本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,著作權歸原作者所有,如有問題請及時聯系我們以作處理
本文來自騰訊云,作者:Python小二
前幾天 B 站上線了一個小視頻《后浪》,在全網引起了熱烈反響,有贊揚也有批評,視頻地址:https://www.bilibili.com/video/BV1FV411d7u7,本文我們爬一下視頻彈幕來了解一下 B 站網友對視頻的看法,
視頻彈幕是存在 xml
檔案中的,鏈接的格式為:http://comment.bilibili.com/+cid+.xml,我們只需要拿到視頻的 cid
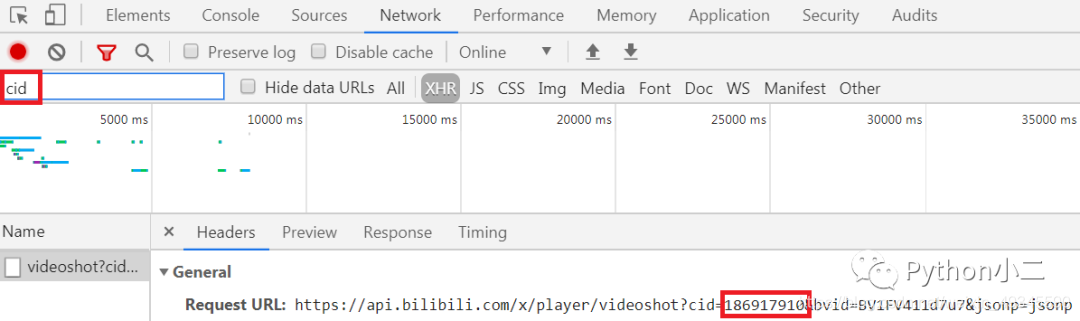
即可,看一下獲取方式,我們先打開視頻鏈接 https://www.bilibili.com/video/BV1FV411d7u7,接著按
F12 鍵打開開發者工具選擇 Network,再重繪一下頁面,我們到 Filter 中輸入 cid 即可,如下所示:
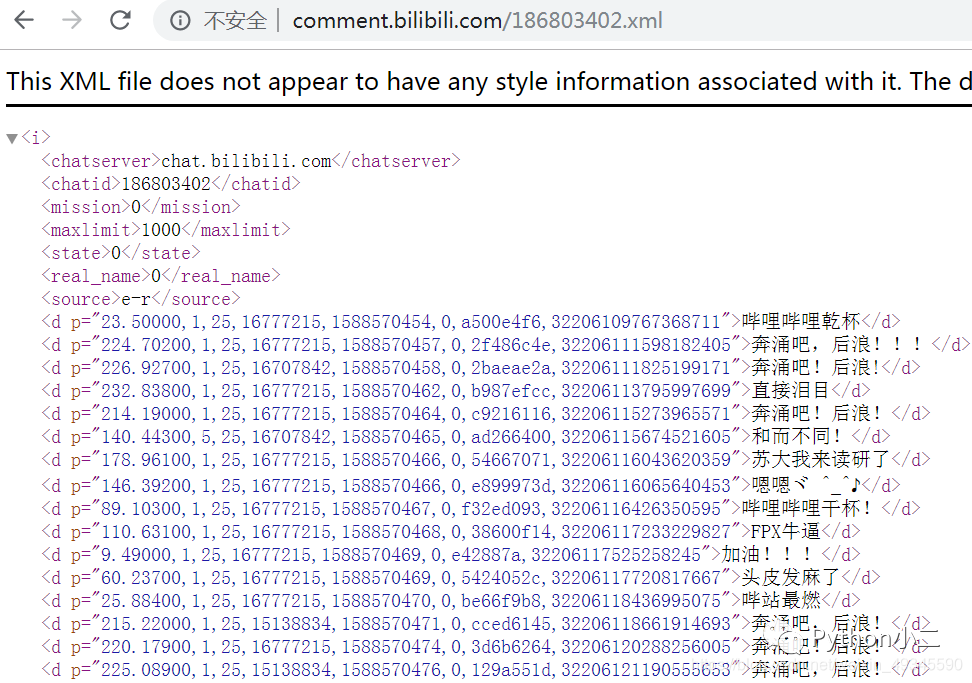
拿到了 cid,我們可以知道彈幕檔案鏈接為:http://comment.bilibili.com/186803402.xml,打開鏈接看一下:
彈幕爬取的實作代碼如下所示:
url = "http://comment.bilibili.com/186803402.xml" req = requests.get(url) html = req.content html_doc = str(html, "utf-8") # 修改成utf-8 # 決議 soup = BeautifulSoup(html_doc, "lxml") results = soup.find_all('d') contents = [x.text for x in results] # 保存結果 dic = {"contents": contents} df = pd.DataFrame(dic) df["contents"].to_csv("bili.csv", encoding="utf-8", index=False)
現在我們已經獲取了彈幕資料,接下來再對資料做個詞云展示,實作代碼如下所示:
def jieba_(): # 打開評論資料檔案 content = open("bili.csv", "rb").read() # jieba 分詞 word_list = jieba.cut(content) words = [] # 過濾掉的詞 stopwords = open("stopwords.txt", "r", encoding="utf-8").read().split("\n")[:-1] for word in word_list: if word not in stopwords: words.append(word) global word_cloud # 用逗號隔開詞語 word_cloud = ','.join(words) def cloud(): # 打開詞云背景圖 cloud_mask = np.array(Image.open("bg.png")) # 定義詞云的一些屬性 wc = WordCloud( # 背景圖分割顏色為白色 background_color='white', # 背景圖樣 mask=cloud_mask, # 顯示最大詞數 max_words=500, # 顯示中文 font_path='./fonts/simhei.ttf', # 最大尺寸 max_font_size=60, repeat=True ) global word_cloud # 詞云函式 x = wc.generate(word_cloud) # 生成詞云圖片 image = x.to_image() # 展示詞云圖片 image.show() # 保存詞云圖片 wc.to_file('cloud.png')
看一下效果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236934.html
標籤:Python
上一篇:Python 分析電影《南方車站的聚會》,看看這部電影到底在講些什么?
下一篇:Python通用函式實作陣列計算