這篇文章寫得很冗余,但是我相信你如果真的看完,并且按照我的代碼和邏輯進行分析,對您以后的資料預處理和命名物體識別都有幫助,只有真正對這些復雜的文本進行NLP處理后,您才能適應更多的真實環境,堅持!畢竟我寫的時候也看了20多小時的視頻,又寫了20多個小時,別抱怨,加油~
本專欄主要結合作者之前的博客、AI經驗和相關視頻及論文介紹,后面隨著深入會講解更多的Python人工智能案例及應用,基礎性文章,希望對您有所幫助,如果文章中存在錯誤或不足之處,還請海涵~作者作為人工智能的菜鳥,希望大家能與我在這一筆一劃的博客中成長起來,寫了這么多年博客,嘗試第一個付費專欄,但更多博客尤其基礎性文章,還是會繼續免費分享,但該專欄也會用心撰寫,望對得起讀者,共勉!
- Keras下載地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下載地址:https://github.com/eastmountyxz/AI-for-TensorFlow
文章目錄
- 一.什么是命名物體識別
- 二.資料集描述
- 三.資料預處理
- 1.提取識別類別
- 2.物體標記編碼轉換
- 3.文本分割
- 4.長短句處理
- 四.物體標記自動化處理
- 1.分割句子對應的標簽字典生成
- 2.提取詞性和詞邊界
- 3.獲取拼音特征
- 4.按字標記及資料存盤
- 5.多文本處理
- 五.完整代碼
- 1.data_process.py
- 2.prepare_data.py
- 六.總結
同時推薦前面作者另外五個Python系列文章,從2014年開始,作者主要寫了三個Python系列文章,分別是基礎知識、網路爬蟲和資料分析,2018年陸續增加了Python影像識別和Python人工智能專欄,
- Python基礎知識系列:Python基礎知識學習與提升
- Python網路爬蟲系列:Python爬蟲之Selenium+BeautifulSoup+Requests
- Python資料分析系列:知識圖譜、web資料挖掘及NLP
- Python影像識別系列:Python影像處理及影像識別
- Python人工智能系列:Python人工智能及知識圖譜實戰

前文:
[Python人工智能] 一.TensorFlow2.0環境搭建及神經網路入門
[Python人工智能] 二.TensorFlow基礎及一元直線預測案例
[Python人工智能] 三.TensorFlow基礎之Session、變數、傳入值和激勵函式
[Python人工智能] 四.TensorFlow創建回歸神經網路及Optimizer優化器
[Python人工智能] 五.Tensorboard可視化基本用法及繪制整個神經網路
[Python人工智能] 六.TensorFlow實作分類學習及MNIST手寫體識別案例
[Python人工智能] 七.什么是過擬合及dropout解決神經網路中的過擬合問題
[Python人工智能] 八.卷積神經網路CNN原理詳解及TensorFlow撰寫CNN
[Python人工智能] 九.gensim詞向量Word2Vec安裝及《慶余年》中文短文本相似度計算
[Python人工智能] 十.Tensorflow+Opencv實作CNN自定義影像分類案例及與機器學習KNN影像分類演算法對比
[Python人工智能] 十一.Tensorflow如何保存神經網路引數
[Python人工智能] 十二.回圈神經網路RNN和LSTM原理詳解及TensorFlow撰寫RNN分類案例
[Python人工智能] 十三.如何評價神經網路、loss曲線圖繪制、影像分類案例的F值計算
[Python人工智能] 十四.回圈神經網路LSTM RNN回歸案例之sin曲線預測
[Python人工智能] 十五.無監督學習Autoencoder原理及聚類可視化案例詳解
[Python人工智能] 十六.Keras環境搭建、入門基礎及回歸神經網路案例
[Python人工智能] 十七.Keras搭建分類神經網路及MNIST數字影像案例分析
[Python人工智能] 十八.Keras搭建卷積神經網路及CNN原理詳解
[Python人工智能] 十九.Keras搭建回圈神經網路分類案例及RNN原理詳解
[Python人工智能] 二十.基于Keras+RNN的文本分類vs基于傳統機器學習的文本分類
[Python人工智能] 二十一.Word2Vec+CNN中文文本分類詳解及與機器學習(RF\DTC\SVM\KNN\NB\LR)分類對比
[Python人工智能] 二十二.基于大連理工情感詞典的情感分析和情緒計算
[Python人工智能] 二十三.基于機器學習和TFIDF的情感分類(含詳細的NLP資料清洗)
[Python人工智能] 二十四.易學智能GPU搭建Keras環境實作LSTM惡意URL請求分類
[Python人工智能] 二十六.基于BiLSTM-CRF的醫學命名物體識別研究(上)資料預處理
《人工智能狂潮》讀后感——什么是人工智能?(一)
一.什么是命名物體識別
物體是知識圖譜最重要的組成,命名物體識別(Named Entity Recognition,NER)對于知識圖譜構建具有很重要意義,命名物體是一個詞或短語,它可以在具有相似屬性的一組事物中清楚地標識出某一個事物,命名物體識別(NER)則是指在文本中定位命名物體的邊界并分類到預定義型別集合的程序,
這篇文章將詳細介紹醫學物體識別的程序,其資料預處理極其復雜,但值得大家去學習,下面我們先簡單回顧命名物體的幾個問題,
1.什么是物體?
物體是一個認知概念,指代世界上存在的某個特定事物,物體在文本中通常有不同的表示形式,或者不同的提及方式,命名物體可以理解為有文本標識的物體,物體在文本中的表示形式通常被稱作物體指代(Mention,或者直接被稱為指代),比如周杰倫,在文本中有時被稱作“周董”,有時被稱作“Jay Chou”,因此,物體指代是語言學層面的概念,
2.什么是命名物體識別?
命名物體識別(Named Entity Recognition,NER)就是從一段自然語言文本中找出相關物體,并標注出其位置以及型別,是資訊提取、問答系統、句法分析、機器翻譯等應用領域的重要基礎工具,在自然語言處理技術走向實用化的程序中占有重要地位,包含行業領域專有名詞,如人名、地名、公司名、機構名、日期、時間、疾病名、癥狀名、手術名稱、軟體名稱等,具體可參看如下示例圖:

NER的輸入是一個句子對應的單詞序列 s=<w1,w2,…,wn>,輸出是一個三元集合,其中每個元組形式為<Is,Ie,t>,表示s中的一個命名物體,其中Is和Ie分別表示命名物體在s中的開始和結束位置,而t是物體型別,命名物體識別的作用如下:
- 識別專有名詞,為文本結構化提供支持
- 主體識別,輔助句法分析
- 物體關系抽取,有利于知識推理
3.命名物體識別常用方法
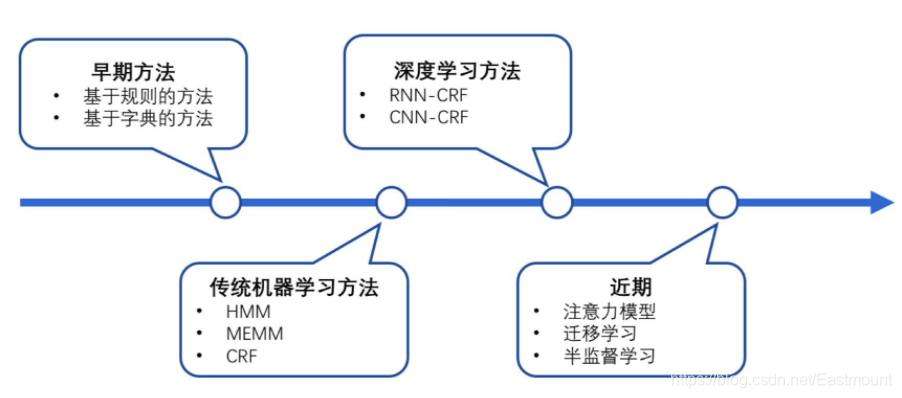
可以根據各種屬性劃分為不同的方法,但劃分大同小異,本文按照下圖劃分為始終類別:
- 早期方法:基于規則的方法、基于字典的方法
- 傳統機器學習方法:HMM、MEMM、CRF
- 深度學習方法:RNN-CRF、CNN-CRF
- 機器方法:注意力模型、遷移學習、半監督學習
4.命名物體識別最新發展
最新的方法是注意力機制、遷移學習和半監督學習,一方面減少資料標注任務,在少量標注情況下仍然能很好地識別物體;另一方面遷移學習(Transfer Learning)旨在將從源域(通常樣本豐富)學到的知識遷移到目標域(通常樣本稀缺)上執行機器學習任務,常見的模型如下:
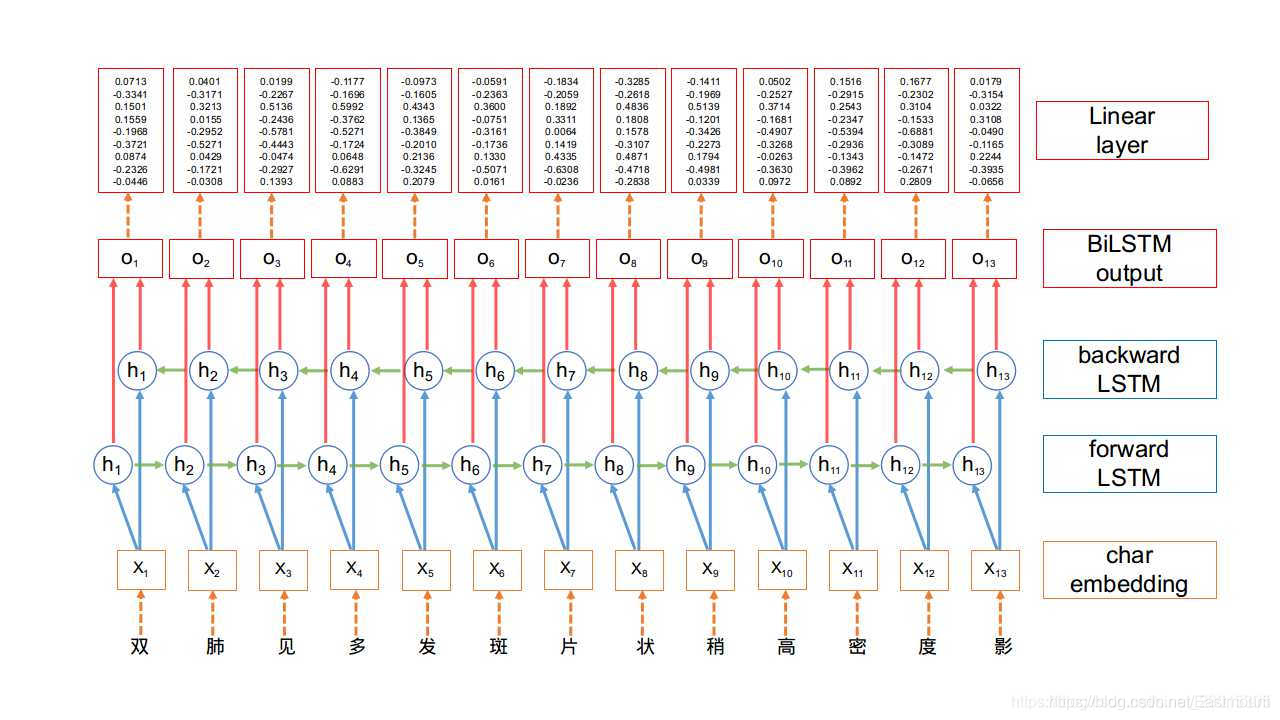
- BiLSTM網路應用于遷移學習
雙向LSTM的網路可以同時捕捉正向資訊和反向資訊,使得對文本資訊的利用更全面,效果也更好,
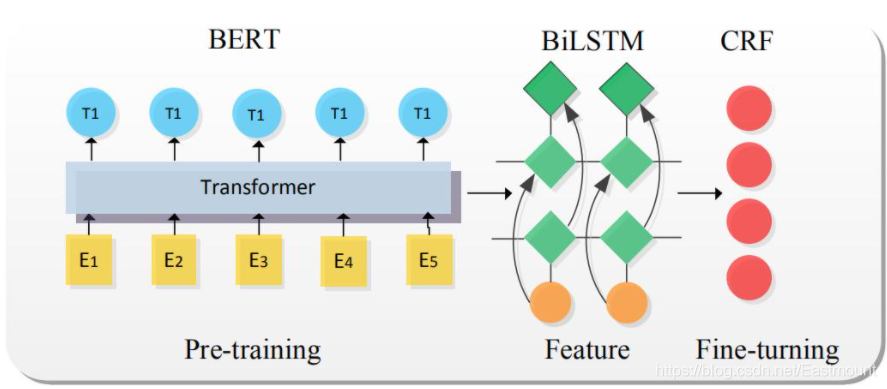
- BERT-BiLSTM-CRF模型
該模型在資料挖掘比賽和論文中很經典,也是非常新的一個模型,值得大家使用,
上面內容參考了肖仰華老師《知識圖譜概念與技術》書籍,以及“閣下和不同風起”朋友的文章,再次感謝,也非常推薦大家去閱讀這位朋友的文章,非常棒,
- NLP在線醫生-BiLSTM+CRF命名物體識別
二.資料集描述
資料集如下圖所示,它由兩個檔案組成
- ann檔案
- txt檔案
我們打開txt檔案,可以看到它們是一些文本,這些文本很多是通過文字識別軟體識別出來的,所以存在一些錯誤,
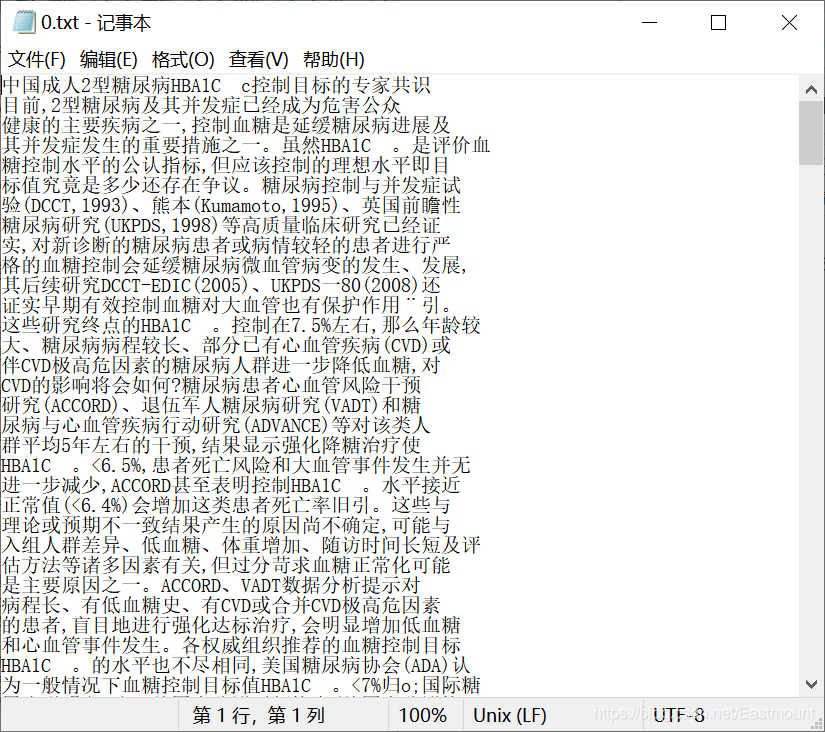
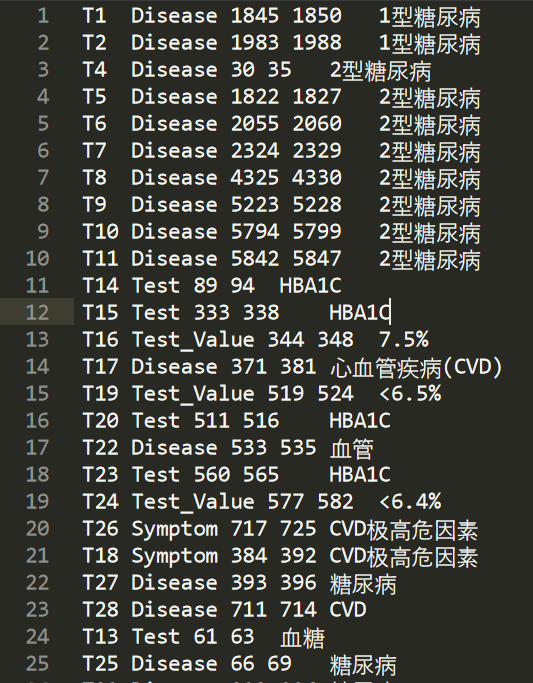
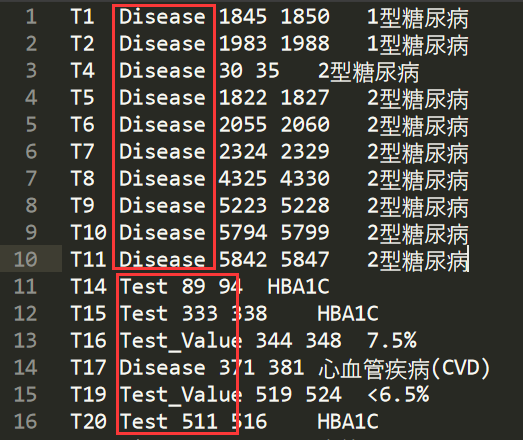
對應的ann檔案如下圖所示,它相當于標注資料,主要用于訓練,包括:
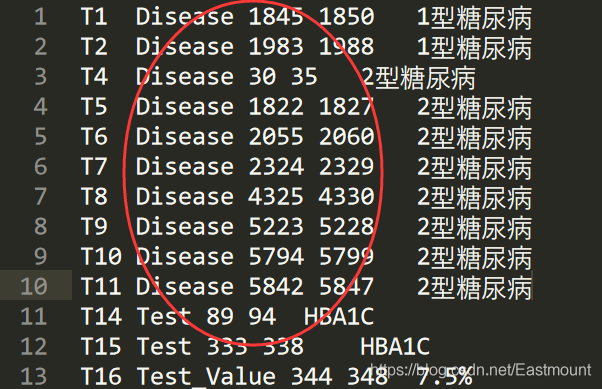
- 標號:T1、T2、T8
- 物體型別:疾病(Disease)、檢測(Test)、檢測值(Test_Value)、癥狀(Symptom)
- 起始位置:30
- 結束位置:35
- 物體內容:2型糖尿病
換句話說,通過專家知識已經將文本中的癥狀、疾病、級別、檢測手段等進行了標注,這些資料也是我們要提取的資訊,接下來我們設計一個模型,通過演算法實作物體識別,而不需要通過專家去標注,
當我們拿到這樣的資料怎么去做呢?
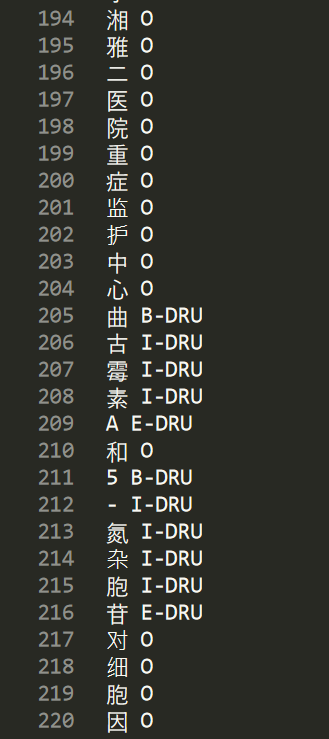
首先我們需要把標簽設計好,通過BIO對每個字打一個標簽(BIO標注),注意,我們不能拿ANN檔案直接去訓練,而需要標注成如下圖所示的模樣,每個字都對應一個標記,這些字相當于可觀測序列,而這些標記是不可觀測的隱狀態序列(隱馬爾可夫模型),
這相當于監督學習,預測的時候就沒有相應標記了,需要演算法自動完成這些標記的預測,所以接下來我們需要想辦法將資料標記成下圖的格式,
- BIO標注法
– B表示物體起始位置,I表示物體中間位置,E表示物體結束位置
– O表示非物體標記
– DRU、ANT、DIS等表示不同型別的標記,比如癥狀、疾病、級別、檢測手段等
三.資料預處理
注意,資料集預處理通常都很枯燥,但需要我們熟悉基本流程,這將為后續的實驗提供良好的基礎,同時,下面的代碼會講解得非常詳細,甚至有些啰嗦,但只希望讀者能學到我撰寫Python代碼的程序,包括除錯、打樁,大神可以直接看最終完整代碼或github的分享,
命名物體識別是企業中常見的任務,資料標注是其基礎,那么,我們怎么才能完成該標注任務呢?
1.提取識別類別
首先,我們需要獲取總共存在多少種物體,
遍歷訓練集檔案夾中所有ANN檔案,統計所有的命名物體種類,下面我們寫代碼完成這部分實驗,
下面的代碼是統計所有物體型別,以及各個型別的物體個數,
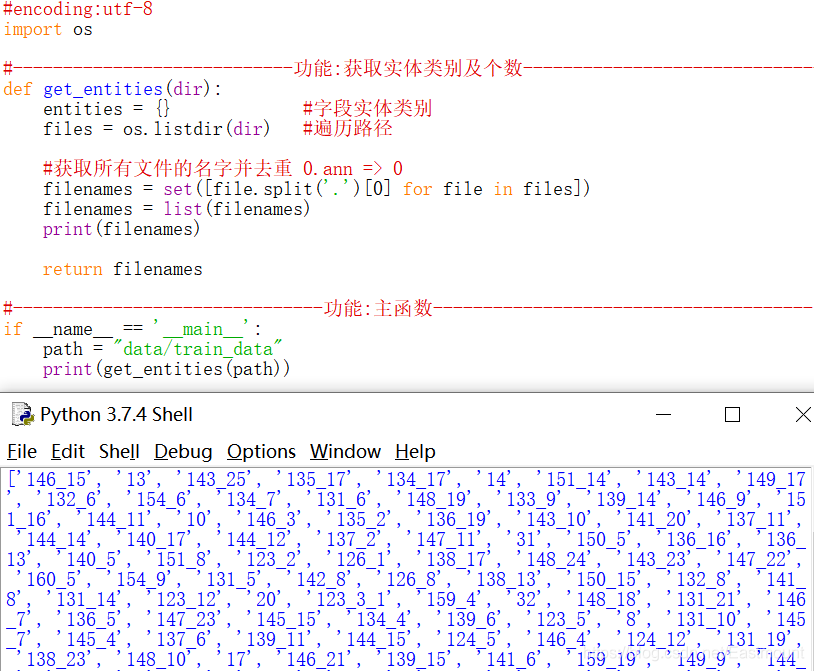
第一步,獲取指定檔案夾的檔案目錄,
#encoding:utf-8
import os
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dir):
entities = {} #欄位物體類別
files = os.listdir(dir) #遍歷路徑
return files
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
print(get_entities(path))
顯示目錄如下圖所示:

接著通過split分割提取所有檔案的名字,并進行去重操作,如下圖所示,
第二步,獲取每個ANN檔案中的第二個欄位,即物體型別,
#encoding:utf-8
import os
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dirPath):
entities = {} #欄位物體類別
files = os.listdir(dirPath) #遍歷路徑
#獲取所有檔案的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新構造ANN檔案名并遍歷檔案
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
print(path)
#讀檔案
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB鍵分割獲取物體型別
name = line.split('\t')[1]
print(name)
return filenames
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
print(get_entities(path))
輸出結果如下圖所示:
data/train_data\126_20.ann
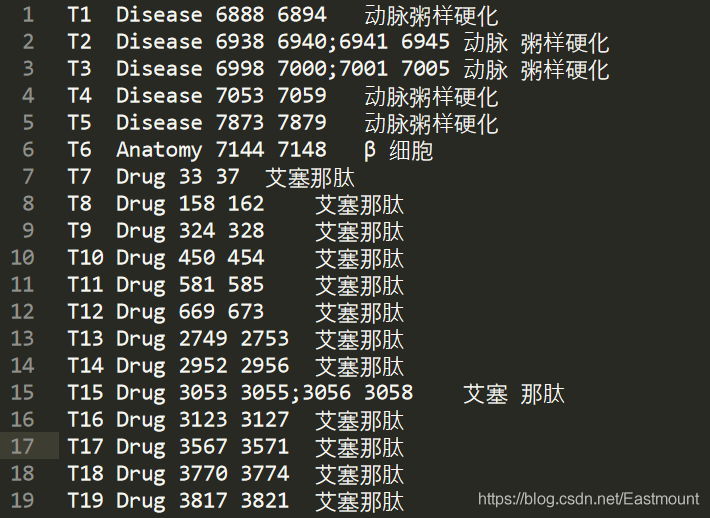
Disease 6938 6940;6941 6945
Disease 6998 7000;7001 7005
Disease 7053 7059
Disease 7873 7879
Anatomy 7144 7148
Drug 33 37
Drug 158 162
Drug 324 328
Drug 450 454
.....
對應的126_20.ann檔案如下圖所示,接著我們可以從提取的欄位中按照空格獲取物體類別,比如Disease、Anatomy、Drug等,
第三步,通過回圈判斷物體是否存在,存在個數加1,否則新物體加入字典,
#encoding:utf-8
import os
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dirPath):
entities = {} #存盤物體類別
files = os.listdir(dirPath) #遍歷路徑
#獲取所有檔案的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新構造ANN檔案名并遍歷檔案
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
print(path)
#讀檔案
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB鍵分割獲取物體型別
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#物體加入字典并統計個數
if value in entities:
entities[value] += 1 #在物體集合中數量加1
else:
entities[value] = 1 #創建鍵值且值為1
#回傳物體集
return entities
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
print(get_entities(path))
輸出結果如下圖所示:
總共有15個物體,我們可以通過len函式計算其個數,然后每個物體包括B和I兩個標注,再加上O標注,攻擊31個標注,至此,我們成功獲取了物體類別,
2.物體標記編碼轉換
接下來我們進行物體標記,這也是深度學習或NLP領域中非常基礎的知識,這段代碼也非常有意思,
第一步,獲取物體標記名稱,
#----------------------------功能:命名物體BIO標注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#獲取物體類別名稱
entities = [x[0] for x in entities]
print(entities)
輸出結果如下圖所示,成功獲取了物體型別名稱,如Test、Disease、Anatomy等,

第二步,生成不同物體型別的標記,包括B起始位置和I中間位置,
#encoding:utf-8
import os
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dirPath):
entities = {} #存盤物體類別
files = os.listdir(dirPath) #遍歷路徑
#獲取所有檔案的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新構造ANN檔案名并遍歷檔案
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#讀檔案
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB鍵分割獲取物體型別
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#物體加入字典并統計個數
if value in entities:
entities[value] += 1 #在物體集合中數量加1
else:
entities[value] = 1 #創建鍵值且值為1
#回傳物體集
return entities
#----------------------------功能:命名物體BIO標注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#獲取物體類別名稱
entities = [x[0] for x in entities]
print(entities)
#標記物體
id2label = []
id2label.append('O')
#生成物體標記
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典鍵值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
#獲取物體類別及個數
entities = get_entities(path)
print(entities)
print(len(entities))
#完成物體標記 串列 字典
#得到標簽和下標的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic)
輸出結果如下圖所示,共計31個標記(15個物體型別、O標記),

3.文本分割
由于每個文本都由很多字符組成,比如0.ann包含了六千多個漢字,因此轉換成單個字和標記后,它是一個很長的序列,這會影響深度學習模型的效果及運算速度,因此,我們需要將文本切分成短句,那么,它切割的方法是什么呢?

文本切割可以采用斷句的方式實作,定義一個串列將我們要斷句的地方包含,通常需要進行綜合考慮,比如句號、問號、換行等斷句,而逗號不執行斷句等, 由于本文采用的醫療資料集是影像識別生成的,因此存在一些錯誤,比如“使HBA1C ,<6.5%,患者” 該部分的句號不能直接斷句,否則會影響前后語意依賴,
第一步,定義分隔符并獲取字符下標,
下列代碼是個簡單示例,能獲取某些字符的前后5個字串,
import re
#-------------------------功能:自定義分隔符文本分割------------------------------
def split_text(text):
pattern = ',|,|,|;|?'
#獲取字符的下標位置
for m in re.finditer(pattern, text):
print(m)
start = m.span()[0] #標點符號位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
break
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
#自定義分割文本
text = path + "/0.txt"
print(text)
with open(text, 'r', encoding='utf8') as f:
text = f.read()
split_text(text)
輸出結果如下圖所示:

第二步,如果特殊字符前面是換行符情況,我們跳過該操作不分割,
#encoding:utf-8
import os
import re
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dirPath):
entities = {} #存盤物體類別
files = os.listdir(dirPath) #遍歷路徑
#獲取所有檔案的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新構造ANN檔案名并遍歷檔案
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#讀檔案
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB鍵分割獲取物體型別
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#物體加入字典并統計個數
if value in entities:
entities[value] += 1 #在物體集合中數量加1
else:
entities[value] = 1 #創建鍵值且值為1
#回傳物體集
return entities
#----------------------------功能:命名物體BIO標注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#獲取物體類別名稱
entities = [x[0] for x in entities]
print(entities)
#標記物體
id2label = []
id2label.append('O')
#生成物體標記
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典鍵值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定義分隔符文本分割------------------------------
def split_text(text):
pattern = ',|,|,|;|;|?|\?|\.'
#獲取字符的下標位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #標點符號位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符號下標
idx = m.span()[0]
#判斷是否斷句
if text[idx-1]=='\n': #當前符號前是換行符
print(path)
print('****', text[idx-20:idx+20], '****')
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
#獲取物體類別及個數
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成物體標記 串列 字典
#得到標簽和下標的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍歷路徑
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT檔案
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
split_text(text)
print("\n")
輸出結果如下圖所示,我們可以看到此時的結果很多被錯誤識別,因此不需要進行句子分割,增加continue即可,注意,因為ANN標記資料是按照原始TXT檔案位置標記,我們也不能進行洗掉操作,當然如果你的資料集干凈則預處理更簡單,
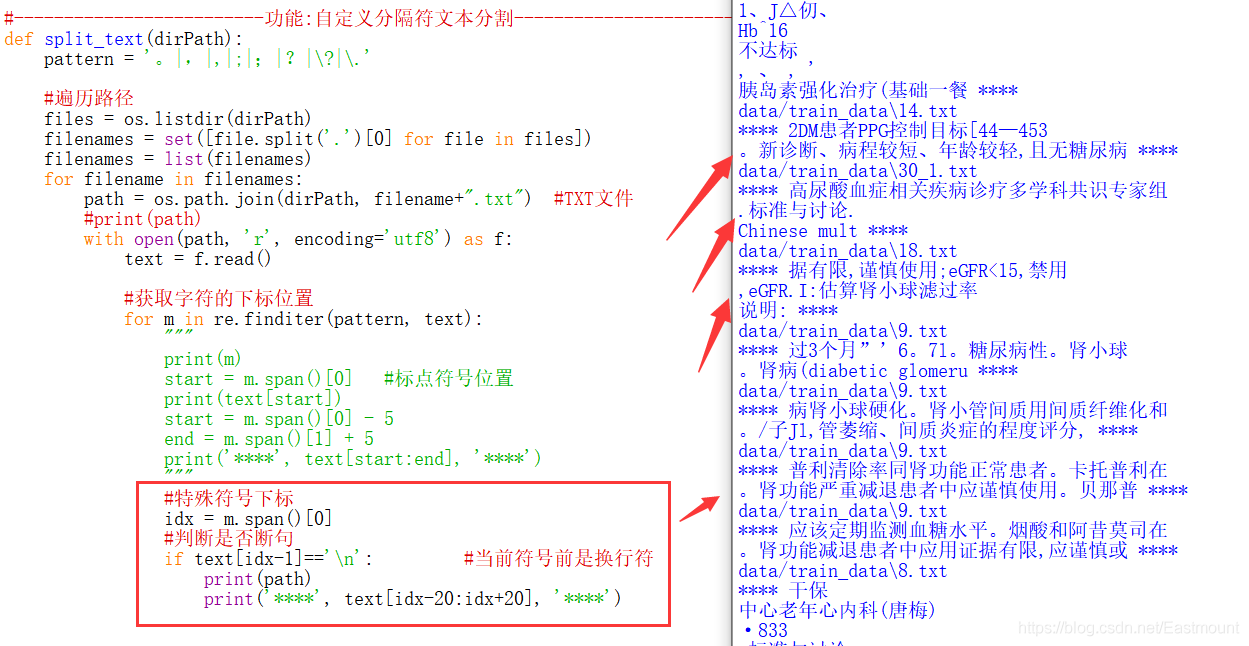
第三步,如果特殊符號前后是數字的情況,此時不應該分割保留,
比如[3,5]區間、OR=1.66、支撐專案(81270913,81070640)、(0. 888,0. 975)等,注意如果數字后面是空格也需要跳過,
if text[idx-1].isdigit() and text[idx+1].isdigit():
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue

第四步,前后都是字母的情況,此時不應該分割保留,
if text[idx-1].islower() and text[idx+1].islower():
continue
輸出如下圖所示,它們同樣不能切割成句子,
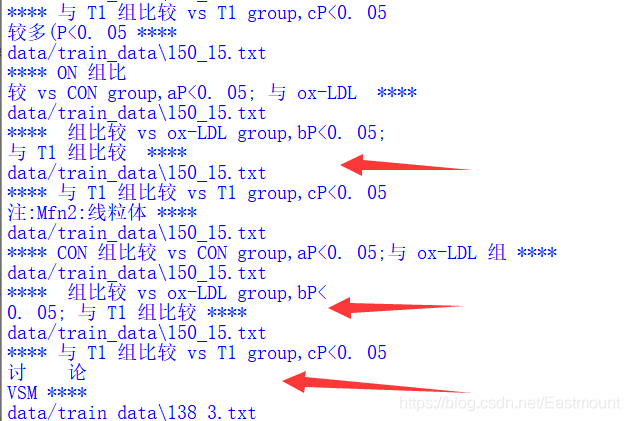
第五步,前后字母和數字的組合情況也不能切割,
if text[idx-1].islower() and text[idx+1].isdigit():
continue
if text[idx-1].isupper() and text[idx+1].isdigit():
continue
if text[idx-1].isdigit() and text[idx+1].islower():
continue
if text[idx-1].isdigit() and text[idx+1].isupper():
continue
第六步,增加能某些分割句子的正則運算式,
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附錄 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^,,,;;]+?\n|'
pattern2 += '圖 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【關鍵詞】|'
pattern2 += '結 果|討 論|and |or |with |by |because of |as well as '
for m in re.finditer(pattern2, text):
idx = m.span()[0]
print('****', text[idx-20:idx+20], '****')
輸出如下圖所示:

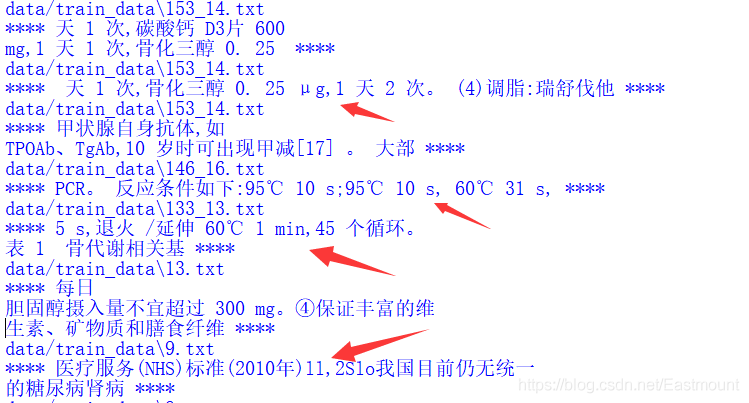
第七步,如果數字序列后面包含漢字,則進行分割,
比如“2.接下來…”,同時小數不能切割,這里通過自定義函式實作,
#------------------------功能:判斷字符是不是漢字-----------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
def split_text(dirPath):
.....
#判斷序列且包含漢字的分割(2.接下來...) 同時小數不進行切割
pattern3 = '\d\.' #數字+點
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+2]): #第三個字符為中文漢字
print('****', text[idx-20:idx+20], '****')
如下圖所示的結果都需要分割,

最終句子分割組合的完整代碼如下所示:
- data_process_01_.py
#encoding:utf-8
import os
import re
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dirPath):
entities = {} #存盤物體類別
files = os.listdir(dirPath) #遍歷路徑
#獲取所有檔案的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新構造ANN檔案名并遍歷檔案
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#讀檔案
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB鍵分割獲取物體型別
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#物體加入字典并統計個數
if value in entities:
entities[value] += 1 #在物體集合中數量加1
else:
entities[value] = 1 #創建鍵值且值為1
#回傳物體集
return entities
#----------------------------功能:命名物體BIO標注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#獲取物體類別名稱
entities = [x[0] for x in entities]
print(entities)
#標記物體
id2label = []
id2label.append('O')
#生成物體標記
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典鍵值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定義分隔符文本分割------------------------------
def split_text(text):
#分割后的下標
split_index = []
#--------------------------------------------------------------------
# 文本分割
#--------------------------------------------------------------------
#第一部分 按照符號分割
pattern = ',|,|,|;|;|?|\?|\.'
#獲取字符的下標位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #標點符號位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符號下標
idx = m.span()[0]
#判斷是否斷句 contniue表示不能直接分割句子
if text[idx-1]=='\n': #當前符號前是換行符
continue
if text[idx-1].isdigit() and text[idx+1].isdigit(): #前后都是數字或數字+空格
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue
if text[idx-1].islower() and text[idx+1].islower(): #前后都是小寫字母
continue
if text[idx-1].isupper() and text[idx+1].isupper(): #前后都是大寫字母
continue
if text[idx-1].islower() and text[idx+1].isdigit(): #前面是小寫字母 后面是數字
continue
if text[idx-1].isupper() and text[idx+1].isdigit(): #前面是大寫字母 后面是數字
continue
if text[idx-1].isdigit() and text[idx+1].islower(): #前面是數字 后面是小寫字母
continue
if text[idx-1].isdigit() and text[idx+1].isupper(): #前面是數字 后面是大寫字母
continue
if text[idx+1] in set('.,;;,,'): #前后都是標點符號
continue
if text[idx-1].isspace() and text[idx-2].isspace() and text[idx-3].isupper():
continue #HBA1C ,兩個空格+字母
if text[idx-1].isspace() and text[idx-3].isupper():
continue
#print(path)
#print('****', text[idx-20:idx+20], '****')
#將分句的下標存盤至串列中 -> 標點符號后面的字符
split_index.append(idx+1)
#--------------------------------------------------------------------
#第二部分 按照自定義符號分割
#下列形式進行句子分割
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附錄 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^,,,;;]+?\n|'
pattern2 += '圖 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【關鍵詞】|'
pattern2 += '結 果|討 論|and |or |with |by |because of |as well as '
#print(pattern2)
for m in re.finditer(pattern2, text):
idx = m.span()[0]
#print('****', text[idx-20:idx+20], '****')
#連接詞位于單詞中間不能分割 如 goodbye
if (text[idx:idx+2] in ['or','by'] or text[idx:idx+3]=='and' or text[idx:idx+4]=='with')\
and (text[idx-1].islower() or text[idx-1].isupper()):
continue
split_index.append(idx) #注意這里不加1 找到即分割
#--------------------------------------------------------------------
#第三部分 中文字符+數字分割
#判斷序列且包含漢字的分割(2.接下來...) 同時小數不進行切割
pattern3 = '\n\d\.' #數字+點
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+3]): #第四個字符為中文漢字 含換行
#print('****', text[idx-20:idx+20], '****')
split_index.append(idx+1)
#換行+數字+括號 (1)總體治療原則:淤在選擇降糖藥物時
for m in re.finditer('\n\(\d\)', text):
idx = m.span()[0]
split_index.append(idx+1)
#--------------------------------------------------------------------
#獲取句子分割下標后進行排序操作 增加第一行和最后一行
split_index = sorted(set([0, len(text)] + split_index))
split_index = list(split_index)
#print(split_index)
#計算機最大值和最小值
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)]
print(max(lens), min(lens))
#輸出切割的句子
#for i in range(len(split_index)-1):
# print(i, '******', text[split_index[i]:split_index[i+1]])
#---------------------------功能:判斷字符是不是漢字-------------------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
#獲取物體類別及個數
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成物體標記 串列 字典
#得到標簽和下標的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍歷路徑
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT檔案
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
print(path)
split_text(text)
print("\n")
輸出結果如下圖所示,我們可以計算分割后每個TXT檔案的最長句子和最短句子,
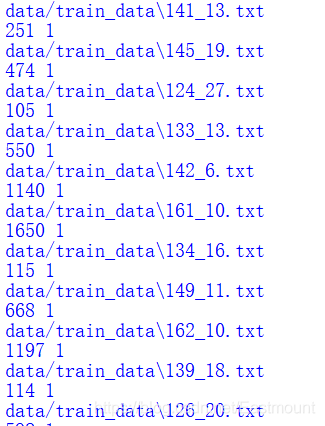
在進行預處理作業時,我們需要不斷地觀察原文本輸出,再進行深入的文本預處理操作,尤其是中文資料,因此,預處理是非常復雜且重要的步驟,它決定著后續實驗的好壞,
4.長短句處理
上面的步驟我們可以計算出最長的句子為2393,最短的句子為1,后續命名物體識別我們準備采用 BiLSTM+CRF 實作,而BiLSTM對長文本的處理效果不理想(只能很好地處理幾十個字),因此需要對句子進行長短處理,當我們將長句拆分成短句后,如果句子過短,我們還需要樣本增強,多個短句進行拼接處理,最終提升預處理語料的質量,
- 長句處理:句子長度超過150進行拆分
- 洗掉句子中的部分空格
- 短句處理:按照字符長度5進行比較,三個句子拼接
- 查看句子最大長度和最短長度,并進行檔案保存
完整代碼如下:
- data_process_02_sentenceCut.py
#encoding:utf-8
import os
import re
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dirPath):
entities = {} #存盤物體類別
files = os.listdir(dirPath) #遍歷路徑
#獲取所有檔案的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新構造ANN檔案名并遍歷檔案
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#讀檔案
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB鍵分割獲取物體型別
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#物體加入字典并統計個數
if value in entities:
entities[value] += 1 #在物體集合中數量加1
else:
entities[value] = 1 #創建鍵值且值為1
#回傳物體集
return entities
#----------------------------功能:命名物體BIO標注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#獲取物體類別名稱
entities = [x[0] for x in entities]
print(entities)
#標記物體
id2label = []
id2label.append('O')
#生成物體標記
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典鍵值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定義分隔符文本分割------------------------------
def split_text(text, outfile):
#分割后的下標
split_index = []
#檔案寫入
fw = open(outfile, 'w', encoding='utf8')
#--------------------------------------------------------------------
# 文本分割
#--------------------------------------------------------------------
#第一部分 按照符號分割
pattern = ',|,|,|;|;|?|\?|\.'
#獲取字符的下標位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #標點符號位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符號下標
idx = m.span()[0]
#判斷是否斷句 contniue表示不能直接分割句子
if text[idx-1]=='\n': #當前符號前是換行符
continue
if text[idx-1].isdigit() and text[idx+1].isdigit(): #前后都是數字或數字+空格
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue
if text[idx-1].islower() and text[idx+1].islower(): #前后都是小寫字母
continue
if text[idx-1].isupper() and text[idx+1].isupper(): #前后都是大寫字母
continue
if text[idx-1].islower() and text[idx+1].isdigit(): #前面是小寫字母 后面是數字
continue
if text[idx-1].isupper() and text[idx+1].isdigit(): #前面是大寫字母 后面是數字
continue
if text[idx-1].isdigit() and text[idx+1].islower(): #前面是數字 后面是小寫字母
continue
if text[idx-1].isdigit() and text[idx+1].isupper(): #前面是數字 后面是大寫字母
continue
if text[idx+1] in set('.,;;,,'): #前后都是標點符號
continue
if text[idx-1].isspace() and text[idx-2].isspace() and text[idx-3].isupper():
continue #HBA1C ,兩個空格+字母
if text[idx-1].isspace() and text[idx-3].isupper():
continue
#print('****', text[idx-20:idx+20], '****')
#將分句的下標存盤至串列中 -> 標點符號后面的字符
split_index.append(idx+1)
#--------------------------------------------------------------------
#第二部分 按照自定義符號分割
#下列形式進行句子分割
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附錄 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^,,,;;]+?\n|'
pattern2 += '圖 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【關鍵詞】|'
pattern2 += '結 果|討 論|and |or |with |by |because of |as well as '
#print(pattern2)
for m in re.finditer(pattern2, text):
idx = m.span()[0]
#print('****', text[idx-20:idx+20], '****')
#連接詞位于單詞中間不能分割 如 goodbye
if (text[idx:idx+2] in ['or','by'] or text[idx:idx+3]=='and' or text[idx:idx+4]=='with')\
and (text[idx-1].islower() or text[idx-1].isupper()):
continue
split_index.append(idx) #注意這里不加1 找到即分割
#--------------------------------------------------------------------
#第三部分 中文字符+數字分割
#判斷序列且包含漢字的分割(2.接下來...) 同時小數不進行切割
pattern3 = '\n\d\.' #數字+點
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+3]): #第四個字符為中文漢字 含換行
#print('****', text[idx-20:idx+20], '****')
split_index.append(idx+1)
#換行+數字+括號 (1)總體治療原則:淤在選擇降糖藥物時
for m in re.finditer('\n\(\d\)', text):
idx = m.span()[0]
split_index.append(idx+1)
#--------------------------------------------------------------------
#獲取句子分割下標后進行排序操作 增加第一行和最后一行
split_index = sorted(set([0, len(text)] + split_index))
split_index = list(split_index)
#print(split_index)
#計算機最大值和最小值
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)]
#print(max(lens), min(lens))
#--------------------------------------------------------------------
# 長短句處理
#--------------------------------------------------------------------
#遍歷每一個句子 (一)xxxx 分割
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#print("-----", text[begin:end])
#print(begin, end)
if (text[begin] in '一二三四五六七八九十零') or \
(text[begin]=='(' and text[begin+1] in '一二三四五六七八九十零'):
for j in range(begin,end):
if text[j]=='\n':
other_index.append(j+1)
#補充+排序
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第一部分 長句處理:句子長度超過150進行拆分
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
other_index.append(begin)
#句子長度超過150切割 并且最短15個字符
if end-begin>150:
for j in range(begin,end):
#這一次下標位置比上一次超過15分割
if(j+1-other_index[-1])>15:
#換行分割
if text[j]=='\n':
other_index.append(j+1)
#空格+前后數字
if text[j]==' ' and text[j-1].isnumeric() and text[j+1].isnumeric():
other_index.append(j+1)
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第二部分 洗掉空格的句子
for i in range(1, len(split_index)-1):
idx = split_index[i]
#當前下標和上一個下標對比 如果等于空格繼續比較
while idx>split_index[i-1]-1 and text[idx-1].isspace():
idx -= 1
split_index[i] = idx
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第三部分 短句處理-拼接
temp_idx = []
i = 0
while i<(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#先統計句子中中文字符和英文字符個數
num_ch = 0
num_en = 0
if end - begin <15:
for ch in text[begin:end]:
if ischinese(ch):
num_ch += 1
elif ch.islower() or ch.isupper():
num_en += 1
if num_ch + 0.5*num_en>5: #大于5說明長度夠用
temp_idx.append(begin)
i += 1 #注意break前i加1 否則死回圈
break
#長度小于等于5和后面的句子合并
if num_ch + 0.5*num_en<=5:
temp_idx.append(begin)
i += 2
else:
temp_idx.append(begin) #大于15直接添加下標
i += 1
split_index = list(sorted(set([0, len(text)] + temp_idx)))
#查看句子長度 由于存在\n換行一個字符
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)][:-1] #洗掉最后一個換行
print(max(lens), min(lens))
#for i in range(len(split_index)-1):
# print(i, '****', text[split_index[i]:split_index[i+1]])
#存盤結果
result = []
for i in range(len(split_index)-1):
result.append(text[split_index[i]:split_index[i+1]])
fw.write(text[split_index[i]:split_index[i+1]])
fw.close()
#檢查:預處理后字符是否減少
s = ''
for r in result:
s += r
assert len(s)==len(text) #斷言
return result
#---------------------------功能:判斷字符是不是漢字-------------------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
outPath = 'data/train_data_pro'
#獲取物體類別及個數
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成物體標記 串列 字典
#得到標簽和下標的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍歷路徑
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT檔案
outfile = os.path.join(outPath, filename+"_pro.txt")
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
print(path)
split_text(text, outfile)
print("\n")
輸出結果如下圖所示,發現句子長短逐漸均衡,最短為6,最長150,
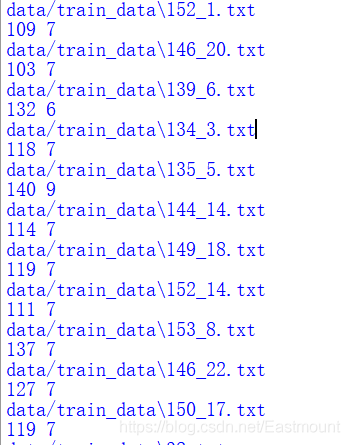
同時,作者寫入了新的檔案夾,將長短句分割的檔案寫入新的檔案夾中,如下圖所示,

四.物體標記自動化處理
1.分割句子對應的標簽字典生成
命名物體識別需要獲取詞和邊界,通常有許多標記型別,比如詞邊界、詞性、偏旁部首、拼音等特征,接下來我們新建一個檔案prepare_data.py,
- prepare_data.py
第一步,將所有文本標記為O,
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #進度條 pip install tqdm
#詞性標注
import jieba.posseg as psg
train_dir = "train_data"
#----------------------------功能:文本預處理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None):
"""
功能: 讀取文本并切割,接著打上標記及提取詞邊界、詞性、偏旁部首、拼音等特征
param idx: 檔案的名字 不含擴展名
param split_method: 切割文本方法
return
"""
#定義字典 保存所有字的標記、邊界、詞性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
#獲取句子
if split_method is None:
#未給文本分割函式 -> 讀取檔案
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示檔案路徑
texts = f.readlines()
else:
#給出文本分割函式 -> 按函式分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
#獲取標簽
tag_list = ['O' for s in texts for x in s] #雙層回圈遍歷每句話中的漢字
return tag_list
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
print(process_text('0',split_method=split_text))
輸出結果如下圖所示:
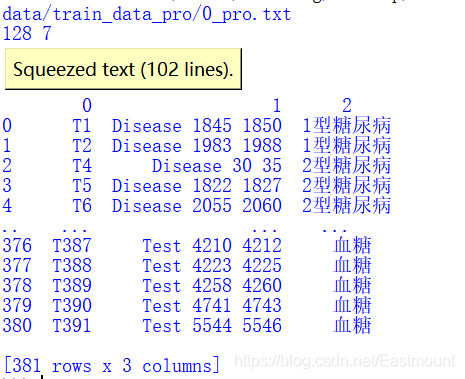
第二步,讀取ANN檔案獲取每個物體的型別、起始位置和結束位置,
這里采用Pandas讀取檔案,并且分割符為Tab鍵,無表頭,核心代碼如下:
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t')
return tag
輸出結果如下圖所示,我們需要提取下標為1的列,
接著我們提取物體型別、起始位置和結束位置,核心代碼如下:
#讀取ANN檔案獲取每個物體的型別、起始位置和結束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas讀取 分隔符為tab鍵
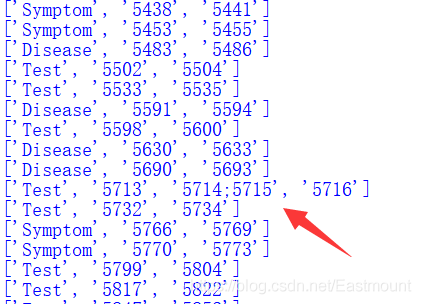
for i in range(tag.shape[0]): #tag.shape[0]為行數
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
print(tag_item)
但會存在某些物體包括兩段位置區間的情況,這是因為有空格,這里我們進行簡單處理,僅獲取物體的起始位置和終止位置,
第三步,物體標記提取,
由于之前我們沒有對原始TXT檔案做任何修改,并且每個TXT和ANN檔案的位置是一一對應的,所以接下來我們直接進行詞語標記即可,如下圖“2型糖尿病”物體位置為30到34,

此時的完整代碼如下:
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #進度條 pip install tqdm
#詞性標注
import jieba.posseg as psg
train_dir = "train_data"
#----------------------------功能:文本預處理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None):
"""
功能: 讀取文本并切割,接著打上標記及提取詞邊界、詞性、偏旁部首、拼音等特征
param idx: 檔案的名字 不含擴展名
param split_method: 切割文本方法
return
"""
#定義字典 保存所有字的標記、邊界、詞性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
#獲取句子
#--------------------------------------------------------------------
if split_method is None:
#未給文本分割函式 -> 讀取檔案
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示檔案路徑
texts = f.readlines()
else:
#給出文本分割函式 -> 按函式分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
# 獲取標簽
#--------------------------------------------------------------------
#初始時將所有漢字標記為O
tag_list = ['O' for s in texts for x in s] #雙層回圈遍歷每句話中的漢字
#讀取ANN檔案獲取每個物體的型別、起始位置和結束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas讀取 分隔符為tab鍵
#0 T1 Disease 1845 1850 1型糖尿病
for i in range(tag.shape[0]): #tag.shape[0]為行數
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
#print(tag_item)
#存在某些物體包括兩段位置區間 僅獲取起始位置和結束位置
cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1])
#print(cls,start,end)
#對tag_list進行修改
tag_list[start] = 'B-' + cls
for j in range(start+1, end):
tag_list[j] = 'I-' + cls
return tag_list
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
print(process_text('0',split_method=split_text))
標記的位置如下圖所示,發現它們是對應的,至此,我們成功提取了物體型別和位置,


第四步,將分割后的句子與標簽匹配,
它將轉換為兩個對應的輸出:
- 分割后的長短句
- 分割后長短句對應的標記資料
#--------------------------------------------------------------------
# 分割后句子匹配標簽
#--------------------------------------------------------------------
tags = []
start = 0
end = 0
#遍歷文本
for s in texts:
length = len(s)
end += length
tags.append(tag_list[start:end])
start += length
return tag_list, tags
輸出結果如下圖所示,我們可以看到第三部分“資料預處理”生成的長短句和我們的標簽對應一致,
2.提取詞性和詞邊界
提取詞性,通過jieba工具進行帶詞性的分詞處理,
#--------------------------------------------------------------------
# 提取詞性和詞邊界
#--------------------------------------------------------------------
#初始標記為M
word_bounds = ['M' for item in tag_list] #邊界 M表示中間
word_flags = [] #詞性
#分詞
for text in texts:
#帶詞性的結巴分詞
for word, flag in psg.cut(text):
if len(word)==1: #1個長度詞
start = len(word_flags)
word_bounds[start] = 'S' #單個字
word_flags.append(flag)
else:
start = len(word_flags)
word_bounds[start] = 'B' #開始邊界
word_flags += [flag]*len(word) #保證詞性和字一一對應
end = len(word_flags) - 1
word_bounds[end] = 'E' #結束邊界
#存盤
bounds = []
flags = []
start = 0
end = 0
for s in texts:
length = len(s)
end += length
bounds.append(word_bounds[start:end])
flags.append(word_flags[start:end])
start += length
data['bound'] = bounds
data['flag'] = flags
#return texts, tags, bounds, flags
return texts[0], tags[0], bounds[0], flags[0]
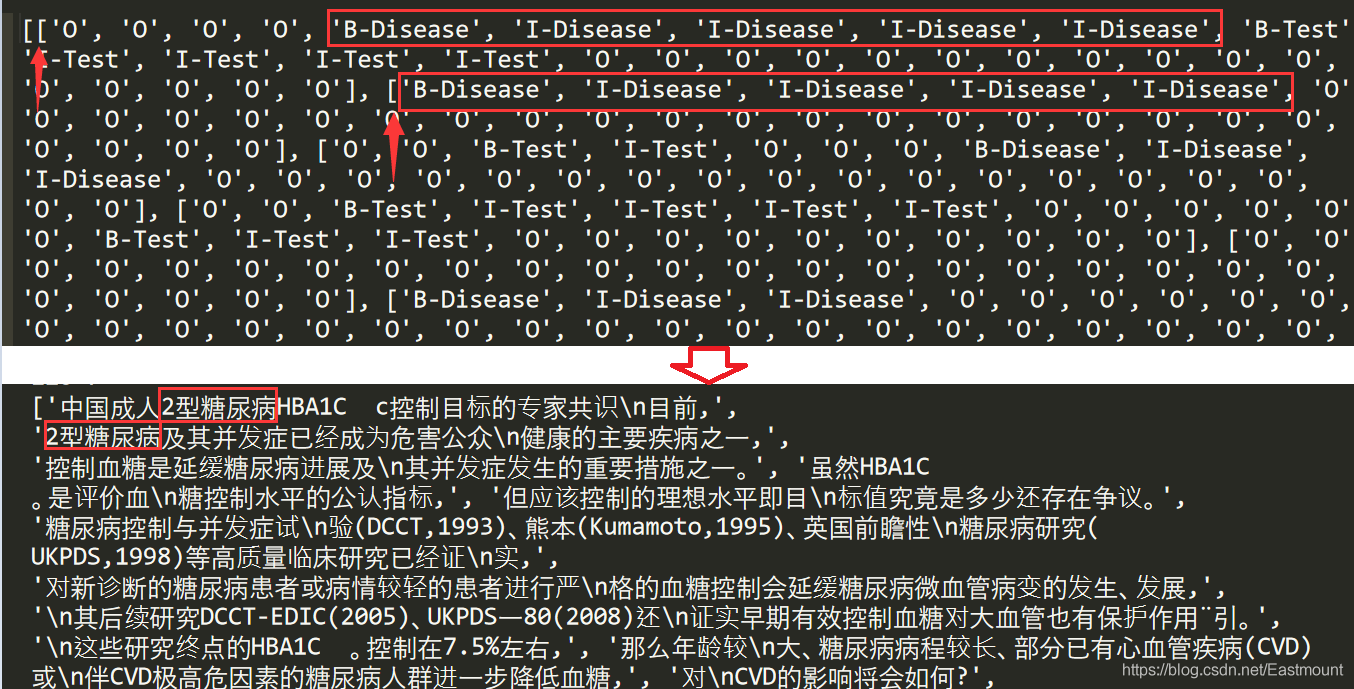
我們輸出第一行內容,看看結果,分別輸出第一句話的字,第一句話的標簽,第一句話的分詞邊界和第一句話的詞性標注,
(
'中國成人2型糖尿病HBA1C c控制目標的專家共識\n目前,',
['O', 'O', 'O', 'O', 'B-Disease', 'I-Disease', 'I-Disease',
'I-Disease', 'I-Disease', 'B-Test', 'I-Test', 'I-Test',
'I-Test', 'I-Test', 'O', 'O', 'O', 'O', 'O', 'O',
'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'],
['B', 'E', 'B', 'E', 'S', 'S', 'B', 'M', 'E',
'B', 'M', 'M', 'M', 'E', 'S', 'S', 'S', 'B',
'M', 'M', 'E', 'S', 'B', 'E', 'B', 'E', 'S', 'B', 'E', 'S'],
['ns', 'ns', 'n', 'n', 'm', 'k', 'n', 'n', 'n',
'eng', 'eng', 'eng', 'eng', 'eng', 'x', 'x',
'x', 'n', 'n', 'n', 'n', 'uj', 'n', 'n', 'n', 'n', 'x', 't', 't', 'x']
)
3.獲取拼音特征
首先,我們安裝一個工具包cnradical,它用于提取中文的偏旁部首和拼音,
- pip install cnradical
- https://github.com/wangchuan2008888/cn-radical
第二步,簡單測驗下這個包的功能,
from cnradical import Radical, RunOption
radical = Radical(RunOption.Radical)
pinyin = Radical(RunOption.Pinyin)
text = '你好,今天早上吃飯了嗎?Eastmount'
radical_out = [radical.trans_ch(ele) for ele in text]
pinyin_out = [pinyin.trans_ch(ele) for ele in text]
print(radical_out)
print(pinyin_out)
radical_out = radical.trans_str(text)
pinyin_out = pinyin.trans_str(text)
print(radical_out)
print(pinyin_out)
輸出結果如下圖所示,成功獲取了偏旁和拼音,

第三步,源代碼進行拼音特征提取,
此時的完整代碼如下所示:
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #進度條 pip install tqdm
#詞性標注
import jieba.posseg as psg
#獲取字的偏旁和拼音
from cnradical import Radical, RunOption
train_dir = "train_data"
#----------------------------功能:文本預處理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None):
"""
功能: 讀取文本并切割,接著打上標記及提取詞邊界、詞性、偏旁部首、拼音等特征
param idx: 檔案的名字 不含擴展名
param split_method: 切割文本方法
return
"""
#定義字典 保存所有字的標記、邊界、詞性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
#獲取句子
#--------------------------------------------------------------------
if split_method is None:
#未給文本分割函式 -> 讀取檔案
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示檔案路徑
texts = f.readlines()
else:
#給出文本分割函式 -> 按函式分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
# 獲取標簽
#--------------------------------------------------------------------
#初始時將所有漢字標記為O
tag_list = ['O' for s in texts for x in s] #雙層回圈遍歷每句話中的漢字
#讀取ANN檔案獲取每個物體的型別、起始位置和結束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas讀取 分隔符為tab鍵
#0 T1 Disease 1845 1850 1型糖尿病
for i in range(tag.shape[0]): #tag.shape[0]為行數
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
#print(tag_item)
#存在某些物體包括兩段位置區間 僅獲取起始位置和結束位置
cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1])
#print(cls,start,end)
#對tag_list進行修改
tag_list[start] = 'B-' + cls
for j in range(start+1, end):
tag_list[j] = 'I-' + cls
#斷言 兩個長度不一致報錯
assert len([x for s in texts for x in s])==len(tag_list)
#print(len([x for s in texts for x in s]))
#print(len(tag_list))
#--------------------------------------------------------------------
# 分割后句子匹配標簽
#--------------------------------------------------------------------
tags = []
start = 0
end = 0
#遍歷文本
for s in texts:
length = len(s)
end += length
tags.append(tag_list[start:end])
start += length
print(len(tags))
#標簽資料存盤至字典中
data['label'] = tags
#--------------------------------------------------------------------
# 提取詞性和詞邊界
#--------------------------------------------------------------------
#初始標記為M
word_bounds = ['M' for item in tag_list] #邊界 M表示中間
word_flags = [] #詞性
#分詞
for text in texts:
#帶詞性的結巴分詞
for word, flag in psg.cut(text):
if len(word)==1: #1個長度詞
start = len(word_flags)
word_bounds[start] = 'S' #單個字
word_flags.append(flag)
else:
start = len(word_flags)
word_bounds[start] = 'B' #開始邊界
word_flags += [flag]*len(word) #保證詞性和字一一對應
end = len(word_flags) - 1
word_bounds[end] = 'E' #結束邊界
#存盤
bounds = []
flags = []
start = 0
end = 0
for s in texts:
length = len(s)
end += length
bounds.append(word_bounds[start:end])
flags.append(word_flags[start:end])
start += length
data['bound'] = bounds
data['flag'] = flags
#--------------------------------------------------------------------
# 獲取拼音特征
#--------------------------------------------------------------------
radical = Radical(RunOption.Radical) #提取偏旁部首
pinyin = Radical(RunOption.Pinyin) #提取拼音
#提取拼音和偏旁 None用特殊符號替代
radical_out = [[radical.trans_ch(x) if radical.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
pinyin_out = [[pinyin.trans_ch(x) if pinyin.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
#賦值
data['radical'] = radical_out
data['pinyin'] = pinyin_out
#return texts, tags, bounds, flags
return texts[0], tags[0], bounds[0], flags[0], radical_out[0], pinyin_out[0]
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
print(process_text('0',split_method=split_text)
輸出結果如下:
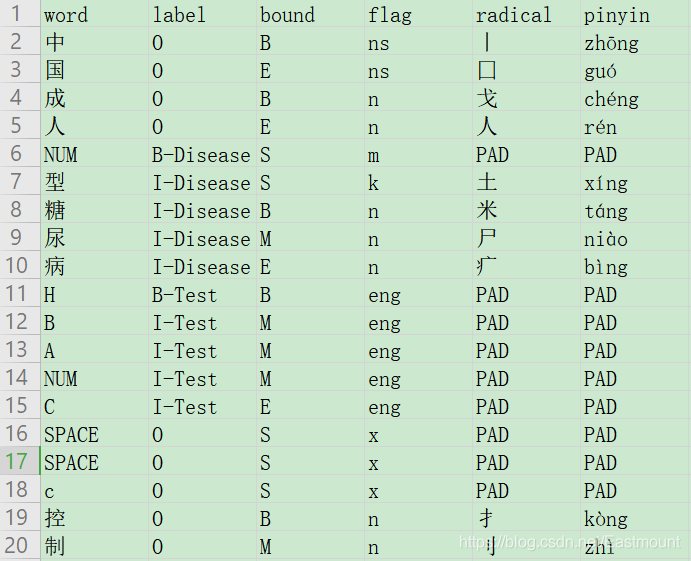
('中國成人2型糖尿病HBA1C c控制目標的專家共識\n目前,',
['O', 'O', 'O', 'O', 'B-Disease', 'I-Disease', 'I-Disease', 'I-Disease', 'I-Disease',
'B-Test', 'I-Test', 'I-Test', 'I-Test', 'I-Test', 'O', 'O', 'O',
'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'],
['B', 'E', 'B', 'E', 'S', 'S', 'B', 'M', 'E', 'B', 'M',
'M', 'M', 'E', 'S', 'S', 'S', 'B', 'M', 'M', 'E', 'S',
'B', 'E', 'B', 'E', 'S', 'B', 'E', 'S'],
['ns', 'ns', 'n', 'n', 'm', 'k', 'n', 'n', 'n', 'eng',
'eng', 'eng', 'eng', 'eng', 'x', 'x', 'x', 'n', 'n',
'n', 'n', 'uj', 'n', 'n', 'n', 'n', 'x', 't', 't', 'x'],
['丨', '囗', '戈', '人', 'PAD', '土', '米', '尸', '疒', 'PAD',
'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', '扌', '刂',
'目', '木', '白', '一', '宀', '八', '讠', 'PAD', '目', '刂', 'PAD'],
['zhōng', 'guó', 'chéng', 'rén', 'PAD', 'xíng', 'táng', 'niào', 'bìng', 'PAD',
'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'kòng', 'zhì', 'mù', 'biāo',
'dí', 'zhuān', 'jiā', 'gòng', 'shí', 'PAD', 'mù', 'qián', 'PAD'])
4.按字標記及資料存盤
第一步,獲取樣本數量并按照每個字進行標記,比如“中”對應的標簽、詞性、偏旁、拼音等,
#--------------------------------------------------------------------
# 存盤資料
#--------------------------------------------------------------------
#獲取樣本數量
num_samples = len(texts) #行數
num_col = len(data.keys()) #列數 字典自定義類別數
print(num_samples)
print(num_col)
dataset = []
for i in range(num_samples):
records = list(zip(*[list(v[i]) for v in data.values()])) #壓縮
records = list(zip(*[list(v[0]) for v in data.values()]))
for r in records:
print(r)
#return texts, tags, bounds, flags
#return texts[0], tags[0], bounds[0], flags[0], radical_out[0], pinyin_out[0]
注意,zip這里不加星號表示壓縮,加星號(*)表示解壓,第一行陳述句最終輸出結果如下圖所示,

第二步,依次處理不同行資料并進行存盤,
每輸出一句話,均增加一行sep,表示換行隔開處理,

核心代碼如下所示:
#--------------------------------------------------------------------
# 存盤資料
#--------------------------------------------------------------------
#獲取樣本數量
num_samples = len(texts) #行數
num_col = len(data.keys()) #列數 字典自定義類別數 6
print(num_samples)
print(num_col)
dataset = []
for i in range(num_samples):
records = list(zip(*[list(v[i]) for v in data.values()])) #壓縮
dataset += records+[['sep']*num_col] #每處理一句話sep分割
#records = list(zip(*[list(v[0]) for v in data.values()]))
#for r in records:
# print(r)
#最后一行sep洗掉
dataset = dataset[:-1]
#轉換成dataframe 增加表頭
dataset = pd.DataFrame(dataset,columns=data.keys())
#保存檔案 測驗集 訓練集
save_path = f'data/prepare/{split_name}/{idx}.csv'
dataset.to_csv(save_path,index=False,encoding='utf-8')
#--------------------------------------------------------------------
# 處理換行符 w表示一個字
#--------------------------------------------------------------------
def clean_word(w):
if w=='\n':
return 'LB'
if w in [' ','\t','\u2003']: #中文空格\u2003
return 'SPACE'
if w.isdigit(): #將所有數字轉換為一種符號 數字訓練會造成干擾
return 'NUM'
return w
#對dataframe應用函式
dataset['word'] = dataset['word'].apply(clean_word)
#存盤資料
dataset.to_csv(save_path,index=False,encoding='utf-8')
5.多文本處理
前面都是針對某個txt檔案進行的資料預處理,接下來我們自定義函式對所有文本進行處理操作,核心代碼如下:
#----------------------------功能:預處理所有文本---------------------------------
def multi_process(split_method=None,train_ratio=0.8):
"""
功能: 對所有文本盡心預處理操作
param split_method: 切割文本方法
param train_ratio: 訓練集和測驗集劃分比例
return
"""
#洗掉目錄
if os.path.exists('data/prepare/'):
shutil.rmtree('data/prepare/')
#創建目錄
if not os.path.exists('data/prepare/train/'):
os.makedirs('data/prepare/train/')
os.makedirs('data/prepare/test/')
#獲取所有檔案名
idxs = set([file.split('.')[0] for file in os.listdir('data/'+train_dir)])
idxs = list(idxs)
#隨機劃分訓練集和測驗集
shuffle(idxs) #打亂順序
index = int(len(idxs)*train_ratio) #獲取訓練集的截止下標
#獲取訓練集和測驗集檔案名集合
train_ids = idxs[:index]
test_ids = idxs[index:]
#--------------------------------------------------------------------
# 引入多行程
#--------------------------------------------------------------------
#執行緒池方式呼叫
import multiprocessing as mp
num_cpus = mp.cpu_count() #獲取機器CPU的個數
pool = mp.Pool(num_cpus)
results = []
#訓練集處理
for idx in train_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'train'))
results.append(result)
#測驗集處理
for idx in test_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'test'))
results.append(result)
#關閉行程池
pool.close()
pool.join()
[r.get for r in results]
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
#print(process_text('0',split_method=split_text,split_name='train'))
multi_process(split_text)
輸出結果如下圖所示,訓練集290個檔案,測驗集73個檔案,我們可以看到“2型糖尿病”和“HBA1C”被成功標記,但是數字被轉換成了NUM,后面我們可以去原文中替換出來即可,
- 2型糖尿病:Disease
- HBA1C:Test
五.完整代碼
完整代碼如下所示:
1.data_process.py
#encoding:utf-8
import os
import re
#----------------------------功能:獲取物體類別及個數---------------------------------
def get_entities(dirPath):
entities = {} #存盤物體類別
files = os.listdir(dirPath) #遍歷路徑
#獲取所有檔案的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新構造ANN檔案名并遍歷檔案
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#讀檔案
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB鍵分割獲取物體型別
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#物體加入字典并統計個數
if value in entities:
entities[value] += 1 #在物體集合中數量加1
else:
entities[value] = 1 #創建鍵值且值為1
#回傳物體集
return entities
#----------------------------功能:命名物體BIO標注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#獲取物體類別名稱
entities = [x[0] for x in entities]
print(entities)
#標記物體
id2label = []
id2label.append('O')
#生成物體標記
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典鍵值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定義分隔符文本分割------------------------------
def split_text(text, outfile):
#分割后的下標
split_index = []
#檔案寫入
fw = open(outfile, 'w', encoding='utf8')
#--------------------------------------------------------------------
# 文本分割
#--------------------------------------------------------------------
#第一部分 按照符號分割
pattern = ',|,|,|;|;|?|\?|\.'
#獲取字符的下標位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #標點符號位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符號下標
idx = m.span()[0]
#判斷是否斷句 contniue表示不能直接分割句子
if text[idx-1]=='\n': #當前符號前是換行符
continue
if text[idx-1].isdigit() and text[idx+1].isdigit(): #前后都是數字或數字+空格
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue
if text[idx-1].islower() and text[idx+1].islower(): #前后都是小寫字母
continue
if text[idx-1].isupper() and text[idx+1].isupper(): #前后都是大寫字母
continue
if text[idx-1].islower() and text[idx+1].isdigit(): #前面是小寫字母 后面是數字
continue
if text[idx-1].isupper() and text[idx+1].isdigit(): #前面是大寫字母 后面是數字
continue
if text[idx-1].isdigit() and text[idx+1].islower(): #前面是數字 后面是小寫字母
continue
if text[idx-1].isdigit() and text[idx+1].isupper(): #前面是數字 后面是大寫字母
continue
if text[idx+1] in set('.,;;,,'): #前后都是標點符號
continue
if text[idx-1].isspace() and text[idx-2].isspace() and text[idx-3].isupper():
continue #HBA1C ,兩個空格+字母
if text[idx-1].isspace() and text[idx-3].isupper():
continue
#print('****', text[idx-20:idx+20], '****')
#將分句的下標存盤至串列中 -> 標點符號后面的字符
split_index.append(idx+1)
#--------------------------------------------------------------------
#第二部分 按照自定義符號分割
#下列形式進行句子分割
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附錄 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^,,,;;]+?\n|'
pattern2 += '圖 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【關鍵詞】|'
pattern2 += '結 果|討 論|and |or |with |by |because of |as well as '
#print(pattern2)
for m in re.finditer(pattern2, text):
idx = m.span()[0]
#print('****', text[idx-20:idx+20], '****')
#連接詞位于單詞中間不能分割 如 goodbye
if (text[idx:idx+2] in ['or','by'] or text[idx:idx+3]=='and' or text[idx:idx+4]=='with')\
and (text[idx-1].islower() or text[idx-1].isupper()):
continue
split_index.append(idx) #注意這里不加1 找到即分割
#--------------------------------------------------------------------
#第三部分 中文字符+數字分割
#判斷序列且包含漢字的分割(2.接下來...) 同時小數不進行切割
pattern3 = '\n\d\.' #數字+點
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+3]): #第四個字符為中文漢字 含換行
#print('****', text[idx-20:idx+20], '****')
split_index.append(idx+1)
#換行+數字+括號 (1)總體治療原則:淤在選擇降糖藥物時
for m in re.finditer('\n\(\d\)', text):
idx = m.span()[0]
split_index.append(idx+1)
#--------------------------------------------------------------------
#獲取句子分割下標后進行排序操作 增加第一行和最后一行
split_index = sorted(set([0, len(text)] + split_index))
split_index = list(split_index)
#print(split_index)
#計算機最大值和最小值
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)]
#print(max(lens), min(lens))
#--------------------------------------------------------------------
# 長短句處理
#--------------------------------------------------------------------
#遍歷每一個句子 (一)xxxx 分割
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#print("-----", text[begin:end])
#print(begin, end)
if (text[begin] in '一二三四五六七八九十零') or \
(text[begin]=='(' and text[begin+1] in '一二三四五六七八九十零'):
for j in range(begin,end):
if text[j]=='\n':
other_index.append(j+1)
#補充+排序
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第一部分 長句處理:句子長度超過150進行拆分
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
other_index.append(begin)
#句子長度超過150切割 并且最短15個字符
if end-begin>150:
for j in range(begin,end):
#這一次下標位置比上一次超過15分割
if(j+1-other_index[-1])>15:
#換行分割
if text[j]=='\n':
other_index.append(j+1)
#空格+前后數字
if text[j]==' ' and text[j-1].isnumeric() and text[j+1].isnumeric():
other_index.append(j+1)
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第二部分 洗掉空格的句子
for i in range(1, len(split_index)-1):
idx = split_index[i]
#當前下標和上一個下標對比 如果等于空格繼續比較
while idx>split_index[i-1]-1 and text[idx-1].isspace():
idx -= 1
split_index[i] = idx
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第三部分 短句處理-拼接
temp_idx = []
i = 0
while i<(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#先統計句子中中文字符和英文字符個數
num_ch = 0
num_en = 0
if end - begin <15:
for ch in text[begin:end]:
if ischinese(ch):
num_ch += 1
elif ch.islower() or ch.isupper():
num_en += 1
if num_ch + 0.5*num_en>5: #大于5說明長度夠用
temp_idx.append(begin)
i += 1 #注意break前i加1 否則死回圈
break
#長度小于等于5和后面的句子合并
if num_ch + 0.5*num_en<=5:
temp_idx.append(begin)
i += 2
else:
temp_idx.append(begin) #大于15直接添加下標
i += 1
split_index = list(sorted(set([0, len(text)] + temp_idx)))
#查看句子長度 由于存在\n換行一個字符
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)][:-1] #洗掉最后一個換行
print(max(lens), min(lens))
#for i in range(len(split_index)-1):
# print(i, '****', text[split_index[i]:split_index[i+1]])
#存盤結果
result = []
for i in range(len(split_index)-1):
result.append(text[split_index[i]:split_index[i+1]])
fw.write(text[split_index[i]:split_index[i+1]])
fw.close()
#檢查:預處理后字符是否減少
s = ''
for r in result:
s += r
assert len(s)==len(text) #斷言
return result
#---------------------------功能:判斷字符是不是漢字-------------------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
outPath = 'data/train_data_pro'
#獲取物體類別及個數
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成物體標記 串列 字典
#得到標簽和下標的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍歷路徑
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT檔案
outfile = os.path.join(outPath, filename+"_pro.txt")
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
print(path)
split_text(text, outfile)
print("\n")
輸出結果:
2.prepare_data.py
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #進度條 pip install tqdm
#詞性標注
import jieba.posseg as psg
#獲取字的偏旁和拼音
from cnradical import Radical, RunOption
#洗掉目錄
import shutil
#隨機劃分訓練集和測驗集
from random import shuffle
train_dir = "train_data"
#----------------------------功能:文本預處理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None, split_name='train'):
"""
功能: 讀取文本并切割,接著打上標記及提取詞邊界、詞性、偏旁部首、拼音等特征
param idx: 檔案的名字 不含擴展名
param split_method: 切割文本方法
param split_name: 存盤資料集 默認訓練集, 還有測驗集
return
"""
#定義字典 保存所有字的標記、邊界、詞性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
# 獲取句子
#--------------------------------------------------------------------
if split_method is None:
#未給文本分割函式 -> 讀取檔案
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示檔案路徑
texts = f.readlines()
else:
#給出文本分割函式 -> 按函式分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
# 獲取標簽(物體類別、起始位置)
#--------------------------------------------------------------------
#初始時將所有漢字標記為O
tag_list = ['O' for s in texts for x in s] #雙層回圈遍歷每句話中的漢字
#讀取ANN檔案獲取每個物體的型別、起始位置和結束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas讀取 分隔符為tab鍵
#0 T1 Disease 1845 1850 1型糖尿病
for i in range(tag.shape[0]): #tag.shape[0]為行數
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
#print(tag_item)
#存在某些物體包括兩段位置區間 僅獲取起始位置和結束位置
cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1])
#print(cls,start,end)
#對tag_list進行修改
tag_list[start] = 'B-' + cls
for j in range(start+1, end):
tag_list[j] = 'I-' + cls
#斷言 兩個長度不一致報錯
assert len([x for s in texts for x in s])==len(tag_list)
#print(len([x for s in texts for x in s]))
#print(len(tag_list))
#--------------------------------------------------------------------
# 分割后句子匹配標簽
#--------------------------------------------------------------------
tags = []
start = 0
end = 0
#遍歷文本
for s in texts:
length = len(s)
end += length
tags.append(tag_list[start:end])
start += length
print(len(tags))
#標簽資料存盤至字典中
data['label'] = tags
#--------------------------------------------------------------------
# 提取詞性和詞邊界
#--------------------------------------------------------------------
#初始標記為M
word_bounds = ['M' for item in tag_list] #邊界 M表示中間
word_flags = [] #詞性
#分詞
for text in texts:
#帶詞性的結巴分詞
for word, flag in psg.cut(text):
if len(word)==1: #1個長度詞
start = len(word_flags)
word_bounds[start] = 'S' #單個字
word_flags.append(flag)
else:
start = len(word_flags)
word_bounds[start] = 'B' #開始邊界
word_flags += [flag]*len(word) #保證詞性和字一一對應
end = len(word_flags) - 1
word_bounds[end] = 'E' #結束邊界
#存盤
bounds = []
flags = []
start = 0
end = 0
for s in texts:
length = len(s)
end += length
bounds.append(word_bounds[start:end])
flags.append(word_flags[start:end])
start += length
data['bound'] = bounds
data['flag'] = flags
#--------------------------------------------------------------------
# 獲取拼音和偏旁特征
#--------------------------------------------------------------------
radical = Radical(RunOption.Radical) #提取偏旁部首
pinyin = Radical(RunOption.Pinyin) #提取拼音
#提取拼音和偏旁 None用特殊符號替代
radical_out = [[radical.trans_ch(x) if radical.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
pinyin_out = [[pinyin.trans_ch(x) if pinyin.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
#賦值
data['radical'] = radical_out
data['pinyin'] = pinyin_out
#--------------------------------------------------------------------
# 存盤資料
#--------------------------------------------------------------------
#獲取樣本數量
num_samples = len(texts) #行數
num_col = len(data.keys()) #列數 字典自定義類別數 6
print(num_samples)
print(num_col)
dataset = []
for i in range(num_samples):
records = list(zip(*[list(v[i]) for v in data.values()])) #壓縮
dataset += records+[['sep']*num_col] #每處理一句話sep分割
#records = list(zip(*[list(v[0]) for v in data.values()]))
#for r in records:
# print(r)
#最后一行sep洗掉
dataset = dataset[:-1]
#轉換成dataframe 增加表頭
dataset = pd.DataFrame(dataset,columns=data.keys())
#保存檔案 測驗集 訓練集
save_path = f'data/prepare/{split_name}/{idx}.csv'
dataset.to_csv(save_path,index=False,encoding='utf-8')
#--------------------------------------------------------------------
# 處理換行符 w表示一個字
#--------------------------------------------------------------------
def clean_word(w):
if w=='\n':
return 'LB'
if w in [' ','\t','\u2003']: #中文空格\u2003
return 'SPACE'
if w.isdigit(): #將所有數字轉換為一種符號 數字訓練會造成干擾
return 'NUM'
return w
#對dataframe應用函式
dataset['word'] = dataset['word'].apply(clean_word)
#存盤資料
dataset.to_csv(save_path,index=False,encoding='utf-8')
#return texts, tags, bounds, flags
#return texts[0], tags[0], bounds[0], flags[0], radical_out[0], pinyin_out[0]
#----------------------------功能:預處理所有文本---------------------------------
def multi_process(split_method=None,train_ratio=0.8):
"""
功能: 對所有文本盡心預處理操作
param split_method: 切割文本方法
param train_ratio: 訓練集和測驗集劃分比例
return
"""
#洗掉目錄
if os.path.exists('data/prepare/'):
shutil.rmtree('data/prepare/')
#創建目錄
if not os.path.exists('data/prepare/train/'):
os.makedirs('data/prepare/train/')
os.makedirs('data/prepare/test/')
#獲取所有檔案名
idxs = set([file.split('.')[0] for file in os.listdir('data/'+train_dir)])
idxs = list(idxs)
#隨機劃分訓練集和測驗集
shuffle(idxs) #打亂順序
index = int(len(idxs)*train_ratio) #獲取訓練集的截止下標
#獲取訓練集和測驗集檔案名集合
train_ids = idxs[:index]
test_ids = idxs[index:]
#--------------------------------------------------------------------
# 引入多行程
#--------------------------------------------------------------------
#執行緒池方式呼叫
import multiprocessing as mp
num_cpus = mp.cpu_count() #獲取機器CPU的個數
pool = mp.Pool(num_cpus)
results = []
#訓練集處理
for idx in train_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'train'))
results.append(result)
#測驗集處理
for idx in test_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'test'))
results.append(result)
#關閉行程池
pool.close()
pool.join()
[r.get for r in results]
#-------------------------------功能:主函式--------------------------------------
if __name__ == '__main__':
#print(process_text('0',split_method=split_text,split_name='train'))
multi_process(split_text)
輸出結果:
六.總結
data_process.py
get_entities(dirPath)函式功能:
- 獲取物體類別及個數
get_labelencoder(entities)函式功能:
- 命名物體BIO標注
split_text(text, outfile)函式功能:
- 文本分割:自定義分隔符、continue分割、中文字判斷、組合分割
- 長短句處理:長句長度超過150進行拆分、短句組合
- 存盤結果
prepare_data.py
def process_text(idx, split_method=None, split_name=‘train’)函式功能:
- 獲取句子
- 獲取標簽:讀取ANN檔案獲取物體型別、起始位置(B)、結束位置(I)
- 分割后的句子匹配標簽
- 提取詞性和邊界:通過Jieba分詞提取詞性,通過長度計算邊界
- 提取拼音和偏旁部首特征:利用cnradical擴展包實作
- 存盤資料:按照輸入字典data的六種類別一組進行資料存盤
def multi_process(split_method=None,train_ratio=0.8)函式功能:
- 多檔案處理:通過執行緒池實作
思考:上面的代碼我們可以通過正則運算式將“2型糖尿病”、“HBA1C”等詞識別出來,但為什么要用神經網路去進行命名物體識別呢?
- 我們通過正則運算式只是單純將某個詞組識別出來,但是構建神經網路模型后,如果將這個位置的詞換成其他物體,即使不是“2型糖尿病”,它也能被正確是識別出來,這種通過背景關系環境的識別方法,是正則運算式不能替代的,并且能較好地識別新生的詞組或物體,比如某種醫學疾病或藥房,但是,前期我們進行資料預處理時,可以通過正則運算式進行標注,再進一步校正,
思考:我們能將這些字直接輸入到模型中訓練嗎?
- 這是不能計算的,比如詞性、拼音、偏旁部首,我們還需要進行詞嵌入,轉換成詞向量,每個詞性、拼音、偏旁部首都轉換成向量,再拼接再一起組成新的向量進行訓練,
下一篇文章我們將詳細講解字典映射、詞嵌入轉換、資料增強和BiLSTM-CrF模型的構建,希望您喜歡這篇文章,從開視頻到撰寫代碼,我真的寫了一周時間,再次感謝視頻的作者及B站UP主,真心希望這篇文章對您有所幫助,加油~
- https://github.com/eastmountyxz/AI-for-Keras
(By:Eastmount 2021-01-05 周二寫于武漢 http://blog.csdn.net/eastmount/ )
2020年8月18新開的“娜璋AI安全之家”,主要圍繞Python大資料分析、網路空間安全、人工智能、Web滲透及攻防技術進行講解,同時分享CCF、SCI、南核北核論文的演算法實作,娜璋之家會更加系統,并重構作者的所有文章,從零講解Python和安全,寫了近十年文章,真心想把自己所學所感所做分享出來,還請各位多多指教,真誠邀請您的關注!謝謝,

參考文獻:
- https://www.bilibili.com/video/BV1Z5411477j - 誰用了我的白樺林
- 肖仰華《知識圖譜概念與技術》
- NLP在線醫生-BiLSTM+CRF命名物體識別 - 閣下兄
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/245215.html
標籤:python