Python爬取B站彈幕資料并獲取彈幕數量最多資料
- 網站分析
- 最終代碼
我們以鄭老師申論課為例子進行分析
網站分析
鄭老師的申論課的網址為
https://www.bilibili.com/video/BV1W7411t7fy
我們爬取106節課程并存盤彈幕到txt檔案
經過分析知道這106節課網址不同點在于params的p引數,我們只需要使用回圈修改p引數即可爬取106節課

B站的彈幕資料在https://api.bilibili.com/x/v1/dm/list.so這個URL中,現在已經在B站抓包已經抓不到了,所以直接寫出來,這個URL要傳入oid引數才可獲取到資料,所以必須在原網址中獲取到oid引數,然后傳入這個URL,方可獲取到彈幕

在控制臺這里搜索oid以找到oid是什么,然后把oid傳入原網址搜索其位置
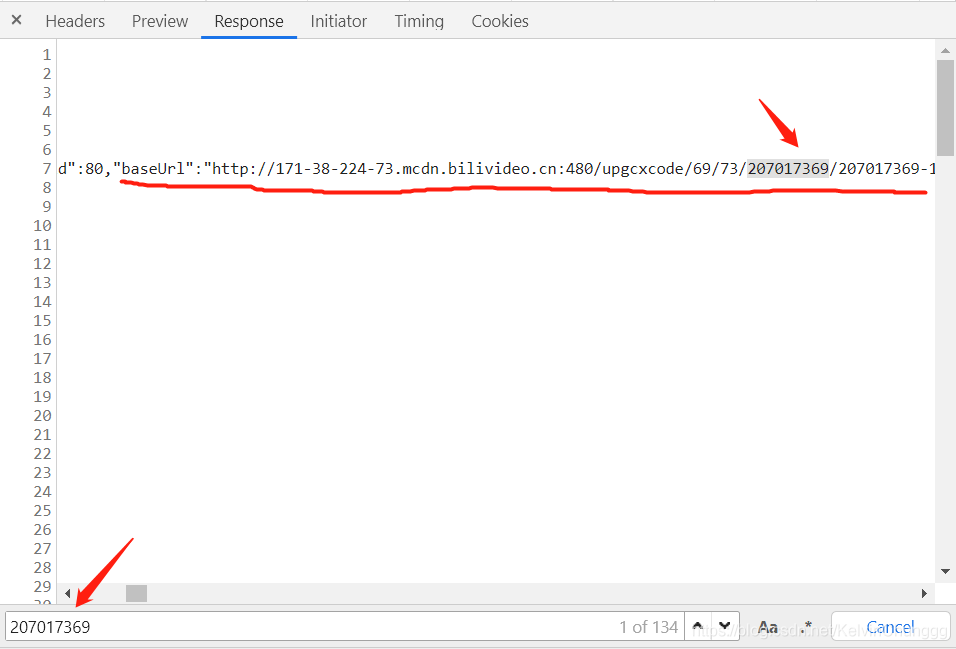
即可在代碼用正則定位到此處進行獲取
獲取到資料后即可存盤到txt檔案以及通過排序進行分析
re.findall(r'"base_url":".*?upgcxcode/\d+/\d+/(.*?)/.*?m4s.*?"',page_text,re.S)[0]
具體說明代碼有備注
注:此代碼也可用于其他的整套系列視頻,如果想要獲取單一視頻彈幕資料,則直接分析其oid并請求
https://api.bilibili.com/x/v1/dm/list.so這個url即可(攜帶oid引數)
最終代碼
import requests
import re
import os
import time
###彈幕存盤路徑
dirName="申論彈幕"
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'https://www.bilibili.com/video/BV1W7411t7fy'
##此變數用于改變檔案名
count = 0
###爬取106節課的彈幕資料
for each in range(1,106):
params = {
'p': str(each)
}
###爬取原網址以獲得oid
response = requests.get(url=url,headers=headers,params=params)
response.encoding = 'utf-8'
page_text = response.text
##獲取oid
oid = re.findall(r'"base_url":".*?upgcxcode/\d+/\d+/(.*?)/.*?m4s.*?"',page_text,re.S)[0]
##獲取這節課的名稱
name = re.findall(r'"part":.*?"(.*?)",',page_text,re.S)[count]
###爬取彈幕資料
content_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid='+str(oid)
content = requests.get(url=content_url,headers= headers)
content.encoding = 'utf-8'
content_text = content.text
###彈幕資料清理
real_content = re.findall(r'<.*?d.*?p.*?=.*?".*?".*?>(.*?)</d>',content_text,re.S)
###存盤彈幕資料
content_path = dirName + '/' + name + '.txt'
with open(content_path,'w',encoding = 'utf-8') as fp:
for cont in real_content:
fp.write(cont)
###使資料更美觀
fp.write('\n')
#####分析每一節課彈幕最多的資料
###把資料存盤為字典格式
content_dict = {}
for every in real_content:
if every not in content_dict:
content_dict[every] = 1
else:
content_dict[every] += 1
###獲取彈幕數最多的資料
max = list(content_dict.items())[0][1]
for i in list(content_dict.items()):
if i[1] >= max:
max = i[1]
content_max = i[0]
print(name+'這節課'+'彈幕最多的是:'+content_max+','+'一共有'+str(max)+'條')
###防止爬取速度過快
time.sleep(0.5)
count += 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236083.html
標籤:python
上一篇:梯度下降與矩陣分解