前言
上一章的內容主要有:
- pandas兩種基本的資料結構:Series 和 DataFrame 及它們的一些重要屬性和方法
- pandas中的I/O方法
- 視窗物件的簡單介紹和使用
在本次學習中,我們主要聚焦于Series和DataFrame中的一些索引操作,比如:
- 通過索引訪問Series、DataFrame中指定的元素
- 隨機訪問Series、DataFrame中的陣列
- 多級索引的構造和訪問
- 索引層的交換和洗掉
- 索引值和名的修改
- 索引的設定和重置
- 索引的運算
希望通過學會“索引”的相關知識,讓我們對一組資料能擁有精準“打擊”的能力,
一、索引器
這一節主要講解如何在不改變資料的前提下,利用索引對資料進行 指定 和 非指定(隨機) 提取:
1.Series資料的行索引
先考慮Series型別的資料,對于一個包含shape為(5,)ndarray型別的Series資料,其直觀表現形式如下:
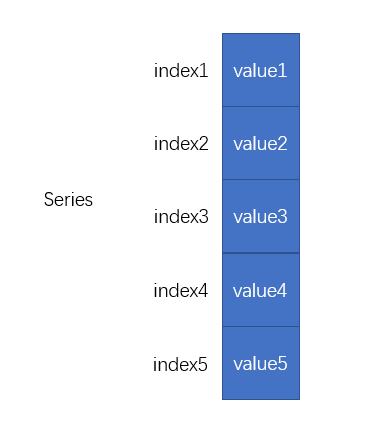
那么對它進行索引訪問,回傳結果勢必只有3種情況:
- 目標索引不存在,報錯
- 長度為1,型別為標量
- 長度大于1,型別依然為Series
接下來讓我們舉例說明:
1)按值訪問
我們可以通過s[索引名] 和 .索引名 去訪問,但需要注意的是后者需要保證索引名中不含有空格:
>>> s = pd.Series(np.arange(1,8),index=['a','b','a','a','a','c',' d'])
>>> print(s)
a 1
b 2
a 3
a 4
a 5
c 6
d 7
dtype: int32
>>> print(s[' d'])
7
>>> print(s.' d')
SyntaxError: invalid syntax
所以,接下來我們只介紹s[索引名] 這種方式,因為它具有一定的穩定性:
>>> s = pd.Series(np.arange(1,7),index=['a','b','a','a','a','c'])
>>> s
a 1
b 2
a 3
a 4
a 5
c 6
dtype: int32
>>> try:
>>> res = s['d']
>>> except Exception as e:
>>> Err_Msg = e
>>> Err_Msg
KeyError('d')
# 情況2 回傳結果為標量
2 <class 'numpy.int32'>
>>> res = s['b']
>>> print(res,type(res))
# 情況3 回傳結果為Series
>>> res = s['a']
>>> print(res,type(res))
a 1
a 3
a 4
a 5
dtype: int32 <class 'pandas.core.series.Series'>
我們可以看到,由于Series的index的值并無唯一性,所以按值訪問Series有可能得到不止一行的回傳結果,
更進一步,我們可以按值對Series進行組合訪問:
>>> res = s[['b','c']]
>>> print(res,type(res))
b 2
c 6
dtype: int32 <class 'pandas.core.series.Series'>
另外,還有一種訪問方法可以取出兩個值之間的資料:
>>> res = s['b':'c':2]
>>> print(res,type(res))
b 2
a 4
c 6
dtype: int32 <class 'pandas.core.series.Series'>
注意這里的索引值在無序狀態下要保持唯一性,否則:
>>> try:
>>> res = s['a':'c':2]
>>> except Exception as e:
>>> Err_Msg = e
>>> Err_Msg
KeyError("Cannot get left slice bound for non-unique label: 'a'")
如果不保證唯一性,但仍想正常訪問,要提前使用sort_index()對index進行排序:
>>> s.sort_index()['a':'c':2]
a 1
a 4
b 2
dtype: int32
另外需要注意的點是這種方式包含左右兩端,且start點訪問的是第一個出現的,end點訪問的是最后一個出現的,如:
>>> s = pd.Series(np.arange(1,7),index=['a','b','a','a','a','b'])
>>> s.sort_index()['a':'b']
a 1
a 3
a 4
a 5
b 2
b 6
dtype: int32
2)按位置訪問
按位置訪問其實和Python原生語法中對list陣列的訪問類似,這里只舉幾個例子:
>>> s = pd.Series(np.arange(1,7),index=['a','b','a','a','a','c'])
>>> s[0]
1
>>> s[[0,2]]
a 1
a 3
dtype: int32
>>> s[0:3]
a 1
b 2
a 3
dtype: int32
我們可以看到按位置訪問與按值訪問不同,是“一個蘿卜一個坑”,即輸入的索引數量和輸出的資料數量保持等比例,
注意,上面兩種訪問方式不能同時使用:
>>> s[['b',2]]

2.DataFrame的列索引
再考慮DataFrame型別的資料,對于一個包含shape為(5,5)ndarray型別的DataFrame資料,其直觀表現形式如下:

對它進行索引訪問,回傳結果也只有3種情況:
- 目標索引不存在,報錯
- 長度為1,型別為Series
- 長度大于1,型別依然為DataFrame
對于DataFrame的列索引,以.data/learn_pandas.csv為目標資料舉例說明:
>>> df = pd.read_csv('data/learn_pandas.csv',usecols=['School', 'Grade', 'Name', 'Gender', 'Weight', 'Transfer'])
>>> df
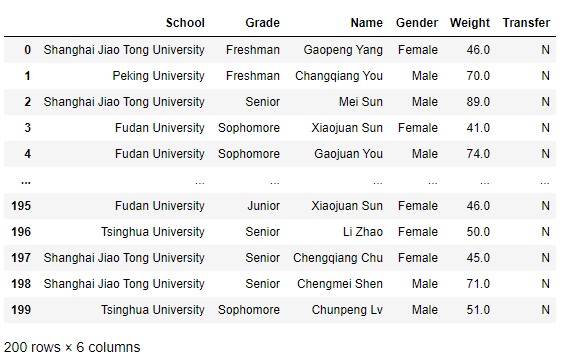
下面兩種訪問方式是等價的:
>>> res = df['School'].head(3)
>>> print(res,type(res))
0 Shanghai Jiao Tong University
1 Peking University
2 Shanghai Jiao Tong University
Name: School, dtype: object <class 'pandas.core.series.Series'>
>>> res = df.School.head(3)
>>> print(res,type(res))
0 Shanghai Jiao Tong University
1 Peking University
2 Shanghai Jiao Tong University
Name: School, dtype: object <class 'pandas.core.series.Series'>
但是對于列名中含有空格的列,與Series訪問一致,只能通過s[列名] 去訪問:
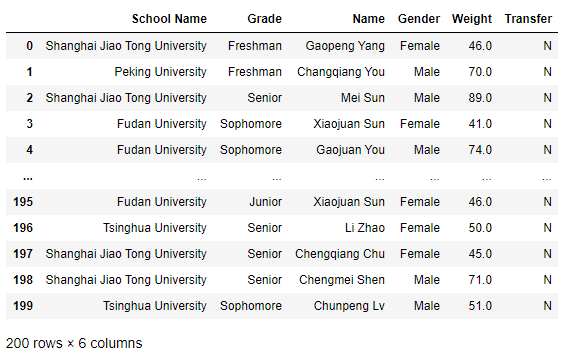
我們偷偷進入資料檔案中,把列名School改成School Name,保存后進行訪問:
>>> df.'School Name'
SyntaxError: invalid syntax
>>> df.School Name
SyntaxError: invalid syntax
>>> df['School Name'].head()
0 Shanghai Jiao Tong University
1 Peking University
2 Shanghai Jiao Tong University
3 Fudan University
4 Fudan University
Name: School Name, dtype: object
只有第三種方式可以,驗證完之后我們再偷偷把School Name改回School,
另外,我們仍然可以通過列名組合去訪問多個列:
>>> print(df[['School','Gender']].head(3))
School Gender
0 Shanghai Jiao Tong University Female
1 Peking University Male
2 Shanghai Jiao Tong University Male
但DataFrame資料不能按位置去訪問:
>>> df[0]
KeyError: 0
簡單說一下我的理解:
#列印前兩行的nd型別資料
>>> df.head(2).values
array([['Shanghai Jiao Tong University', 'Freshman', 'Gaopeng Yang',
'Female', 46.0, 'N'],
['Peking University', 'Freshman', 'Changqiang You', 'Male', 70.0,
'N']], dtype=object)
那是由于DataFrame和Series的值都是ndarray型別陣列,在一維的情況下,我們可以把Series資料想象成一維陣列,按位置訪問即可回傳標量,但在二維情況下,每一條資料與列不匹配,它代表的是由每個列屬性組成的單條行資料,因此df[0]如果真的生效,訪問的也與列無關,是單行資料,但是我們可以通過自定義方法按列的位置拿到資料:
>>> def getCol(data,i):
>>> return pd.Series(data.values[:,i])
>>> print(getCol(df,0).head(3))
0 Shanghai Jiao Tong University
1 Peking University
2 Shanghai Jiao Tong University
dtype: object
即利用numpy特性取出對應列的nd資料,然后再封成pandas資料型別,
3.loc索引器
loc索引器能提供更方便的索引訪問,我們依然用DataFrame資料作為案例使用,我們事先先把Name列設定為行索引方便舉例:
>>> df.set_index('Name',inplace=True)
>>> df.head(3)
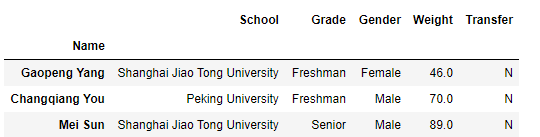
loc的使用方法大致分為五種情況:
#情況1 訪問單個行索引 下面的寫法是等價的 只給出一次列印
>>> print(df.loc['Mei Sun'])
>>> print(df.loc['Mei Sun',:])
School Grade Gender Weight Transfer
Name
Mei Sun Shanghai Jiao Tong University Senior Male 89.0 N
Mei Sun Shanghai Jiao Tong University Junior Female 50.0 N
#情況2 訪問多個行索引
>>> print(df.loc[['Mei Sun','Li Zhao']])
>>> print(df.loc[['Mei Sun','Li Zhao'],:])
School Grade Gender Weight Transfer
Name
Mei Sun Shanghai Jiao Tong University Senior Male 89.0 N
Mei Sun Shanghai Jiao Tong University Junior Female 50.0 N
Li Zhao Tsinghua University Senior Female 50.0 N
#情況3 切片訪問
>>> print(df.loc['Gaojuan You':'Gaoqiang Qian','Grade':'Transfer'])
Grade Gender Weight Transfer
Name
Gaojuan You Sophomore Male 74.0 N
Xiaoli Qian Freshman Female 51.0 N
Qiang Chu Freshman Female 52.0 N
Gaoqiang Qian Junior Female 50.0 N
#情況4 通過布爾串列訪問
>>> print(df.loc[df.Gender == 'Male'].head(3))
School Grade Gender Weight Transfer
Name
Changqiang You Peking University Freshman Male 70.0 N
Mei Sun Shanghai Jiao Tong University Senior Male 89.0 N
Gaojuan You Fudan University Sophomore Male 74.0 N
#情況5 通過函式訪問
>>> def condition(x):
>>> condition_1 = x.Gender == 'Female'
>>> condition_2 = x.Grade == 'Freshman'
>>> return condition_1 & condition_2
>>> print(df.loc[condition].head(3))
School Grade Gender Weight Transfer
Name
Gaopeng Yang Shanghai Jiao Tong University Freshman Female 46.0 N
Xiaoli Qian Tsinghua University Freshman Female 51.0 N
Qiang Chu Shanghai Jiao Tong University Freshman Female 52.0 N
注意在前三種情況中,loc的形式為loc[A,B],其中A表示行索引,B表示列索引(可不顯式指出),且A和B均可使用[,]、[:]方式進行組合和切片訪問,
在第四種情況中,其實loc[A]中的A為一個dtype為布爾型別的Series資料,
而在第五種情況中,函式的入參其實代表整個DataFrame資料,
練一練
使用select_dtypes()方法:
>>> df.select_dtypes('number').head()
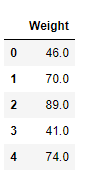
4.iloc索引器
iloc索引器的用法基本上和loc索引器的用法保持一致,不同的是iloc[A,B]中A和B是由位置而不是值構成的:
#情況1 訪問單行單列
>>> print(df.iloc[1,0])
Peking University
#情況2 訪問多行多列
>>> print(df.iloc[[0,1],[1,2]])
Grade Gender
Name
Gaopeng Yang Freshman Female
Changqiang You Freshman Male
#情況3 利用切片訪問多行多列
>>> print(df.iloc[0:2,1:3])
Grade Gender
Name
Gaopeng Yang Freshman Female
Changqiang You Freshman Male
#情況4 利用布爾串列訪問
>>> print(df.iloc[(df.Gender == 'Female').values].tail(3))
School Grade Gender Weight Transfer
Name
Xiaojuan Sun Fudan University Junior Female 46.0 N
Li Zhao Tsinghua University Senior Female 50.0 N
Chengqiang Chu Shanghai Jiao Tong University Senior Female 45.0 N
#情況5 通過函式訪問
>>> def condition(x):
>>> condition_1 = x.Gender == 'Female'
>>> condition_2 = x.Grade == 'Freshman'
>>> return (condition_1 & condition_2).values
>>> print(df.loc[condition].head(3))
School Grade Gender Weight Transfer
Name
Gaopeng Yang Shanghai Jiao Tong University Freshman Female 46.0 N
Xiaoli Qian Tsinghua University Freshman Female 51.0 N
Qiang Chu Shanghai Jiao Tong University Freshman Female 52.0 N
可以看到,iloc的用法與loc大體相同,這里注意情況4和情況5,回傳的Series型別要通過.values轉為nd型別才可以正常使用,
5.query方法
query方法的使用類似于資料庫SQL陳述句,對于列名,我們無需在前面加上DataFrame的變數名,而是直接寫出即可訪問,舉例:
# 例1 獲得清華女生的資訊
>>> query1 = '((School == "Tsinghua University") & (Gender == "Female"))'
>>> print(df.query(query1).head(3))
School Grade Gender Weight Transfer
Name
Xiaoli Qian Tsinghua University Freshman Female 51.0 N
Gaoqiang Qian Tsinghua University Junior Female 50.0 N
Changli Zhang Tsinghua University Freshman Female 48.0 N
#例2 在引數中直接呼叫Series方法:獲取體重最輕的學生資訊
>>> query2 = 'Weight == Weight.min()'
>>> print(df.query(query2).head(3))
School Grade Gender Weight Transfer
Name
Gaomei Lv Fudan University Senior Female 34.0 N
Peng Han Peking University Sophomore Female 34.0 NaN
Xiaoli Chu Shanghai Jiao Tong University Junior Female 34.0 N
#例3 參考外部變數
>>> low, high =60, 70
>>> print(df.query('Weight.between(@low, @high)').head(3))
School Grade Gender Weight Transfer
Name
Changqiang You Peking University Freshman Male 70.0 N
Xiaoqiang Qin Tsinghua University Junior Male 68.0 N
Peng Wang Tsinghua University Junior Male 65.0 N
這里注意條件判斷之間要用括號括起來,在陳述句中可以直接呼叫Series的方法,
6.隨機抽樣
sample方法可以對資料進行抽樣,以Series資料為例:
>>> s = pd.Series(np.arange(1,7),index=['a','b','a','a','a','c'])
>>> p = [0.1,0.2,0.1,0.1,0.2,0.3]
>>> s.sample(3, replace = True, weights = p)
b 2
c 6
b 2
dtype: int32
其中3表示抽樣次數,replace表示每次抽完是否放回,weights表示每個樣本抽中的概率,
二、多級索引
1.多級索引結構及其相應屬性
多級索引,顧名思義,就是指行索引或列索引不止一層,
首先利用剛才的學生資料集構造多級索引:
>>> np.random.seed(20201222)
>>> multi_index = pd.MultiIndex.from_product([list('ABC'), df.Gender.unique()], names=('School', 'Gender'))
>>> multi_column = pd.MultiIndex.from_product([['Height', 'Weight'], df.Grade.unique()], names=('Indicator', 'Grade'))
>>> df_multi = pd.DataFrame(np.c_[(np.random.randn(6,4)*5 + 163).tolist(), (np.random.randn(6,4)*5 + 65).tolist()],
index = multi_index, columns = multi_column).round(1)
>>> df_multi
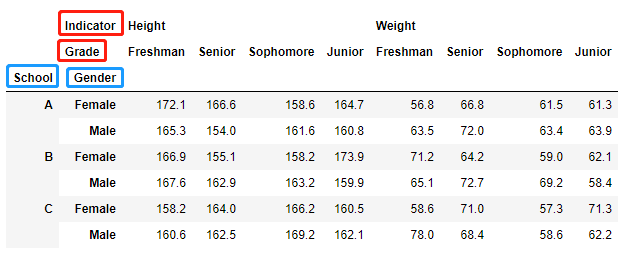
我們可以看到,列印出的表格中增加了索引層數,而且還多了索引的名,紅色框表示列索引的名字,藍色框表示行索引的名字,我們利用代碼訪問一下試試:
#行索引相關屬性
>>> print(df_multi.index)
MultiIndex([('A', 'Female'),
('A', 'Male'),
('B', 'Female'),
('B', 'Male'),
('C', 'Female'),
('C', 'Male')],
names=['School', 'Gender'])
>>> print(df_multi.index.names)
['School', 'Gender']
>>> print(df_multi.index.values)
[('A', 'Female') ('A', 'Male') ('B', 'Female') ('B', 'Male')
('C', 'Female') ('C', 'Male')]
#列索引相關屬性
>>> print(df_multi.columns)
MultiIndex([('Height', 'Freshman'),
('Height', 'Senior'),
('Height', 'Sophomore'),
('Height', 'Junior'),
('Weight', 'Freshman'),
('Weight', 'Senior'),
('Weight', 'Sophomore'),
('Weight', 'Junior')],
names=['Indicator', 'Grade'])
>>> print(df_multi.columns.names)
['Indicator', 'Grade']
>>> print(df_multi.columns.values)
[('Height', 'Freshman') ('Height', 'Senior') ('Height', 'Sophomore')
('Height', 'Junior') ('Weight', 'Freshman') ('Weight', 'Senior')
('Weight', 'Sophomore') ('Weight', 'Junior')]
#列索引的第二層索引值
print(df_multi.columns.get_level_values(1))
在第三個例子中,我們可以通過columns.get_level_values()方法去訪問指定層的索引值,
2.loc索引器在多級索引中的使用
loc索引在多級索引中的使用與單級索引中的使用是有共通性的,我們仍采用上一節的資料舉例說明:
這是訪問單行資料:
>>> df_multi.loc[('A','Female')]
Indicator Grade
Height Freshman 172.1
Senior 166.6
Sophomore 158.6
Junior 164.7
Weight Freshman 56.8
Senior 66.8
Sophomore 61.5
Junior 61.3
Name: (A, Female), dtype: float64
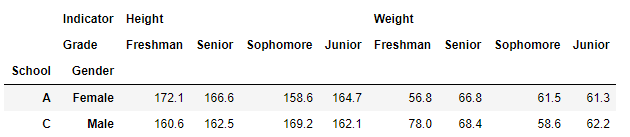
這是訪問多個單資料:
>>> df_multi.loc[[('A','Female'),('C','Male')]]
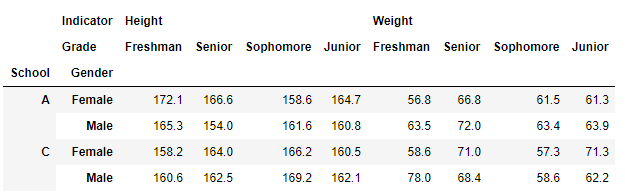
這是訪問指定行+列的資料:
>>> df_multi.loc[['A','C'],['Height','Weight']]
這里通過布爾串列訪問行的操作與單級索引一致,所以不再給出,
3.IndexSlice物件
IndexSlice物件的作用:
- 可以對多層索引每層進行切片
- 允許在loc中將不同型別的訪問方式組合進行使用
主要分為兩種使用方式idx[A,B]型和[idx[A,B],idx[C,D]]型,
怎么理解這兩種型別呢,第一種不能對非第一級以外的行列索引進行區域切片,而第二種可以,
先定義一個擁有多級索引的DF變數:
>>> np.random.seed(20201222)
>>> L1,L2 = ['A','B','C'],['a','b','c']
>>> mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
>>> L3,L4 = ['D','E','F'],['d','e','f']
>>> mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
>>> df_ex = pd.DataFrame(np.random.randint(-9,10,(9,9)), index=mul_index1, columns=mul_index2)
>>> df_ex
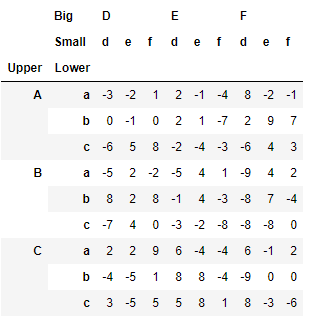
1)idx[A,B]型
>>> idx = pd.IndexSlice
>>> df_ex.loc[idx['B':,('E','e'):]]
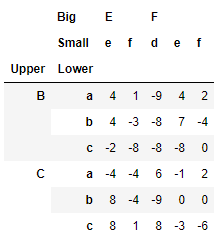
引數中的A在這里指的是‘B’:,它表示行索引從B開始一直到結尾;引數中的B在這里指的是('E','e'):,他表示從列索引(E,e)開始一直到結尾,
注意這里就不能針對列索引的第二級進行區域切片,比如只取第二例的e和f,解決這種問題的方式是第二種型別,
2)[idx[A,B],idx[C,D]]型
df_ex.loc[idx[:'B','b':],idx['E':,'e':]]

引數中的A在這里指的是:'B',它表示行索引的第一層從開始一直到B;引數中的B在這里指的是'b':,他表示行索引的第二層從b開始到第二層的結尾;引數中的C在這里指的是'E':,它表示列索引的第一層從E一直到結尾;引數中的D在這里指的是'e':,他表示列索引的第二層從e開始到第二層的結尾,
可以看到,利用這種方式就可以針對第二級的列索引進行單獨的區域切片,更多例子請看本章習題2-3,
4.多級索引的構造
這里的構造用三種方式:
#第一種:利用元組串列進行構建
>>> index_names = ['First','Second']
>>> data_tuple = [('A','a'),('A','b'),('B','a'),('B','b')]
>>> idx = pd.MultiIndex.from_tuples(data_tuple,names=index_names)
>>> print(idx)
MultiIndex([('A', 'a'),
('A', 'b'),
('B', 'a'),
('B', 'b')],
names=['First', 'Second'])
#第二種:利用雙層串列進行構建
>>> data_list = [list('abcd'),list('ABCD')]
>>> idx = pd.MultiIndex.from_arrays(data_list,names=index_names)
>>> print(idx)
MultiIndex([('a', 'A'),
('b', 'B'),
('c', 'C'),
('d', 'D')],
names=['First', 'Second'])
#第三種:利用多個串列的交叉組合進行構建
>>> idx = pd.MultiIndex.from_product([['A','B'],['a','b']],names=index_names)
>>> print(idx)
MultiIndex([('A', 'a'),
('A', 'b'),
('B', 'a'),
('B', 'b')],
names=['First', 'Second'])
三、索引的常用方法
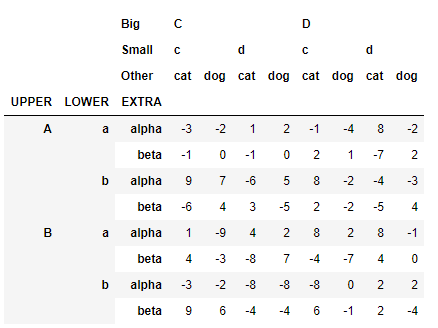
首先先構造一個多級索引的表:
>>> np.random.seed(20201222)
>>> L1,L2,L3 = ['A','B'],['a','b'],['alpha','beta']
>>> mul_index1 = pd.MultiIndex.from_product([L1,L2,L3], names=('Upper', 'Lower','Extra'))
>>> L4,L5,L6 = ['C','D'],['c','d'],['cat','dog']
>>> mul_index2 = pd.MultiIndex.from_product([L4,L5,L6], names=('Big', 'Small', 'Other'))
>>> df_ex = pd.DataFrame(np.random.randint(-9,10,(8,8)), index=mul_index1, columns=mul_index2)
>>> df_ex
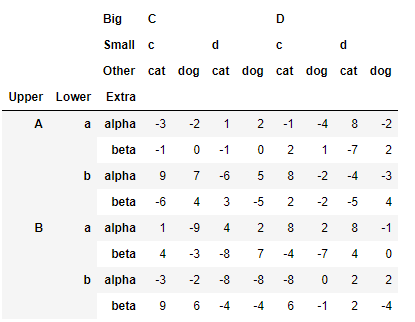
1.索引層的交換和洗掉
針對行索引,進行不同層的交換:
>>> df_ex.swaplevel(1,2,axis=0)
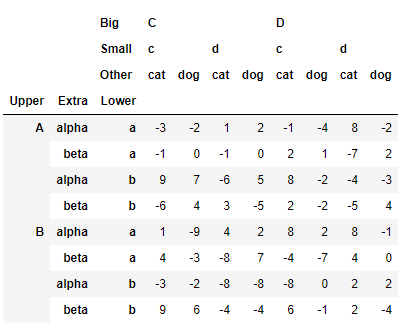
這里采用swaplevel()方法進行交換,前面兩個引數表示需要交換的層數,以最外層為0,axis代表需要交換的軸,0代表行,1代表列,
但是這種方法只能交換2層,如果想要交換多層可以使用reorder_levels()方法:
>>> df_ex.reorder_levels([2,1,0],axis=1)
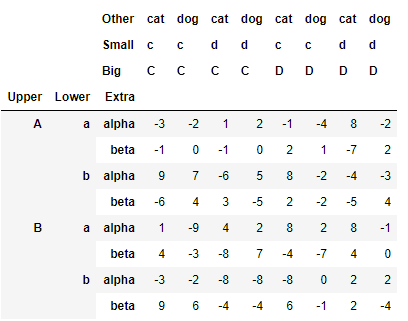
這里只講第一個引數,對于三層來說原始的層排列是[0,1,2],第一個引數的作用是用來指定目標層的排列,比如例子里的[2,1,0]就是指將列索引的不同層顛倒過來,
我們也可以洗掉行或列索引中指定的某層索引:
>>> df_ex.droplevel(1,axis=0)
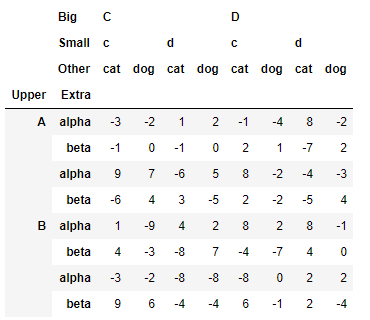
2.索引屬性的修改
我們可以通過rename_axis和rename修改索引的名和值:
>>> df_ex.rename_axis(index={'Upper':'upper'}, columns={'Other':'other'})
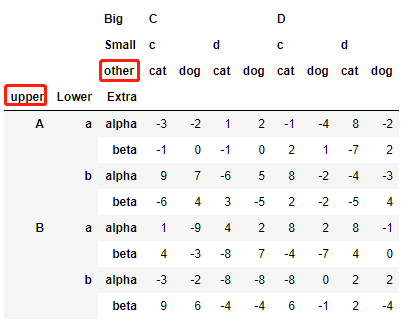
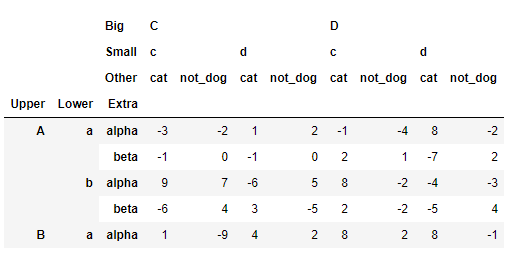
>>> df_ex.rename(columns={'dog':'not_dog'}, level=2).head()
練一練
利用rename_axis結合匿名函式對索引層的名字進行修改:
>>> df_ex.rename_axis(index=lambda x:str.upper(x))
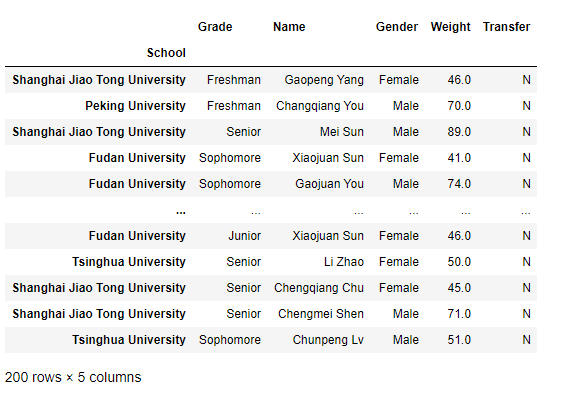
3.索引的設定與重置
>>> df = pd.read_csv('data/learn_pandas.csv',usecols=['School', 'Grade', 'Name', 'Gender', 'Weight', 'Transfer'])
>>> df.set_index('School')
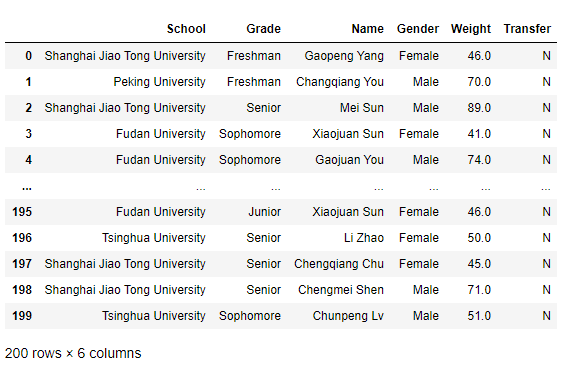
>>> df.set_index('School').reset_index()
4.索引的變形
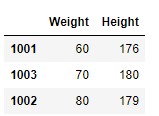
新建一個用于演示的DF資料:
>>> df_reindex = pd.DataFrame({"Weight":[60,70,80], "Height":[176,180,179]}, index=['1001','1003','1002'])
>>> df_reindex
>>> df_reindex.reindex(index=['1001','1002','1003','2020'], columns=['Weight','School'])
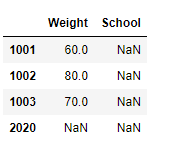
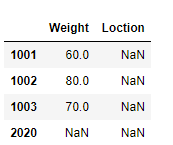
>>> df_existed = pd.DataFrame(index=['1001','1002','1003','2020'], columns=['Weight','Loction'])
>>> df_reindex.reindex_like(df_existed)
四、索引運算
>>> df_set_1 = pd.DataFrame([[0,1],[1,2],[3,4]], index = pd.Index(['a','b','a'],name='id1'))
>>> df_set_2 = pd.DataFrame([[5,1],[6,2],[3,4]], index = pd.Index(['a','c','d'],name='id2'))
>>> id1, id2 = df_set_1.index.unique(), df_set_2.index.unique()
>>> print(id1.intersection(id2))
Index(['a'], dtype='object')
>>> print(id1.union(id2))
Index(['a', 'b', 'c', 'd'], dtype='object')
>>> print(id1.difference(id2))
Index(['b'], dtype='object')
>>> print(id1.symmetric_difference(id2))
Index(['b', 'c', 'd'], dtype='object')
分別表示交集、并集、差集、并集減去交集
練習
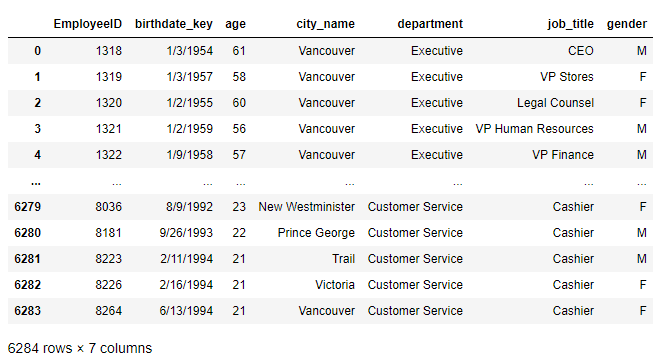
Ex-1 公司員工資料集
>>> df = pd.read_csv('data/company.csv')
df
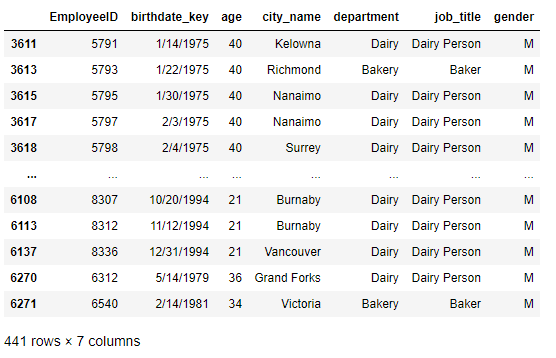
Ex-1-1 多條件篩選
#EX1-1:
#解法1
>>> df.query('age <= 40 and (department == "Dairy" or department == "Bakery") and gender == "M"')
#解法2
>>> def condition(x):
>>> condition_1 = x.age <= 40
>>> condition_2 = x.department.isin(['Dairy','Bakery'])
>>> condition_3 = x.gender == 'M'
>>> return condition_1 & condition_2 & condition_3
>>> df.loc[condition]
#解法3
>>> df.loc[(df.age <= 40) & (df.gender == 'M') & (df.department.isin(['Dairy','Bakery']))]
思路:三種方法大同小異,分別利用了query和loc陳述句對條件進行組合,
Ex-1-2 多行多列篩選
#利用iloc索引
>>> df[df.EmployeeID%2!=0].iloc[[0,1,-2]]

檢查的時候發現理解錯了題意,應該是奇數行+3列,我理解成了只對行進行篩選,
改,利用IndexSlice同時進行布爾判斷和按值切片訪問:
>>> idx = pd.IndexSlice
>>> df.loc[idx[df.EmployeeID%2!=0,'department':]]
#等價寫法
>>> df.loc[idx[lambda x:x.EmployeeID %2 !=0,'department':]]
思路:利用IndexSlice物件將索引的布爾串列和切片訪問進行合并,利用的第一種idx[A:B]的形式,
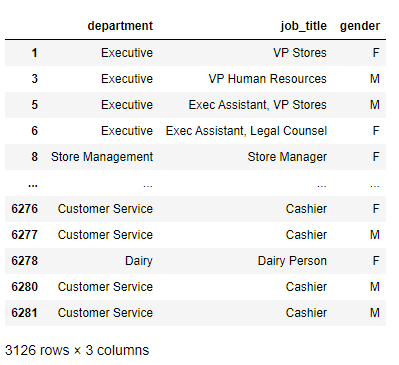
Ex-1-3-1 后三列設為索引后交換內外兩層
#EX1-3-1:
#獲取所有列名,之后有用
>>> column_names = df.columns.values
>>> a = list(column_names[-3:])
#設定索引
>>> df.set_index(a,inplace=True)
>>> df.swaplevel(0,2,axis=0)
>>> df
思路:利用column_names變數獲取所有列名,型別為nd型別,然后通過set_index()方法利用list切片將后三列設定為index,最后利用swaplevel()方法交換行索引的內外兩層,
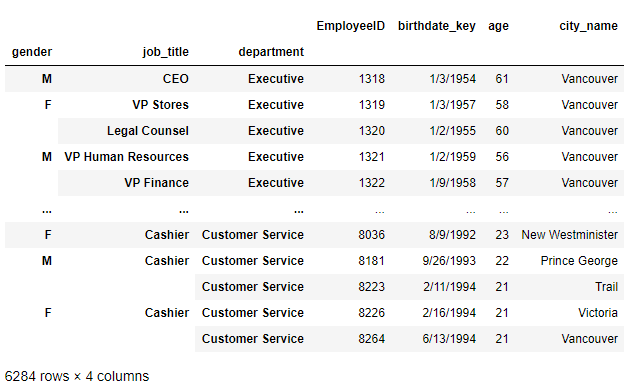
Ex-1-3-2 恢復行索引的中間層
>>> df.reset_index(column_names[-2],inplace=True)
>>> df
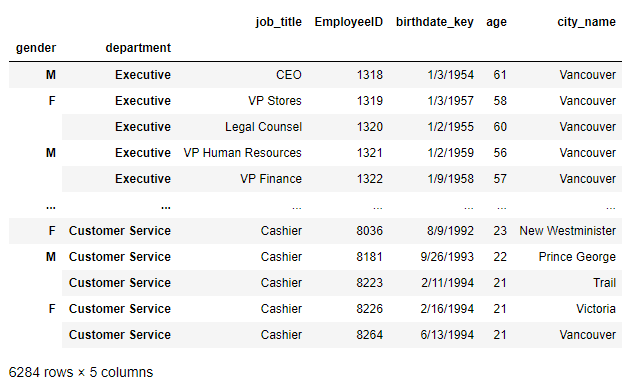
思路:利用reset_index()方法配合之前的column_names變數進行恢復索引操作,
Ex-1-3-3 修改索引名
>>> df.rename_axis(index = {column_names[-1]:'Gender'},inplace = True)
>>> df
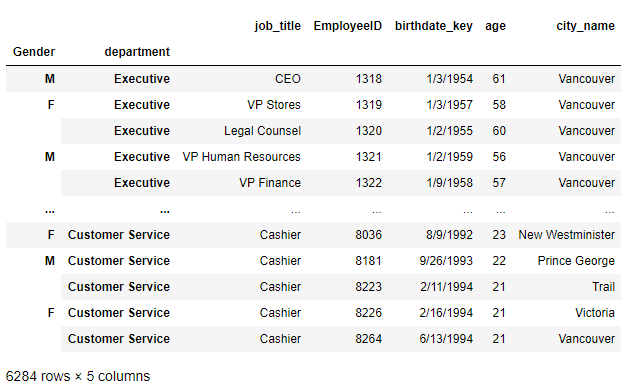
思路:利用rename_axis()方法配合之前的column_names變數修改行索引的名,
Ex-1-3-4 合并索引
>>> new_idx= df.index.map(lambda x:x[0]+'_'+x[1])
>>> df.index = new_idx
>>> df
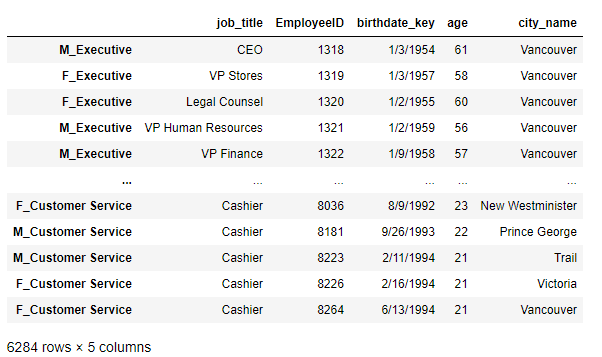
思路:利用map操作合并DF資料的行索引資訊,并且重新設定,(取-改-存)
Ex-1-3-5 索引拆分
>>> new_idx = df.index.map(lambda x:tuple(x.split('_')))
>>> df.index = new_idx
>>> df
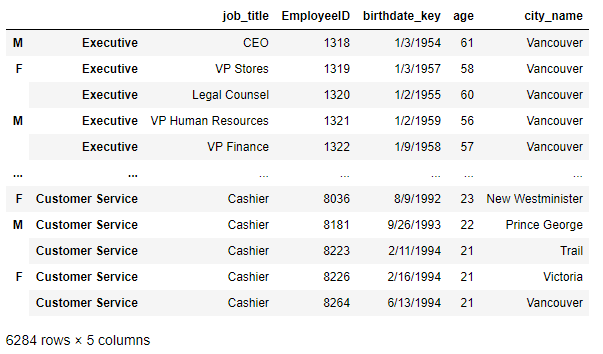
思路:上一題的逆操作,依然通過map操作生成,
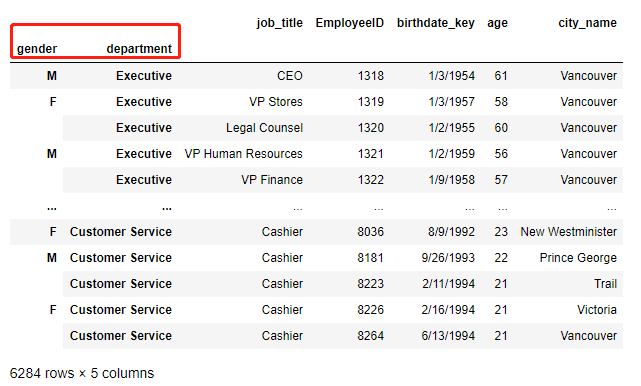
Ex-1-3-6 修改索引的名
>>> df.rename_axis([column_names[-1],column_names[-3]],inplace = True)
>>> df
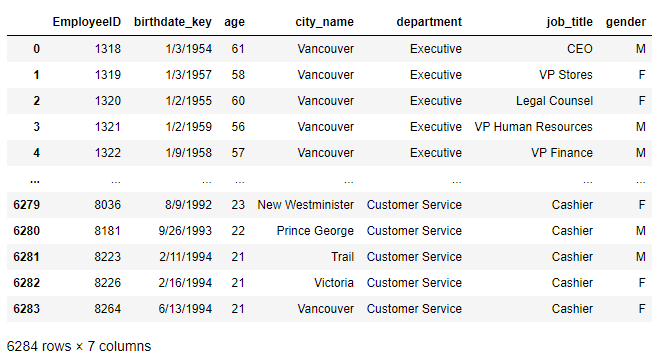
Ex-1-3-7 恢復默認索引并恢復列的相對位置
#去掉所有index 恢復默認
>>> df = df.reset_index()
#重新按原順序將列排序
>>> df = df[column_names]
>>> df
Ex-2 巧克力資料集
>>> df = pd.read_csv('data/chocolate.csv')
>>> df
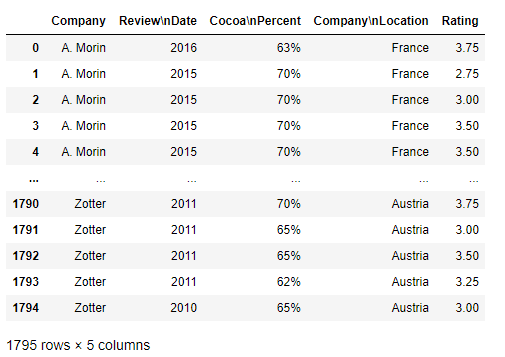
Ex-2-1 索引名修改
>>> df = df.rename(lambda x:x.replace('\n',' '),axis=1)
>>> df
#另一種表達形式
>>> df = df.rename(columns=lambda x:x.replace('\n',' '))
>>> df
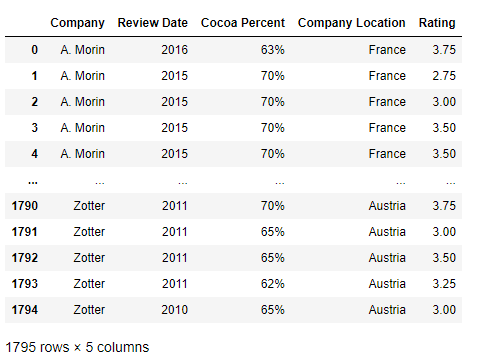
思路:通過rename()方法內嵌lambda運算式進行修改,可以使用columns或axis引數指定目標為列索引,
Ex-2-2 列索引訪問
#對Cocoa Percent列進行處理 轉換成float型 注意apply方法無inplace引數 只能重新賦值
>>> df['Cocoa Percent'] = df['Cocoa Percent'].apply(lambda x:float(x[:-1]))
#對Review Date列進行處理 轉換成int型
>>> df['Review Date'] = df['Review Date'].apply(lambda x:int(x))
#提取出日期和公司位置的無重復資料
>>> dates = df['Review Date'].unique()
>>> company_locs = df['Company Location'].unique()
#求出Cocoa Percent中位數
>>> median = df['Cocoa Percent'].median()
#解法1
>>> res = df.loc[(df.Rating <= 2.75) & (df['Cocoa Percent'] > median)]
>>> res
#解法2
>>> def condition(x):
>>> condition_1 = x.Rating <= 2.75
>>> condition_2 = x['Cocoa Percent'] > median
>>> return condition_1 & condition_2
>>> res = df.loc[condition]
>>> res
#解法3
>>> res = df.query('(Rating <= 2.75) and (`Cocoa Percent` > `Cocoa Percent`.median())')
>>> res
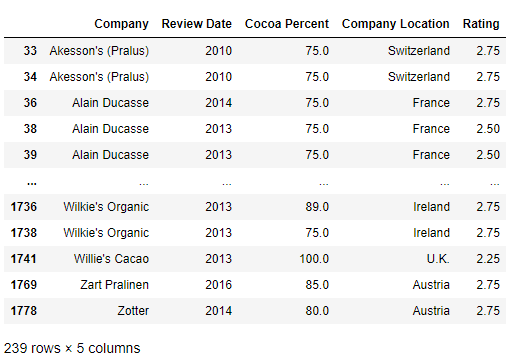
思路:跟公司員工資料集類似,對于這種按條件訪問列的要求,基本上可以從loc和query兩個角度入手,首先先把Cocoa Percent列的資料轉成float型,然后進行組合訪問,注意在query中對于有空格的列名需要通過``去訪問:
Ex-2-3 行索引按層訪問
#nd型別資料 先設定index
>>> column_names = df.columns.values
>>> column_names
>>> df.set_index([column_names[1],column_names[-2]],inplace = True)
>>> df
解法1
#condition_1
>>> dates = [x for x in dates if x>=2012]
##condition_2
>>> companys_locs = [x for x in company_locs if x not in ['France','Canada','Amsterdam','Belgium']]
>>> df = df.sort_index()
>>> df.loc[(dates,companys_locs),:]
思路:通過構造dates和companys_locs兩個list對行索引的交叉組合,然后利用loc方法進行訪問,
解法2
>>> df = df.sort_index()
>>> mask = ['France','Canada','Amsterdam','Belgium']
>>> df.loc[idx[2012:,~np.isin(df.index.get_level_values(1),mask)],:]
思路:利用IndexSlice的第二種使用方法,目標問題化簡為對行索引的多級索引按條件訪問,第一級A很簡單在排序之后進行按值訪問中的切片訪問:2012:;第二級B的最終目標是回傳一個布爾串列,表示不在指定的4個國家(存到mask中),首先通過df.index.get_level_values(1)拿到行索引的第二級索引,然后利用numpy.isin()方法判斷它的每個元素是否存在于mask,最后取反,這里需要注意的是在loc[A:B]中B一定要設定成:,否則系統會誤把此處的idx當做IndexSlice的第一種使用方式,將A和B分別當做對行索引和列索引的條件訪問,
參考文獻
1.解決多重索參考loc出現PerformanceWarning: indexing past lexsort depth may impact performance警告
https://blog.csdn.net/qq_42006613/article/details/110077118
2.熊貓:使用帶有MultiIndex的.loc進行條件選擇
https://www.pythonheidong.com/blog/article/185156/43558ae121564c9ce308/
3.pandas學習之df.rename()
https://blog.csdn.net/lisnyuan/article/details/106802431
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/239697.html
標籤:python
上一篇:Logistic模型原理詳解以及Python專案實作
下一篇:這樣寫為什么第二次輸入時就很奇怪