這篇文章是我在公司 TechDay 上分享的內容的文字實錄版,本來不想寫這么一篇冗長的文章,因為有不少的同學問是否能寫一篇相關的文字版,本來沒有的也就有了,
說起來這是我第二次在 TechDay 上做的分享,四年前第一屆 TechDay 不知天高地厚,上去講了一個《MySQL 最佳實踐》,現在想起來那些最佳實踐貌似不怎么佳了,不扯遠了,接下來看看具體的內容,
這次分享的主題是《記憶體問題探微》,會分為下面幾個方面來聊一聊,
- Linux 記憶體知識的底層原理
- malloc、free 的底層實作原理
- ptmalloc2 的實作原理
- Arena、Heap、Chunk、Bin 的內部結構
- java 開發相關的記憶體問題說明
為什么要分享這個主題
因為這是我被問的最頻繁的問題,哎呀我的程式 OOM 了怎么辦,我的程式記憶體超過配額被 k8s 殺掉了怎么辦,我的程式看起來記憶體占用很高正常嗎?
下面這個圖就是我們之前做壓測的時候,Nginx 記憶體占用過高,被作業系統殺掉的一個圖,
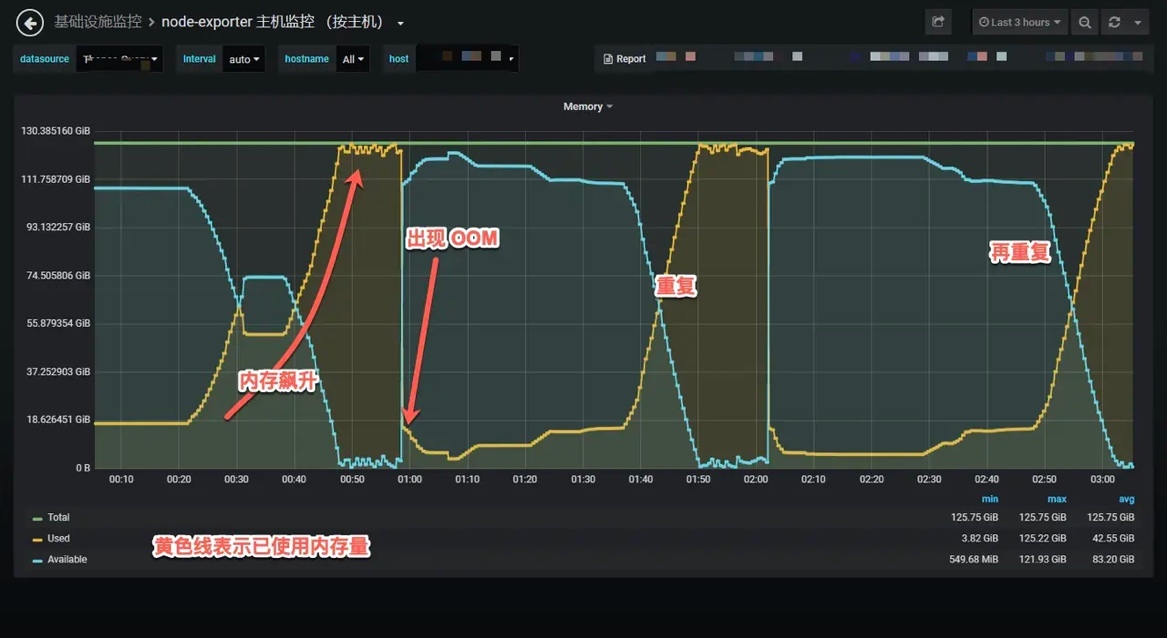
當壓測流量進來時,Nginx 記憶體蹭蹭蹭往上漲,達到 130G 左右時被系統 OOM-killer 殺掉,流量入口都有瓶頸,壓測就沒法繼續進行下去了,那一個成熟的組件出現問題,要從哪些思路排查呢?
第二個原因就是記憶體管理的知識非常龐大,比如 linux 三駕馬車,CPU、IO、記憶體,記憶體可以說是這里面最復雜的,與 CPU 和 IO 的性能有著千絲萬縷的關系,搞懂了記憶體問題,才可以真正的搞清楚很多 Linux 性能相關的問題,
我們最近在做一個 8 點早讀會,每天 8 點到 9 點分享一個小時,我花了將近 18 個小時講記憶體相關的知識,但是還是有很多東西沒能覆寫到,所以我想借這個機會再次把我們之前分享的一些東西拿出來再講一講,盡可能把我們開發程序中最常用的一些東西講清楚,
理解記憶體可以幫助我們更深入的理解一些問題,比如:
- 為什么 golang 原生支持函式多回傳值
- golang 逃逸分析是怎么做的
- Java 堆外記憶體泄露如何分析
- C++ 智能指標是如何實作的
第二部分:Linux 記憶體管理的原理
接下來我們來開始本次分享的主要內容:Linux 記憶體管理的原理,與人類的三個終極問題一樣,記憶體也有三個類似的問題,記憶體是什么,記憶體從哪里申請來,釋放以后去了哪里,
虛擬記憶體與物理記憶體
首先我們來先看看虛擬記憶體與物理記憶體,虛擬記憶體和物理記憶體的關系印證了一句名言,「作業系統中的任何問題都可以通過一個抽象的中間層來解決」,虛擬記憶體正是如此,
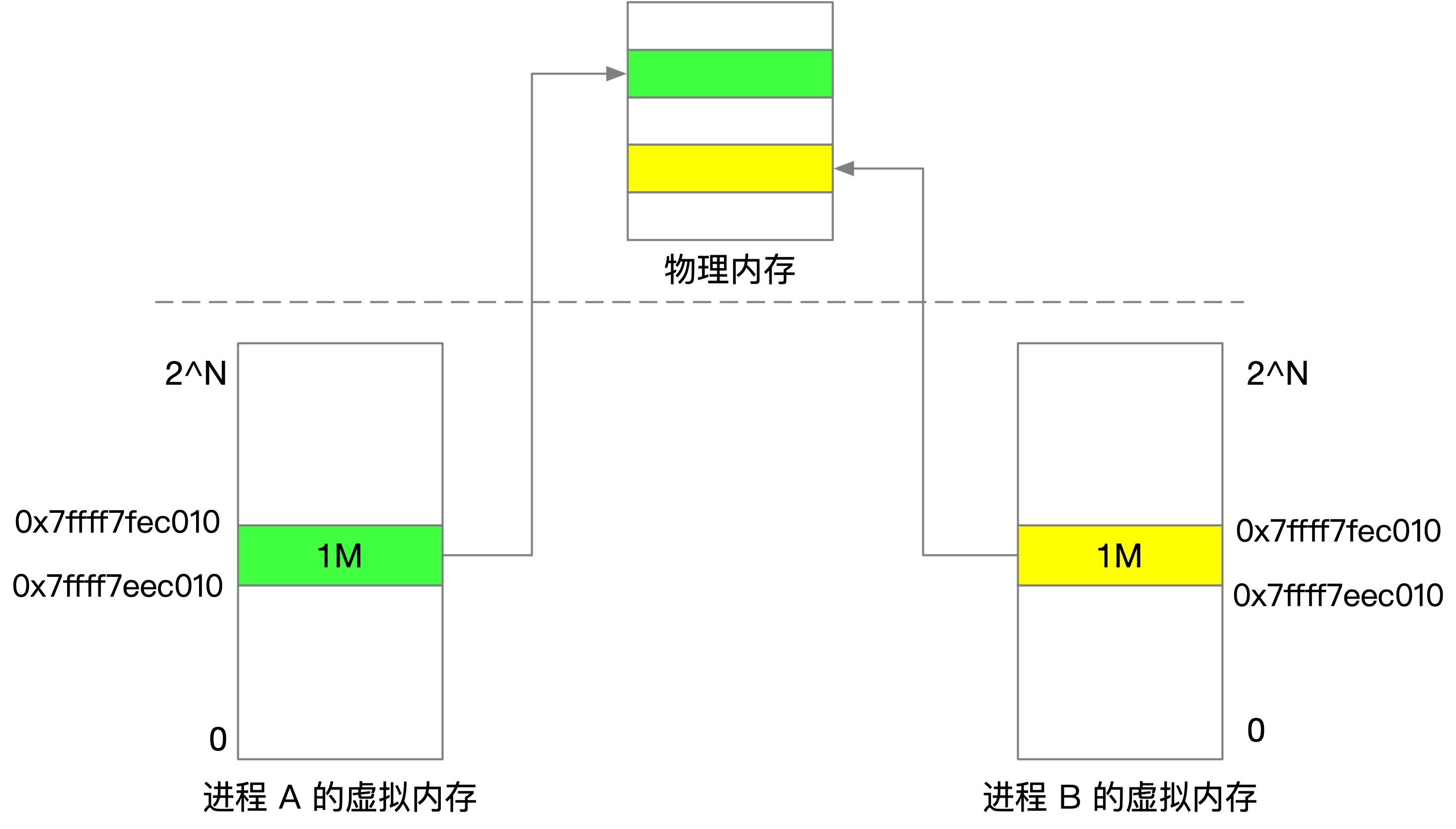
沒有虛擬記憶體,行程直接就可能修改其它行程的記憶體資料,虛擬記憶體的出現對記憶體使用做好了隔離,每個行程擁有獨立的、連續的、統一的虛擬地址空間(好一個錯覺),像極了一個戀愛中的男人,擁有了她,仿佛擁有了全世界,
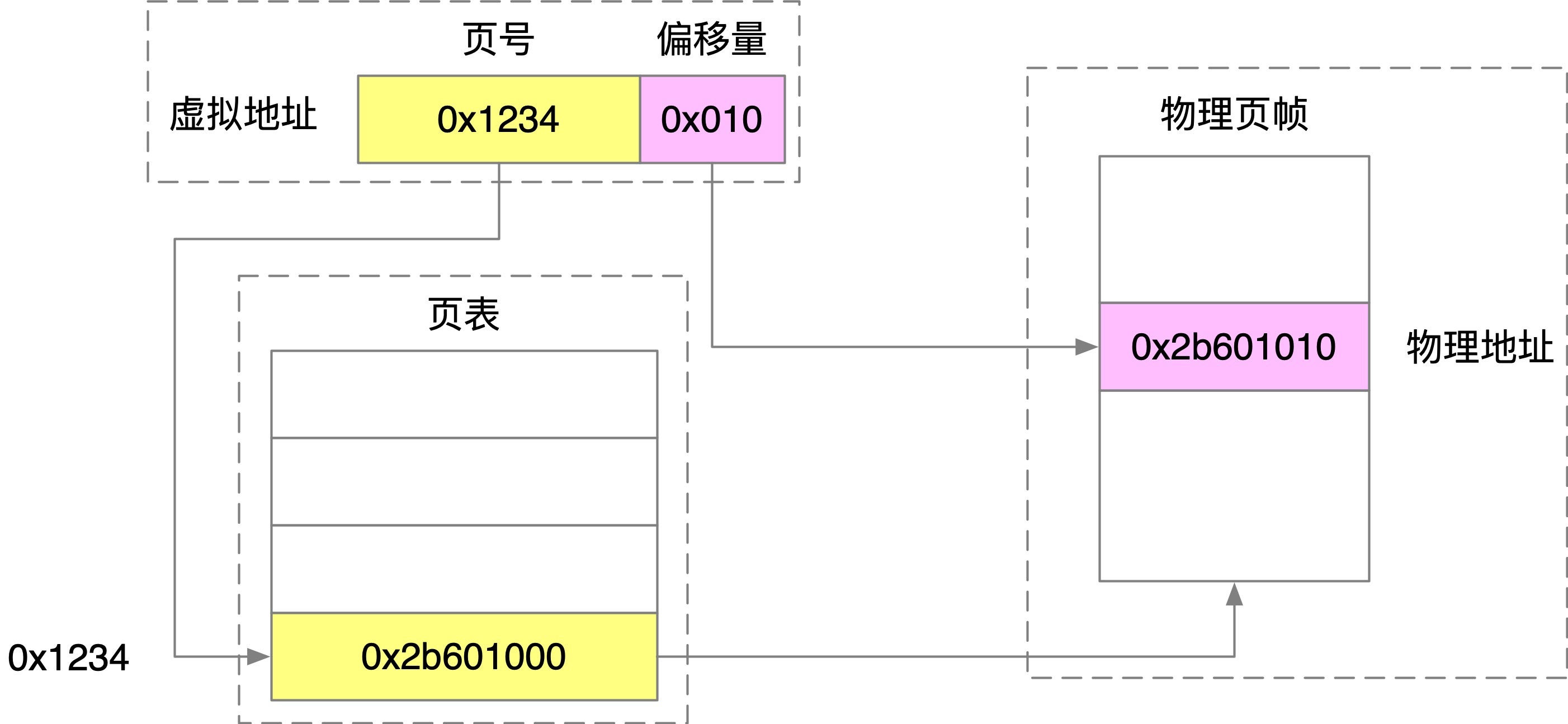
應用程式看到的都是虛擬記憶體,通過 MMU 進行虛擬記憶體到物理記憶體的映射,我們知道 linux 記憶體是按 4k 對齊,4k = 2^12 ,虛擬地址中的低 12 位其實是一個偏移量,
現在我們把頁表想象為一個一維陣列,對于虛擬地址中的每一頁,都分配陣列的一個槽位,這個槽位指向物理地址中的真正地址,那么有這么一個虛擬記憶體地址 0x1234010,那 0x010 就是頁內偏移量,0x1234 是虛擬頁號,CPU 通過 MMU 找到 0x1234 映射的物理記憶體頁地址,假定為 0x2b601000,然后加上頁內偏移 0x010,就找到了真正的物理記憶體地址 0x2b601010,如下圖所示,
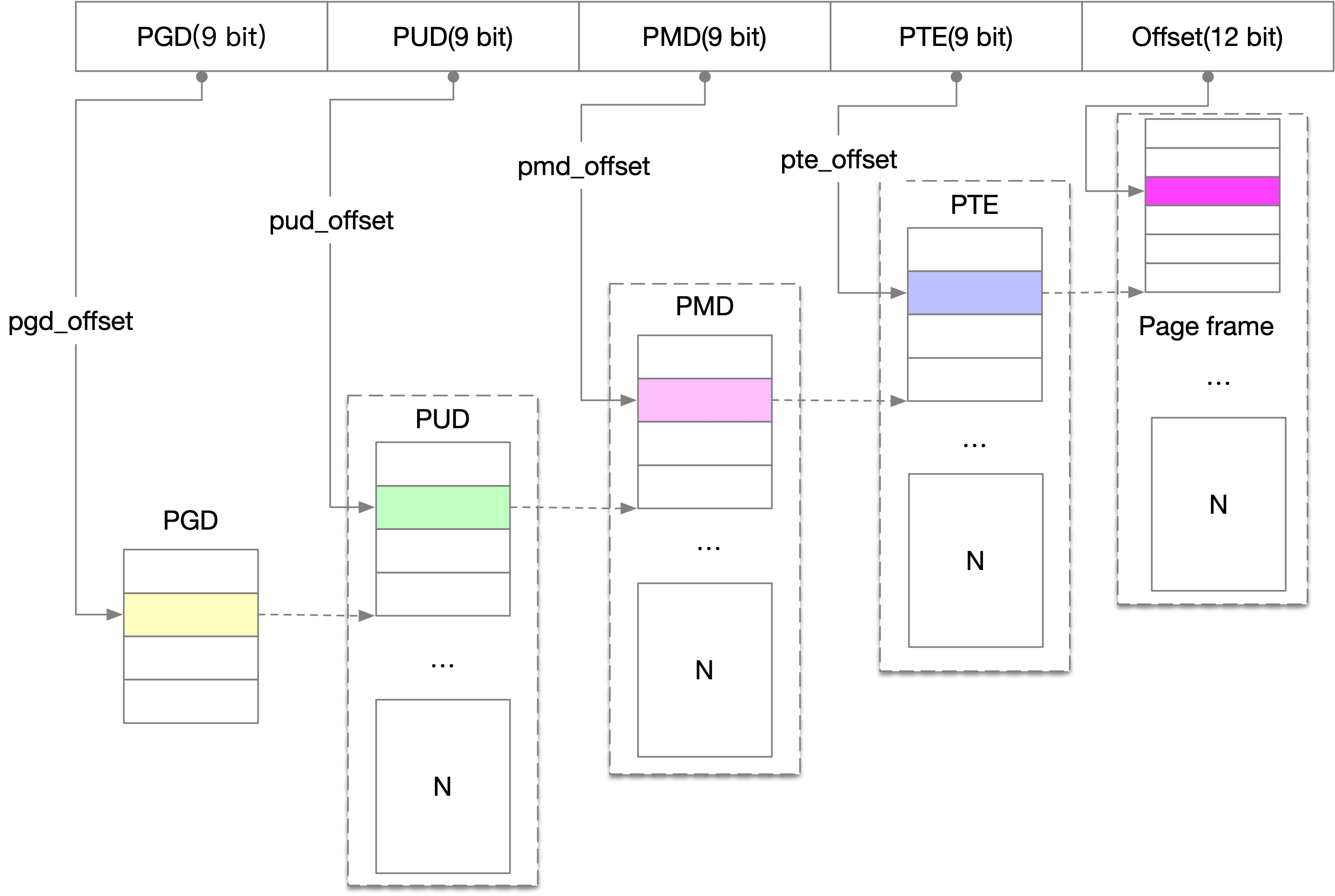
Linux 四級頁表
但是這種方式有一個很明顯的問題,虛擬地址空間可能會非常大,就算拿 32 位的系統為例,虛擬地址空間為 4GB,用戶空間記憶體大小為 3GB,每頁大小為 4kB,陣列的大小為 786432(1024 * 1024),每個頁表項用 4 個位元組來存盤,這樣 4GB 的空間映射就需要 3MB 的記憶體來存盤映射表,(備注:這里很多資料說的是 4M,也沒有太大的問題,我這里的考慮是內核空間是共用的,不用太過于糾結,)
對于單個行程來說,占用 3M 看起來沒有什么,但是頁表是行程獨占的,每個行程都需要自己的頁表,如果有一百個行程,就會占用 300MB 的記憶體,這還僅僅是做地址映射所花的記憶體,如果考慮 64 位系統超大虛擬地址空間的情況,這種一維的陣列實作的方式更加不切實際,
為了解決這個問題,人們使用了 level 的概念,頁表的結構分為多級,頁表項的大小只與虛擬記憶體空間中真正使用的多少有關,之前一維陣串列示的方式頁表項的多少與虛擬地址空間的大小成正比,這種多級結構的方式使得沒有使用的記憶體不用分配頁表項,
于是人們想出了多級頁表的形式,這種方式非常適合,因為大部磁區域的虛擬地址空間實際上是沒有使用的,使用多級頁表可以顯著的減少頁表本身的記憶體占用,在 64 位系統上,Linux 采用了四級頁表,
- PGD:Page Global Directory,頁全域目錄,是頂級頁表,
- PUD:Page Upper Directory,頁上級目錄,是第二級頁表
- PMD:Page Middle Derectory,頁中間目錄,是第三級頁表,
- PTE:Page Table Entry,頁面表,最后一級頁表,指向物理頁面,
如下圖所示,
應用程式看到的只有虛擬記憶體,是看不到物理地址的,當然是有辦法可以通過一些手段通過虛擬地址拿到物理地址,比如這個例子,我們 malloc 一個 1M 的空間,回傳了一個虛擬地址 0x7ffff7eec010,怎么知道這個虛擬地址對應的物理記憶體地址呢?
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
int main() {
char *p = NULL;
p = malloc(1024 * 1024);
*p = 0;
printf("ptr: %p, pid: %d\n", p, getpid());
getchar();
return 0;
}
ptr: 0x7ffff7eec010, pid: 2621
在應用層來做這個事情沒有辦法,但是難不倒我們,我們來寫一個內核擴展模塊來實作這個功能,
寫一個內核模塊也非常簡單,分為下面幾個步驟:
- 定義好兩個回呼鉤子,module_init, module_exit
- 通過傳入的 pid 獲取到這個行程的 task_struct通過 task_struct 中的 mm 變數和傳入的虛擬記憶體地址 va,就可以拿到 pgd
- 通過 pgd 就可以拿到 pud,然后再拿到 pmd,最好獲取到 pte,這個 pte 已經存盤的是物理記憶體的頁幀
- 通過低 12 位的頁內偏移就可以得到最終的物理記憶體的地址,
精簡以后的代碼如下所示,
#include <linux/module.h>
...
int my_module_init(void) {
unsigned long pa = 0;
pgd_t *pgd = NULL; pud_t *pud = NULL;
pmd_t *pmd = NULL; pte_t *pte = NULL;
struct pid *p = find_vpid(pid);
struct task_struct *task_struct = pid_task(p, PIDTYPE_PID);
pgd = pgd_offset(task_struct->mm, va); // 獲取第一級 pgd
pud = pud_offset(pgd, va); // 獲取第二級 pud
pmd = pmd_offset(pud, va); // 獲取第三級 pmd
pte = pte_offset_kernel(pmd, va); // 獲取第四級 pte
unsigned long page_addr = pte_val(*pte) & PAGE_MASK;
unsigned long page_addr &= 0x7fffffffffffffULL;
page_offset = va & ~PAGE_MASK;
pa = page_addr | page_offset; // 加上偏移量
printk("virtual address 0x%lx in RAM Page is 0x%lx\n", va, pa);
return 0;
}
void my_module_exit(void) {
printk("module exit!\n");
}
module_init(my_module_init); // 注冊回呼鉤子
module_exit(my_module_exit); // 注冊回呼鉤子
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Arthur.Zhang");
MODULE_DESCRIPTION("A simple virtual memory inspect");
我們編譯這個內核模塊會生成一個 .ko 檔案,然后加載這個 .ko 檔案,傳入行程號、虛擬記憶體地址,
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
insmod my_mem.ko pid=2621 va=0x7ffff7eec010
然后執行 dmesg -T 就可以看到真正的物理地址的值了,
[Sat Oct 10 05:11:12 2020] virtual address 0x7ffff7eec010 in RAM Page is 0x2358a4010
可以看到在這個例子中,虛擬地址 0x7ffff7eec010 對應的物理地址是 0x2358a4010,
完整的代碼見:https://github.com/arthur-zhang/virtualmem2physical
行程的記憶體布局
前面提到了虛擬內核和物理記憶體的關系,我們知道 linux 上的可執行檔案的格式是 elf,elf 是一個靜態檔案,這個靜態檔案由不同的分節組成,我們這里叫它 section,在運行時,部分跟運行時相關的 Section 會被映射到行程的虛擬地址空間中,比如圖中的代碼段和資料段,除了這部分靜態的區域,行程啟動以后還有大量動態記憶體消耗區,比如堆疊、堆、mmap 區,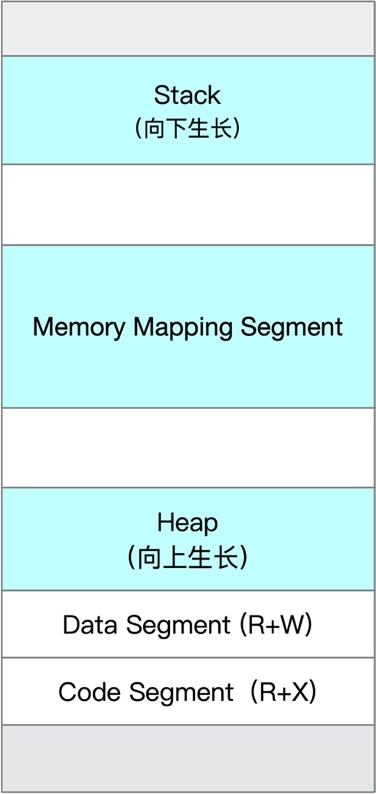
下面這個圖是我們線上 java 服務使用 pmap 輸出的記憶體布局的一部分,如下圖所示,
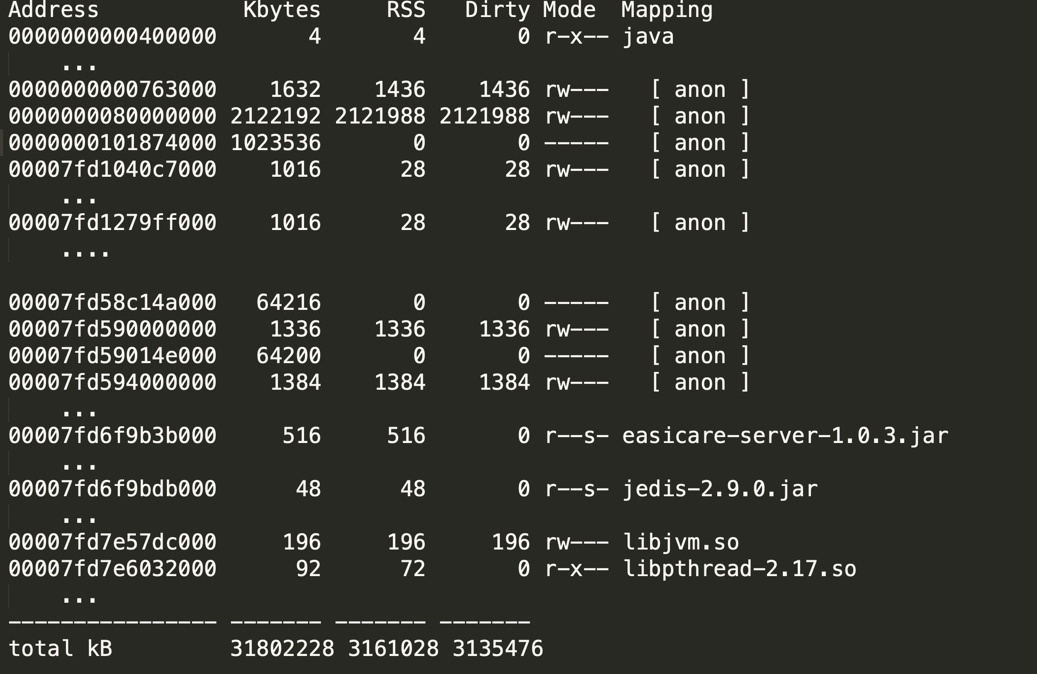
那怎么來看這些部分呢?這就需要我們深入去理解 Linux 中行程的記憶體是如何被瓜分的,
libc 記憶體管理原理探究
Linux 記憶體管理有三個層面,第一層是我們的用戶管理層,比如我們自己程式的記憶體池,mysql 的 bufferpool,第二層是 C 的運行時庫,這部分代碼是對內核的一個包裝,方便上層應用更方便的開發,再下一層就是我們的內核層了,
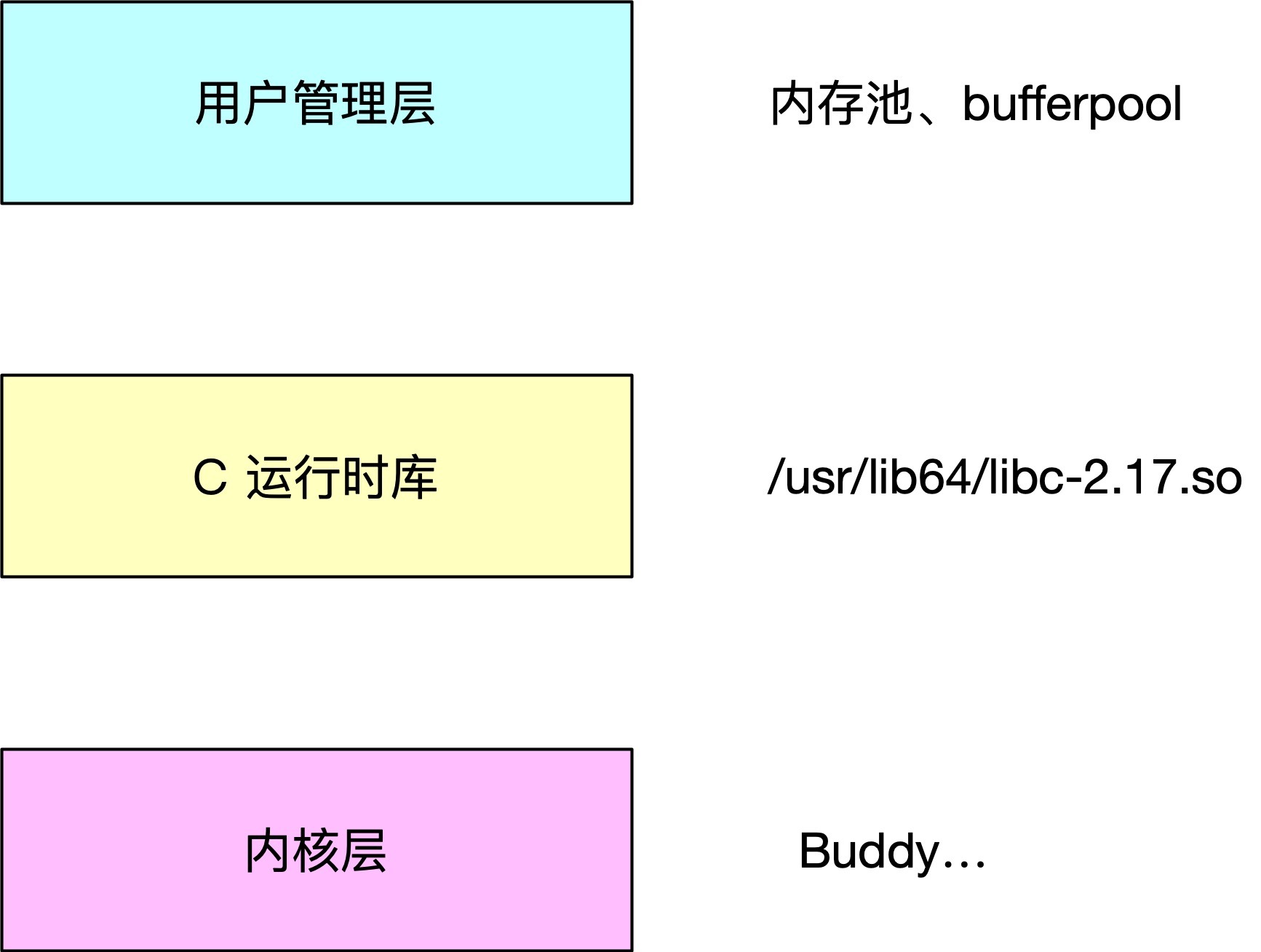
我們今天要重點介紹的就是中間那一層,這一層是由一個 libc 的庫來實作的,接下來詳細看看看 libc 記憶體管理是如何做的,
Linux 記憶體管理的核心思想就是分層管理、批發零售、隱藏內部細節,我們還需要銘記在心的是 libc 中堆的管理是針對小記憶體分配釋放來設計的,為了編程介面上的統一,大記憶體也是支持的,
我們先來看記憶體申請釋放的兩個函式,malloc 和 free,這兩個函式的定義如下,
#include <stdlib.h>
void *malloc(size_t size);
void free(void *ptr);
這兩個函式壓根不是系統呼叫,它們只是對 brk、mmap、munmap 系統呼叫的封裝,那為什么有了這些系統呼叫,還需要 libc 再封裝一層呢?
一個主要原因是因為系統呼叫很昂貴,而記憶體的申請釋放又特別頻繁,所以 libc 采取的的方式就是批量申請,然后作為記憶體的黃牛二道販子,慢慢零售給后面的應用程式,
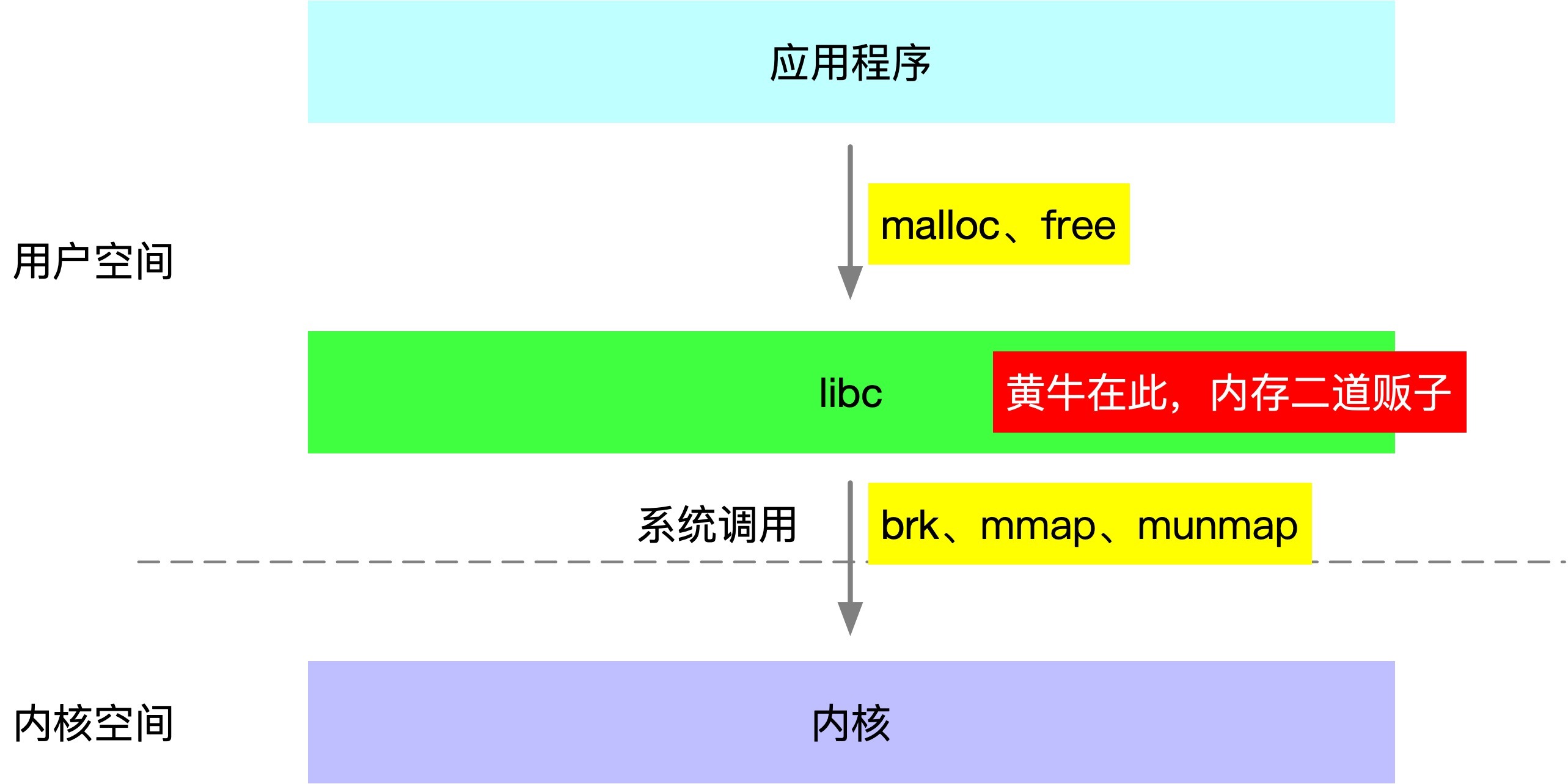
第二個原因是為了編程上的統一,比如有些時候用 brk,有些時候用 mmap,不太友好,brk 在多執行緒下還需要進行加鎖,用一個 malloc 就很香,
Linux 記憶體分配器
Linux 的記憶體分配器有很多種,一開始是 Doug Lea 大神開發的 dlmalloc,這個分配器對多執行緒支持不友好,多執行緒下會競爭全域鎖,隨后有人基于 dmalloc 開發了 ptmalloc,增加了多執行緒的支持,除了 linux 官方的 ptmalloc,各個大廠有開發不同的 malloc 演算法,比如 facebook 出品的 jemalloc,google 出品的 tcmalloc,

這些記憶體分配器致力于解決兩個問題:多執行緒下鎖的粒度問題,是全域鎖,還是區域鎖還是無鎖,第二個問題是小記憶體回收和記憶體碎片問題,比如 jemalloc 在記憶體碎片上有顯著的優勢,
ptmalloc 的核心概念
接下來我們來看 Linux 默認的記憶體分配器 ptmalloc,我總結了一下它有關的四個核心概念:Arena、Heap、Chunk、Bins,
Arena
先來看 Arena,Arena 的中文翻譯的意思是主戰場、舞臺,對應在記憶體分配這里,指的是記憶體分配的主戰場,
Arena 的出現首先用來解決多執行緒下全域鎖的問題,它的思路是盡可能的讓一個執行緒獨占一個 Arena,同時一個執行緒會申請一個或多個堆,釋放的記憶體又會進入回收站,Arena 就是用來管理這些堆和回收站的,
Arena 的資料結構長啥樣?它是一個結構體,可以用下面的圖來表示,
它是一個單向回圈鏈表,使用 mutex 鎖來處理多執行緒競爭,釋放的小塊記憶體會放在 bins 的結構中,
前面提到,Arena 會盡量讓一個執行緒獨占一個鎖,那如果我有幾千個執行緒,會生成幾千個 Arena 嗎?顯然是不會的,所有跟執行緒有關的瓶頸問題,最后都會走到 CPU 核數的限制這里來,分配區的個數也是有上限的,64 位系統下,分配區的個數大小是 cpu 核數的八倍,多個 Arena 組成單向回圈鏈表,
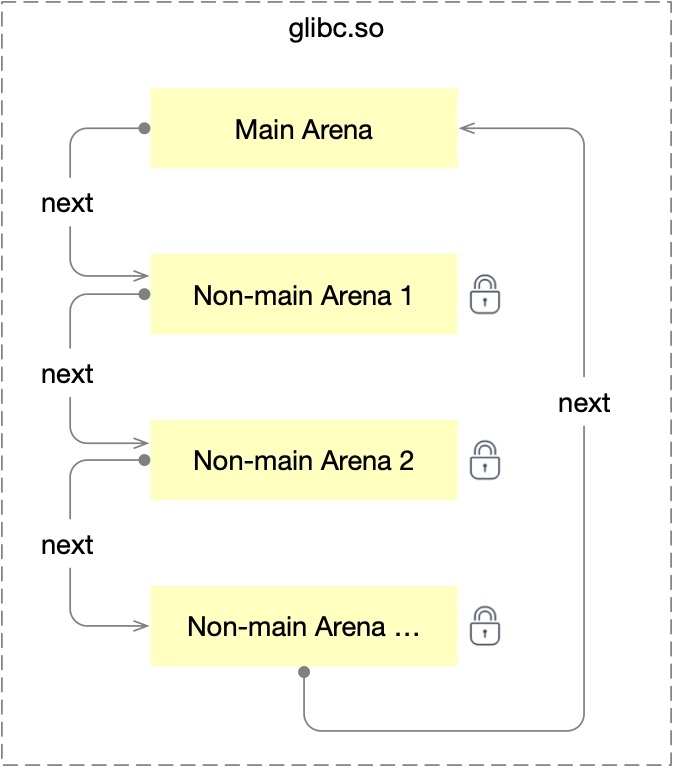
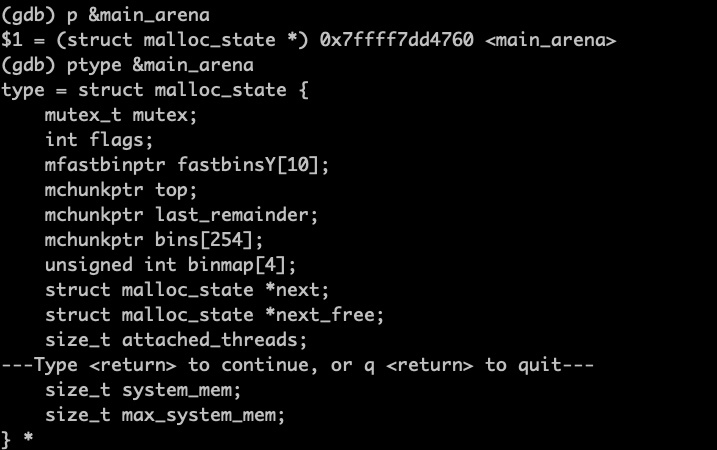
我們可以寫個代碼來列印 Arena 的資訊,它的原理是對于一個確定的程式,main_arena 的地址是一個位于 glibc 庫的確定的地址,我們在 gdb 除錯工具中可以列印這個地址,也可以使用 ptype 命令來查看這個地址對應的結構資訊,如下圖所示,
有了這個基礎,我們就可以寫一個 do while 來遍歷這個回圈鏈表了,我們把 main_arena 的地址轉為 malloc_state 的指標,然后 do while 遍歷,直到遍歷到鏈表頭,
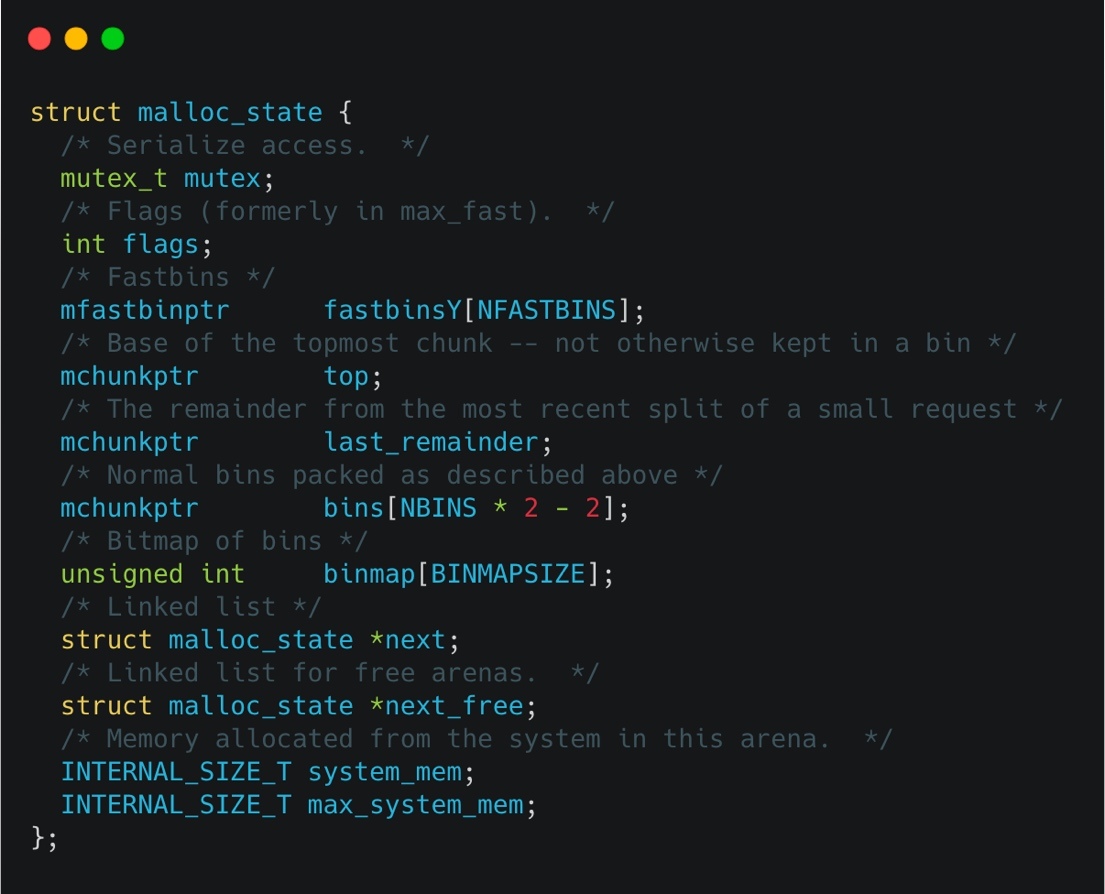
struct malloc_state {
int mutex;
int flags;
void *fastbinsY[NFASTBINS];
struct malloc_chunk *top;
struct malloc_chunk *last_remainder;
struct malloc_chunk *bins[NBINS * 2 - 2];
unsigned int binmap[4];
struct malloc_state *next;
struct malloc_state *next_free;
size_t system_mem;
size_t max_system_mem;
};
void print_arenas(struct malloc_state *main_arena) {
struct malloc_state *ar_ptr = main_arena;
int i = 0;
do {
printf("arena[%02d] %p\n", i++, ar_ptr);
ar_ptr = ar_ptr->next;
} while (ar_ptr != main_arena);
}
#define MAIN_ARENA_ADDR 0x7ffff7bb8760
int main() {
...
print_arenas((void*)MAIN_ARENA_ADDR);
return 0;
}
輸出結果如下,
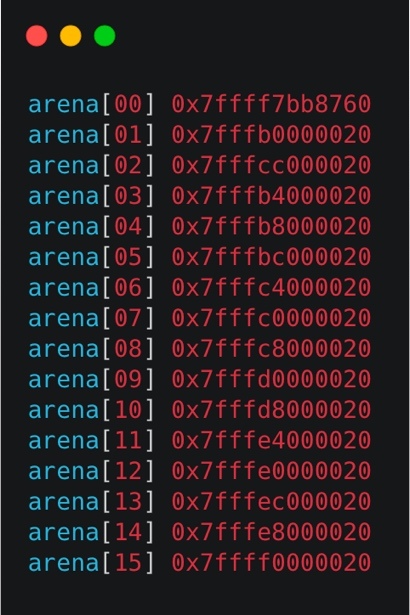
那為什么還要區分一個主分配,一個非主分配區呢?
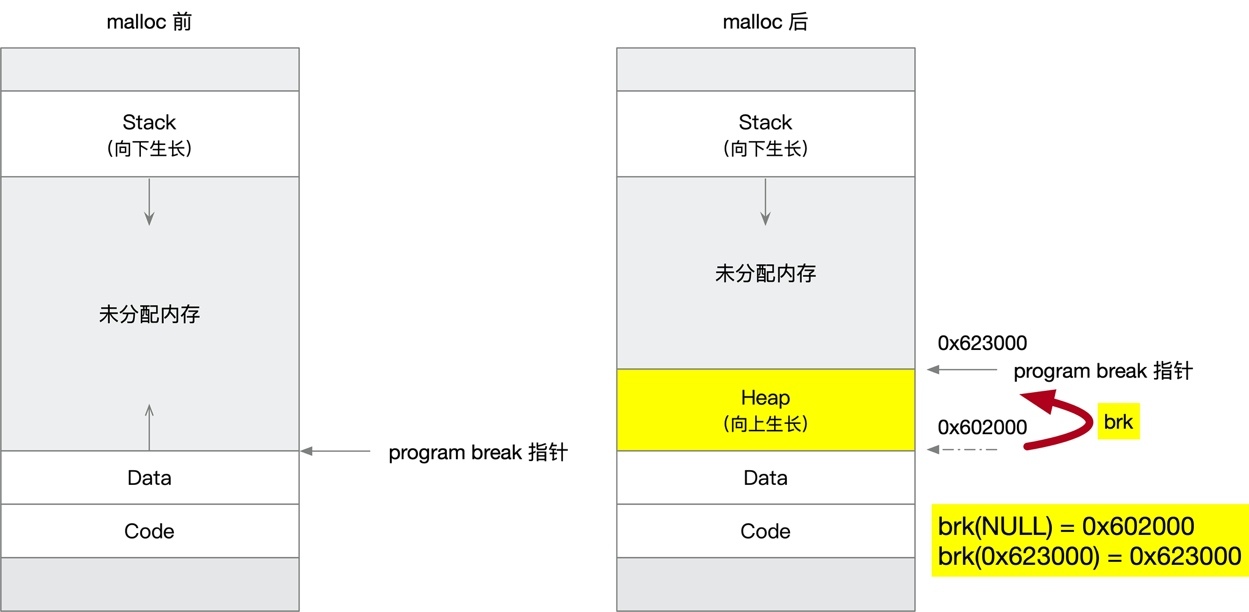
這有點像皇上和王爺的關系, 主分配區只有一個,它還有一個特權,可以使用靠近 DATA 段的 Heap 區,它通過調整 brk 指標來申請釋放記憶體,
從某種意義上來講,Heap 區不過是 DATA 段的擴展而已,
非主分配區呢?它更像是一個分封在外地,自主創業的王爺,它想要記憶體時就使用 mmap 批發大塊記憶體(64M)作為子堆(Sub Heap),然后在慢慢零售給上層應用,
一個 64M 用完,再開辟一個新的,多個子堆之間也是使用鏈表相連,一個 Arena 可以有多個子堆,在接下的內容中,我們還會繼續詳細介紹,
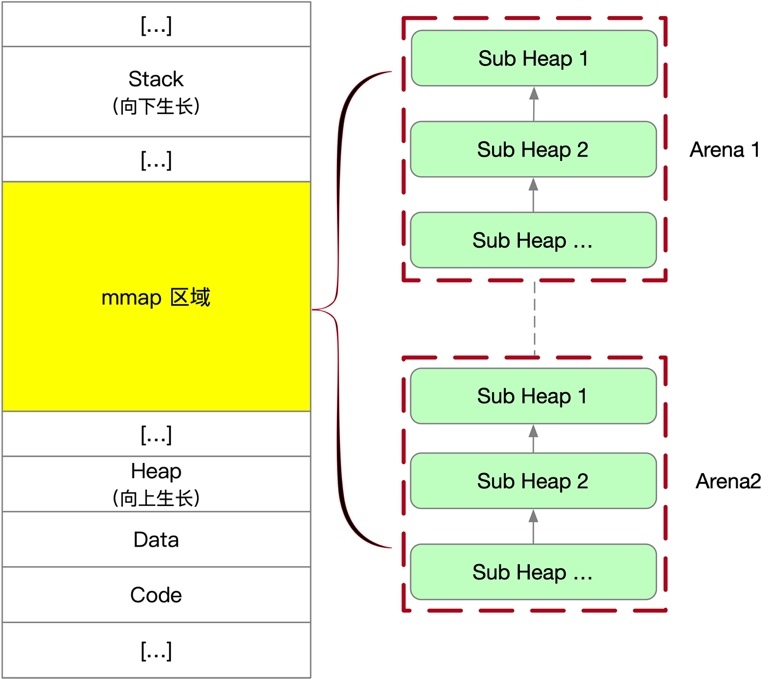
Heap
接下來我們來看 ptmalloc2 的第二個核心概念 ,heap 用來表示大塊連續的記憶體區域,
主分配區的 heap 沒有什么好講的,我們這里重點看「非主分配」的子堆(也稱為模擬堆),前面提到過,非主分配批發大塊記憶體進行切割零售的,
那如何理解切割零售這句話呢?它的實作也非常簡單,先申請一塊 64M 大小的不可讀不可寫不可執行(PROT_NONE)的記憶體區域,需要記憶體時使用 mprotect 把一塊記憶體區域的權限改為可讀可寫(R+W)即可,這塊記憶體區域就可以分配給上層應用了,
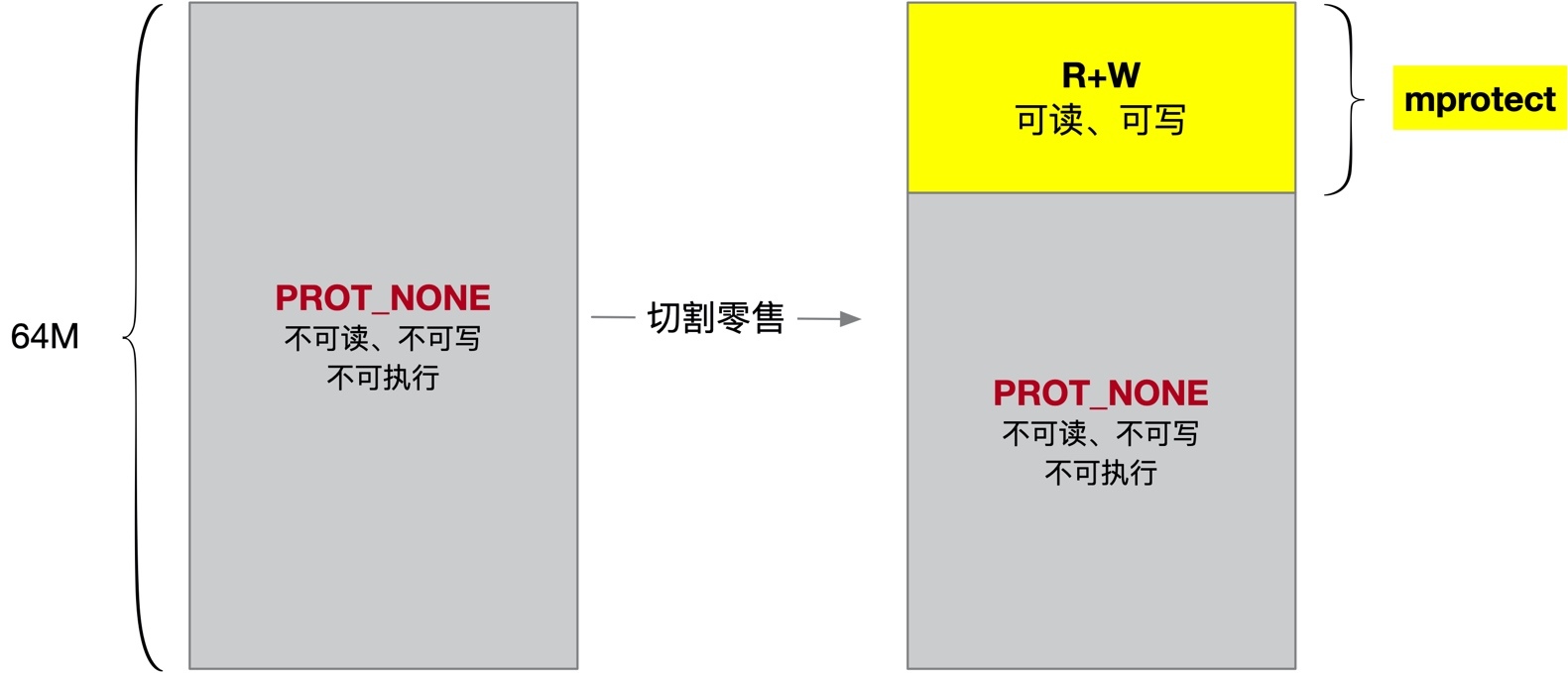
以我們前面 java 行程的記憶體布局為例,
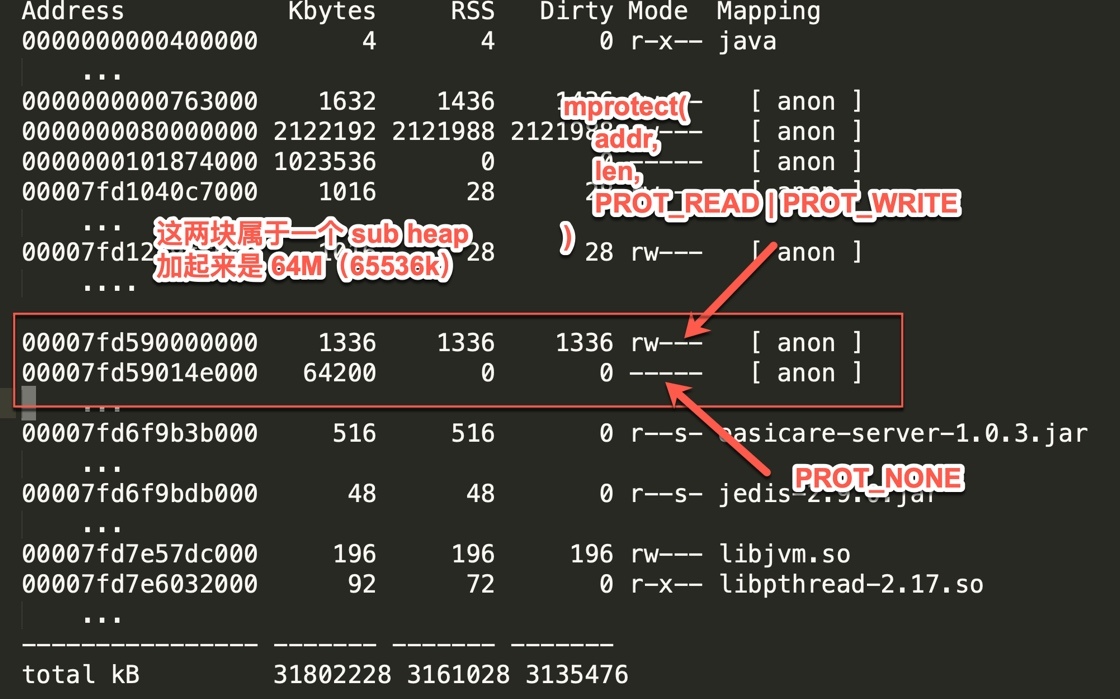
這中間的兩塊記憶體區域是屬于一個子堆,它們加起來的大小是 64M,然后其中有一塊 1.3M 大小的記憶體區域就是使用 mprotrect 分配出去的,剩下的 63M 左右的區域,是不可讀不可寫不可執行的待分配區域,
知道這個有什么用呢?太有用了,你在 google 里所有 Java 堆外記憶體等問題,有很大可能性會搜到 Linux 神奇的 64M 記憶體問題,有了這里的知識,你就比較清楚到底這 64M 記憶體問題是什么了,

與前面的 Arena 一樣,我們同樣可以在代碼中,遍歷所有 Arena 的所有的 heap 串列,代碼如下所示,
struct heap_info {
struct malloc_state *ar_ptr;
struct heap_info *prev;
size_t size;
size_t mprotect_size;
char pad[0];
};
void dump_non_main_subheaps(struct malloc_state *main_arena) {
struct malloc_state *ar_ptr = main_arena->next;
int i = 0;
while (ar_ptr != main_arena) {
printf("arena[%d]\n", ++i);
struct heap_info *heap = heap_for_ptr(ar_ptr->top);
do {
printf("arena:%p, heap: %p, size: %d\n", heap->ar_ptr, heap, heap->size);
heap = heap->prev;
} while (heap != NULL);
ar_ptr = ar_ptr->next;
}
}
#define MAIN_ARENA_ADDR 0x7ffff7bb8760
dump_non_main_subheaps((void*)MAIN_ARENA_ADDR);
Chunk
接下來我們來看分配的基本單元 chunk,chunk 的字面意思是「厚塊; 厚片」,chunk 是 glibc 中記憶體分配的基礎單元,以一個簡單的例子來開頭,
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
void *p;
p = malloc(1024);
printf("%p\n", p);
p = malloc(1024);
printf("%p\n", p);
p = malloc(1024);
printf("%p\n", p);
getchar();
return (EXIT_SUCCESS);
}
這段代碼邏輯是連續呼叫三次 malloc,每次分配 1k 記憶體,然后我們來觀察它的記憶體地址,
./malloc_test
0x602010
0x602420
0x602830
可以看到記憶體地址之間差了 0x410,1024 是等于 0x400,那多出來的 0x10 位元組是什么?我們先按下不表,
再來回看 malloc 和 free,那我們不禁問自己一個問題,free 函式的引數只有一個指標,它是怎么知道要釋放多少記憶體的呢?
#include <stdlib.h>
void *malloc(size_t size);
void free(void *ptr);
香港作家張小嫻說過,「凡事皆有代價,快樂的代價便是痛苦」,為了存盤 1k 的資料,實際上還需要一些資料來記錄這塊記憶體的元資料,這塊額外的資料被稱為 chunk header,長度為 16 位元組,這就是我們前面看到的多出來 0x10 位元組,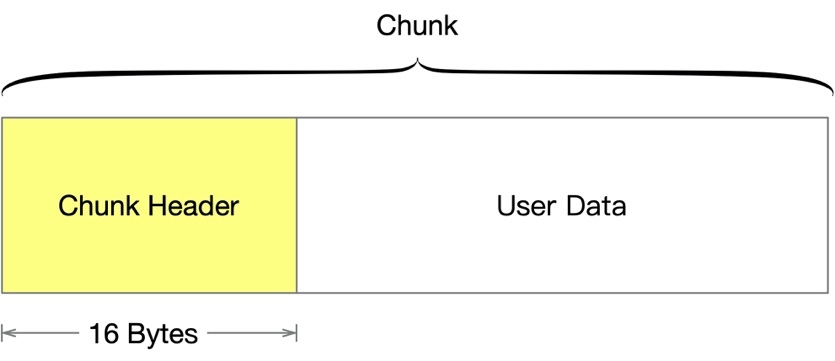
這種通過在實際資料前面添加 head 方式使用的非常普遍,比如 java 中 new Integer(1024),實際存盤的資料大小遠不止 4 位元組,它有一個巨大無比的物件頭,里面存盤了物件的 hashcode,經過了幾次 GC,有沒有被當做鎖同步,
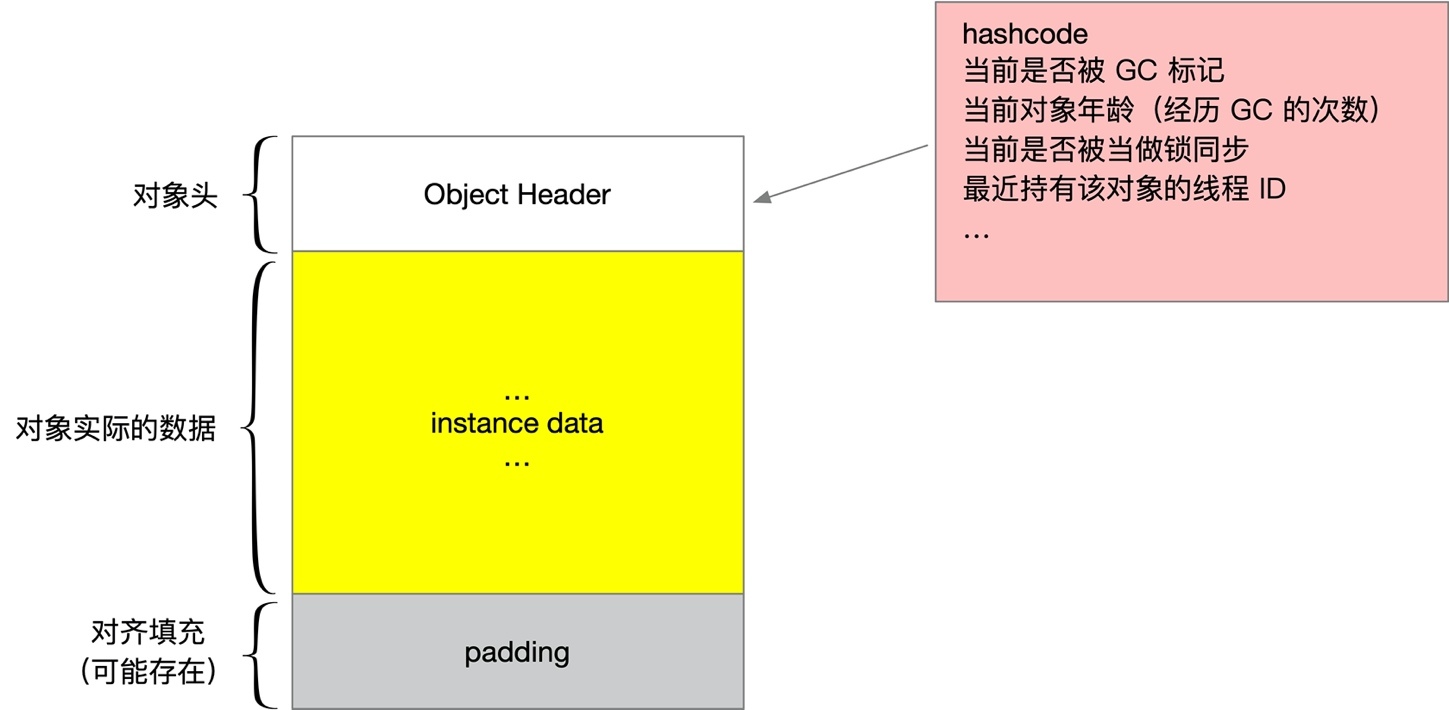
害,說 java 臃腫并不是沒有道理,
在我們繼續來看這個 16 位元組的 header 里面到底存盤了什么,它的結構示意圖如下所示,
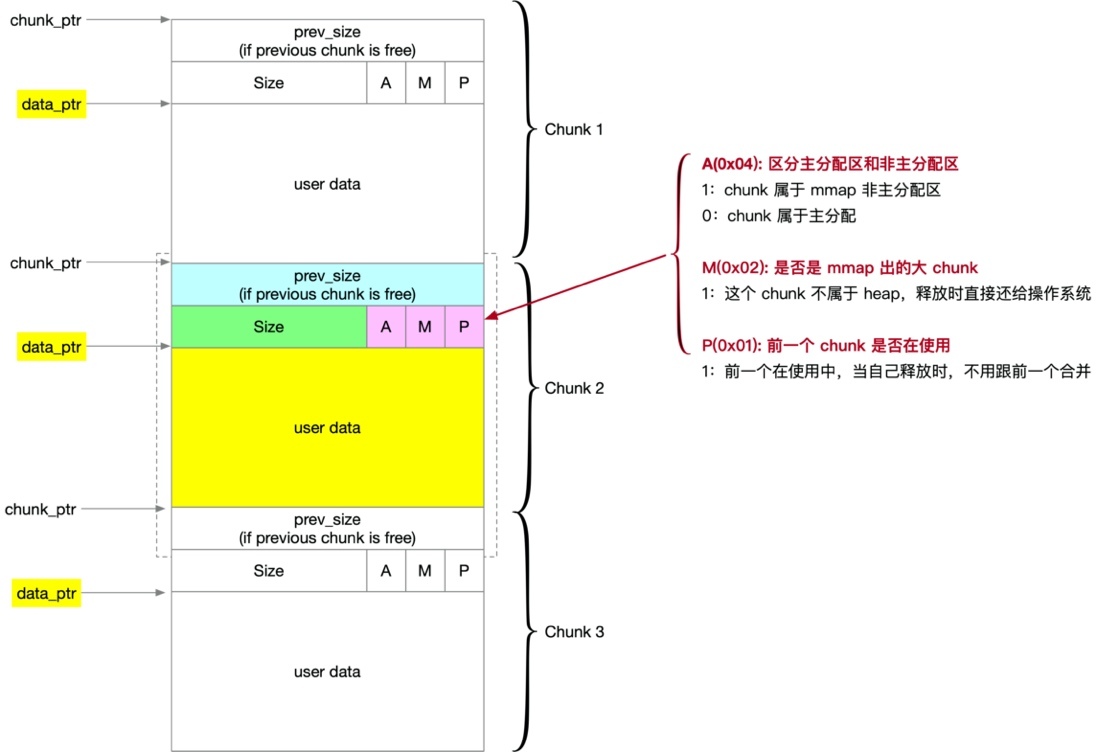
它分為兩部分,前 8 位元組表示前一個 chunk 塊的大小,接下來的 8 位元組表示當前 chunk 塊的大小,因為 chunk 塊要按 16 位元組對齊,所以低 4 位元組都是沒用的,其中三個被用來當做標記位來使用,這三個分別是 AMP,其中 A 表示是否是主分配區,M 表示是否是 mmap 分配的大 chunk 塊,P 表示前一個 chunk 是否在使用中,
以前面的例子為例,我們可以用 gdb 來查看這部分的記憶體,
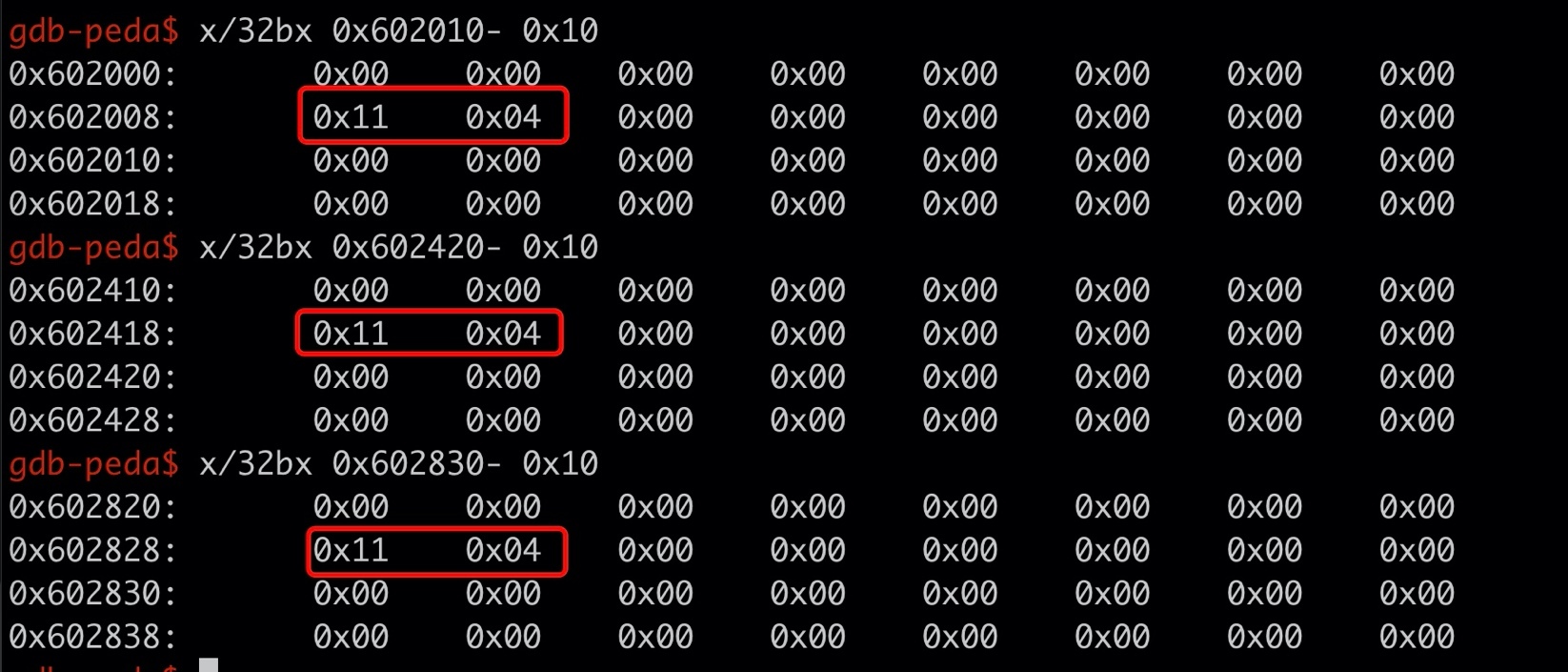
可以看到對應 size 的 8 個位元組是 0x0411,這個值是怎么來的呢?其實是按 size + 8 對齊到 16B 再加上低三位的 B001,
0x0400 + 0x10 + 0x01 = 0x0411
因為當一個 chunk 正在被使用時,它的下一個 chunk 的 prev_size 是沒有意義的,這 8 個位元組可以被這個當前 chunk 使用,別奇怪,就是這么摳,接下來我們來看看 chunk 中 prev_size 的復用,測驗的代碼如下,
#include <stdlib.h>
#include <string.h>
void main() {
char *p1, *p2;
p1 = (char *)malloc(sizeof(char) * 18); // 0x602010
p2 = (char *)malloc(sizeof(char) * 1); // 0x602030
memcpy(p1, "111111111111111111", 18);
}
編譯這個源檔案,然后使用 gdb 除錯單步運行,查看 p1、p2 的地址,
p/x p1
$2 = 0x602010
(gdb) p/x p2
$3 = 0x602030
然后輸出 p1、p2 附近的記憶體區域,
(gdb) x/64bx p1-0x10
0x602000: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602008: 0x21 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602010: 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
0x602018: 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
0x602020: 0x31 0x31 0x00 0x00 0x00 0x00 0x00 0x00
0x602028: 0x21 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602030: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602038: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
布局如下圖所示,
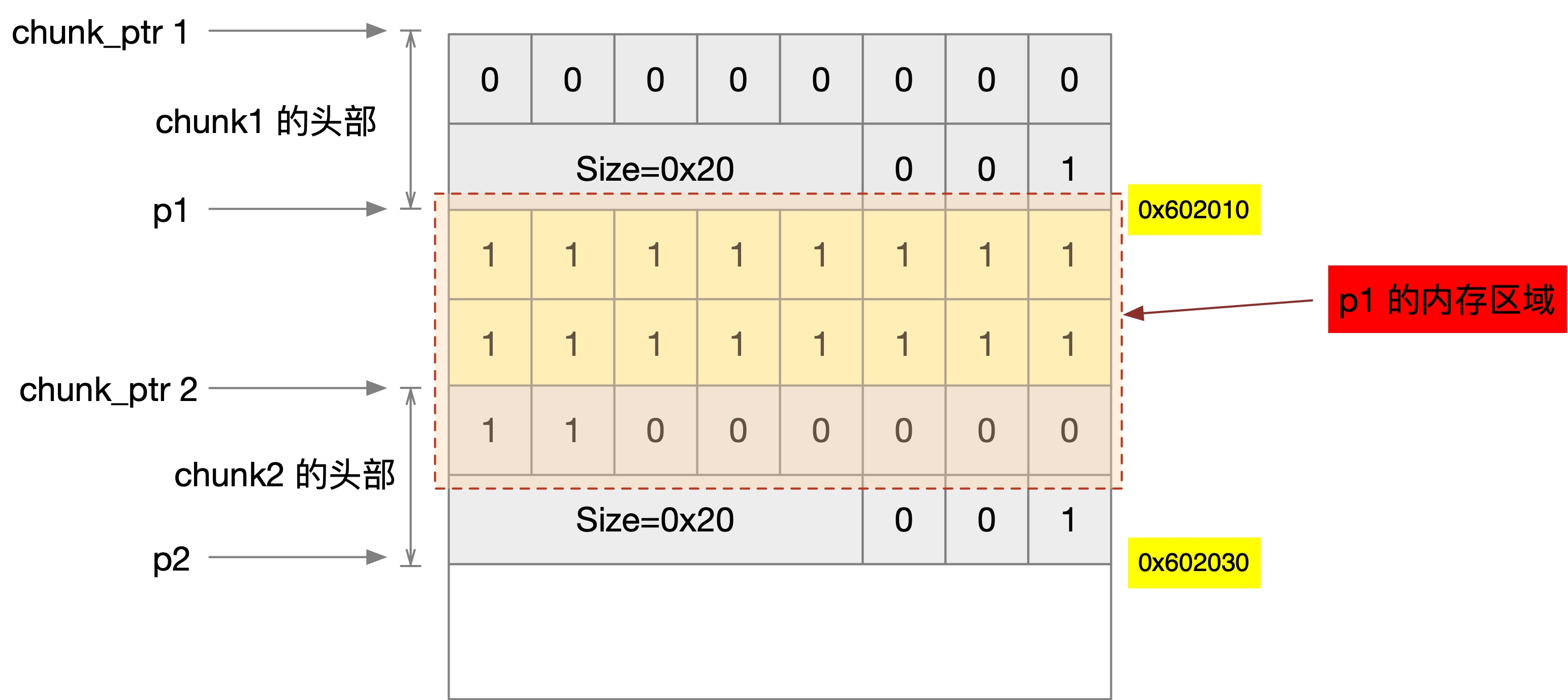
篇幅有限,我這里只展示了 malloc chunk 的結構,還有 Free chunk、Top chunk、Last Remainder chunk 沒有展開,可以參考其它的資料,
Bins
我們接下來看最后一個概念,小塊記憶體的回收站 Bins,
記憶體的回收站分為兩大類,第一類是普通的 bin,一類是 fastbin,
- fastbin 采用單向鏈表,每條鏈表的中空閑 chunk 大小是確定的,插入洗掉都在隊尾進行,
- 普通 bin 根據回收的記憶體大小又分為了 small、large 和 unsorted 三種,采用雙向鏈表存盤,它們之間最大的區別就是它們存盤的 chunk 塊的大小范圍不一樣,
接下來我們看這兩種 bin 的細節,
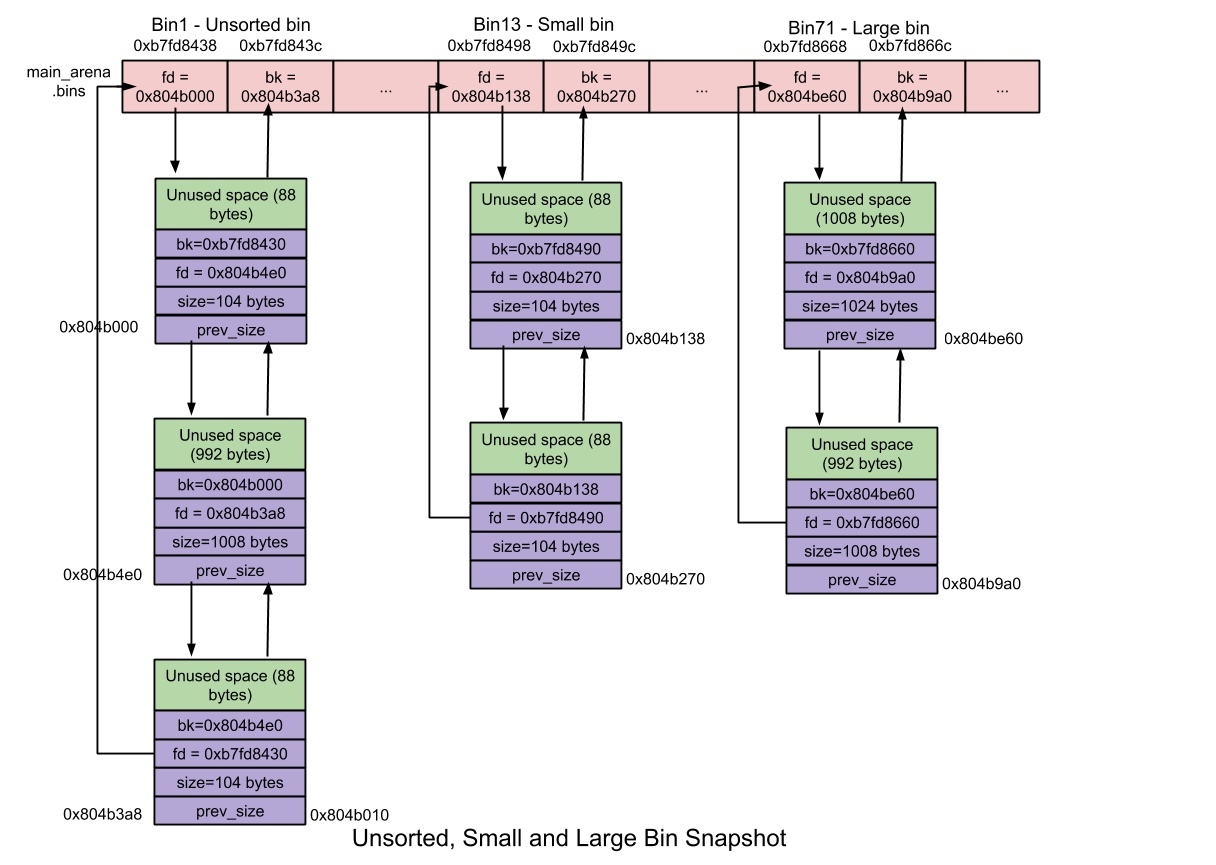
普通 bin 采用雙向鏈表存盤,以陣列形式定義,共 254 個元素,兩個陣列元素組成一個 bin,通過 fd、bk 組成雙向回圈鏈表,結構有點像九連環玩具,
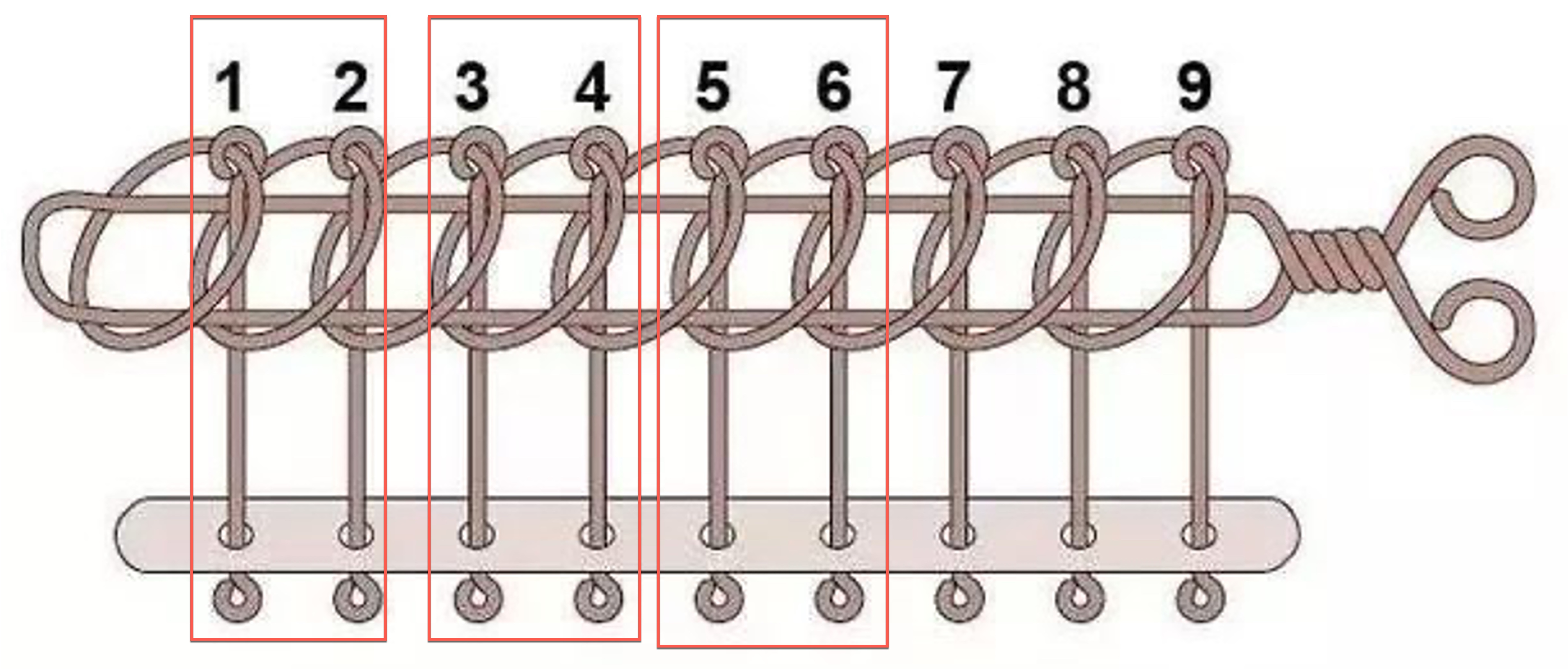
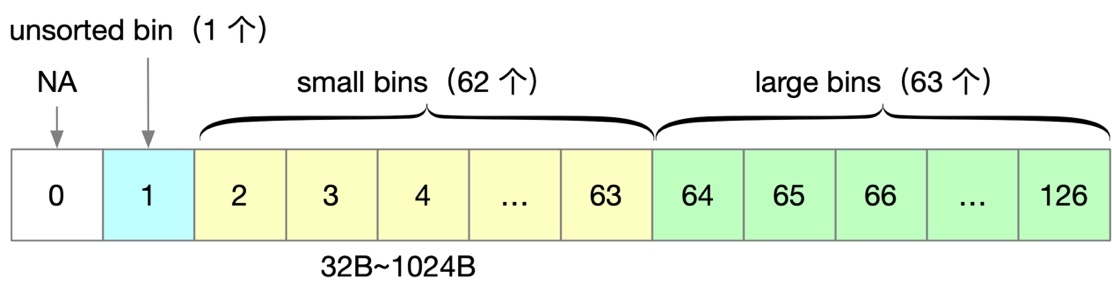
所以普通 bin 的總個數是 254/2 = 127 個,其中 unsorted bin 只有 1 個,small 有 62 個,large bin 有 63 個,還有一個暫未使用,如下圖所示,
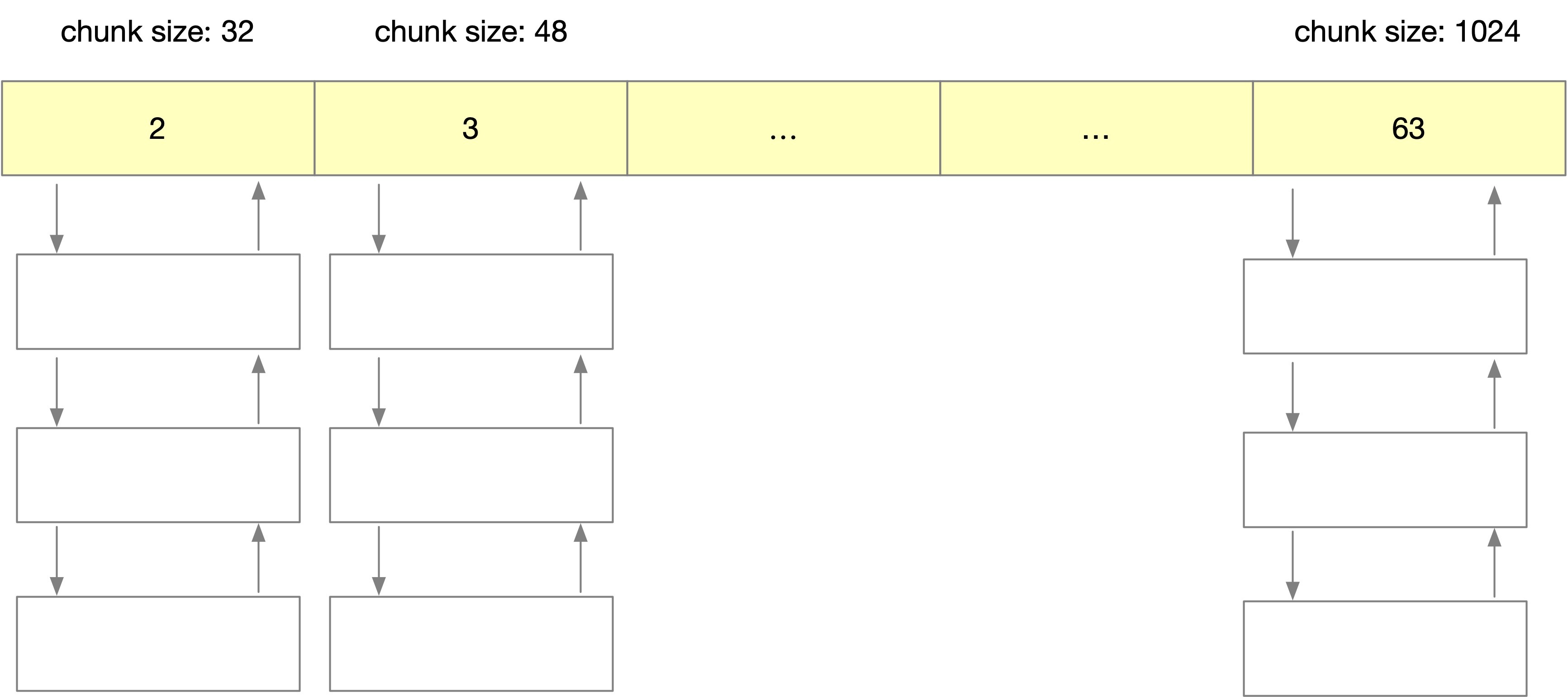
smallbin
其中 smallbin 用于維護 <= 1024B 的 chunk 記憶體塊,同一條 small bin 鏈中的 chunk 具有相同的大小,都為 index * 16,結構如下圖所示,
largebin
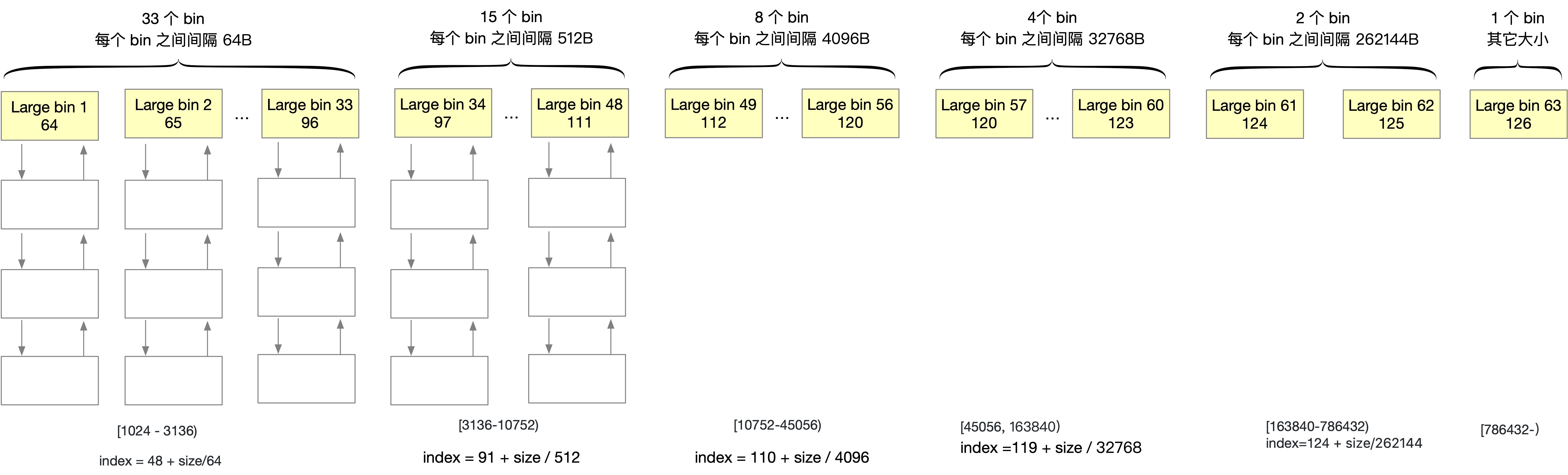
largebin 中同一條鏈中的 chunk 具有「不同」的大小
- 分為 6 組
- 每組的 bin 數量依次為 33、15、8、4、2、1,每條鏈表中的最大 chunk 大小公差依次為 64B、 512B、4096B、32768B、262144B 等
結構如下圖所示,
unsorted bin
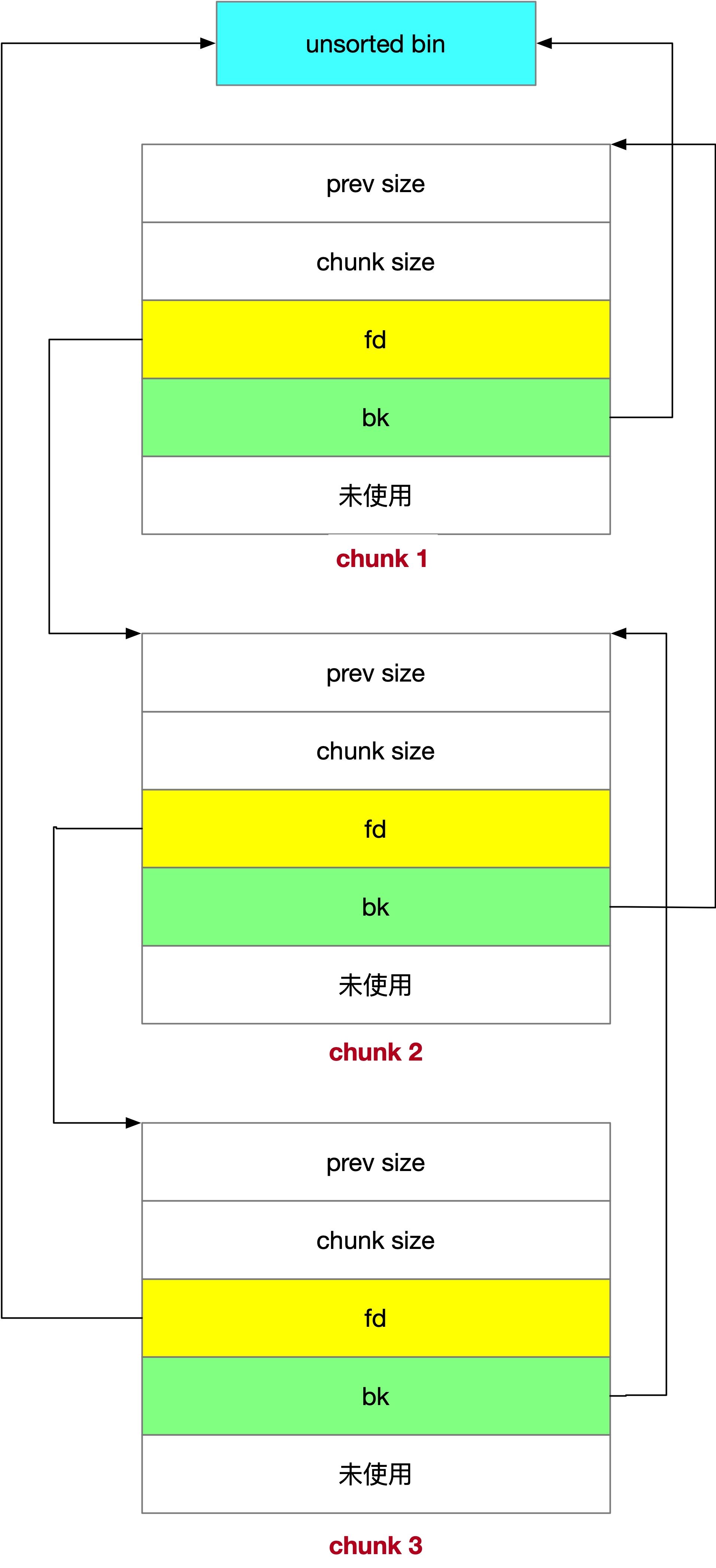
unsorted bin 只有一條雙向鏈表,它的特點如下,
- 空閑 chunk 不排序
- 大于 128B 的記憶體 chunk 回收時先放到 unsorted bin
它的結構如下圖所示,
下面是所有普通 bin 的概覽圖,
FastBin
說完了普通 bin,我們來詳細看看 FastBin,FastBin 專門用來提高小記憶體的分配效率,它的結構如下,
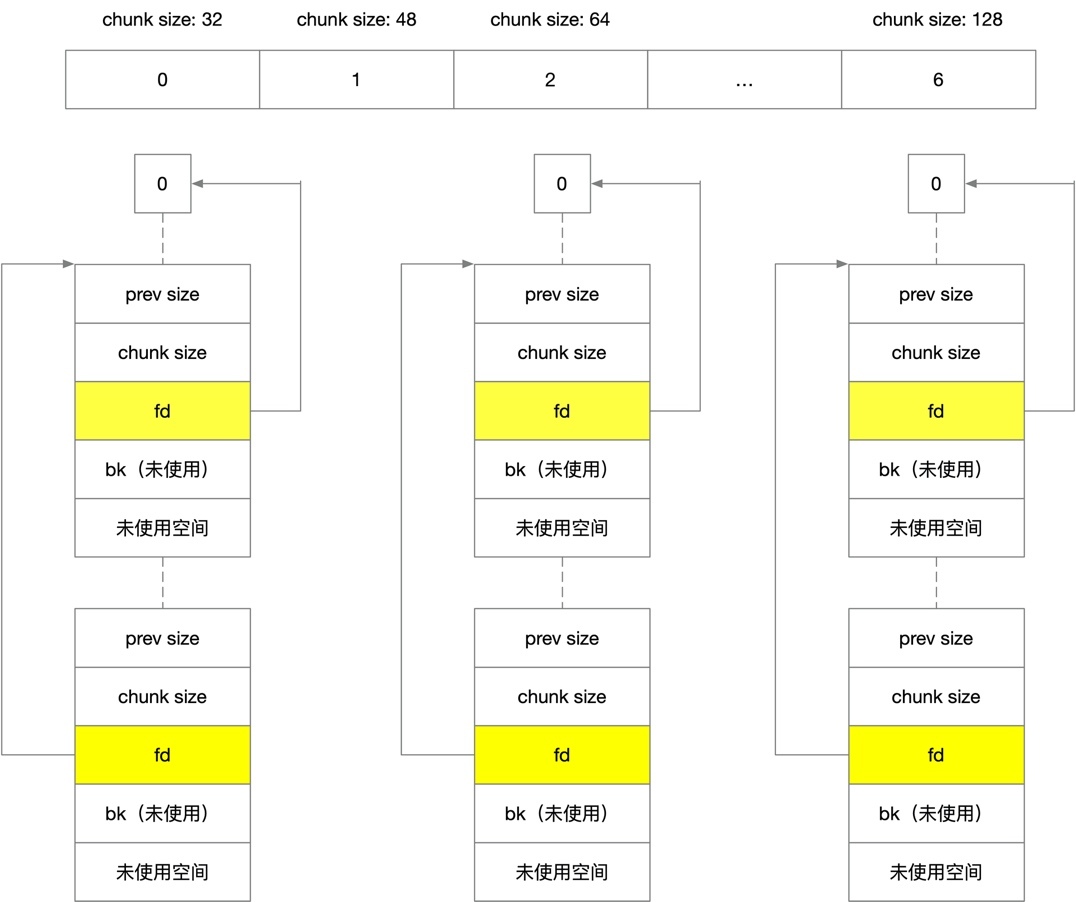
它有下面這些特性,
- 小于 128B 的記憶體分配會先在 Fast Bin 中查找
- 單向鏈表,每條鏈表中的 chunk 大小相同,有 7 個 chunk 空閑鏈表,每個 bin 的 chunk 大小依次為 32B,48B,64B,80B,96B,112B,128B
- 因為是單向鏈表,fastbin 中的 bk 指標沒有用到,第一個 chunk 的 fd 指標指向特殊的 0 地址
- P 標記始終為 1,一般情況下不合并
- FIFO,添加和洗掉都從隊尾進行
Fast bins 可以看著是 small bins 的一小部分 cache,
記憶體的申請與釋放
有了前面的知識,我們就可以來回答分享一開頭的問題,記憶體從哪里來,大塊記憶體申請沒有特別多可以講的,直接 mmap 系統呼叫申請一塊,釋放的時候也直接還給作業系統,
小塊記憶體的申請就復雜很多了,原則就是先在 chunk 回收站中找,找到了是最好,就直接回傳了,不用再去向內核申請,它是怎么做的呢?
首先會根據傳入的大小計算真正 chunk 的大小,根據這個大小看看在不在 fastbin 的區間里,如果有的話,從 fastbin 直接回傳,如果不在則嘗試 smallbin,然后如果 smallbin 里沒有則會觸發一次合并,然后從 unsorted bin 里查找,還沒有則會從 Large Bin 查找,如果沒有再去切割 top 塊,top 塊也沒有了,則會重新申請 heap 或者調整 heap 的大小,如下圖所示,
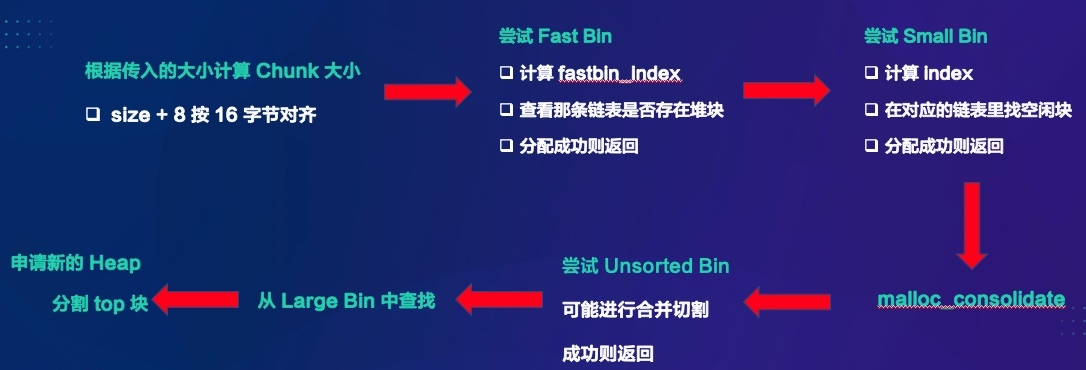
接下來我們來回答最后一個問題,記憶體 free 以后去了哪里,根據不同的大小,有不同的處理策略,
- 符合 fastbin 的超小塊記憶體直接放入 fastbin 單鏈表,快速釋放,畫外音就是這么點空間,值得我處理半天嗎?
- 超大塊記憶體,直接還給內核不進入 bin 的管理邏輯,畫外音就是大客戶要特殊處理,畢竟大客戶是少數情況,
- 大部分是介于中間的,釋放的時候首先會被放入 unsorted bin,根據情況合并、遷移空閑塊,靠近 top 則更新 top chunk,這才是人生常態啊,
堆疊記憶體
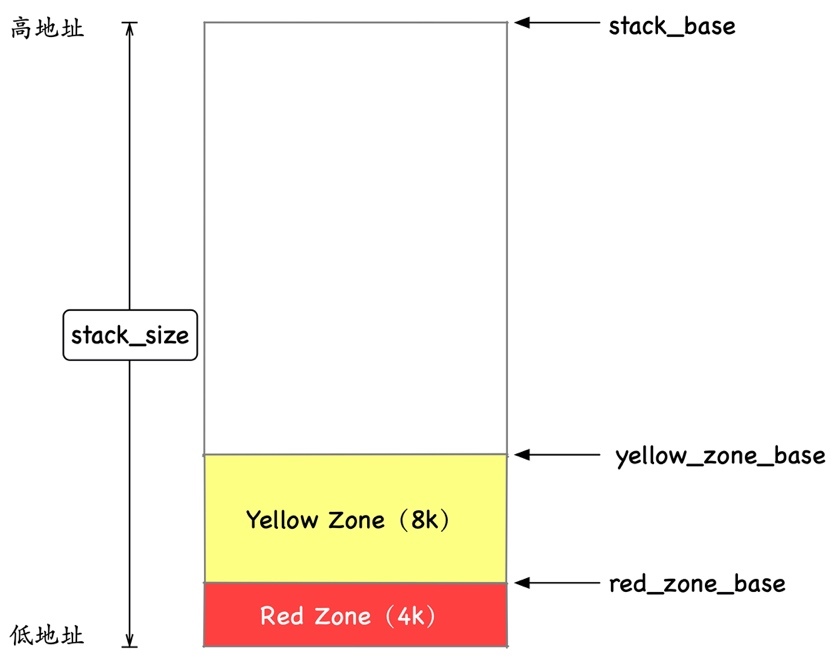
前面我們介紹的大部分都是堆記憶體,其實還有一個非常重要的東西是堆疊記憶體,LInux 中默認的堆疊記憶體大小是 8M,然后外加 4K 的保護區,這 4k 的保護區不可讀不可寫不可執行,當真有堆疊越界時可以更早的發現,盡快 fast fail,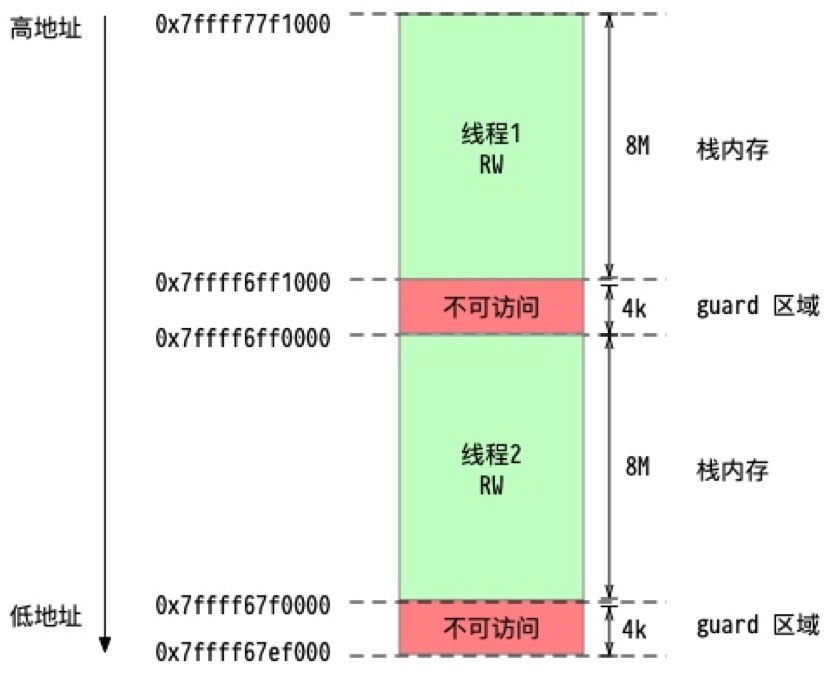
這個圖就是一個典型的 linux 原生執行緒的堆疊記憶體布局,可以看到 8M 的堆疊空間和 4k 的 guard 區域的情況,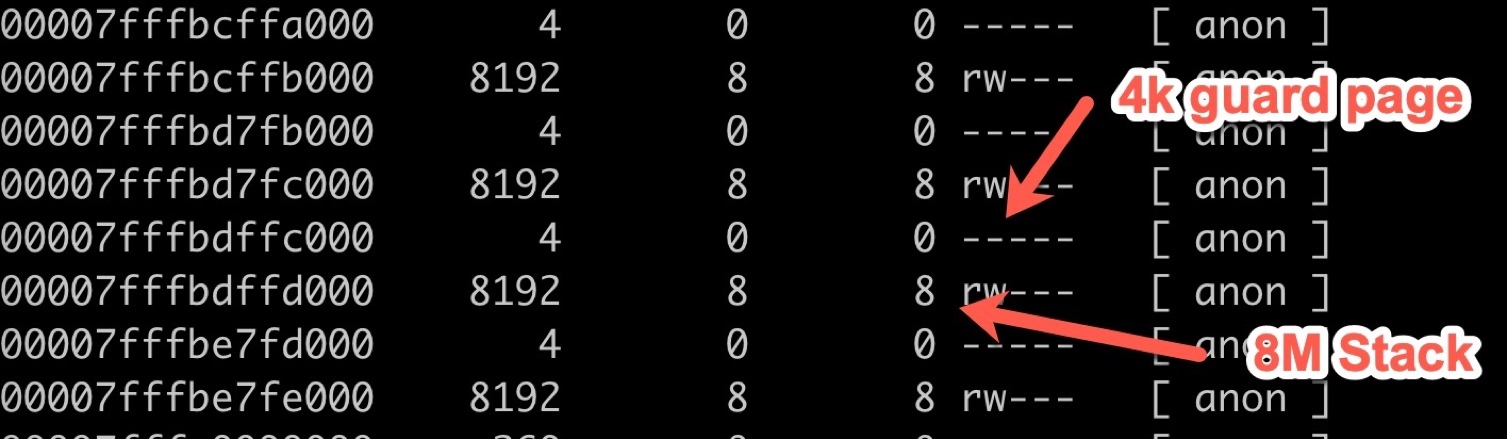
對于 Java 來說,它做了一些細微的調整,默認的堆疊大小空間為 1M,然后有 4k 的 RED 區域和 8K 的 yellow 區域,以便做更細粒度的堆疊溢位控制,這里的 yellow 區域和 red 區域到底有什么作用,之前我有寫一篇文章執行緒與堆疊的文章專門介紹,這里就不展開了,
第三部分:開發相關的記憶體問題說明
接下來進入我們的最后一個部分,開發相關的記憶體問題,
Xmx 與記憶體消耗
首先要說的是一個問的比較多的問題,為什么我 Java 應用的記憶體消耗遠大于 Xmx,這也是 Stack Overflow 上問的非常多的一個問題,

其實我們要搞清楚,一個行程除了堆消耗記憶體,還有大量的其他的開銷,如下所示,
- Heap
- Code Cache
- GC 開銷
- Metaspace
- Thread Stack
- Direct Buffers
- Mapped files
- C/C++ Native 記憶體消耗
- malloc 本身的開銷
- ,,,
記憶體大戶不是開玩笑的,根據多年實踐 Xmx 設定為容器記憶體的 65% 左右比較合理
RES 占用
第二個問題是 top 命令中 RES 占用很高,是不是代表程式真正有大量消耗呢?
其實不是的,我們以一個最簡單的 java 程式為例,在使用 -Xms1G -Xmx1G 來運行程式時,
java -Xms1G -Xmx1G MyTest
它的記憶體占用如下,
我們把啟動命令稍作改動,加上 AlwaysPreTouch,如下所示,
java -XX:+AlwaysPreTouch -Xms1G -Xmx1G MyTest
這個時候 RES 占用如下所示,

這里的 1G 業務程式其實沒有使用,只是 JVM 把記憶體做了寫入,以便后面真正使用時,不用發起缺頁中斷去真正申請物理記憶體,
記憶體占用不是越少越好,還要兼顧 GC 次數、GC 停頓時間,
替換默認的記憶體分配器
默認的 Linux 記憶體分配器在性能和記憶體碎片方面表現不是很好,可以嘗試替換默認的記憶體分配器為 jemalloc 或者 tcmalloc,只用新增一個 LD_PRELOAD 環境變數即可,
LD_PRELOAD=/usr/local/lib/libjemalloc.so
在實際的服務中,有一個服務記憶體占用從 7G 變為了 3G,效果還是非常明顯的,
native 記憶體分析
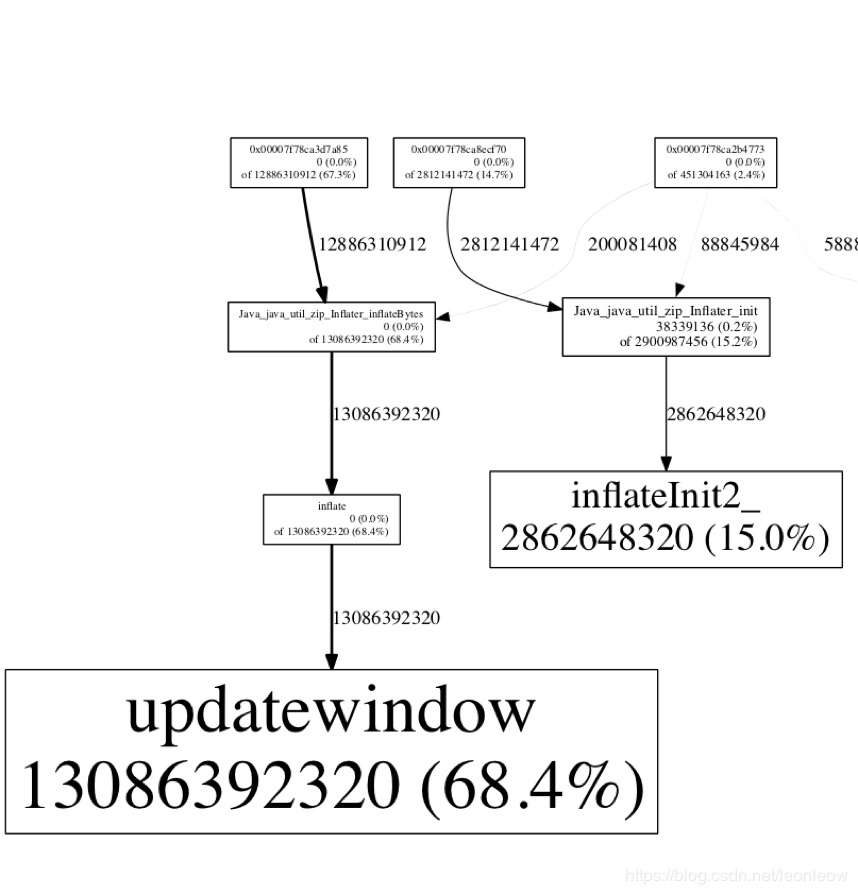
Java 的堆記憶體分析非常容易,jmap 命令 dump 出記憶體,然后使用 jprofile、mat、perfma 等平臺都可以很快的進行分析了,然而對于 native 的記憶體占用過大,還是比較麻煩的,這里可以使用 jemalloc 和 tcmalloc 強大的 profile 功能,以 jemalloc 為例,可以將記憶體的申請關系生成 svg,
export MALLOC_CONF=prof:true,lg_prof_sample:1,lg_prof_interval:30,prof_prefix:jeprof.out
jeprof –svg /path/to/svg jeprof.out.* > out.svg
生成的 svg 示意圖如下所示,
小結
這次介紹的只是記憶體問題的冰山一角,很多細節的東西沒能在這次分享里詳細展開,有問題可以來交流,
講完這個 PPT,有人跟我說,場子有點冷,這個結局還不錯,我以為中間要走一半,
看完三件事??
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力,
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識,
-
同時可以期待后續文章ing??

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236346.html
標籤:Java
上一篇:性能優化:執行緒資源回收