Python機器學習 學習筆記與實踐
環境:win10 + Anaconda Python3.8
該篇總結各類監督學習演算法的實踐使用方法
注:mglearn庫在這個版本的Anaconda中沒有,需要自己安裝一下,步驟:打開Anaconda Prompt -->輸入“pip install mglearn”,然后回車–>完成后輸入“conda list”查看是否安裝成功,
1、線性回歸(普通最小二乘法)
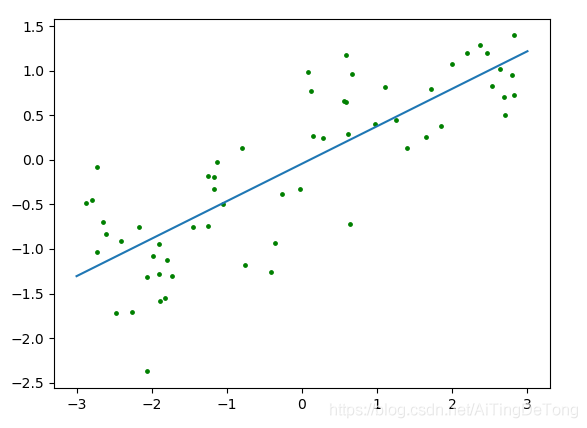
首先對于最簡單的情況,即對每個樣本只有一個特征的資料集使用該演算法,從而直觀地理解,
完整代碼如下:
import mglearn
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
#產生資料集
X,y=mglearn.datasets.make_wave(n_samples=60)
#觀察資料集
plt.scatter(X,y,c="g",s=6)
#將資料集分為訓練集和測驗集
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=1)
#訓練模型
lr=LinearRegression()
lr.fit(X_train,y_train)
#查看線性模型的斜率和截距
print('模型斜率為: {} '.format(lr.coef_))
print('模型截距為: {} '.format(lr.intercept_))
#評價模型性能
print('Score of training set is : {}'.format(lr.score(X_train,y_train)))
print('Score of testing set is : {}'.format(lr.score(X_test,y_test)))
#用圖來觀察模型
x0=np.linspace(-3,3,100)
y0=lr.coef_*x0+lr.intercept_
plt.plot(x0,y0)
plt.show()
輸出結果:

(1)mglearn.datasets.make_wave方法定義如下:
def make_wave(n_samples=100):
rnd = np.random.RandomState(42)
x = rnd.uniform(-3, 3, size=n_samples)
y_no_noise = (np.sin(4 * x) + x)
y = (y_no_noise + rnd.normal(size=len(x))) / 2
return x.reshape(-1, 1), y
(2)“lr=LinearRegression()” 不要忘記括號,若無括號,運行時將報錯:
“fit() missing 1 required positional argument: ‘y’” ,
(3)score()函式回傳的是模型對括號內引數的擬合程度的評價,越接近1,則擬合程度越高,
(4)我們可以看到,模型在訓練集和測驗集上的得分比較接近,這說明也能欠擬合了,沒有完全地提取到訓練資料的特征,
(5)標準線性回歸無法控制復雜度,因而對于過擬合的處理比較無力,因此常用嶺回歸替代,
2、嶺回歸
嶺回歸的思想是使得線性模型的斜率盡量的小,即接近于0,使得X對y的影響達到最小,同時,模型不只要擬合訓練集,還要擬合給定的約束條件,這種約束也叫“正則化”嶺回歸用到的是L2正則化,
A、首先我們先直觀的看看過擬合,用上面的標準線性回歸模型對經典資料集“extended_boston”即經過擴展的波士頓房價資料集的應用,該資料集有506個樣本,每個樣本x有105個特征,目標是y是房價,
修改代碼如下:
import mglearn
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
#產生資料集
X,y=mglearn.datasets.load_extended_boston()
#觀察資料集
print('The shape of extended_boston\'s data is : {}'.format(X.shape))
print('The shape of extended_boston\'s target is : {}'.format(y.shape))
#將資料集分為訓練集和測驗集
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=6)
#訓練模型
lr=LinearRegression()
lr.fit(X_train,y_train)
#評價模型性能
print('Score of training set is : {:.2f}'.format(lr.score(X_train,y_train)))
print('Score of testing set is : {:.2f}'.format(lr.score(X_test,y_test)))
運行結果為:

我們可以看到,這個時候雖然模型可以在訓練集上取得不錯的分數,但在測驗集上的效果與其差距太大,這就很可能發生了過擬合,
B、接下來我們觀察嶺回歸對同樣資料集的性能,
修改代碼,將A中代碼的"LinearRegression"換成“Ridge”,
運行結果如下:

可見,雖然嶺回歸相對于標準線性回歸來說,在訓練集上的性能有所降低,但其在測驗集上的性能提升了,可以說一定程度上緩解了過擬合的問題,在此例當中,使用嶺回歸模型時默認引數alpha為1,這個引數越大,則約束程度越高,模型的斜率越接近0,如果我們嘗試讓alpha接近于0,例如0.01,我們再來看一看模型的性能:

此時表明約束程度很小,自然模型的性能就與標準線性回歸的性能接近了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236087.html
標籤:python
上一篇:Python實作輸入電影名字自動生成豆瓣評論詞云圖(帶GUI界面)小程式
下一篇:Python期末作業