一、問題
模型服務平臺的排序請求出現較多超時情況,且不定時伴隨空指標例外,
二、問題發生前后的改動
召回引擎擴大了召回量,導致排序請求的item數量增加了,
三、出問題的模型
基于XGBoost預測的全排序模型,
四、專案介紹
web-rec-model:模型服務平臺,用于管理排序模型:XGBoost、TensorFlow、pmml…召回模型:item2item,key2item,vec2item…等模型的上下線、測驗模型一致性、模型服務等,
五、一次排序請求流程
1、如下圖所示,一次排序請求流程包含:特征獲取、向量獲取、資料處理及預測,以上提到的三個步驟均采用多執行緒并行處理,均以子任務形式執行,每個階段中間夾雜這資料處理的流程,由主執行緒進行處理,且每個階段的執行任務均為超時回傳,主執行緒等待子執行緒任務時,也采用超時等待的策略,(同事實作的一個樹形任務執行,超時等待的執行緒框架)
2、特征資料倍訓:該步驟為異步執行,將排序計算使用到的特征及分數,模型版本等資訊記錄,后續作為模型的訓練樣本,達到特征倍訓,
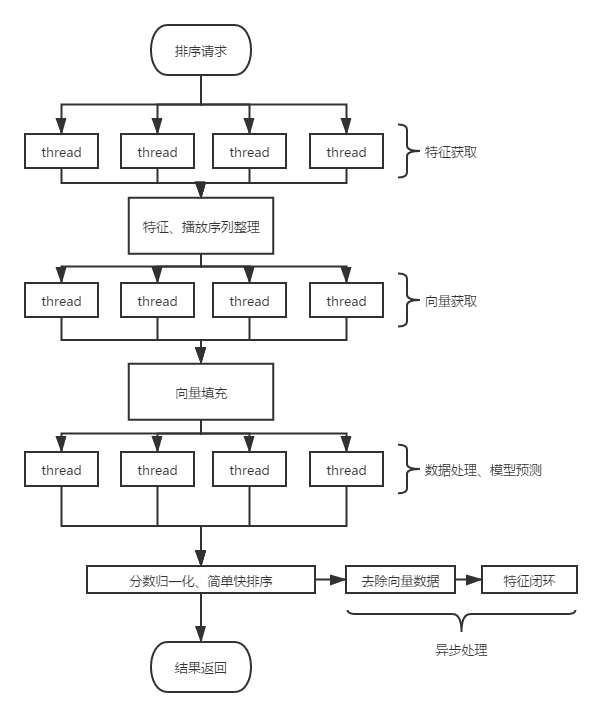
3、一次排序請求中,特征獲取及向量獲取為網路IO(IO密集型任務),超時可直接回應中斷,執行緒可快速回傳,資料處理及模型為計算步驟(CPU密集型任務),
4、當前請求耗時情況:特征與向量的獲取階段耗時均為5-8ms,資料處理及模型預測階段耗時平均在10ms左右,
六、問題發生現象
1、首先是呼叫方:推薦策略平臺,監控報警排序請求的超時數量變多(呼叫方超時時間為300ms),且從監控上看發現排序服務的耗時明顯變長:50ms+,正常高峰期的期望值為50ms以下,
2、其次排序服務告警出現大量超時錯誤,

3、第三根據錯誤資訊定位到該錯誤資訊來自于資料處理及模型預測階段,
4、除了超時變多以外,服務中會出現偶發性的空指標例外,
七、問題排查
1、首先解決空指標這類低級錯誤,
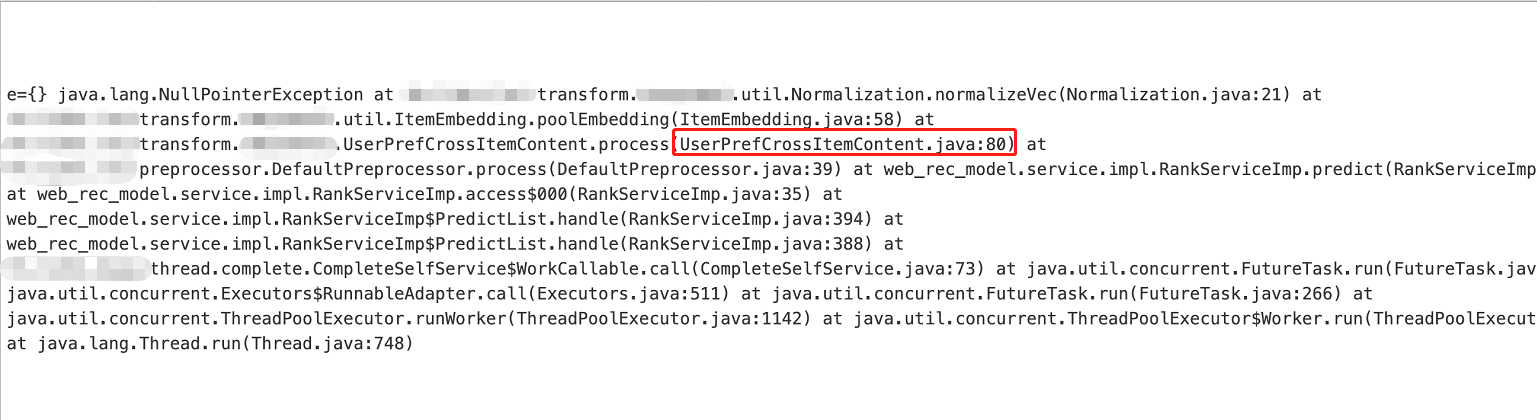
2、根據錯誤提示找到對應的代碼,此處就不粘貼代碼了,做一個簡單的代碼解釋,代碼邏輯為:從Map<String,Object>中根據特征key獲取特征值進行計算,
3、疑惑點出現,首先該Map<String,Object>用于存放特征及向量鍵值對,且key均做了空值計算兼容,特征或者向量在查詢到空值時,會在Map<String,Object>中放入一個對應的默認值,經過反復的代碼確認,報錯資訊對應的代碼不可能出現漏放默認值的情況,
4、借助Arthas的watch命令,監控空指標例外的入參,方便后面做模擬請求還原現場,
5、根據報錯時的資訊進行模擬請求,嘗試N次,且使用不同的報錯資料進行嘗試,均未重現事故,
6、此時懷疑是多執行緒并發進行資料處理及預測時,發生對Map<String,Object>進行修改的動作,導致部分鍵值對丟失,
7、反復檢查代碼,確定資料處理及預測均為只讀動作,不會對Map<String,Object>進行任何鍵值對的刪改,
8、線索中斷,排查一度擱置,
八、豁然開朗
1、借用Arthas進行報錯觀察:使用watch命令,依靠-e引數(指定報錯觸發列印)以及-x n 引數(列印方法入參及回傳值資料層數)
2、根據觀察,發現Map<String,Object>中丟失的均為向量鍵值對,
3、找到問題:在排序請求流程圖中,在主執行緒進行分數歸一化時,會fork子執行緒異步做特征資料進行壓縮寫入kafka,由于Map<String,Object>中存在大量的向量資料,導致保存資料過冗余的情況,此處的做法是先去除所有的向量資料,再進行保存,
4、但是該動作是發生在資料處理及模型預測后的,為何還會因為Map<String,Object>中洗掉鍵值對導致空指標例外呢,
5、此時懷疑是資料處理及模型預測階段,多執行緒任務還沒完成時,主執行緒已經等候超時回傳了,
九、驗證想法
1、還是觀察超時日志,
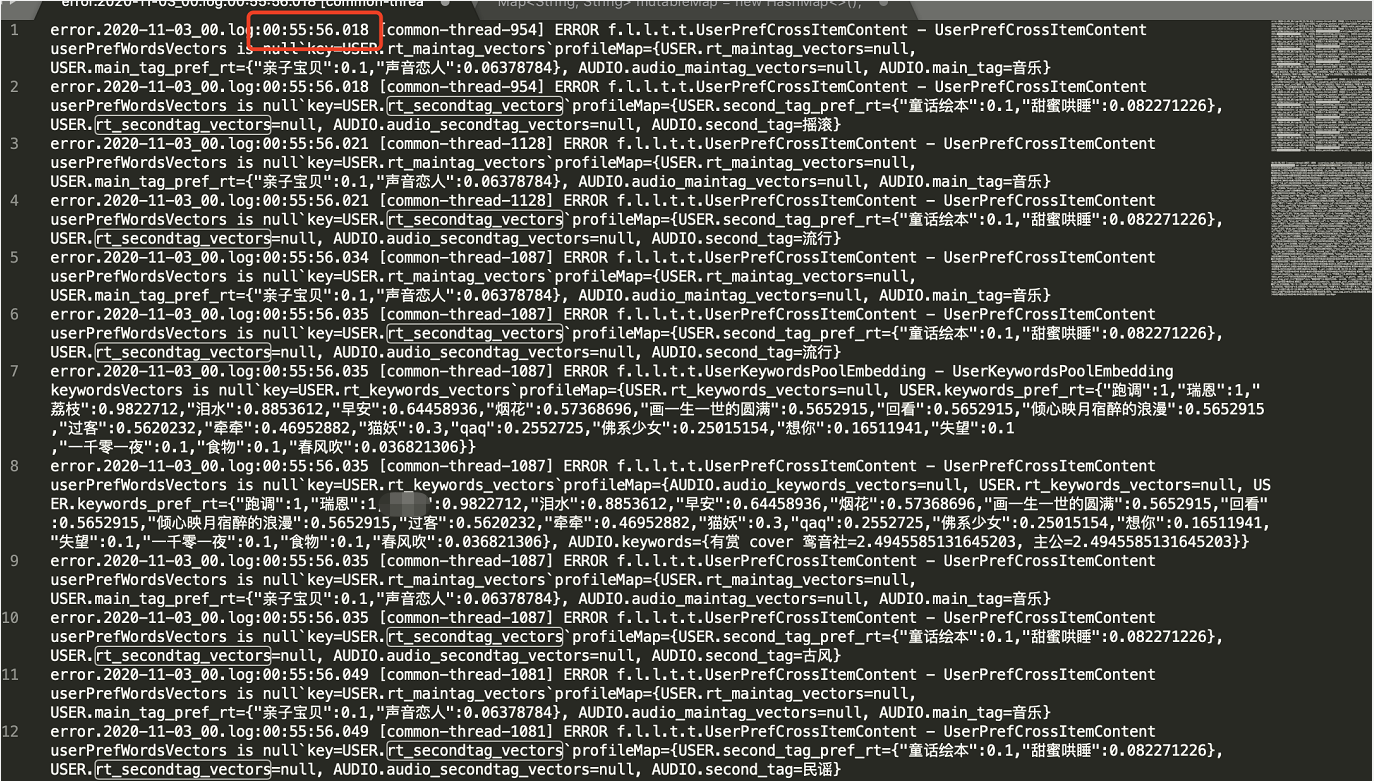
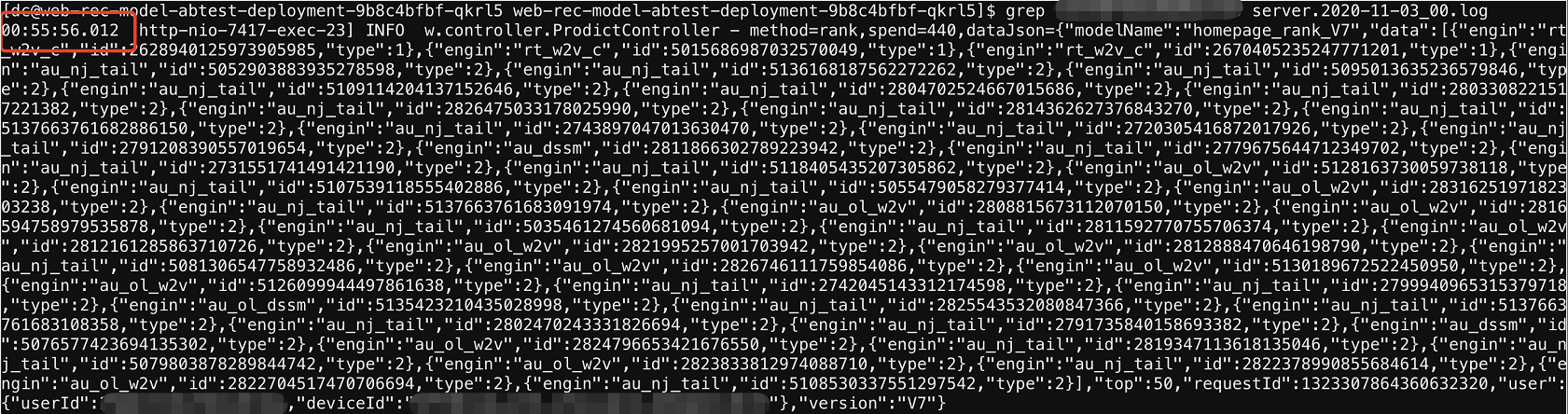
2、發現請求已經回傳后,才出現空指標例外,那基本就可以驗證以上的想法了,
十、問題解決
1、翻看使用的多執行緒框架(同事實作),主執行緒超時等待子執行緒任務,主執行緒超時回傳后,沒有通知子執行緒任務取消,所以才發生請求已回傳,特征資料異步落地后,偶發性出現晚到的空指標例外的情況,如下圖,主執行緒超時回傳后,只取消主執行緒任務,
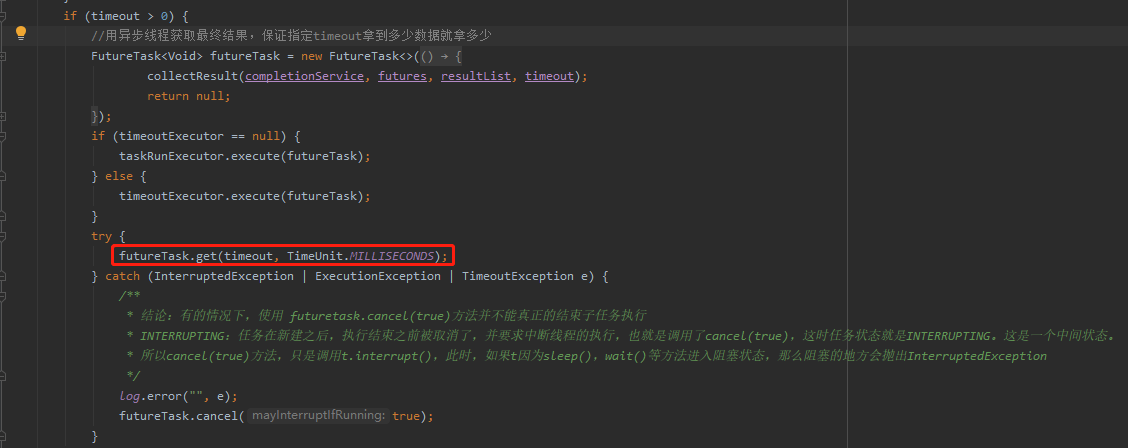
2、解決思路:主執行緒超時回傳后,中斷子任務(取消子任務),由于java的中斷機制為軟中斷,一般是通過中斷標志位進行執行緒中斷協作的,當然IO或者sleep的中斷由系統幫我們做了中斷可以快速回傳,對于CPU密集型的任務,是需要使用者在合適的計算點上做標志位判斷,確定是否已中斷結束任務,以這種協作的方式達到中斷,(此處可能有部分理解不當)
3、修改多執行緒框架,在主執行緒超時回傳后,修改子執行緒中斷標志位,
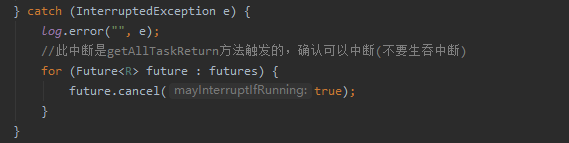
4、在計算流程中加入執行緒中斷檢查,如果被中斷則提前結束計算,

十一、效果檢查
1、修改發版后,空指標沒再出現,(其實該空指標是不影響排序結果,因為結果已經是錯的,該例外只是附帶的蟲子而已)
2、超時請求減少,高峰期的超時資料減少三分之一,50ms+的排序請求有明顯減少,
十二、復盤
1、主執行緒等待子任務的場景下,如果主執行緒超時回傳了,需通知子執行緒結束執行的任務,首先,主執行緒回傳了,表示子任務已被丟棄,繼續執行都是在做無用的計算,占用計算機資源,也不是說占著茅坑不拉屎,而是拉了沒人要,應該盡量減少服務器資源用在沒必要的消耗上,
2、該服務在資料處理及預測階段使用的執行緒池佇列為SynchronousQueue,如果不了解SynchronousQueue的話可以簡單理解為一個0長度的佇列,任務進池子時必須要有執行緒進行對接,與常規的BlockingQueue不同的是,任務在池子中不會堆積,對于任務的快速回應比較友好,但是也因為如果沒有空閑的執行緒,則會不停創建執行緒直到最高執行緒數限制而觸發丟棄策略,在該專案問題中,由于部分子任務在主執行緒回傳后仍然在執行,新的請求進來后,會出現沒有空閑執行緒的情況,導致池子創建新執行緒接任務,對于CPU密集型任務來說,過多的執行緒數對服務來說是另一種負擔,畢竟執行緒切換的代價還是比較大的,這就套入死回圈了,(個人理解,如表述有誤,還望指正)
看完三件事??
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力,
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識,
-
同時可以期待后續文章ing??

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236345.html
標籤:Java
上一篇:GitHub 標星 15.3k,Java 編程思想最新中文版(On Java 8)
下一篇:記憶體問題探微