總共是下面幾個檔案:
注意,最后一個是json檔案,里面是電影影評資料集MR的劃分出來的訓練集生成的詞典,是個字典檔案,也可以自己再弄一個,
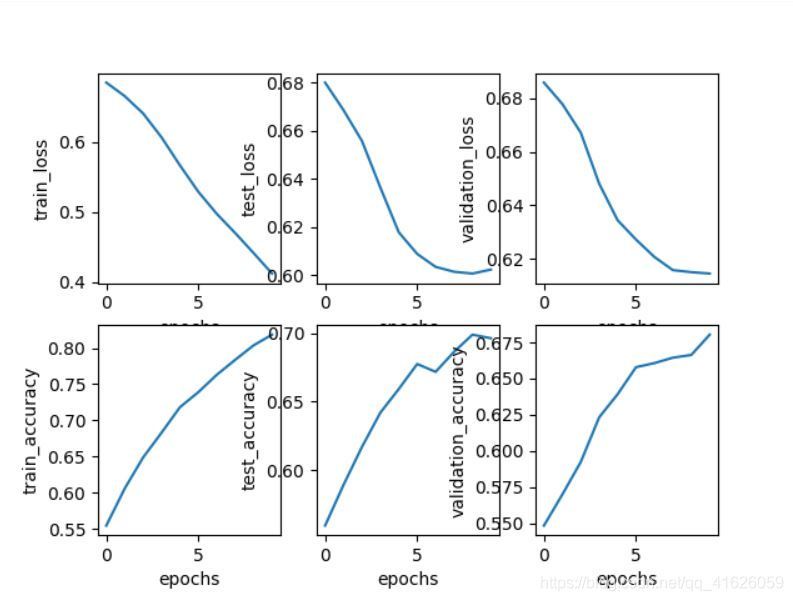
在訓練集上訓練了10個epoch,結果大概是上圖這個樣子
1、創建model_para.py檔案,里面是模型的超引數,
import argparse
class Hpara():
parser = argparse.ArgumentParser()
############# insert paras #############
parser.add_argument('--batch_size',default = 16, type = int) # batch_size
parser.add_argument('--epochs',default = 1, type = int) # epochs
parser.add_argument('--lr',default = 3*10**(-5), type = float) # learning rate
parser.add_argument('--l2_lambda',default = 0.0, type = float) # L2_loss lambda
parser.add_argument('--seg_net_nums_layer',default = 6, type = int) # segnet Rnn Layers
parser.add_argument('--seg_net_dropout_rate',default = 0.2, type = float) # segnet dropout rate
parser.add_argument('--seg_net_hidden_size',default = 64, type = int) # segnet hidden size
parser.add_argument('--seg_net_n_best',default = 12, type = int) # sample nums
parser.add_argument('--seg_net_beam_size',default = 8, type = int) # beam size
parser.add_argument('--seg_net_rnntype',default = 'GRU', type = str) # segnet Rnn Type
parser.add_argument('--is_bi_rnn',default = True, type = bool) # segnet bi_Rnn
parser.add_argument('--unfreezing_bert_nums',default = 12, type = int)
parser.add_argument('--is_training_bert',default = True, type = bool)
parser.add_argument('--is_load_best_model', default = False ,type = bool)
## MLP model paras
parser.add_argument('--MLP_hidden_nums_layer',default = 1, type = int)
parser.add_argument('--Bert_drop_out',default = 0.1, type = float)
## SA model paras
parser.add_argument('--SA_hidden_dim',default = 256, type = int)
parser.add_argument('--SA_is_bi',default = True, type = bool)
parser.add_argument('--SA_dropout_rate',default = 0.4, type = float)
parser.add_argument('--SA_word_dim',default = 300, type = int)
parser.add_argument('--SA_vocab_size',default = 16783, type = int)
parser.add_argument('--SA_layer_nums',default = 2, type = int)
parser.add_argument('--SA_Rnn_type',default = 'LSTM', type = str)
parser.add_argument('--pretrained_bert_path',default = '/bert-base-uncased', type = str)
parser.add_argument('--bert_out_size',default = 768, type = int)
parser.add_argument('--bert_vocab_path',default = /bert-base-uncased/vocab.txt', type = str)
parser.add_argument('--saved_model_path',default = './best_model', type = str)
parser.add_argument('--final_model_path',default = './final_epoch_saved_model', type = str)
## SegNet model paras
parser.add_argument('--pretrained_segnet_model',default = './segnet_model/trained_model.torchsave', type = str)
parser.add_argument('--seg_net_vocab',default = './segnet_model/all_vocabulary.pickle', type = str)
parser.add_argument('--seg_net_vocab_size',default = 16703, type = int)
parser.add_argument('--seg_net_embed_size',default = 300, type = int)
parser.add_argument('--seg_net_use_cuda',default = False, type = bool)
parser.add_argument('--seg_net_finetuning',default = False, type = bool)
parser.add_argument('--seg_net_isbanor',default = True, type = bool)
## Other paras
parser.add_argument('--emotion_label_nums',default = 2, type = int)
parser.add_argument('--train_csv',default = r'./data/train_1.csv', type = str)
parser.add_argument('--test_csv',default = r'./data/test_1.csv', type = str)
parser.add_argument('--val_csv',default = r'./data/val_1.csv', type = str)
這個里面的引數是我在別的一個專案里面直接復制過來的,很多引數沒有修改,實際使用到的引數很少,可以在代碼里面自己看一下
2、創建資料處理檔案data_utils.py
該檔案主要用來加載資料集,并且分成batch輸入到模型里面,還有最重要的對文本按照長度進行排序,這樣做的目的是LSTM或者別的RNN在計算的時候不考慮padding,
import numpy as np
import json
import pandas as pd
def del_none(text): # delete ‘’ 洗掉使用空格切分之后句子里面的長度為0的字串
new_text = []
for t in text:
ws = t.split(' ')
ws = [w for w in ws if w != '']
new_text.append(' '.join(ws))
return new_text
def read_csv(para):# read Moive Review DataSet
train_data = pd.read_csv(para.train_csv, delimiter=',')
test_data = pd.read_csv(para.test_csv, delimiter=',')
val_data = pd.read_csv(para.val_csv, delimiter=',')
train_text = list(train_data['INPUT'])
train_label = list(train_data['OUTPUT'])
test_text = list(test_data['INPUT'])
test_label = list(test_data['OUTPUT'])
val_text = list(val_data['INPUT'])
val_label = list(val_data['OUTPUT'])
train_text = del_none(train_text)
test_text = del_none(test_text)
val_text = del_none(val_text)
train_label = np.array(train_label, dtype=np.int32)
test_label = np.array(test_label, dtype=np.int32)
val_label = np.array(val_label, dtype=np.int32)
return train_text, test_text, val_text, train_label, test_label, val_label
def create_dict(train_text):
for t in train_text:
ws = t.split(' ')
aw.extend(ws)
vocab = list(set(aw))
vd = dict(zip(vocab, range(2,len(vocab)+2)))
vd['UNKNOWN'] = 1
vd['PADDING'] = 0
with open('vd.json', 'w', encoding='utf-8') as f:
json.dump(vd, f)
def get_vd(path):
f = open(path,'r', encoding='utf-8')
vd = json.load(f)
return vd
def text2id(text, vd):
bs = len(text)
lens = [len(t.split(' ')) for t in text]
ml = max(lens)
text_id = np.zeros(shape = (bs, ml), dtype=np.int32)
words = list(vd.keys())
for i in range(bs):
ws = text[i].split(' ')
for j in range(lens[i]):
if ws[j] in words:
text_id[i,j] = vd[ws[j]]
else:
text_id[i, j] = vd['UNKNOWN']
return text_id, lens
def sort_data_by_length(textid, label, lengths):
lengths = np.array(lengths, dtype=np.int32)
idx = np.argsort(lengths)
idx = idx[::-1]
lengths = lengths[idx]
sc_id = textid[idx]
label = label[idx]
return sc_id, label, lengths
def batch_iter_str(text, label , batch_size = 16):
path = 'vd.json'
vd = get_vd(path)
data_nums = len(text)
num_batch = (data_nums + batch_size - 1) // batch_size
indices = np.random.permutation(np.arange(data_nums))
text = [text[i] for i in indices]
label = label[indices]
for i in range(num_batch):
start_offset = i * batch_size
end_offset = min(start_offset + batch_size, data_nums)
bt_text = text[start_offset:end_offset]
bt_label = label[start_offset:end_offset]
text_id, lens = text2id(bt_text, vd)
sc_id, bt_label, lengths = sort_data_by_length(text_id, bt_label, lens)
yield i, num_batch, sc_id, bt_label, lengths
3、創建Model.py檔案
import torch.nn as nn
import torch
device = torch.device("cuda:4" if torch.cuda.is_available() else "cpu")
class sa_model(nn.Module):
def __init__(self, para):
super(sa_model, self).__init__()
self.para = para
if para.SA_Rnn_type == 'LSTM':
self.RNN = nn.LSTM(input_size = para.SA_word_dim,
hidden_size = para.SA_hidden_dim,
num_layers = para.SA_layer_nums,
batch_first = True,
dropout = para.SA_dropout_rate,
bidirectional = para.SA_is_bi)
elif para.SA_Rnn_type == 'GRU':
self.RNN = nn.GRU(input_size = para.SA_word_dim,
hidden_size = para.SA_hidden_dim,
num_layers = para.SA_layer_nums,
batch_first = True,
dropout = para.SA_dropout_rate,
bidirectional = para.SA_is_bi)
elif para.SA_Rnn_type == 'RNN':
self.RNN = nn.RNN(input_size = para.SA_word_dim,
hidden_size = para.SA_hidden_dim,
num_layers = para.SA_layer_nums,
batch_first = True,
dropout = para.SA_dropout_rate,
bidirectional = para.SA_is_bi)
self.nnEm = nn.Embedding(para.SA_vocab_size, para.SA_word_dim, padding_idx = 0).to(device)
self.criterion = nn.CrossEntropyLoss()
self.linear = nn.Linear(para.SA_hidden_dim*2, para.emotion_label_nums)
def forward(self, x, x_len, label):
x = self.nnEm(x)
packed_embeds = nn.utils.rnn.pack_padded_sequence(x, x_len, batch_first=True)
out, hs = self.RNN(packed_embeds)
out, _ = nn.utils.rnn.pad_packed_sequence(out,
batch_first=True)
h1 = hs[0][0]
h2 = hs[0][1]
h = torch.cat([h1, h2], dim = 1)
logits = self.linear(h)
loss = self.criterion(logits, label)
pred = torch.argmax(torch.nn.functional.softmax(logits, dim = 1), dim = 1)
return loss, pred
4、創建train.py檔案
from Model import sa_model
from data_utils import batch_iter_str, read_csv
import torch
from model_para import Hpara
import torch.optim as optim
import matplotlib.pyplot as plt
from tqdm import tqdm
import os
from sklearn.metrics import accuracy_score
device = torch.device("cuda:4" if torch.cuda.is_available() else "cpu")
print(device)
def train(text, label, model, epoch):
optimizer = optim.RMSprop(filter(lambda p: p.requires_grad, model.parameters()), lr = para.lr * (0.95)**epoch)
pred_label = []
true_label = []
all_loss = []
model.train()
db = batch_iter_str(text, label)
for i, num_batch, sc_id, label, lengths in db:
sc_id = torch.tensor(sc_id).long().to(device)
label = torch.tensor(label).long().to(device)
lens = torch.tensor(lengths).long().to(device)
model.zero_grad()
loss ,pred = model(sc_id, lens, label)
all_loss.append(loss)
pred_label.append(pred)
true_label.append(label)
loss.backward()
optimizer.step()
if (i+1)%10 == 0:
print('%d step loss is : %f'%(i+1, loss.item()))
print('%d acc is : %f'%(i+1, accuracy_score(label.data.cpu().numpy(), pred.data.cpu().numpy())))
mean_loss = sum(all_loss) / num_batch
pred_label = torch.cat(pred_label, dim = 0)
true_label = torch.cat(true_label, dim = 0)
mean_acc = accuracy_score(true_label, pred_label)
return mean_loss, mean_acc
def test(saved_acc, text, label, model, mode = 'validation'):
pred_label = []
true_label = []
all_loss = []
model.eval()
db = batch_iter_str(text, label)
for i, num_batch, sc_id, label, lengths in db:
sc_id = torch.tensor(sc_id).long().to(device)
label = torch.tensor(label).long().to(device)
lens = torch.tensor(lengths).long().to(device)
model.zero_grad()
loss ,pred = model(sc_id, lens, label)
all_loss.append(loss)
pred_label.append(pred)
true_label.append(label)
mean_loss = sum(all_loss) / num_batch
pred_label = torch.cat(pred_label, dim = 0)
true_label = torch.cat(true_label, dim = 0)
mean_acc = accuracy_score(true_label, pred_label)
if mode == 'validation':# save the best model when the mode is 'validation'
if mean_acc >= saved_acc:
torch.save(model, os.path.join(para.saved_model_path,'My_model_pth'))
saved_acc = mean_acc
## TODO: the next step is to save the model every epoch
torch.save(model, os.path.join(para.final_model_path,'My_model_pth'))
return mean_loss, mean_acc, saved_acc
def load_model(para, model, best_model = True):
if best_model:
model_path = para.saved_model_path
else:
model_path = para.final_model_path
if os.path.exists(os.path.join(model_path, 'My_model_pth')):
print('model path is : ', model_path)
model = torch.load(os.path.join(model_path, 'My_model_pth'))
print('load pre-train')
else:
model = model
return model
if __name__ == '__main__':
saved_acc = 0.0
hp=Hpara()
parser = hp.parser
para = parser.parse_args()
train_text, test_text, val_text, train_label, test_label, val_label = read_csv(para)
model = sa_model(para)
model = model.to(device)
if para.is_load_best_model:
print('load the best model...')
_, _, saved_acc = test(saved_acc, val_text, val_label, model, mode = 'get_saved_acc')
model = load_model(para, model)
else:
print('load the final epoch model...')
_, _, saved_acc = test(saved_acc, val_text, val_label, model, mode = 'get_saved_acc')
model = load_model(para, model, best_model = False)
print('saved accuracy is :', saved_acc)
train_loss = []
train_acc = []
val_loss = []
val_acc = []
test_loss = []
test_acc = []
for i in range(para.epochs):
########### train ###########
train_mean_loss_i, train_mean_acc_i = train(train_text, train_label, model, i)
train_loss.append(train_mean_loss_i)
train_acc.append(train_mean_acc_i)
########## val #############
val_loss_i, val_acc_i, saved_acc = test(saved_acc, val_text, val_label, model, )
print('%d epoch val acc is', val_acc_i)
val_loss.append(val_loss_i)
val_acc.append(val_acc_i)
########## test ###########
test_loss_i, test_acc_i, saved_acc = test(saved_acc, test_text, test_label, model, mode = 'test')
print('%d epoch test acc is :', test_acc_i)
test_loss.append(test_loss_i)
test_acc.append(test_acc_i)
plt.figure(2)
plt.subplot(231)
plt.plot(train_loss)
plt.xlabel('epochs')
plt.ylabel('emotion_train_loss')
plt.subplot(232)
plt.plot(test_loss)
plt.xlabel('epochs')
plt.ylabel('emotion_test_loss')
plt.subplot(233)
plt.plot(val_loss)
plt.xlabel('epochs')
plt.ylabel('emotion_val_loss')
plt.subplot(234)
plt.plot(train_acc)
plt.xlabel('epochs')
plt.ylabel('emotion_train_acc')
plt.subplot(235)
plt.plot(test_acc)
plt.xlabel('epochs')
plt.ylabel('emotion_test_acc')
plt.subplot(236)
plt.plot(val_acc)
plt.xlabel('epochs')
plt.ylabel('emotion_val_acc')
plt.show()
5、完整的代碼
鏈接:https://pan.baidu.com/s/1nWMThnz9eK8zVggQJ7Umag
提取碼:0rwq
復制這段內容后打開百度網盤手機App,操作更方便哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/239676.html
標籤:python