Python實作輸入電影名字自動生成豆瓣評論詞云圖(帶GUI界面)小程式
一、專案背景
電影逐漸成為人們生活的不可或缺的一部分,而了解一部電影的可以通過電影評分與大眾推薦度,但以上的方式都太過于片面,了解一部電影的方法是通過已經觀看完電影的人群的反饋,雖然電影評分和大眾推薦度在一定程度上是觀影人群的反饋,但是并沒有電影評論的反饋真實,評論對影視劇的好壞與特色可以更加充分的體現,所以了解一部影視作品的最好方式是通過評論,出于對評論的大量且參差不齊的考慮,通過出現的高頻詞來分析,是通過評論了解影視劇較為便捷的方式,將高頻詞整合,通過詞云圖是極好的方式,所以專案基于以上背景決定基于網路爬蟲獲取豆瓣評論生成詞云圖實作指定電影豆瓣評論關鍵詞詞云生成器,
二、專案的詳細設計
- 生成器的主要結構為,爬蟲模塊、詞云生成模塊、GUI界面模塊,
- 主要流程為在GUI輸入電影名稱后,將引數傳給爬蟲模塊,具體通過get方式將電影名稱封裝成url發送至豆瓣服務器進入搜索界面獲取指定電影URL中指定的id,將獲取的id再次封裝成url發送至豆瓣服務器進入評論網頁,通過爬蟲爬取評論資料存至本地生成文本格式,生成本地文本后,程式將呼叫詞云模塊對生成的文本提取,并進行符號洗掉并且刪去停用詞,并定位背景圖以及設定圖片詞語引數生成詞云圖回傳,
- 考慮到人工收集影評較為復雜且作業量繁重,故通過網路爬蟲實作對指定豆瓣評論的爬取,爬取物件為豆瓣影評取,且需要考慮輸入電影名字爬取指定的功能,所以選用的庫函式有:requests、urllib.request、Beautifulsoup、用于爬取評論資料及獲取,將電影名稱封裝url發送后,進入搜索界面,使用Xpath定位HTML代碼中的搜索結果的第一項中的sid,
- 將獲取到的的id構造url發送給豆瓣服務器,訪問評論網頁,進入網站后,呼叫定義函式getComment()對評論進行爬取,并保存至本地文本中,
后續通過詞云處理后生成詞云圖展示,
爬蟲模塊
- 以上為爬蟲作業所有需要呼叫的包
import urllib.request
import requests, re
from bs4 import BeautifulSoup
- 獲取HTML原始碼
def getHtml(url):
"""獲取url頁面"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
content = req.read().decode('utf-8')
return content
- 這部分代碼用于將獲取后的HTML原始碼處理并提取出指定內容,
def getComment(url):
"""決議HTML頁面"""
html = getHtml(url)
soupComment = BeautifulSoup(html, 'html.parser')
comments = soupComment.findAll('span', 'short')
onePageComments = []
for comment in comments:
# print(comment.getText()+'\n')
onePageComments.append(comment.getText()+'\n')
return onePageComments
- 在搜索頁面內定位第一個展示的電影對應的sid(即為豆瓣網里每一部電影唯一的id)
def getid(name):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
}
movie_name = name
params = {
"q": movie_name
}
search_url = "https://www.douban.com/search"
r = requests.get(search_url, params=params, headers=headers)
soup = BeautifulSoup(r.content, 'lxml')
first_movie_info = soup.find('a', {'class': 'nbg'})['onclick']
pattern = re.compile('\d{4,}')
sid = str(pattern.search(first_movie_info).group())
return(sid)
- 將上一個函式回傳的結果進行評論提取并存入txt文本
def get_data():
with open('電影評論.txt', 'w', encoding='utf-8') as f:
sid=getid(_input.get())
for page in range(10): # 豆瓣爬取多頁評論需要驗證,
url = 'https://movie.douban.com/subject/'+sid+'/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P'
for i in getComment(url):
f.write(i)
GUI模塊
- GUI模塊呼叫的庫
from tkinter import *
import matplotlib.pyplot as plt
app = Tk()#主視窗
_input = Entry()#輸入框
_input.pack()
app.title("電影評論關鍵詞生成器")
screenwidth = app.winfo_screenwidth()#定義視窗寬度
screenheight = app.winfo_screenheight()#定義視窗高度
dialog_width = 400
dialog_height = 170
# 前兩個引數是視窗的大小,后面兩個引數是視窗的位置
app.geometry(
"%dx%d+%d+%d" % (dialog_width, dialog_height, (screenwidth - dialog_width) / 2, (screenheight - dialog_height) / 2))#設定視窗局中分布
btn = Button(text='查詢', command=get_data,width=10)#定義按鈕,按鈕的結果是呼叫get data函式進入爬蟲模塊
btn.place(x=155, y=80)#定義按鈕位置
btn.pack()
app.mainloop()
詞云模塊
- 詞云模塊呼叫的庫
from wordcloud import WordCloud
import pandas as pd
from imageio import imread
import jieba
with open("電影評論.txt", "r", encoding='UTF-8') as fin1:
all_words = cut_words(fin1)#讀取文本
#定義停用詞
stop = ['的','你','了','將','為','例',' ','多','再','有','是','等','天','次','讓','在','我','也','就','這樣','啊','和','都','《','》',',','看','!','什么','怎么','這么','很','給','沒有','不是','說'
,'不','嗎','?','!' ,'?',',' ,'...' ,'電影','主','男','女' ]
words_cut = []#定義停用詞
for word in all_words:
if word not in stop:
words_cut.append(word)
word_count = pd.Series(words_cut).value_counts()
back_ground = imread("F:\\flower.jpg")#自己定義圖片位置
wc = WordCloud(
font_path="C:\\Windows\\Fonts\\simhei.ttf", #設定字體
background_color="white", #設定詞云背景顏色
max_words=400, #詞云允許最大詞匯數
mask=back_ground, #詞云形狀
max_font_size=400, #最大字體大小
random_state=90 #配色方案的種數
)
wc1 = wc.fit_words(word_count) #生成詞云
plt.figure()
plt.imshow(wc1)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
三、專案的分析與測驗
界面如下:
輸入電影名稱(采用《八佰》作為示例)
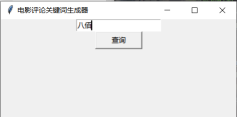
回傳結果:

結果分析:
成功將豆瓣社區中《八佰》的評論區出現的高頻次進行生成詞云圖并回傳,
全部代碼
from tkinter import *
import urllib.request
import requests, re
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import pandas as pd
from imageio import imread
import matplotlib.pyplot as plt
import jieba
def getHtml(url):
"""獲取url頁面"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
content = req.read().decode('utf-8')
return content
def cut_words(top_search):
top_cut=[]
for top in top_search:
top_cut.extend(list(jieba.cut(top))) #使用精確模式切割詞匯
return top_cut
def getComment(url):
"""決議HTML頁面"""
html = getHtml(url)
soupComment = BeautifulSoup(html, 'html.parser')
comments = soupComment.findAll('span', 'short')
onePageComments = []
for comment in comments:
# print(comment.getText()+'\n')
onePageComments.append(comment.getText()+'\n')
return onePageComments
def getid(name):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
}
movie_name = name
params = {
"q": movie_name
}
search_url = "https://www.douban.com/search"
r = requests.get(search_url, params=params, headers=headers)
soup = BeautifulSoup(r.content, 'lxml')
first_movie_info = soup.find('a', {'class': 'nbg'})['onclick']
pattern = re.compile('\d{4,}')
sid = str(pattern.search(first_movie_info).group())
return(sid)
def get_data():
with open('電影評論.txt', 'w', encoding='utf-8') as f:
sid=getid(_input.get())
for page in range(10): # 豆瓣爬取多頁評論需要驗證,
url = 'https://movie.douban.com/subject/'+sid+'/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P'
for i in getComment(url):
f.write(i)
with open("電影評論.txt", "r", encoding='UTF-8') as fin1:
all_words = cut_words(fin1)
#定義停用詞
stop = ['的','你','了','將','為','例',' ','多','再','有','是','等','天','次','讓','在','我','也','就','這樣','啊','和','都','《','》',',','看','!','什么','怎么','這么','很','給','沒有','不是','說'
,'不','嗎','?','!' ,'?',',' ,'...' ,'電影','主','男','女' ]
words_cut = []
for word in all_words:
if word not in stop:
words_cut.append(word)
word_count = pd.Series(words_cut).value_counts()
back_ground = imread("F:\\flower.jpg")
wc = WordCloud(
font_path="C:\\Windows\\Fonts\\simhei.ttf", #設定字體
background_color="white", #設定詞云背景顏色
max_words=400, #詞云允許最大詞匯數
mask=back_ground, #詞云形狀
max_font_size=400, #最大字體大小
random_state=90 #配色方案的種數
)
wc1 = wc.fit_words(word_count) #生成詞云
plt.figure()
plt.imshow(wc1)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
print('succeed!\n')
app = Tk()
_input = Entry()
#_input.place(x=113, y=80)
_input.pack()
app.title("電影評論關鍵詞生成器")
screenwidth = app.winfo_screenwidth()
screenheight = app.winfo_screenheight()
dialog_width = 400
dialog_height = 170
# 前兩個引數是視窗的大小,后面兩個引數是視窗的位置
app.geometry(
"%dx%d+%d+%d" % (dialog_width, dialog_height, (screenwidth - dialog_width) / 2, (screenheight - dialog_height) / 2))
btn = Button(text='查詢', command=get_data,width=10)
btn.place(x=155, y=80)
btn.pack()
app.mainloop()
END
學業繁重,好久沒更新,后續寒假可能會更新,一起加油💪
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236086.html
標籤:python
上一篇:華中農業大學python實驗題