本文摘自深入理解 Java 虛擬機第三版
垃圾收集發生的區域
之前我們介紹過 Java 記憶體運行時區域的各個部分,其中程式計數器、虛擬機堆疊、本地方法堆疊三個區域隨執行緒共存亡,堆疊中的每一個堆疊幀分配多少記憶體基本上在類結構確定下來時就已知,因此這幾個區域的記憶體分配和回收都具有確定性,不需要考慮如何回收的問題,當方法結束或執行緒結束,記憶體自然也跟著回收了
而 Java 堆和方法區這兩個區域則有顯著的不確定性,只有在程式運行時我們才能知道程式究竟創建了哪些物件,創建了多少物件,所以這部分記憶體的分配和回收是動態的,垃圾收集器所關注的正是這部分記憶體該如何管理
如何判定需要被回收的物件?
如果一個物件沒有被其他物件參考,則證明這個物件可以被回收,因為它已經沒有實際用途了,那我們怎么去判斷一個物件是否可回收呢?業界主要有兩種判斷方式:
1. 參考計數法
在物件中添加一個參考計數器,每當有一個地方參考它時,計數器值加一;當參考失效,計數器值減一;任何時刻計數器值都為零的物件就是不可能再被使用了,這種方法雖然會占用額外的記憶體空間用于計數,但它的原理簡單,判定效率也高,大多數情況下它都是一個不錯的演算法,然而,這個看似簡單的演算法卻需要考慮很多額外情況,否則將無法保證其正確作業,例如單純的參考計數法就很難解決物件之間相互回圈參考的問題
2. 可達性分析演算法
該演算法的基本思路是通過一系列稱為 GC Roots 的根物件作為起始節點集,從這些節點開始,根據參考關系向下搜索,搜索程序走過的路徑稱為參考鏈,如果某個物件到 GC Roots 間沒有任何參考鏈相連,則證明此物件是不可能再被使用,可以回收
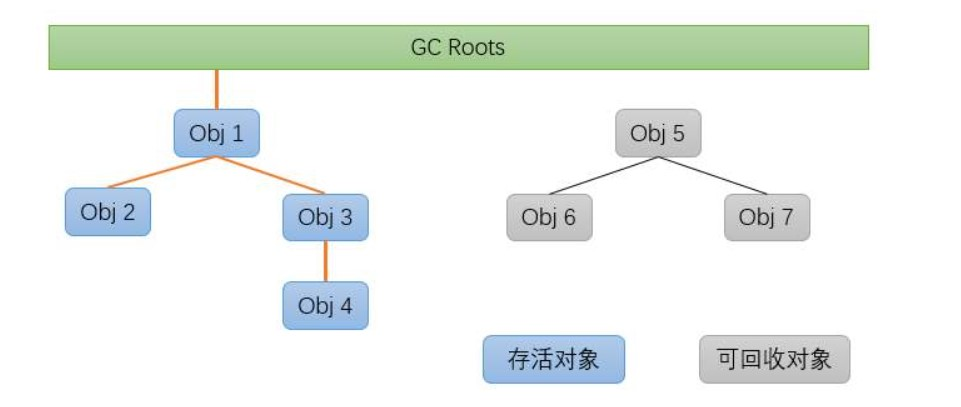
在 Java 技術體系中,可以作為 GC Roots 的物件包括:
- 在虛擬機堆疊(堆疊幀中的本地變數表)中參考的物件
- 方法區中類靜態屬性參考的物件
- 方法區中常量參考的物件
- 本地方法堆疊中 JNI(即通常所說的 Native 方法)參考的物件
- Java 虛擬機內部的參考,如基本資料型別對應的 Class 物件,一些常駐的例外物件(NullPointException、OutOfMemoryError)
- 所有被同步鎖持有的物件
- 反映 Java 虛擬機內部情況的 JMXBean、JVMTI 中注冊的回呼、本地代碼快取等
除了這些固定的 GC Roots 集合外,根據用戶所選用的垃圾收集器以及當前回收的記憶體區域的不同,還可以有其他物件臨時加入,共同構成完整的 GC Roots 集合
四種參考型別
無論是通過參考計數法還是可達性分析演算法,判斷物件是否存活都和參考離不開關系,在 JDK1.2 以前,Java 里的參考是很傳統的定義:如果 reference 型別的資料中存盤的數值代表的是另外一塊記憶體的起始地址,就稱該 reference 資料是代表某塊記憶體、某個物件的參考,這種定義當然沒有什么不對,但現在看來顯得太狹隘了,比如我們希望描述一類物件:當記憶體空間足夠時,能保留在記憶體中,如果記憶體空間在進行了垃圾收集后仍然緊張,則可以拋棄這些物件,很多系統的快取功能都符合這樣的應用場景
JDK1.2 對參考的概念作了補充,將參考分為強參考(Strongly Reference)、軟參考(SoftReference)、弱參考(Weak Reference)和虛參考(Phantom Reference),強度依次減弱
-
強參考
形如 Object obj = new Object() 這種參考關系就是我們常說的強參考,無論什么情況,只要強參考關系存在,物件就永遠不會被回收
-
軟參考
用來描述一些有用但非必須的物件,此類物件只有在進行一次垃圾收集仍然沒有足夠記憶體時,才會在第二次垃圾收集時被回收,JDK1.2 之后提供了 SoftReference 類來實作軟參考
-
弱參考
也是用來描述那些非必須物件,但它的強度比軟參考更弱一些,被軟參考關聯的物件只能生存到下一次垃圾收集發生為止,當垃圾收集器開始作業,無論當前記憶體是否足夠,都會回收掉只被弱參考關聯的物件,JDK1.2 之后提供了 WeakReference 類來實作軟參考
-
虛參考
最弱的一種參考關系,一個物件是否存在虛參考,絲毫不會對其生存時間造成任何影響,也無法通過虛參考來取得一個物件實體,設定虛參考關聯的唯一目的就是讓這個物件被回收時能收到一個系統通知,JDK1.2 之后提供了 PhantomReference 類來實作軟參考
finalize() 方法
在可達性分析中被判定為不可達的物件,并不是立即赴死,至少要經歷兩次標記程序:如果物件在進行可達性分析后發現沒有與 GC Root 相連接的參考鏈,那么它將被第一次標記,隨后再進行一次篩選,篩選條件是物件是否有必要執行 finalize() 方法,如果物件沒有覆寫 finalize() 方法或是 finalize() 方法已經被呼叫過,則都視為“沒有必要執行”
如果物件被判定為有必要執行 finalize() 方法,那么該物件將會被放置在一個名為 F-Queue 的佇列之中,并在稍后由一條由虛擬機自動創建的、低調度優先級的 Finalizer 執行緒去執行它們的 finalize() 方法,注意這里所說的執行是指虛擬機會觸發這個方法開始運行,但并不承諾一定會等待它運行結束,這樣做的原因是防止某個物件的 finalize() 方法執行緩慢,或者發生死回圈,導致 F-Queue 佇列中的其他物件永久處于等待狀態
finalize() 方法是物件逃脫死亡命運的最后一次機會,稍后收集器將對 F-Queue 中的物件進行第二次小規模標記,如果物件希望在 finalize() 方法中成功拯救自己,只要重新與參考鏈上的任何一個物件建立關聯即可,那么在第二次標記時它將被移出“即將回收”的集合;如果物件這時候還沒有逃脫,那基本上就真的要被回收了
任何一個物件的 finalize() 方法都只會被系統自動呼叫一次,如果物件面臨下一次回收,它的 finalize() 方法將不會再執行,finalize() 方法運行代價高,不確定性大,無法保證各個物件的呼叫順序,因此已被官方明確宣告為不推薦使用的語法
回收方法區
方法區的垃圾收集主要回收兩部分:廢棄的常量和不再使用的型別,判定一個常量是否廢棄相對簡單,與物件類似,只要某個常量不再被參考,就會被清理,而判定一個型別是否屬于“不再被使用的類”的條件就比較苛刻了,需要同時滿足下面三個條件:
- 該類的所有實體都已經被回收,即 Java 堆中不存在該類及其任何派生子類的實體
- 加載該類的類加載器已經被回收
- 該類對應的 java.lang.Class 物件沒有在任何地方被參考,無法再任何地方通過反射訪問該類的方法
Java 虛擬機允許對滿足上述三個條件的無用類進行回收,但并不是說必然被回收,僅僅是允許而已,關于是否要對型別進行回收,HotSpot 虛擬機提供了 -Xnoclassgc 引數進行控制
分代收集理論
當前商業虛擬機的垃圾收集器大多數都遵循了“分代收集”的設計理論,分代收集理論其實是一套符合大多數程式運行實際情況的經驗法則,主要建立在兩個分代假說之上:
- 弱分代假說:絕大多數物件都是朝生夕滅的
- 強分代假說:熬過越多次垃圾收集程序的物件就越難以消亡
這兩個分代假說共同奠定了多款常用垃圾收集器的一致設計原則:收集器應該將 Java 堆劃分出不同的區域,將回收物件依據年齡(即物件熬過垃圾收集程序的次數)分配到不同的區域之中存盤,把存活時間短的物件集中在一起,每次回收只關注如何保留少量存活的物件,即新生代(Young Generation);把難以消亡的物件集中在一起,虛擬機就可以使用較低的頻率來回收這個區域,即老年代(Old Generation)
正因為劃出了不同的區域,垃圾收集器才可以每次只回收其中一個或多個區域,因此才有了“Minor GC”、“Major GC”、“Full GC”這樣的回收型別劃分,也才能夠針對不同的區域采用不同的垃圾收集演算法,因而有了“標記-復制”演算法、“標記-清除”演算法、“標記-整理”演算法
分代收集并非只是簡單劃分一下記憶體區域,它至少存在一個明顯的困難:物件之間不是孤立的,物件之間會存在跨代參考,假如現在要進行只局限于新生代的垃圾收集,根據前面可達性分析的知識,與 GC Roots 之間不存在參考鏈即為可回收,但新生代的物件很有可能會被老年代所參考,那么老年代物件將臨時加入 GC Roots 集合中,我們不得不再額外遍歷整個老年代中的所有物件來確保可達性分析結果的正確性,這無疑為記憶體回收帶來很大的性能負擔,為了解決這個問題,就需要對分代收集理論添加第三條經驗法則:
- 跨代參考假說:跨代參考相對于同代參考僅占少數
存在互相參考的兩個物件,應該是傾向于同時生存或同時消亡的,舉個例子,如果某個新生代物件存在跨代參考,由于老年代物件難以消亡,會使得新生代物件同樣在收集時得以存活,進而年齡增長后晉升到老年代,那么跨代參考也隨之消除了,既然跨帶參考只是少數,那么就沒必要去掃描整個老年代,也不必專門記錄每一個物件是否存在哪些跨代參考,只需在新生代上建立一個全域的資料結構,稱為記憶集(Remembered Set),這個結構把老年代劃分為若干個小塊,標識出老年代的哪一塊記憶體會存在跨代參考,此后當發生 Minor GC 時,只有包含了跨代參考的小塊記憶體里的物件才會被加入 GC Roots 進行掃描
標記 - 清除演算法
如其名,演算法分為標記和清除兩個階段:首先標記出所有需要回收的物件,在標記完成之后,統一回收所有被標記的物件,也可以反過來,標記存活的物件,統一回收所有未被標記的物件,標記程序就是物件是否屬于垃圾的判定程序,標記 - 清除演算法執行程序如圖所示:
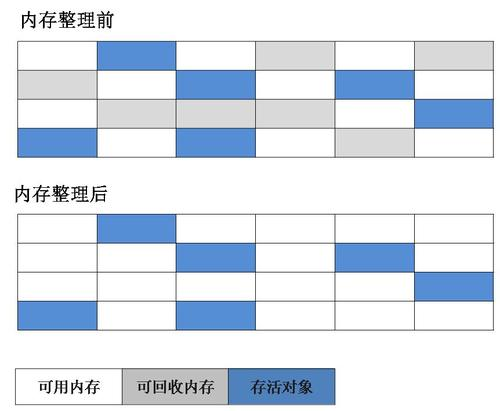
標記 - 清除演算法是最基礎的演算法,后續的收集演算法都是以標記 - 清除演算法為基礎,對其缺點進行改進,它的主要缺點有兩個:
-
執行效率不穩定
如果 Java 堆中包含大量物件且大部分需要回收,則必須進行大量標記和清除的動作‘
-
記憶體空間碎片化問題
標記、清除之后會產生大量不連續的記憶體碎片,記憶體碎片太多會導致下次分配較大物件時無法找到足夠的連續記憶體,從而不得不提前觸發一次垃圾收集動作
標記 - 復制演算法
為了解決標記 - 清除演算法面對大量可回收物件時執行效率低的問題,復制演算法將可用記憶體按容量劃分為大小相等的兩塊,每次只使用其中一塊,當這一塊記憶體用完了,就將還存活著的物件復制到另外一記憶體上,再把已使用過的記憶體空間一次清理掉
如果記憶體中多數物件都是存活的,這種演算法無疑會產生大量記憶體間復制的開銷,但對于多數物件都是可回收的情況,演算法需要復制的就是占少數的存活物件,而且每次都是針對整個半區進行記憶體回收,分配記憶體時也不用考慮空間碎片的問題,只要移動堆頂指標,按順序分配即可,不過這種演算法的缺陷也顯而易見,可用記憶體被縮小為原來的一半
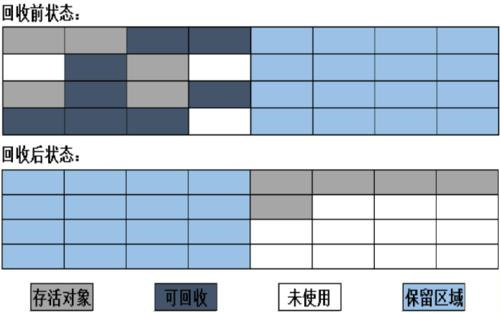
標記 - 復制演算法大多用于新生代,實際上,新生代中的物件大多數都熬不過第一輪收集,因此不需要按 1:1 的比例來劃分新生代的記憶體空間,具體做法是將新生代劃分為一塊較大的 Eden 區和兩塊較小的 Survivor 區,每次分配只使用 Eden 區和其中一塊 Survivor 區,發生垃圾收集時,將 Eden 區和 Survivor 區中仍然存活的物件一次性復制到另一個 Survivor 區,然后直接清理掉 Eden 區和已經用過的 Survivor 區,HotSpot 虛擬機默認 Eden 和 Survivor 的大小比例是 8:1:1
當 Survivor 空間不足以容納一次 Minor GC 之后存活的物件時,就需要依賴其他記憶體區域(大多是老年代)進行分配擔保,上一次新生代存活下來的物件直接進入老年代
標記 - 整理演算法
標記 - 復制演算法不適合用在物件存活率高的區域,而且會浪費一半的空間,因此老年代一般不采用這種演算法,取而代之的是有針對性的標記 - 整理演算法,標記 - 整理演算法的標記程序與標記 - 清除演算法一樣,但后續步驟不是直接清理可回收物件,而是讓所有存活物件都向記憶體空間的一側移動,然后直接清理掉邊界以外的記憶體
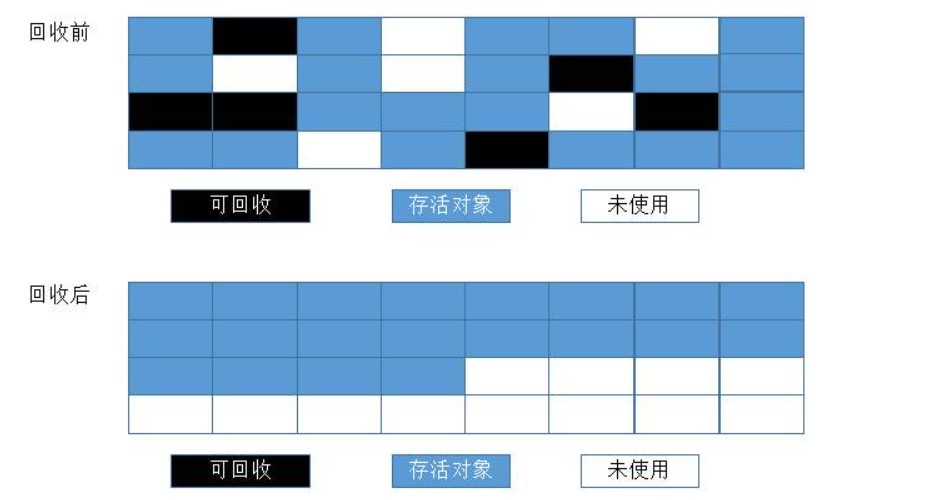
是否移動回收后的存活物件是一項優缺點并存的風險決策,尤其是在老年代這種每次回收都有大量物件存活的區域,移動存活物件并更新其參考將會是一個極為繁重的操作,必須暫停用戶應用程式執行緒才能進行,像這樣的停頓行為被稱為“Stop the World”,但如果不考慮移動存活物件,又會影響記憶體分配和訪問的效率,為此使用者必須小心權衡其中的得失,一種和稀泥式的解決方案就是讓虛擬機平時采用標記 - 清除演算法,直到記憶體空間碎片化程度大到影響物件分配時,再采用標記 - 整理演算法收集一次,已獲得規整的記憶體空間
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/229670.html
標籤:Java