1.梯度下降
梯度下降屬于迭代法的一種,所謂迭代法就是不斷用變數的舊值得到新值的方法,在求解損失函式最小值的時候,可以通過梯度下降法來一步步迭代求出最小化的損失函式和模型引數值,
梯度:
對于一元函式來說,梯度就是該函式的導數,即▽f(x)=f'(x)
對于多元函式來說,梯度就是對多元函式的引數求偏導數,把求得的各個引數的偏導數以向量的形式寫出來,比如函式f(x,y),分別對x,y求偏導數,得到的的梯度就是(?f/?x, ?f/?y)T,簡稱grad f(x,y)或者▽f(x,y),
在求極小值的時候,要向負梯度方向求最小值,以下圖為例:
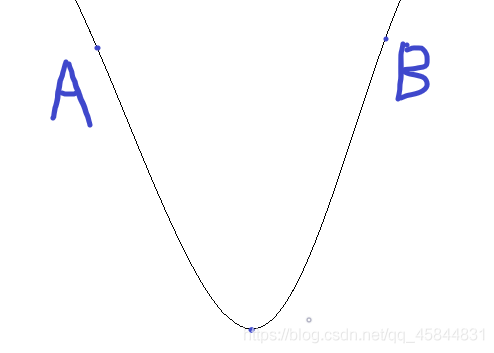 默認向上為y軸正方向,向右為x軸正方向
默認向上為y軸正方向,向右為x軸正方向
在A點求最小值時要向梯度反方向,在B點求最小值時也是如此,梯度是在該點的導數,
求解程序:
1.設出兩個較小的正數s,b s代表步長,b代表非常小的常數閾值;
2.求當前位置的偏導數:
▽f(x)=f'(x);▽f(x,y)=(?f/?x, ?f/?y)T (x=0....n)
3.修改函式的引數值:
X1=x-s*▽
引數值為函式的梯度與步長的乘積的絕對值,
4.如果修改后的引數值小于b,則此時的引數值就是求得最小值;否則回到步驟2,此時x=x-X0,
一般情況下,梯度向量為0的時候就是一個極值點,此時梯度的幅值也為0,梯度下降演算法迭代結束的條件是幅值接近0,故剛開始可以設定一個較小的閾值,
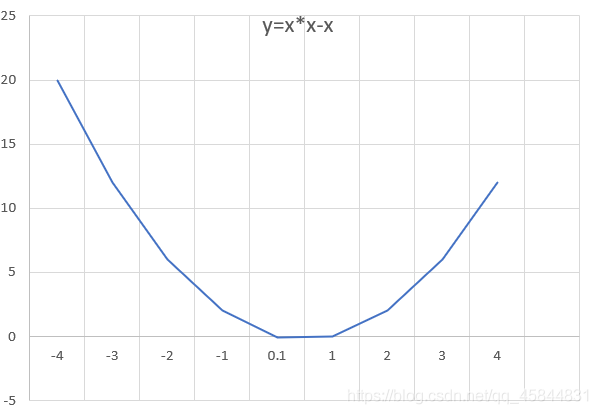
例:出發點設為-4利用梯度下降法求函式y=x*x-x的極小值
def f(x):
return 2*x-1
x=-4
s=0.9
b=0.01
while True:
x1=f(x)*s
if x1<0:
x1=-x1
x=x+x1
else:
x=x-x1
if x1<b:
break
print(x)
print("函式最小值",x*x-x)運行結果:
4.1
-2.38
2.8040000000000003
-1.3432000000000004
1.9745600000000003
-0.6796480000000003
1.4437184000000003
-0.2549747200000003
1.1039797760000003
0.01681617919999967
0.8865470566400003
0.19076235468799974
0.7473901162496003
0.3020879070003198
0.6583296743997442
0.37333626048020463
0.6013309916158363
0.418935206707331
0.5648518346341352
0.44811853229269183
0.5415051741658465
0.46679586066732276
0.5265633114661418
0.4787493508270866
0.5170005193383307
0.48639958452933546
0.5108803323765316
0.4912957340987747
0.5069634127209802
0.49442926982321583
0.5044565841414274
函式最小值 -0.24998728886898583
2.矩陣分解:
矩陣分解就是把一個矩陣近似變成若干個小矩陣相乘的形式,個人感覺矩陣分解就是預測一些矩陣中沒有的元素,
應用矩陣分解思想解決評分矩陣中沒有打分的元素,這種思想可以看做是有監督的機器學習,
矩陣R可以近似表示為P與Q的乘積:R(m,n)≈ P(m,K)*Q(K,n),為什么要說是近似表示呢,因為矩陣R中并不是所有的元素都有值,而分解后的矩陣P和Q是都有元素值的,K值是通過交叉驗證法獲得的最佳的值,
![]() ,為了得到近似的R(m,n),必須求出矩陣P和Q,如何求出這兩個矩陣是關鍵問題,
,為了得到近似的R(m,n),必須求出矩陣P和Q,如何求出這兩個矩陣是關鍵問題,
隨機生成矩陣P和Q
然后使用原始的評分矩陣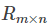 與重新構建的評分矩陣
與重新構建的評分矩陣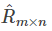 之間的誤差的平方作為損失函式,即:
之間的誤差的平方作為損失函式,即:
如果R(i,j)已知,則R(i,j)的誤差平方和為: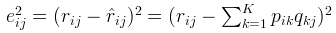
最終,需要求解所有的非“-”項的損失之和的最小值: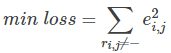
之后使用梯度下降法獲得修正的p和q分量:
- 求解損失函式的負梯度:
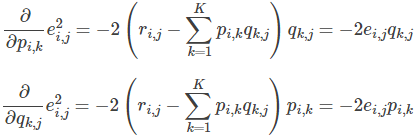
- 根據負梯度的方向更新變數:
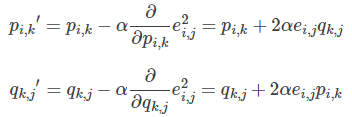
最后不停迭代直到演算法最終收斂(直到sum(e^2) <=閾值)
import matplotlib.pyplot as plt
from math import pow
import numpy
def matrix_factorization(R,P,Q,K,steps=5000,alpha=0.0002,beta=0.02):
Q=Q.T # .T操作表示矩陣的轉置
result=[]
for step in range(steps):
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j]>0:
eij=R[i][j]-numpy.dot(P[i,:],Q[:,j]) # .dot(P,Q) 表示矩陣內積
for k in range(K):
P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k])
Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j])
eR=numpy.dot(P,Q)
e=0
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j]>0:
e=e+pow(R[i][j]-numpy.dot(P[i,:],Q[:,j]),2)
for k in range(K):
e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2))
result.append(e)
if e<0.001:
break
return P,Q.T,result
if __name__ == '__main__':
R=[
[5,3,0,2],
[4,0,0,1],
[1,1,0,5],
[1,0,1,4],
[0,1,5,4]
]
R=numpy.array(R)
N=len(R)
M=len(R[0])
K=2
P=numpy.random.rand(N,K) #隨機生成一個 N行 K列的矩陣
Q=numpy.random.rand(M,K) #隨機生成一個 M行 K列的矩陣
nP,nQ,result=matrix_factorization(R,P,Q,K)
print("原始的評分矩陣R為:\n",R)
R_MF=numpy.dot(nP,nQ.T)
print("經過MF演算法填充0處評分值后的評分矩陣R_MF為:\n",R_MF)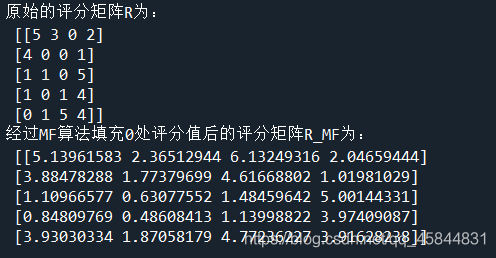
矩陣分解的方法和代碼參考:https://www.cnblogs.com/shenxiaolin/p/8637794.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236082.html
標籤:python