本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,著作權歸原作者所有,如有問題請及時聯系我們以作處理
本文來自騰訊云,作者:Python小二
《南方車站的聚會》由刁亦男執導,主要演員包括:胡歌、桂綸鎂、廖凡、萬茜等,該片于 2019 年 5 月 18 在戛納電影節首映,2019 年 12 月 6 日在中國正式上映,故事靈感來自真實新聞事件,主要講述盜竊團伙頭目周澤農(胡歌飾),在重金懸賞下走上逃亡之路,艱難尋求自我救贖的故事,
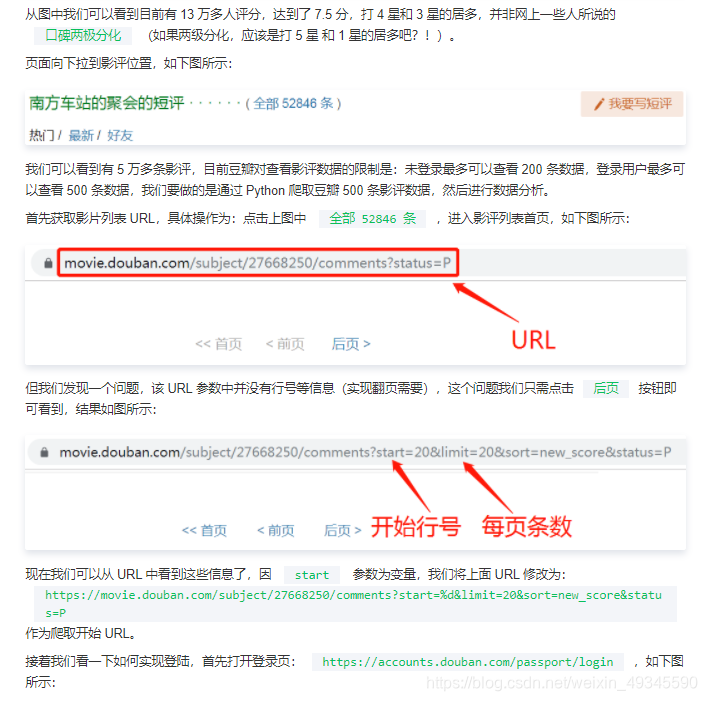
影片上映了一周多,票房接近 2 億,作為一部文藝片,這個表現應該算是屬于中上水平了,下面打開豆瓣:https://movie.douban.com/subject/27668250/,看一下評分情況,如下圖所示:

我們先在手機號/郵箱和密碼輸入框處隨意輸入(不要輸入正確的用戶名和密碼),再按 F12 鍵打開開發者工具,最后點擊登錄豆瓣按鈕,結果如圖所示:
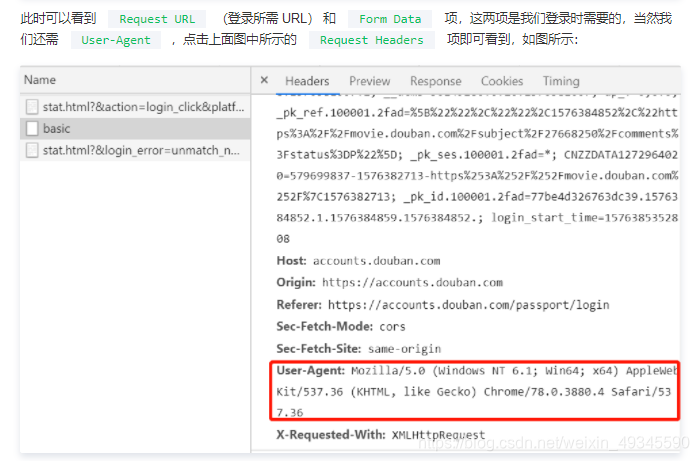
我們點擊上面圖中所示 basic 項,點擊后結果如圖所示: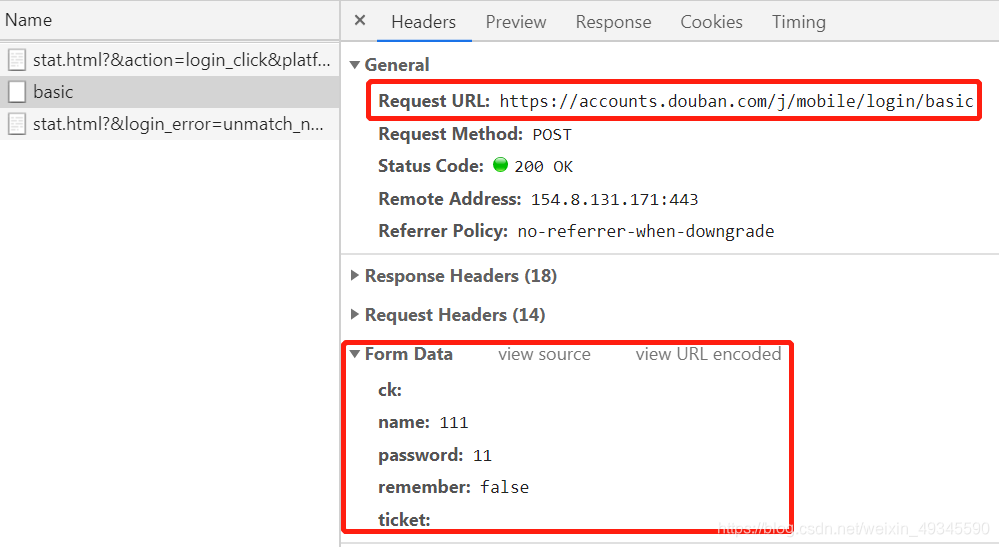
所需要的東西都找好了,接下來就是具體實作了,豆瓣登錄和影評資料爬取的具體實作如下所示:
import requests import time import random from lxml import etree import csv # 新建 csv 檔案 csvfile = open('南方車站的聚會.csv','w',encoding='utf-8',newline='') writer = csv.writer(csvfile) # 表頭 writer.writerow(['時間','星級','評論內容']) def spider(): url = 'https://accounts.douban.com/j/mobile/login/basic' headers = {"User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'} comment_url = 'https://movie.douban.com/subject/27668250/comments?start=%d&limit=20&sort=new_score&status=P' data = { 'ck': '', 'name': '自己的用戶名', 'password': '自己的密碼', 'remember': 'false', 'ticket': '' } session = requests.session() session.post(url=url, headers=headers, data=https://www.cnblogs.com/aa1273935919/p/data) # 總共 500 條,每頁 20 條 for i in range(0, 500, 20): # 獲取 HTML data = https://www.cnblogs.com/aa1273935919/p/session.get(comment_url % i, headers=headers) print('第', i, '頁', '狀態碼:', data.status_code) # 暫停 0-1 秒 time.sleep(random.random()) # 決議 HTML selector = etree.HTML(data.text) # 獲取當前頁所有評論 comments = selector.xpath('//div[@]') # 遍歷所有評論 for comment in comments: # 獲取星級 star = comment.xpath('.//h3/span[2]/span[2]/@class')[0][7] # 獲取時間 t = comment.xpath('.//h3/span[2]/span[3]/text()') # 獲取評論內容 content = comment.xpath('.//p/span/text()')[0].strip() # 排除時間為空的項 if len(t) != 0: t = t[0].strip() writer.writerow([t, star, content])
接下來我們通過詞云直觀的來展示下整體評論情況,具體實作如下所示:
import csv import jieba from wordcloud import WordCloud import numpy as np from PIL import Image # jieba 分詞處理 def jieba_(): csv_list = csv.reader(open('南方車站的聚會.csv', 'r', encoding='utf-8')) print('csv_list',csv_list) comments = '' for i,line in enumerate(csv_list): if i != 0: comment = line[2] comments += comment print("comment-->",comments) # jieba 分詞 words = jieba.cut(comments) new_words = [] # 要排除的詞 remove_words = ['以及', '在于', '一些', '一場', '只有', '不過', '東西', '場景', '所有', '這么', '但是', '全片', '之前', '一部', '一個', '作為', '雖然', '一切', '怎么', '表現', '人物', '沒有', '不是', '一種', '個人' '如果', '之后', '出來', '開始', '就是', '電影', '還是', '不是', '武漢', '鏡頭'] for word in words: if word not in remove_words: new_words.append(word) global word_cloud # 用逗號分隔詞語 word_cloud = ','.join(new_words) # 生成詞云 def world_cloud(): # 背景圖 cloud_mask = np.array(Image.open('bg.jpg')) wc = WordCloud( # 背景圖分割顏色 background_color='white', # 背景圖樣 mask=cloud_mask, # 顯示最大詞數 max_words=600, # 顯示中文 font_path='./fonts/simhei.ttf', # 字的尺寸限制 min_font_size=20, max_font_size=100, margin=5 ) global word_cloud x = wc.generate(word_cloud) # 生成詞云圖片 image = x.to_image() # 展示詞云圖片 image.show() # 保存詞云圖片 wc.to_file('wc.png')
整體評論詞云圖

因為有人說了影片口碑兩級分化,接下來我們看一下打 1 星和 5 星的詞云效果如何,主要實作如下所示:
for i,line in enumerate(csv_list): if i != 0: star = line[1] comment = line[2] # 一星評論用 1,五星評論用 5 if star == '1': comments += comment
一星評論詞云圖

五星評論詞云圖
上面我們只使用了評論內容資訊,還有時間和星級資訊沒有使用,最后我們可以用這兩項資料分析下隨著時間的變化影片星級的波動情況,以月為單位統計影片從首映(2019 年 5 月)到當前時間(2019 年 12月)的星級波動情況,具體實作如下所示:
import csv from pyecharts.charts import Line import pyecharts.options as opts import numpy as np from datetime import datetime def score(): csv_list = csv.reader(open('南方車站的聚會.csv', 'r', encoding='utf-8')) print('csv_list', csv_list) comments = '' ts = [] ss = set() for i, line in enumerate(csv_list): if i != 0: t = line[0][0:7] s = line[1] ts.append(t+':'+s) ss.add(t) new_times = [] new_starts = [] new_ss = [] for i in ss: new_ss.append(i) arr = np.array(new_ss) new_ss = arr[np.argsort([datetime.strptime(i, '%Y-%m') for i in np.array(new_ss)])].tolist() print('new_ss',new_ss) for i in new_ss: x = 0 y = 0 z = 0 for j in ts: t = j.split(':')[0] s = int(j.split(':')[1]) if i == t: x += s z += 1 new_times.append(i) new_starts.append(round(x / z, 1)) c = ( Line() .add_xaxis(new_times) .add_yaxis('南方車站的聚會',new_starts) .set_global_opts(title_opts=opts.TitleOpts(title='豆瓣星級波動圖')) ).render()
影片星級波動效果如下圖所示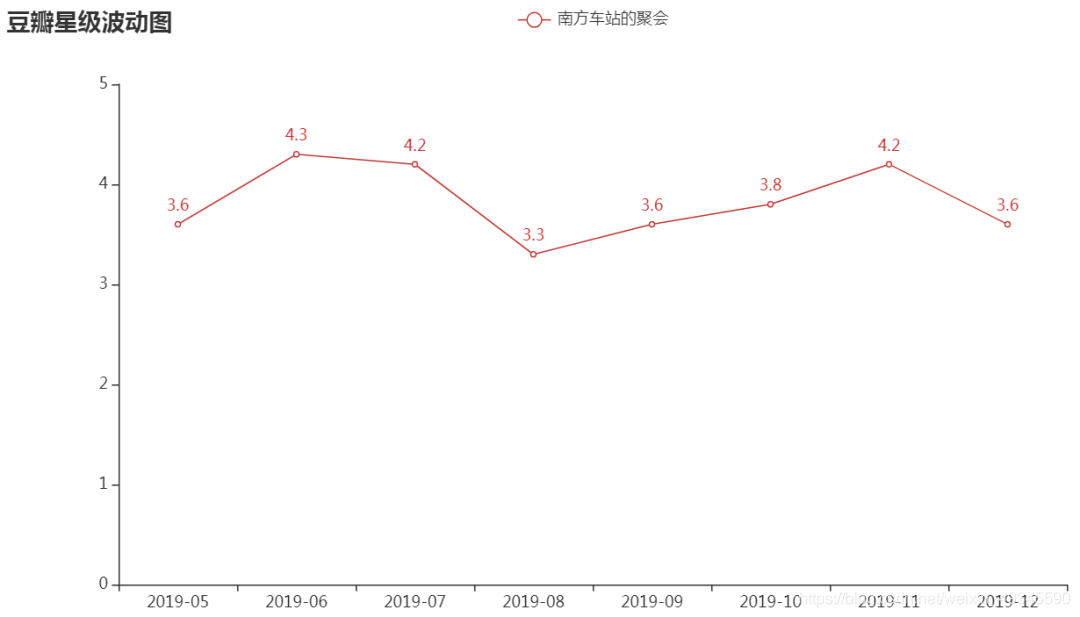
根據影片星級的波動情況我們也能大致預測到影片評分的波動情況,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236932.html
標籤:Python