本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來源于資料雜論,作者:Wpc7113

Python 資料分析入門案例講解
https://www.bilibili.com/video/BV18f4y1i7q9/
1.標準化:去均值,方差規模化
Standardization標準化:將特征資料的分布調整成標準正態分布,也叫高斯分布,也就是使得資料的均值為0,方差為1.
標準化的原因在于如果有些特征的方差過大,則會主導目標函式從而使引數估計器無法正確地去學習其他特征,
標準化的程序為兩步:去均值的中心化(均值變為0);方差的規模化(方差變為1),
from sklearn import preprocessing from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target '''標準變換''' scaler = preprocessing.StandardScaler().fit(X) x_scaler=scaler.transform(X)
2. 最小-最大規范化
最小-最大規范化對原始資料進行線性變換,變換到[0,1]區間(也可以是其他固定最小最大值的區間)
min_max_scaler = preprocessing.MinMaxScaler()
x_train_minmax = min_max_scaler.fit_transform(X)
3.MaxAbsScaler
max_abs_scaler = preprocessing.MaxAbsScaler()
x_train_maxabs = max_abs_scaler.fit_transform(X)
4.RobustScaler:帶有outlier的資料的標準化
transformer = preprocessing.RobustScaler().fit(X)
x_robust_scaler=transformer.transform(X)
5.QuantileTransformer 分位數變換
quantile_transformer = preprocessing.QuantileTransformer(random_state=0)
X_train_trans = quantile_transformer.fit_transform(X)
6.Box-Cox
Box-Cox變換是Box和Cox在1964年提出的一種廣義冪變換方法,是統計建模中常用的一種資料變換,用于連續的回應變數不滿足正態分布的情況,Box-Cox變換之后,可以一定程度上減小不可觀測的誤差和預測變數的相關性,Box-Cox變換的主要特點是引入一個引數,通過資料本身估計該引數進而確定應采取的資料變換形式,Box-Cox變換可以明顯地改善資料的正態性、對稱性和方差相等性,對許多實際資料都是行之有效,變化方式如下:
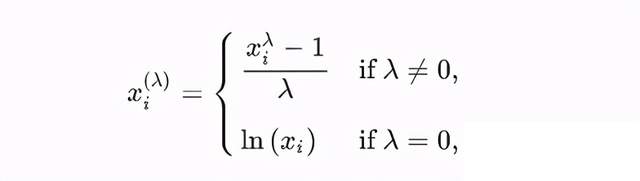
pt = preprocessing.PowerTransformer(method='box-cox', standardize=False) pt.fit_transform(X)
7.規范化(Normalization)
規范化是將不同變化范圍的值映射到相同的固定范圍,常見的是[0,1],此時也稱為歸一化,
X_normalized = preprocessing.normalize(X, norm='l2')
8.獨熱編碼
enc = preprocessing.OneHotEncoder(categories='auto') enc.fit(y.reshape(-1,1)) y_one_hot=enc.transform(y.reshape(-1,1)) y_one_hot.toarray()
9.Binarizer二值化
binarizer = preprocessing.Binarizer(threshold=1.1)
binarizer.fit(X)
binarizer.transform(X)
10.多項式變換
poly =preprocessing.PolynomialFeatures(2)
poly.fit_transform(X)
11.自定義變換
transformer = preprocessing.FunctionTransformer(np.log1p, validate=True)
transformer.fit(X)
log1p_x=transformer.transform(X)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236929.html
標籤:Python