.toArray()) {
30 if (e instanceof RunnableScheduledFuture) {
31 //否則就判斷如果任務是RunnableScheduledFuture型別的,就強轉一下型別
32 RunnableScheduledFuture<?> t =
33 (RunnableScheduledFuture<?>) e;
34 //如果關閉執行緒池時不需要繼續執行任務,又或者需要繼續執行但是任務已經取消了
35 if ((t.isPeriodic() ? !keepPeriodic : !keepDelayed) ||
36 t.isCancelled()) {
37 //就洗掉當前節點
38 if (q.remove(t))
39 //同時取消任務
40 t.cancel(false);
41 }
42 }
43 }
44 }
45 //根據執行緒池狀態來判斷是否應該結束執行緒池
46 tryTerminate();
47 }
48
49 /**
50 * 第27行代碼處:
51 */
52 public void clear() {
53 final ReentrantLock lock = this.lock;
54 //加鎖
55 lock.lock();
56 try {
57 for (int i = 0; i < size; i++) {
58 //遍歷獲得延遲佇列中的每一個節點
59 RunnableScheduledFuture<?> t = queue[i];
60 if (t != null) {
61 //將節點置為null
62 queue[i] = null;
63 //同時將索引位置為-1(recheck)
64 setIndex(t, -1);
65 }
66 }
67 //size賦為初始值0
68 size = 0;
69 } finally {
70 //釋放鎖
71 lock.unlock();
72 }
73 }
更多內容請關注微信公眾號:奇客時間
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/229668.html
標籤:Java
上一篇:認證授權基礎