目錄
前言
一、Logistic回歸模型
二、Logit模型
三、幾率
四、Logistic模型
五、基于最優化方法的最佳回歸系數確定
5.1梯度上升演算法
5.1.1梯度
5.1.2使用梯度上升找到最佳引數
5.2、畫出決策邊界
5.3、 隨機梯度上升
5.4、優化隨機梯度上升
六、實戰:從疝氣病癥預測病馬的死亡率
總結
前言
這是自學習機器學習以來第一次接觸到最優化演算法,首先必須要有一定的概率論理論基礎才更好的理解該回歸的原理以及意義,本篇將詳細說明該模型的原理以及用途,結合例子更好理解Logistic回歸,本篇大幅度參考logistic回歸模型這篇優質博客作為前期基礎理論引入方便大家理解,在理解之后在進行建模和實戰,
提示:以下是本篇文章正文內容,下面案例可供參考
一、Logistic回歸模型
logistic回歸(Logistic Regression)是一種廣義線性回歸(Generalized Linear Model),在機器學習中是最常見的一種用于二分類的演算法模型,由于數學原理簡單,方便理解,作用高效,其實際運用相當廣泛,為了通過自變數的線性組合來預測類別因變數的取值,logistic回歸模型應運而生,logistic回歸的因變數可以是二分類的,也可以是多分類的,但是二分類的更為常用,也更加容易解釋,多類可以使用softmax方法進行處理,實際中最為常用的就是二分類的logistic回歸,雖然帶有回歸二字,但實則是分類模型,下面從最基礎的logit變換開始理解,
二、Logit模型
對于研究因變數(結果)與引發其變化的因素自變數(因素)的關系時,我們想到最基礎的方法就是建立因變數與自變數的多元線性關系:
其中 為模型的引數,可視為該一變數的權重,如果因變數是數值型的話,可以解釋為不同變數
變化導致結果Y因此而變化多少,如果因變數
是用來刻畫結果是否發生或者更一般的來刻畫某特定結果發生的概率的情況,一個自變數
的改變可能會讓Y結果改變的微乎其微,有時候甚至忽略不計,然而實際生活中,我們知道某些關鍵因素會直接導致某一結果的發生,例如最典型的演算法AHP中影響去不同的景點的因素權重不同導致選取方向發生改變幾率大不相同,我們需要讓不顯著的線性關系變得顯著,使得模型能夠很好解釋隨因素的變化,結果也會發生較顯著的變化,這時候,人們想到了logit變換,下圖是對數函式影像:
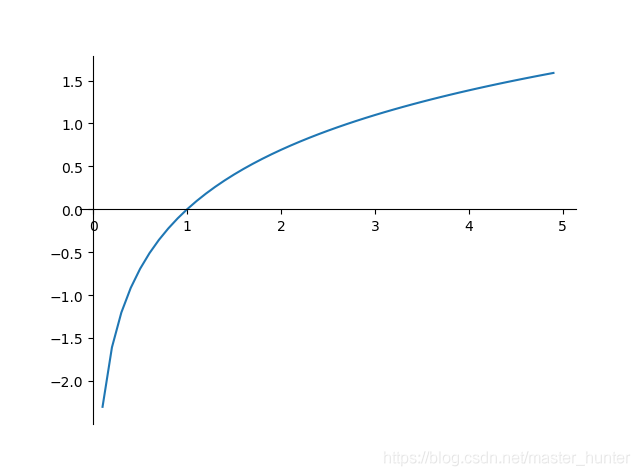
從對數函式的影像來看,其在之間的因變數的變化是很迅速的,也就是說自變數的微小變化會導致因變數的巨大變化,這就符合了之前想要的效果,于是,對因變數進行對數變換,右邊依然保持線性關系,有下面式子:
雖然上式解決了因變數隨自變數變化的敏感性問題,同時也約束了y的取值范圍為( 0 , + ∞ ),我們知道概率是用來描述某件事發生的可能性,一件事情發生與否,更應該是調和對稱的,也就是說該事件發生與不發生有對立性,結果可以走向必然發生(概率為1),也可以走向必然不發生(概率為0),概率的取值范圍為( 0 , 1 ) ,而等式左邊 y 的取值范圍是( 0 , + ∞ ),所以需要進一步壓縮,又引進了幾率,
三、幾率
幾率和機率是兩個不同的詞,前者是指事件發生的概率與不發生的概率之比,而后者只是指事情發生的概率,
假設事件 A 發生的概率為 ,不發生的概率為
,那么事件 A 的幾率為
幾率恰好反應了某一事件兩個對立面,具有很好的對稱性,下面我們再來看一下概率和幾率的關系:
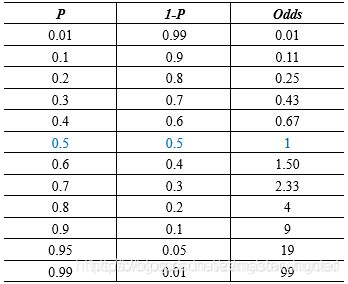
首先,我們看到概率從0.01不斷增大到 0.99,幾率也從0.01隨之不斷變大到99,兩者具有很好的正相關系,我們再對 p 向兩端取極限有:
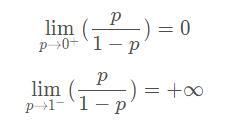
于是,幾率的取值范圍就在( 0 , + ∞ ),這符合我們之前的因變數取值范圍的假設,
四、Logistic模型
從上述推到可以發現,我們可以利用幾率來代替Y結果,二者范圍都為(0,+∞),且幾率與概率密切對等,這樣既能滿足結果對特定因素的敏感性,又能滿足對稱性 ,于是便可推匯出:
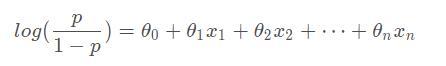
現在對這個公式進行化簡:讓等式左邊對數變成自然對數,等式右邊改為向量乘積的形式,便有
其中,
,我們解得
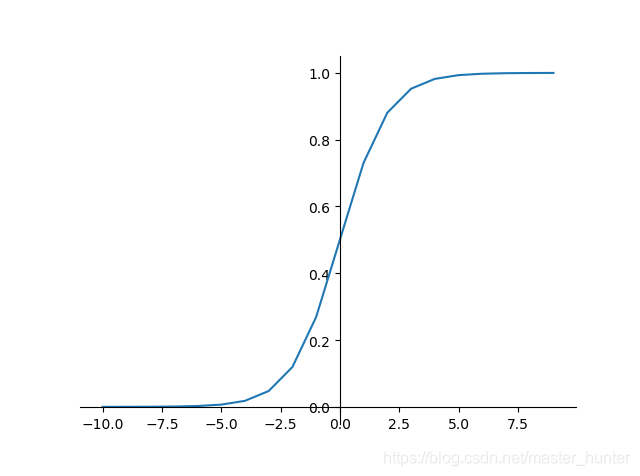
其中是自然常數,保留5位小數是2.71828,這就是我們常見的logistic模型運算式,作出其函式影像如下
import matplotlib.pyplot as plt
import math
import numpy as np
def sigmoid(z):
y=[]
for i in z:
y.append(1/(1+math.exp(-i)))
return y
if __name__ == '__main__':
x=np.arange(-10,10)
y=sigmoid(x)
ax=plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
plt.plot(x,y)
plt.show()
我們看到logistic函式影像是一條S型曲線,又名sigmoid曲線,以 ( 0 , 0.5 ) 為對稱中心,隨著自變數 x 不斷增大,其函式值不斷增大接近1,隨自變數 x 不斷減小,其函式值不斷降低接近0,函式的取值范圍在 ( 0 , 1 ) 之間,且函式曲線在中心位置變化速度最快,在兩端的變化速率較慢,
從上面的操作,我們可以看到邏輯回歸模型從最初的線性回歸模型基礎上對因變數進行 logit 變換,使得因變數對自變數顯著,同時約束因變數取值范圍為0到正無窮大,然后用概率表示幾率,最后求出概率關于自變數的運算式,把線性回歸的結果壓縮在 ( 0 , 1 ) 范圍內,這樣最后計算出的結果是一個0到1之間的概率值,表示某事件發生的可能性大小,可以做概率建模,這也是為什么邏輯回歸叫邏輯回歸,而不叫邏輯分類了,
五、基于最優化方法的最佳回歸系數確定
根據上述推導我們已知,其中的向量x是分類器的輸入資料,向量
也就是我們要找的最佳引數系數,從而使得分類器盡可能地精確,為了尋找最佳引數,需要用到最優化理論的一些知識,
5.1梯度上升演算法
要理解該演算法推薦看一篇博客較詳細理解:梯度演算法之梯度上升和梯度下降,這里僅作簡單解釋,
5.1.1梯度
梯度上升演算法基于的思想是:要找到函式的最大值,最好的方法是沿著該函式的梯度方向探尋,對此我們需要明白代表函式變化快慢的導數以及偏導數,在此基礎上我們不僅要知道函式在坐標軸正方向上的變化率(即偏導數),而且還要設法求得函式在其他特定方向上的變化率,而方向導數就是函式在其他特定方向上的變化率,梯度與方向導數有一定的關聯性,在微積分里面,對多元函式的引數求偏導數,把求得的各個引數的偏導數以向量的形式寫出來,就是梯度,
例如我們對函式求得它的梯度:
對其求偏導可知:
所以,
函式在某一點的梯度是這樣一個向量,它的方向與取得最大方向導數的方向一致,而它的模為方向導數的最大值,
5.1.2使用梯度上升找到最佳引數
可以假設為爬山運動,我們總是往向著山頂的方向攀爬,當爬到一定角度以后也會駐足停留下觀察自身角度是否是朝著山頂的角度上攀爬,并且我們需要總是指向攀爬速度最快的方向爬,
關于梯度上升的幾個概念:
)步長(learning rate):步長決定了在梯度下降迭代程序中,每一步沿梯度負方向前進的長度
2)特征(feature):指的是樣本中輸入部門,比如樣本(x0,y0),(x1,y1),則樣本特征為x,樣本輸出為y
3)假設函式(hypothesis function):在監督學習中,為了擬合輸入樣本,而使用的假設函式,記為,比如對于樣本
(,
)(i=1,2,...n),可以采用擬合函式如下:
![]()
4)損失函式(loss function):為了評估模型擬合的好壞,通常用損失函式來度量擬合的程度,損失函式極小化,意味著擬合程度最好,對應的模型引數即為最優引數,在線性回歸中,損失函式通常為樣本輸出和假設函式的差取平方,比如對于樣本(,
)(i=1,2,...n),采用線性回歸,損失函式為:
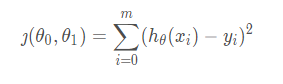
其中?表示樣本特征x的第i個元素,
表示樣本輸出y的第i個元素,
為假設函式,
梯度上升演算法的基本思想是:要找到某函式的最大值,最好的方法就是沿著該函式的梯度方向搜尋,我們假設步長為,用向量來表示的話,梯度上升演算法的迭代公式如下:
,該公式停止的條件是迭代次數達到某個指定值或者演算法達到某個允許的誤差范圍,
關于梯度演算法將直接用代碼演示,這里不作詳細解釋,在之后會詳細說明這一演算法,先直接進入實戰:
先給出資料檔案:《機器學習實戰Logistic回歸舉例資料》
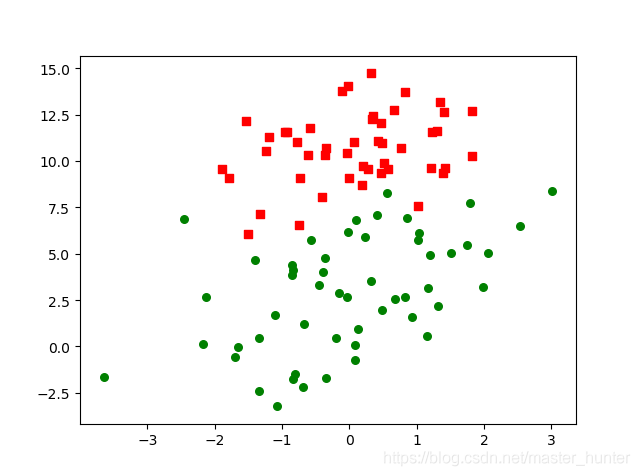
這里我們可以看看資料分布,制作散點圖:
import matplotlib.pyplot as plt
from numpy import *
def loadData():
dataMat=[]
labelMat=[]
fr = open('sample1.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])
labelMat.append(int(lineArr[2]))
# print(dataMat)
# print(labelMat)
return dataMat, labelMat
def plotDot():
dataMat,labelMat=loadData()
dataArr = array(dataMat)
n = shape(dataArr)[0]
x0=[]
x1=[]
y0=[]
y1=[]
for i in range(n):
if labelMat[i]==1:
x1.append(dataMat[i][1])
y1.append(dataMat[i][2])
else:
x0.append(dataMat[i][1])
y0.append(dataMat[i][2])
print(x0)
print(x1)
fig = plt.figure()
ax = fig.add_subplot(111)#分割為1行1列第1塊
ax.scatter(x0, y0, s=30, c='red', marker='s')
ax.scatter(x1, y1, s=30, c='green')
plt.show()
plotDot()
資料集中一共有100個點,每個點包含兩個數值型特征:X1和X2,因此可以將資料在一個二維平面上展示出來,我們可以將第一列資料(X1)看作x軸上的值,第二列資料(X2)看作y軸上的值,而最后一列資料即為分類標簽,根據標簽的不同,對這些點進行分類,
梯度上升法的偽代碼:
每個回歸系數初始化為1
重復R次:
計算整個資料集的梯度
使用alpha * gradient更新回歸系數的向量
回傳回歸系數代碼實作:
from numpy import *
#預處理資料
def loadDataSet():
#創建兩個串列
dataMat=[];labelMat=[]
#打開文本資料集
fr=open('sample1.txt')
#遍歷文本的每一行
for line in fr.readlines():
#對當前行去除首尾空格,并按空格進行分離
lineArr=line.strip().split()
#將每一行的兩個特征x1,x2,加上x0=1,組成串列并添加到資料集串列中
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])
#將當前行標簽添加到標簽串列
labelMat.append(int(lineArr[2]))
#回傳資料串列,標簽串列
return dataMat,labelMat
#定義sigmoid函式
def sigmoid(inx):
return 1.0/(1+exp(-inx))
#梯度上升法更新最優擬合引數
#@dataMatIn:資料集
#@classLabels:資料標簽
def gradAscent(dataMatIn,classLabels):
#將資料集串列轉為Numpy矩陣
dataMatrix=mat(dataMatIn)
#將資料集標簽串列轉為Numpy矩陣,并轉置
labelMat=mat(classLabels).transpose()
#獲取資料集矩陣的行數和列數
m,n=shape(dataMatrix)
#學習步長
alpha=0.001
#最大迭代次數
maxCycles=500
#初始化權值引數向量每個維度均為1.0
weights=ones((n,1))
print(weights)
#回圈迭代次數
for k in range(maxCycles):
#求當前的sigmoid函式預測概率
h=sigmoid(dataMatrix*weights)
#***********************************************
#此處計算真實類別和預測類別的差值
#對logistic回歸函式的對數釋然函式的引數項求偏導
error=(labelMat-h)
#更新權值引數
weights=weights+alpha*dataMatrix.transpose()*error
#***********************************************
return weights
dataMat,labelMat=loadDataSet()
m=gradAscent(dataMat,labelMat)
print(m) 
我們知道對回歸系數進行更新的公式為:,其中
是對引數w求偏導數,則我們可以通過求導驗證logistic回歸函式對引數w的梯度為(
-sigmoid(
))*
,
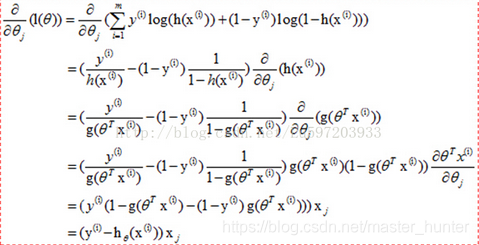
5.2、畫出決策邊界
def plotBestFit(wei):
import matplotlib.pyplot as plt
weights = wei.getA()
dataMat, labelMat = loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else: xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 30, c = 'red', marker='s')
ax.scatter(xcord2, ycord2, s = 30, c = 'green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]- weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1');
plt.ylabel('X2');
plt.show()
plotBestFit(m)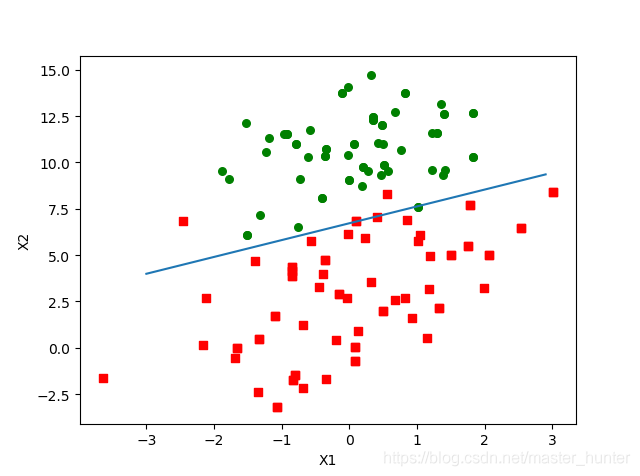
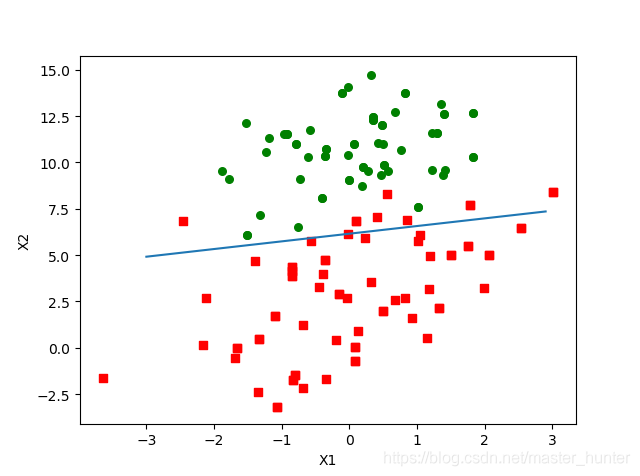
在擬合分類線中,我們設定sigmoid函式為0,0是兩個分類的分解處,因此我們設定,然后根據函式制定x坐標表示為x1,y坐標表示為x2,畫出分類線,盡管分類結果不錯,但是這個方法卻需要大量計算,
5.3、 隨機梯度上升
梯度上升演算法在每次更新回歸系數時需要遍歷整個資料集,該方法在處理100個左右的資料集時尚可,但如果有數十億樣本和成千上萬的特征,那么該方法就很費勁了,所有我們思考了優化,一次僅用一個樣本點來更新回歸系數,該方法稱為隨機梯度上升法,對應的更新公式是:
由于可以在新的樣本到來時對分類器進行增量式更新,因而隨機梯度上升演算法是一個在線學習演算法,與之對應的是批處理演算法,
隨機梯度上升偽代碼:
所有回歸系數初始化為1
對資料集中每個樣本
計算該樣本的梯度
使用alpha*gradient更新回歸系數值
回傳回歸系數值代碼:
def stocGradAscent0(dataMatrix,classLabels):
m,n=shape(dataMatrix)
alpha=0.01
weights=ones(n)
dataMatrix=array(dataMat)
for i in range(m):
h=sigmoid(sum([dataMatrix[i]*weights]))
error = classLabels[i]-h
weights=weights+alpha*error*dataMatrix[i]
print(type(dataMatrix[i]))
return weights
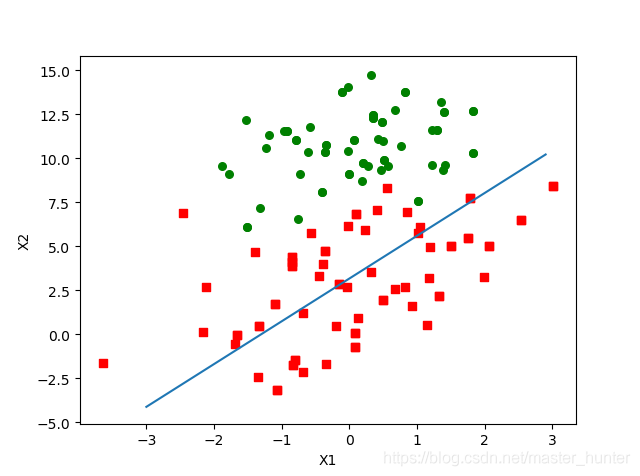
隨機梯度上升法和批量梯度上升法是兩個極端,一個采用所有資料來梯度上升,一個用一個樣本來梯度上升,自然各自的優缺點都非常突出,對于訓練速度來說,隨機梯度上升法由于每次僅僅采用一個樣本來迭代,訓練速度很快,而批量梯度上升法在樣本量很大的時候,訓練速度不能讓人滿意,對于準確度來說,隨機梯度上升法用于僅僅用一個樣本決定梯度方向,導致解很有可能不是最優,對于收斂速度來說,由于隨機梯度上升法一次迭代一個樣本,導致迭代方向變化很大,不能很快的收斂到區域最優解, 但值得一提的是,隨機梯度上升法在處理非凸函式優化的程序當中有非常好的表現,由于其上升方向具有一定隨機性,因此能很好的繞開區域最優解,從而逼近全域最優解,
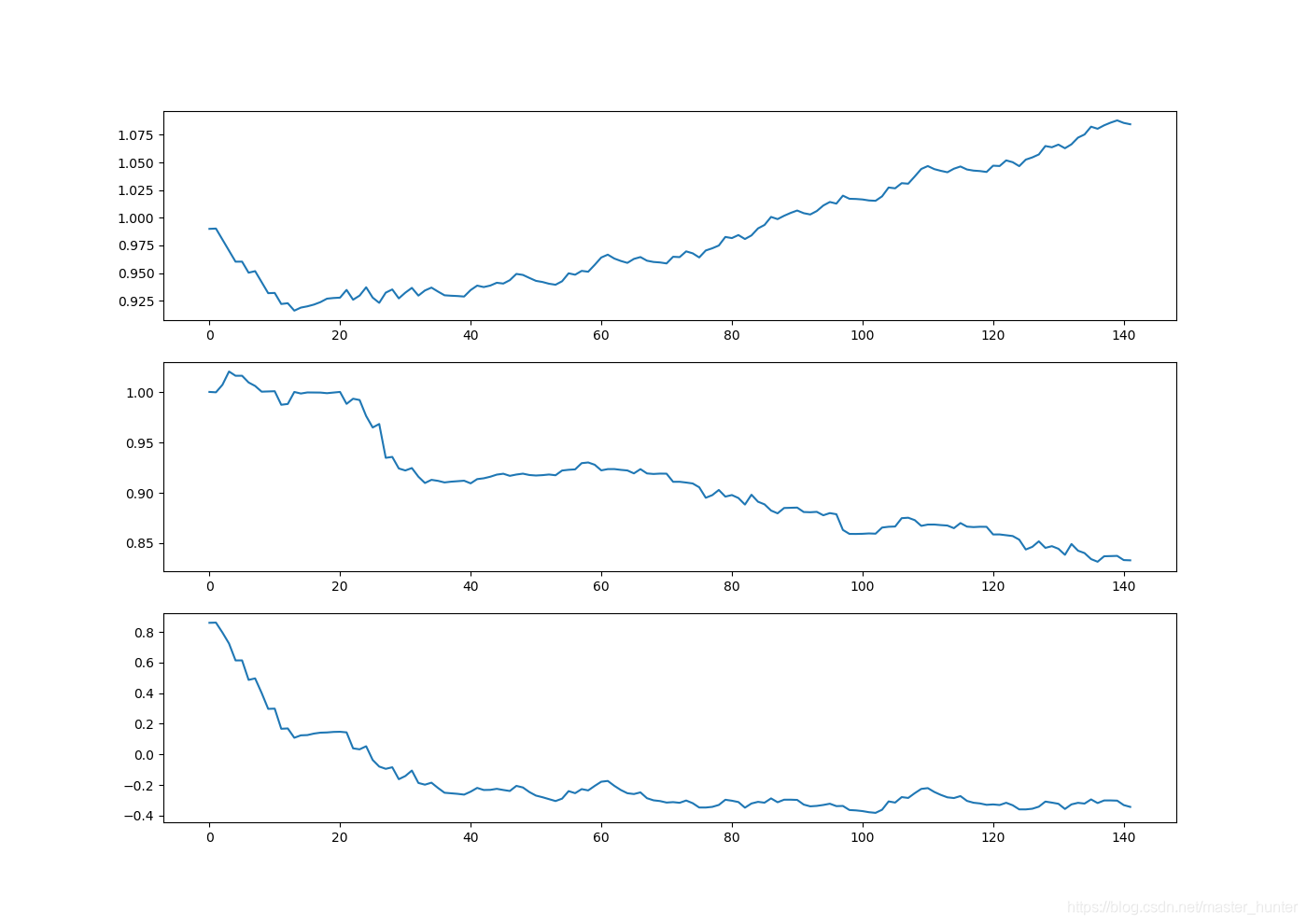
一個判斷優化演算法的可靠辦法是看它是否收斂,也就是說引數是否達到了穩定值,是否還會變化,對此觀察隨機梯度上升演算法的3個引數的變化:
def stocGradAscent0(dataMatrix,classLabels):
m,n=shape(dataMatrix)
print(n)
x1 = arange(0, 142)
y1=[]
y2=[]
y3=[]
alpha=0.01
weights=ones(n)
dataMatrix=array(dataMat)
for i in range(142):
h=sigmoid(sum([dataMatrix[i]*weights]))
error = classLabels[i]-h
weights=weights+alpha*error*dataMatrix[i]
y1.append(weights[0])
y2.append(weights[1])
y3.append(weights[2])
fig=plt.figure(figsize=(14,14),dpi=100)
plt.subplot(3, 1, 1)
plt.plot(x1,y1)
plt.subplot(3, 1, 2)
plt.plot(x1, y2)
plt.subplot(3, 1, 3)
plt.plot(x1, y3)
# ax = fig.add_subplot(111)
# bx = fig.add_subplot(211)
# cx = fig.add_subplot(311)
# ax.plot(x1, y1)
# bx.plot(x1,y2)
# cx.plot(x1,y3)
plt.show()
return weights我們發現第三個引數僅僅在50次迭代就達到了穩定值,而其他兩個則需要更多次迭代,產生這種現象的原因是存在一些不能正確分類的樣本點(資料集并非線性可分),在每次迭代時會引發系數的劇烈變化,
5.4、優化隨機梯度上升
我們對隨機梯度上升演算法做一些調整:
def stocGradAscent0(dataMatrix,classLabels,numIter=150):
m,n=shape(dataMatrix)
alpha=0.01
weights=ones(n)
dataMatrix=array(dataMat)
for j in range(150):
dataIndex = range(m)
dataIndex=list(dataIndex)
for i in range (m):
#alpha每次迭代時調整
alpha=4/(1.0+j+i)+0.1
#隨機選取更新
randIndex=int(random.uniform(0,len(dataIndex)))
h=sigmoid(sum([dataMatrix[randIndex]*weights]))
error = classLabels[randIndex]-h
weights=weights+alpha*error*dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights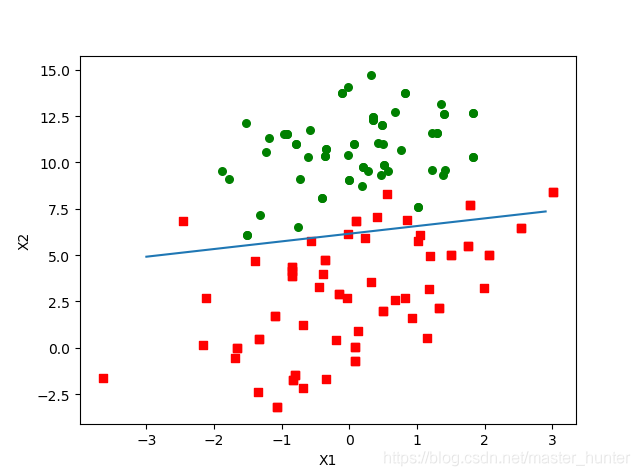
該分割線達到了與gradAscent()差不多的效果,而且計算量明顯少于批量梯度上升演算法,
六、實戰:從疝氣病癥預測病馬的死亡率
我們將使用Logistic回歸來預測患有疝氣病的馬存活問題,此資料集包含368個樣本和28個特征,另外需要說明的是這些資料集是有部分缺失,我們需要先進行資料預處理再利用回歸預測,
對于資料集中缺失資料我們可以采取以下辦法進行處理:
- 使用可用特征的均值來填補缺失值;
- 使用特殊值來填補缺失值,比如-1;
- 忽略有缺失值的樣本;
- 使用相似樣本的均值添補缺失值;
- ‘使用另外的機器學習演算法預測缺失值;(如KNN)
而對于該資料集我們選擇用0代替缺失值,因為根據回歸系數的更新公式:
當一資料集特征為0時,,將不作更新,
另外由于sigmoid(0)=0.5,它對結果的預測不具有任何傾向性,因此上述做法也不會對誤差項造成任何影響,
現在我們根據上述所做的作業,現在只需要將特征向量乘以最優化系數得到的值全部相加,作為輸入給sigmoid函式中,如果sigmoid值大于0.5則給定標簽為1,否則為0,
def colicTest():
frTrain = open('horseColicTraining.txt', encoding='utf8');
frTest = open('horseColicTest.txt', encoding='utf8')
trainingSet = []
trainingLabels = []
print(frTest)
print(frTrain)
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent0(array(trainingSet), trainingLabels, 1000)
errorCount = 0
numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount) / numTestVec)
print("該模型錯誤率為: %f" % errorRate)
return errorRate由于每次是隨機取數,所以我們可將colicTest()迭代次數更多一些:
def multiTest():
numTests = 10
errorSum = 0.0
for k in range(numTests):
errorSum += colicTest()
print("該模型迭代%d次平均錯誤率為: %f",numTests,(numTests, errorSum / float(numTests)))運行輸出:
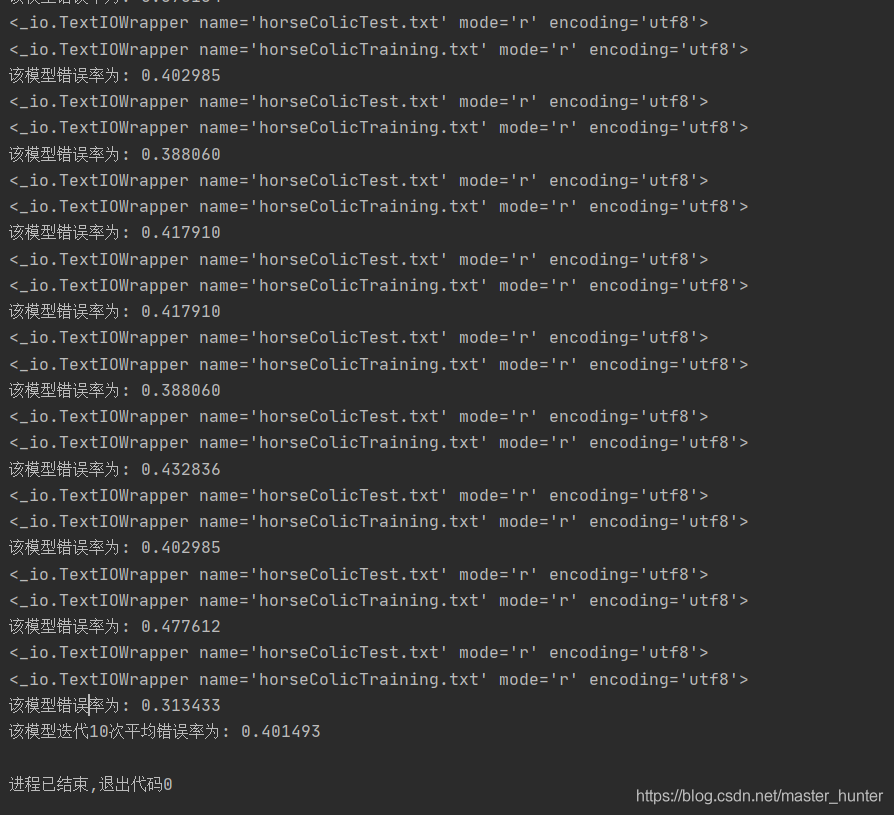
可見錯誤率還是很低,因為資料存在30%的丟失,
總結
Logistic回歸利用Sigmoid函式作為最佳擬合函式,利用最優化演算法求出引數,再把資料集特征向量矩陣與對應訓練好的引數相乘再相加,作為Sigmoid的輸入從而得到預測,
參閱:
https://blog.csdn.net/zengbowengood/article/details/105006063
https://blog.csdn.net/weixin_43250805/article/details/105238795?utm_medium=distribute.pc_relevant.none-task-blog-baidulandingword-11&spm=1001.2101.3001.4242
https://www.cnblogs.com/zy230530/p/6875145.html
https://thinkgamer.blog.csdn.net/article/details/78797667
https://www.cnblogs.com/tianqizhi/p/10203412.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/239678.html
標籤:python