前言

Hello,大家好,今天是早起的小澤!
早上10點相信對大家來說都還沒有起來吧,當然有作業的除外,要上學的除外,相信還是有很多可以天天在家里待著的富婆鴨,會來這里偷偷地學習,
那么今天咱們是要搞什么呢?
相信通過標題你也是知道了,自動化!

那么話不多說,直接帶大家起飛,好好學,好好問,你也可以成為大神!
什么是自動化
今天我們說到的自動化,不是你們可能聽過很多的無人駕駛,機器人鴨什么的,就是沒有那么高級哈,
這個自動化呢,在python里面用一個模塊來實作:selenium

如果缺少這個東西呢,大家是有可能得抑郁癥的,所以也可以看出來自動化對大家來說是多么的重要,還不趕緊學起來!
什么,你老抑郁了?

還沒12點呢,
當然想只通過上面毫無關聯的翻譯來了解自動化,不太現實,
所以再給大家科普一下:
Selenium
是一個用于Web應用程式測驗的工具,Selenium測驗直接運行在瀏覽器中,就像真正的用戶在操作一樣,支持的瀏覽器包括IE(7, 8, 9,10, 11),Mozilla Firefox,Safari,Google,Chrome,Opera等,這個工具的主要功能包括:測驗與瀏覽器的兼容性——測驗你的應用程式看是否能夠很好得作業在不同瀏覽器和作業系統之上,測驗系統功能——創建回歸測驗檢驗軟體功能和用戶需求,支持自動錄制動作和自動生成
.Net、Java、Perl等不同語言的測驗腳本,
如果你還是看的不太明白,就可以這么理解:
selenium就是能幫我們自動瀏覽網頁,自動獲取那些我們能看到的資料,
總之呢,requests是屬于黑暗里的一道光,而selenium就是光明正大的搞你,就是要搞你,
雖然上面說支持的瀏覽器有很多,但是還是推薦大家統一使用谷歌瀏覽器哈,
怎么安裝selenium
又到了熟悉的教小白環節,小澤發現有很多人是直接學爬蟲的誒,然后很多基礎方面的,或者前端方面的知識鴨,就不太懂,這里可以花點時間把需要掌握的知識,系統的學一遍,畢竟不能急嘛,比的就是基本功,
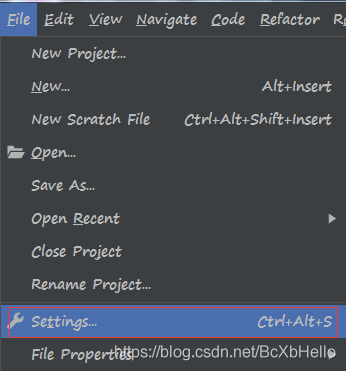
直接開始教程,很快啊,
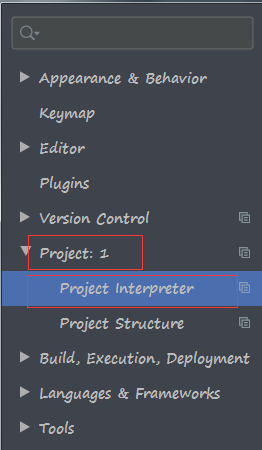
上面那個Project:1有的人可能找不到哦,因為你的專案名字不是1,找你的專案名字就好了,專案名字是最外層那個檔案夾的名字哦,
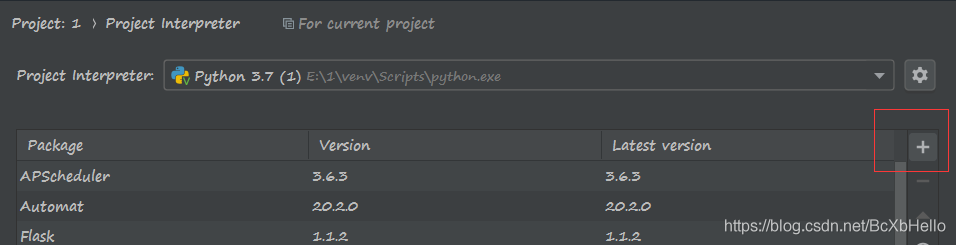
找加號,有的人的加號可能在下面,
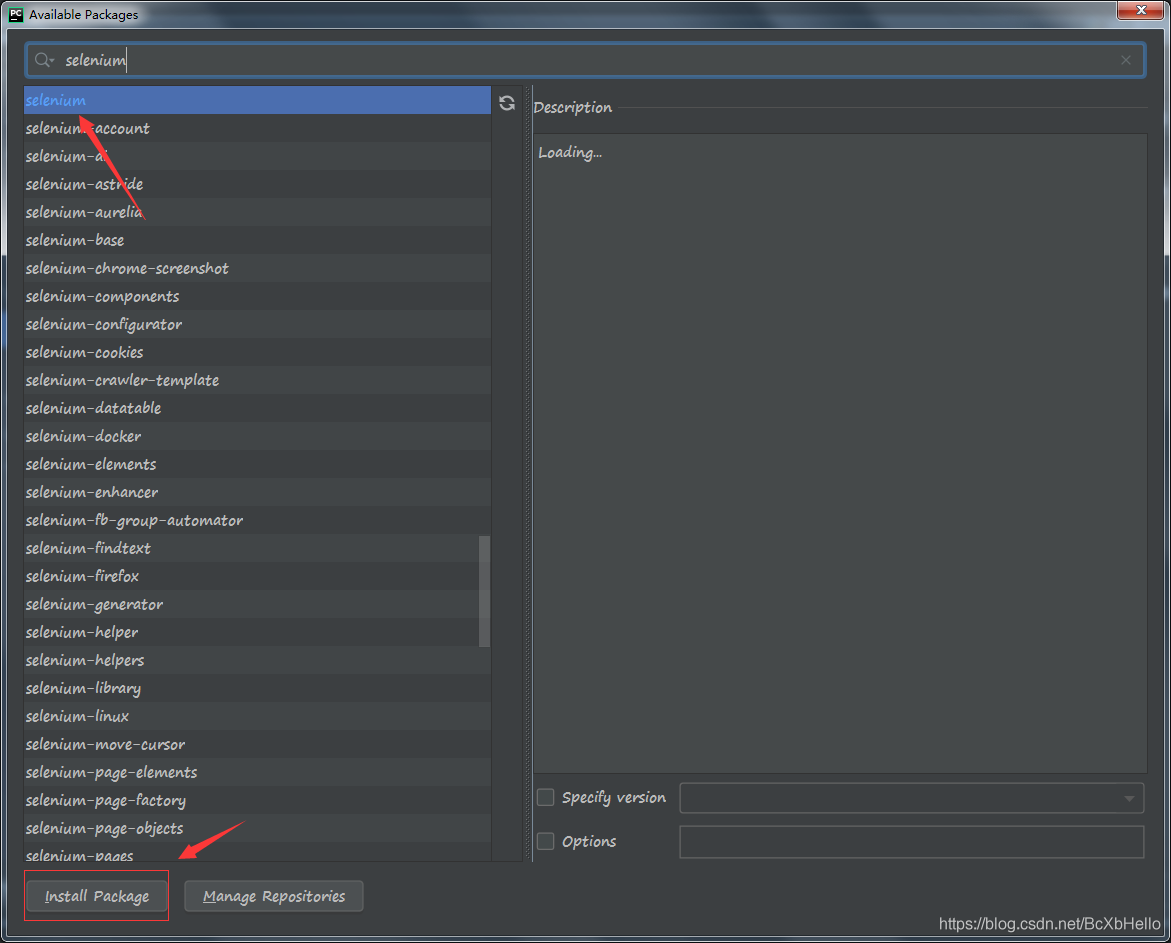
搜索selenium,然后點擊左下方的下載,等你變綠了,就說明沒毛病了嗷,
當然有的小伙伴可能會出現紅色,下載失敗,解決方法呢,在 一起學爬蟲(Python) — 07 里面是有介紹的,在中間往下的部分,可以去找一找,
神奇の傳送門1號
然后,模塊我們就安裝完成啦!
接下來就是重頭戲了,要一起安裝谷歌瀏覽器的引擎!
神奇の傳送門2號
打開這個網址之前呢,大家先跟著小澤一起看一下自己谷歌瀏覽器的版本:
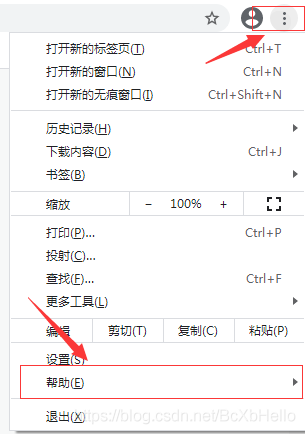
在幫助里面呢,有個關于Google Chrome,點進去,
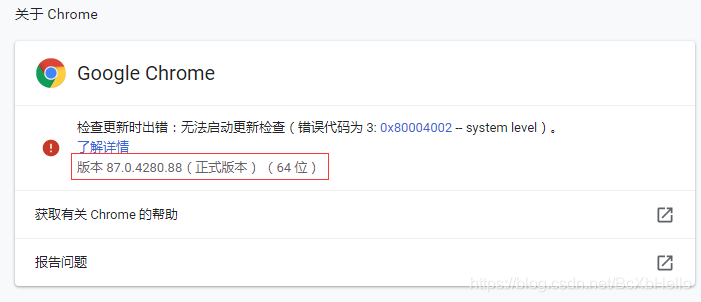
你就能看到你的版本啦,
然后打開上面的傳送門2號:
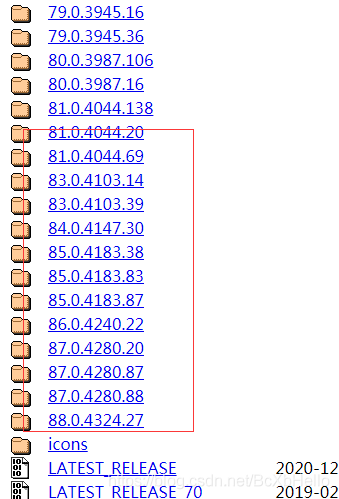
找到你對應的版本號的檔案,然后點進去:
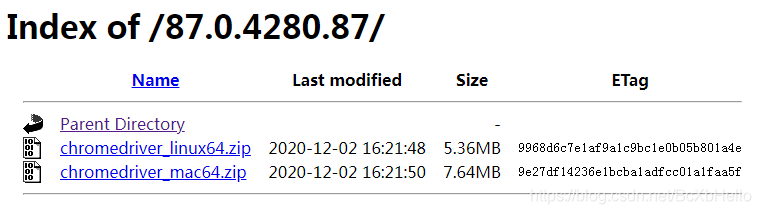
再根據自己的系統進行下載哈,
下載完了把里面的:
放在你能找得到的地方,
如果這些你都準備好了,那我們就可以開始了!
開沖!
最近小澤看到淘寶上有代沖的哦,10塊錢一次,能讓老板代替我們沖,如果大家實在忍不住可以去光顧一下,關愛自己,人人有責,

# 匯入模塊
from selenium import webdriver
第一步當然不用說啦,匯入模塊,對了,上面那個引擎,可以放在py檔案的當前目錄下哦,用的時候也方便!
# 這里指定自己的谷歌引擎目錄
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
今天,我們都是老司機!
上面那句是每次都要這樣寫的,所以不用糾結是為什么哦,Chrome就是谷歌的意思嘛~
from time import sleep
# 打開csdn的登錄界面
driver.get('https://passport.csdn.net/login?code=public')
print('正在打開指定網頁…')
sleep(1)
這里sleep1秒呢,是因為怕還沒加載出來就繼續下一步了,就有問題了,
先不要問代碼為什么這么寫,試試效果鴨!
# 找到那個輸入賬號密碼的按鈕
dl = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/ul/li[2]')
# 模擬點擊
dl.click()
sleep(1)
先照樣子復制,find_element_by_xpath就是根據xpath去找標簽的位置哦,你也可以根據class,id等等…
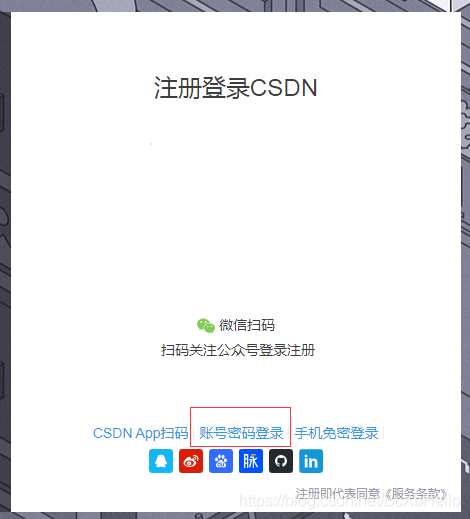
剛進來的時候,我們是需要點一下這個賬號密碼登錄的,所以就點擊了這個標簽對應的xpath,

第一步:輸入賬號
第二步:輸入密碼
第三步:點擊登錄
清楚了步驟,就讓我們開始復制代碼吧!
# 回圈判斷是否登陸成功
while True:
user_number = input('輸入你滴賬號:')
pass_word = input('輸入你滴密碼:')
# 找到賬號框
input = driver.find_element_by_xpath('//*[@id="all"]')
# 找到密碼框
password = driver.find_element_by_id('password-number')
# 把賬號放進賬號框
input.send_keys(user_number)
# 把密碼放進密碼框
password.send_keys(pass_word)
# 找到登錄按鈕
btn = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/div/div[6]/div/button')
# 點擊登錄按鈕
btn.click()
sleep(1)
# 取得目前的url
now_url = driver.current_url
# 判斷是否登陸成功
if now_url == 'https://passport.csdn.net/login?code=public':
print('登陸失敗!')
sleep(1)
continue
else:
print('登陸成功!')
sleep(1)
break
相信聰明的你,一定能自己消化掉上面的代碼,如果不能,沒關系,下一期我們詳細到每根毛孔都講的清清楚楚! 先復制哈~
print('正在獲取所有文章……')
# 前往存有所有博客url的那篇博客
driver.get('https://blog.csdn.net/BcXbHello/article/details/111560584')
sleep(1)
# 獲取博客文本
data = driver.find_element_by_xpath('//*[@id="content_views"]/p').text
print('成功獲取所有文章!')
sleep(1)
# 判斷是否點贊
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '點贊':
is_like.click()
sleep(1)
# 處理url
data = data.split('|')[:-2]
for url in data:
driver.get(url)
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '點贊':
title = driver.find_element_by_xpath('//*[@id="articleContentId"]').text
is_like.click()
print(title+'點贊完畢!')
sleep(1)
print('已經全部點贊完畢!堅決不做白嫖黨,我愛小澤!!!')
# 退出除錯
driver.quit()
注釋呢,盡量的都寫上去了,這一篇就先帶著大家感受一下selenium的魅力~

結尾
也許聰明的你已經發現,這是一個防止白嫖的帖子,但是真的很有意思對不對~
點了贊,就是我的人了,好好聽話,好好學習,下一篇給你看個大寶貝,

當然,有些懶家伙,不喜歡一個一個復制,這里也直接把所有代碼都打出來好了:
from time import sleep
from selenium import webdriver
# 實作無可視化界面
from selenium.webdriver.chrome.options import Options
# 實體化一個options物件 實作無可視化界面的操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 這里指定自己的谷歌引擎目錄
driver = webdriver.Chrome(executable_path='./chromedriver.exe',options=chrome_options)
# 打開csdn的登錄界面
driver.get('https://passport.csdn.net/login?code=public')
print('正在打開指定網頁…')
sleep(1)
# 找到那個輸入賬號密碼的按鈕
dl = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/ul/li[2]')
# 點擊
dl.click()
sleep(1)
# 回圈判斷是否登陸成功
while True:
user_number = input('輸入你滴賬號:')
pass_word = input('輸入你滴密碼:')
# 找到賬號框
input = driver.find_element_by_xpath('//*[@id="all"]')
# 找到密碼框
password = driver.find_element_by_id('password-number')
# 把賬號放進賬號框
input.send_keys(user_number)
# 把密碼放進密碼框
password.send_keys(pass_word)
# 找到登錄按鈕
btn = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[2]/div[5]/div/div[6]/div/button')
# 點擊登錄按鈕
btn.click()
sleep(1)
# 取的目前的url
now_url = driver.current_url
# 判斷是否登陸成功
if now_url == 'https://passport.csdn.net/login?code=public':
print('登陸失敗!')
sleep(1)
continue
else:
print('登陸成功!')
sleep(1)
break
print('正在獲取所有文章……')
# 前往存有所有博客url的那篇博客
driver.get('https://blog.csdn.net/BcXbHello/article/details/111560584')
sleep(1)
# 獲取博客文本
data = driver.find_element_by_xpath('//*[@id="content_views"]/p').text
print('成功獲取所有文章!')
sleep(1)
# 判斷是否點贊
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '點贊':
is_like.click()
sleep(1)
# 處理url
data = data.split('|')[:-2]
print(data)
for url in data:
driver.get(url)
is_like = driver.find_element_by_xpath('//*[@id="is-like-span"]')
if is_like.text == '點贊':
title = driver.find_element_by_xpath('//*[@id="articleContentId"]').text
is_like.click()
print(title+'點贊完畢!')
sleep(1)
print('已經全部點贊完畢!堅決不做白嫖黨,我愛小澤!!!')
# 退出除錯
driver.quit()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/239677.html
標籤:python