- 『OCR深度實踐』OCR學習筆記(1):緒論
OCR 學習筆記
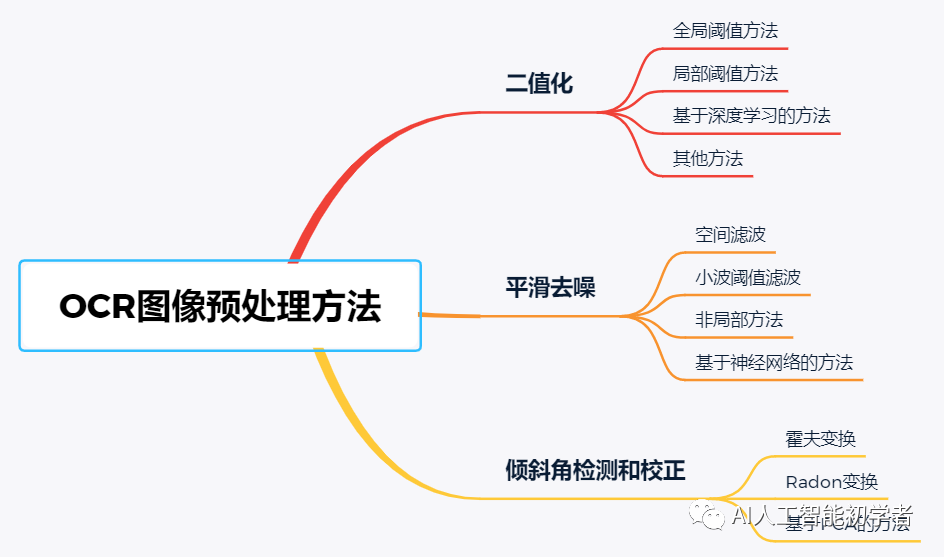
- 二、影像預處理
- 2.1 二值化
- 2.1.1 全域閾值方法
- 2.1.1.1 固定閾值方法
- 2.1.1.2 OTSU 閾值方法(基于直方圖)
- 2.1.2 區域閾值方法
- 2.1.2.1 自適應閾值演算法
- 2.1.2.2 Niblack 演算法
- 2.1.2.3 Sauvola 演算法
- 2.1.3 基于深度學習的方法
- 2.1.3.1 使用全卷積的二值化方法
- 2.1.4 基于影像處理的方法
- 2.2 平滑噪聲
- 2.2.1 空間濾波
- 2.2.1.1 線性空間濾波器
- 2.2.1.2 非線性空間濾波器
- 2.2.2 小波閾值去噪
- 2.2.2.1 硬閾值函式
- 2.2.2.2 軟閾值函式
- 2.2.3 非區域方法
- 2.2.4 基于神經網路的方法
- 2.3 傾斜角檢測和矯正
- 2.3.1 霍夫變換
- 2.3.2 Radon 變換
- 2.3.3 基于 PCA 的方法
二、影像預處理
2.1 二值化
- 定義: 影像的二值化,就是將影像上的像素點的灰度值設定為 0 或 255,也就是將整個影像呈現出明顯的只有黑和白的視覺效果,
- 優勢: 一方面減少了資料維度,另一方面通過排除原圖中噪聲帶來的干擾,可以凸顯有效區域的輪廓結構,
2.1.1 全域閾值方法
2.1.1.1 固定閾值方法
該方法是對于輸入影像中的所有像素點統一使用同一個固定閾值,
主要缺陷:很難為不同的輸入影像確定最佳閾值,
import cv2
import numpy as np
from tqdm import tqdm
image = cv2.imread("peng.png",0)
h = image.shape[0]
w = image.shape[1]
## 唯一確定閾值
a = 150
new_image = np.zeros((h,w),np.uint8)
for i in tqdm(range(h)):
for j in range(w):
if(image[i,j]> a ):
new_image[i,j] = 255
else:
new_image[i,j] = 0
cv2.imshow("new",new_image)
cv2.waitKey()
2.1.1.2 OTSU 閾值方法(基于直方圖)
OTSU 演算法又稱為
最大類間方差法;
基本原理: 用一個閾值將影像中的資料分為兩類,一類中影像的像素點的灰度均小于這個閾值,另一類中的影像的像素點的灰度均大于或者等于該閾值,如果這兩個類中像素點的灰度的方差越大,說明獲取到的閾值就是最佳的閾值,(底層原理才疏學淺,不知道怎么表述)
import cv2
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
### 大津法
def otsu(image):
h = image.shape[0]
w = image.shape[1]
m = h*w
otsuimg = np.zeros((h, w), np.uint8)
initial_threshold = 0
final_threshold = 0
# 初始化各灰度級個數統計引數
histogram = np.zeros(256, np.int32)
# 初始化各灰度級占影像中的分布的統計引數
probability = np.zeros(256, np.float32)
### 各個灰度級的個數統計
for i in tqdm(range(h)):
for j in range(w):
s = image[i,j]
histogram[s] = histogram[s] +1
### 各灰度級占影像中的分布的統計引數
for i in tqdm(range(256)):
probability[i] = histogram[i]/m
for i in tqdm(range(255)):
w0 = w1 = 0 ## 前景和背景的灰度數
fgs = bgs = 0 # 定義前景像素點灰度級總和背景像素點灰度級總和
for j in range(256):
if j <= i: # 當前i為分割閾值
w0 += probability[j] # 前景像素點占整幅影像的比例累加
fgs += j * probability[j]
else:
w1 += probability[j] # 背景像素點占整幅影像的比例累加
bgs += j * probability[j]
u0 = fgs / w0 # 前景像素點的平均灰度
u1 = bgs / w1 # 背景像素點的平均灰度
G = w0*w1*(u0-u1)**2
if G >= initial_threshold:
initial_threshold = G
final_threshold = i
print(final_threshold)
for i in range(h):
for j in range(w):
if image[i, j] > final_threshold:
otsuimg[i, j] = 255
else:
otsuimg[i, j] = 0
return otsuimg
### 首先將圖片轉化為灰度影像
image = cv2.imread("***.png")
gray = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
# 方法一:原理代碼實作
otsuimage = otsu(gray)
# 方法二:OpenCV 函式實作
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
print('threshold value: ', ret)
cv2.imshow('binary', binary)
2.1.2 區域閾值方法
2.1.2.1 自適應閾值演算法
主要思想: 以一個像素點為中心設定
s*s的滑窗,滑窗掃過整張圖片,每次掃描均對視窗內的像素求均值并將均值作為區域閾值,它的思想不是計算全域影像的閾值,而是根據影像不同區域亮度分布,計算其區域閾值,所以對于影像不同區域,能夠自適應計算不同的閾值,因此被稱為自適應閾值法,
adaptiveThreshold(
src, # 原始灰度影像
maxValue, # 像素值上限
adaptiveMethod, # 自適應方法
thresholdType, # 值的賦值方法
blockSize, # 規定鄰域大小(一個正方形的領域)
C, # 閾值等于均值或者加權值減去這個常數(為0相當于閾值,就是求得領域內均值或者加權值)
dst=None
)
自適應方法:
cv2.ADAPTIVE_THRESH_MEAN_C:鄰域內均值cv2.ADAPTIVE_THRESH_GAUSSIAN_C:鄰域內像素點加權和,權重為一個高斯視窗
值的賦值方法:
cv2.THRESH_BINARYcv2.THRESH_BINARY_INV
# 示例:
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
binary = cv2.adaptiveThreshold(gray,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,25,10)
2.1.2.2 Niblack 演算法
Niblack 演算法同樣是根據視窗內的像素值來計算區域閾值的,不同之處在于它不僅考慮到區域內像素點的均值和方差,還考慮到用一個事先設定的修正系數 k 來決定影響程度,
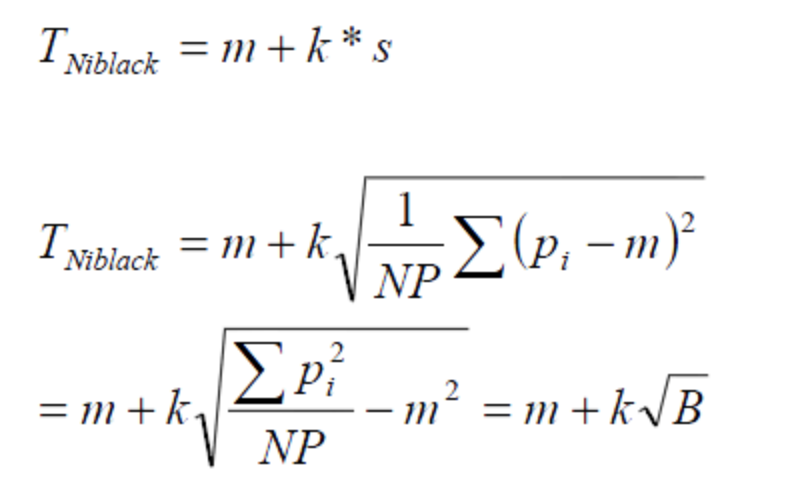
- T 是閾值,m 是影像鄰域視窗的均值,s 是鄰域視窗的標準差,K 是預先設定的修正值,
- Niblack法的優點:
對每一個像素點都獨立的根據此像素點的鄰域的情況來計算門限,與 m(x,y) 相近的像素點被判定為背景,反之則為前景,而相近的程度則由標準差和修正系數來決定,這樣做可以保證演算法的靈活性,- Niblack法的不足:
由于要利用域 r×r 模板遍歷影像,導致邊界區域(r-1)/2的像素范圍內無法求取閾值;同時當進行影像遍歷時,如果域 r×r 范圍內都是背景,經 Niblack 計算后必有一部分被確定為目標,產生偽噪聲,因此,r 的選擇非常關鍵,若視窗太小,則不能有效地抑制噪聲;若視窗太大,則會導致細節丟失,- 總之,用 Niblack 方法進行影像分割時,選擇的處理模板視窗
r*r大小的選擇很關鍵,選擇的空間太小,則噪聲抑制的效果不理想,目標主體不夠突出,選擇的空間太大,則目標的細節會被去除而丟失資訊,
2.1.2.3 Sauvola 演算法
- Sauvola 演算法的輸入是灰度影像,它以當前像素點為中心,根據當前像素點鄰域內的灰度均值與標準方差來動態計算該像素點的閾值,
- 假定當前像素點的坐標為 (x,y),以該點為中心的領域為 r*r,g(x,y) 表示 (x,y) 處的灰度值,Sauvola 演算法的步驟為:
step 1: 計算 r*r 鄰域內的灰度均值 m(x,y) 與標準方差 s(x,y);
step 2: 計算像素點 (x,y) 的閾值 T(x,y),


def integral(img):
'''
計算影像的積分和平方積分
:param img:Mat--- 輸入待處理影像
:return:integral_sum, integral_sqrt_sum:Mat--- 積分圖和平方積分圖
'''
integral_sum = np.zeros((img.shape[0],img.shape[1]),dtype=np.int32)
integral_sqrt_sum = np.zeros((img.shape[0],img.shape[1]),dtype=np.int32)
rows,cols = img.shape
for r in range(rows):
sum = 0
sqrt_sum = 0
for c in range(cols):
sum += img[r][c]
sqrt_sum += math.sqrt(img[r][c])
if r==0:
integral_sum[r][c] = sum
integral_sqrt_sum[r][c] = sqrt_sum
else:
integral_sum[r][c] = sum + integral_sum[r-1][c]
integral_sqrt_sum[r][c] = sqrt_sum + integral_sqrt_sum[r-1][c]
return integral_sum, integral_sqrt_sum
def sauvola(img,k=0.1,kernerl=(31,31)):
'''
sauvola閾值法,
根據當前像素點鄰域內的灰度均值與標準方差來動態計算該像素點的閾值
:param img:Mat--- 輸入待處理影像
:param k:float---修正引數,一般0<k<1
:param kernerl:set---視窗大小
:return:img:Mat---閾值處理后的影像
'''
if kernerl[0]%2!=1 or kernerl[1]%2!=1:
raise ValueError('kernerl元組中的值必須為奇數,'
'請檢查kernerl[0] or kernerl[1]是否為奇數!!!')
# 計算積分圖和積分平方和圖
integral_sum,integral_sqrt_sum=integral(img)
# integral_sum, integral_sqrt_sum = cv2.integral2(img)
# integral_sum=integral_sum[1:integral_sum.shape[0],1:integral_sum.shape[1]]
# integral_sqrt_sum=integral_sqrt_sum[1:integral_sqrt_sum.shape[0],1:integral_sqrt_sum.shape[1]]
#創建影像
rows,cols=img.shape
diff=np.zeros((rows,cols),np.float32)
sqrt_diff=np.zeros((rows,cols),np.float32)
mean=np.zeros((rows,cols),np.float32)
threshold=np.zeros((rows,cols),np.float32)
std=np.zeros((rows,cols),np.float32)
whalf=kernerl[0]>>1#計算領域類半徑的一半
for row in range(rows):
print('第{}行處理中...'.format(row))
for col in range(cols):
xmin=max(0,row-whalf)
ymin=max(0,col-whalf)
xmax=min(rows-1,row+whalf)
ymax=min(cols-1,col+whalf)
area=(xmax-xmin+1)*(ymax-ymin+1)
if area<=0:
sys.exit(1)
if xmin==0 and ymin==0:
diff[row,col]=integral_sum[xmax,ymax]
sqrt_diff[row,col]=integral_sqrt_sum[xmax,ymax]
elif xmin>0 and ymin==0:
diff[row, col] = integral_sum[xmax, ymax]-integral_sum[xmin-1,ymax]
sqrt_diff[row, col] = integral_sqrt_sum[xmax, ymax]-integral_sqrt_sum[xmin-1, ymax]
elif xmin==0 and ymin>0:
diff[row, col] = integral_sum[xmax, ymax] - integral_sum[xmax, ymax-1]
sqrt_diff[row, col] = integral_sqrt_sum[xmax, ymax] - integral_sqrt_sum[xmax, ymax-1]
else:
diagsum=integral_sum[xmax, ymax]+integral_sum[xmin-1, ymin-1]
idiagsum=integral_sum[xmax, ymin-1]+integral_sum[xmin-1, ymax]
diff[row,col]=diagsum-idiagsum
sqdiagsum=integral_sqrt_sum[xmax, ymax]+integral_sqrt_sum[xmin-1, ymin-1]
sqidiagsum=integral_sqrt_sum[xmax, ymin-1]+integral_sqrt_sum[xmin-1, ymax]
sqrt_diff[row,col]=sqdiagsum-sqidiagsum
mean[row,col]=diff[row, col]/area
std[row,col]=math.sqrt((sqrt_diff[row,col]-math.sqrt(diff[row,col])/area)/(area-1))
threshold[row,col]=mean[row,col]*(1+k*((std[row,col]/128)-1))
if img[row,col]<threshold[row,col]:
img[row,col]=0
else:
img[row,col]=255
return img
2.1.3 基于深度學習的方法
2.1.3.1 使用全卷積的二值化方法
看了效果很不錯,在公開的資料集中的表現性能很好,具體我還沒有去復現,到時來補全,
2.1.4 基于影像處理的方法
實作的方法步驟主要如下:
- 將 RGB 影像轉為灰度圖;
- 影像濾波處理;
- 數學形態學處理;
- 閾值計算,
濾波:
- 維納濾波(Wiener Filter):又稱為最小二值濾波器,是利用平穩隨機程序的相關特性和頻譜特性對混有噪聲的信號進行濾波,
- 高斯濾波(Gaussian Filter):是一種線性平滑濾波,適用于消除高斯噪聲,
數學形態學:
- 通過從影像中提取對表達和描繪區域形狀有意義的影像分量,使后續作業能夠抓住目標物件最具區分性的形狀特征,
- 基本運算包括:腐蝕、膨脹、開運算、閉運算
2.2 平滑噪聲
- 影像噪聲: 是指存在于影像資料中的不必要的或多余的干擾資訊,產生于影像的采集、量化或傳輸程序,對影像的后處理、分析均會產生極大的影響,噪聲的存在嚴重影響了影像的質量,因此在影像增強處理和分類處理之前,必須予以糾正, 影像中各種妨礙人們對其資訊接受的因素即可稱為影像噪聲 ,噪聲在理論上可以定義為
“不可預測,只能用概率統計方法來認識的隨機誤差”,- 平滑濾波: 是低頻增強的空間域濾波技術,它的目的有兩類:一類是
模糊;另一類是消除噪音,空間域的平滑濾波一般采用簡單平均法進行,就是求鄰近像元點的平均亮度值,鄰域的大小與平滑的效果直接相關,鄰域越大平滑的效果越好,但鄰域過大,平滑會使邊緣資訊損失的越大,從而使輸出的影像變得模糊,因此需合理選擇鄰域的大小,
2.2.1 空間濾波
- 空間濾波是一種采用濾波處理的影像增強方法,其理論基礎是空間卷積和空間相關,目的是改善影像質量,包括去除高頻噪聲與干擾,及影像邊緣增強、線性增強以及去模糊等,分為
低通濾波(平滑化)、高通濾波(銳化)和帶通濾波,- 空間濾波由一個鄰域和對該鄰域內像素執行的預定義操作組成,濾波器中心遍歷輸入影像的每個像素點之后就得到了處理后的影像,每經過一個像素點,鄰域中心坐標的像素值就替換為預定義操作的計算結果,
- 若在影像像素上執行的線性操作,則該濾波器稱為
線性空間濾波器,反之則稱為非線性空間濾波器,(PS: 后面的表述來源于一本書《基于深度學習的文字識別》)
2.2.1.1 線性空間濾波器
- 常見的有
平滑線性濾波器和高斯濾波器- 平滑線性濾波器: 輸出是包含在濾波器模板鄰域內像素的簡單平均值,因此也稱為
均值濾波器;- 高斯濾波器: 其模板系數隨著與模板中心距離的增大而減小,
2.2.1.2 非線性空間濾波器
- 常見的有
中值濾波器和雙邊濾波器- 中值濾波器: 首先是對鄰域內的值進行排序,中值作為輸出,該濾波器消除椒鹽噪聲的效果優于線性空間濾波器;
- 雙邊濾波器: 不僅如高斯濾波一樣考慮到像素間的歐式距離,還關注到像素范圍域中的輻射差異(如像素與中心點間的相似程度、顏色強度和深度距離等),這兩個權重域分別稱為:空間域 和 像素范圍域,
- 雙邊濾波器的好處是可以做 邊緣保存(edge preserving),一般用高斯濾波去降噪,會較明顯地模糊邊緣,對于高頻細節的保護效果并不明顯,雙邊濾波器顧名思義比高斯濾波多了一個高斯方差sigma-d,它是基于空間分布的高斯濾波函式,所以在邊緣附近,離的較遠的像素不會太多影響到邊緣上的像素值,這樣就保證了邊緣附近像素值的保存,但是由于保存了過多的高頻資訊,對于彩色影像里的高頻噪聲,雙邊濾波器不能夠干凈的濾掉,只能夠對于低頻資訊進行較好的濾波,
######## 四個不同的濾波器 #########
img = cv2.imread('img/test.png')
# 平滑線性濾波濾波
img_mean = cv2.blur(img, (5, 5))
# 高斯濾波
img_Guassian = cv2.GaussianBlur(img, (5, 5), 0)
# 中值濾波
img_median = cv2.medianBlur(img, 5)
# 雙邊濾波
dst = cv2.bilateralFilter(src=image, d=0, sigmaColor=100, sigmaSpace=15)
2.2.2 小波閾值去噪
小波閾值去噪的實質為抑制信號中無用部分、增強有用部分的程序,小波閾值去噪程序為:
- 分解程序,即選定一種小波對信號進行 n 層小波分解;
- 閾值處理程序,即對分解的各層系數進行閾值處理,獲得估計小波系數;
- 重構程序,據去噪后的小波系數進行小波重構,獲得去噪后的信號,
閾值的選擇是離散小波去噪中最關鍵的一步,閾值處理函式分為 硬閾值 和 軟閾值,
2.2.2.1 硬閾值函式
當小波系數的絕對值大于給定閾值時,小波系數不變;小于閾值時,小波系數置零,
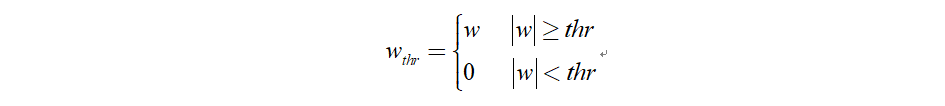
2.2.2.2 軟閾值函式
當小波系數的絕對值大于給定閾值時,令小波系數減去閾值;小于閾值時,小波系數置零,
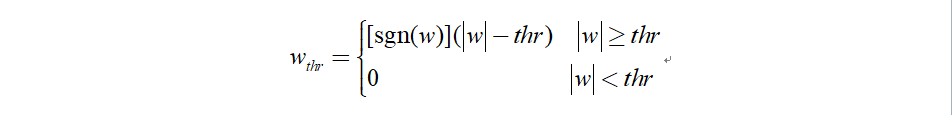
2.2.3 非區域方法
2.2.4 基于神經網路的方法
2.3 傾斜角檢測和矯正
2.3.1 霍夫變換

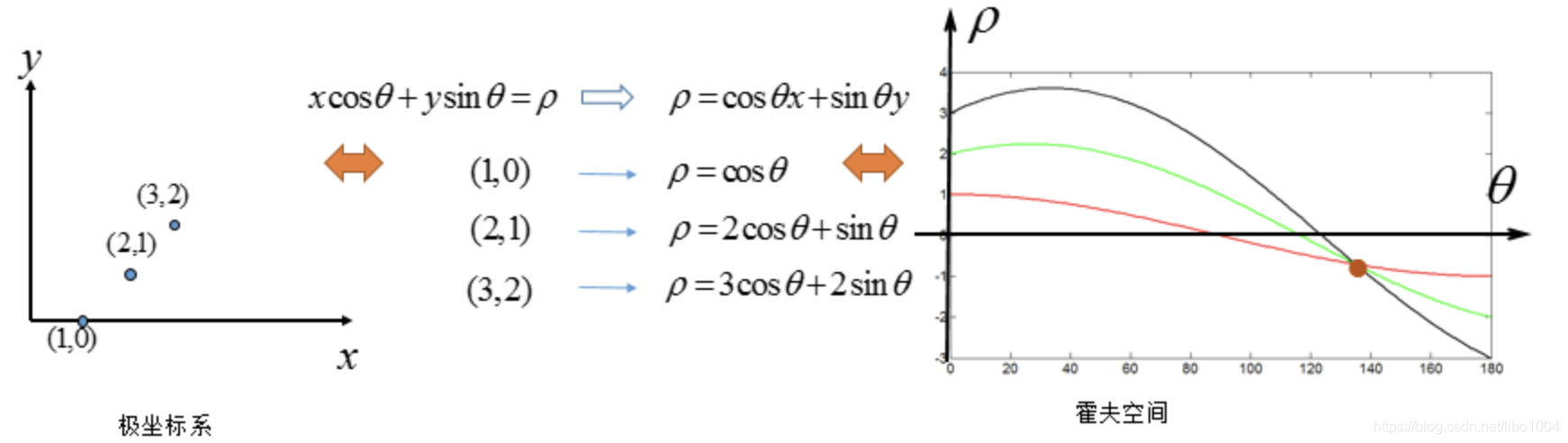
原理:若直線坐標系中的點共線,那么它們在霍夫空間中對應的曲線也必然相交于一點,
霍夫變換的后處理的基本方式:選擇由盡可能多直線匯成的點,
# 先通過 hough transform 檢測圖片中的圖片,計算直線的傾斜角度并實作對圖片的旋轉
import os
import cv2
import math
import random
import numpy as np
from scipy import misc, ndimage
filepath = './test_image'
for filename in os.listdir(filepath):
img = cv2.imread('./test_image/%s' % filename)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize=3
# 霍夫變換
lines = cv2.HoughLines(edges,1,np.pi/180,0)
for rho,theta in lines[0]:
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(x0 + 1000 * (-b))
y1 = int(y0 + 1000 * (a))
x2 = int(x0 - 1000 * (-b))
y2 = int(y0 - 1000 * (a))
if x1 == x2 or y1 == y2:
continue
t = float(y2-y1)/(x2-x1)
rotate_angle = math.degrees(math.atan(t))
if rotate_angle > 45:
rotate_angle = -90 + rotate_angle
elif rotate_angle < -45:
rotate_angle = 90 + rotate_angle
rotate_img = ndimage.rotate(img, rotate_angle)
misc.imsave('./test_image/%s' % filename, rotate_img)
2.3.2 Radon 變換
Radon 變換以線積分的形式將影像投影到 ( s , θ s, \theta s,θ) 空間,
與霍夫的區別:霍夫變換是直線引數變換的離散形式,Radon 變換則是直線引數變換的連續形式,
from scipy import ndimage
import numpy as np
import matplotlib.pyplot as plt
import imageio
from cv2 import cv2
def DiscreteRadonTransform(image, steps):
channels = len(image[0])
res = np.zeros((channels, channels), dtype='float64')
for s in range(steps):
rotation = ndimage.rotate(image, -s*180/steps, reshape=False).astype('float64')
res[:,s] = sum(rotation)
return res
# 讀取原始圖片
# image = cv2.imread("test.png", cv2.IMREAD_GRAYSCALE)
image = imageio.imread('test.jpg').astype(np.float64)
radon = DiscreteRadonTransform(image, len(image[0]))
print(radon.shape)
# 繪制原始影像和對應的 sinogram 圖
plt.subplot(1, 2, 1)
plt.imshow(image, cmap='gray')
plt.subplot(1, 2, 2)
plt.imshow(radon, cmap='gray')
plt.show()
2.3.3 基于 PCA 的方法
PCA 演算法需要計算對傾斜角度的分布具有最大影響的特征向量,即分布的主分量,因此首先需要將黑色像素點(即前景)映射為二維向量,使每個像素點與相同坐標的二維向量相匹配,并對每個維度減去其對應強度的均值,然后計算向量幾何的協方差矩陣,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/245216.html
標籤:python
上一篇:[Python人工智能] 二十六.基于BiLSTM-CRF的醫學命名物體識別研究(上)資料預處理
下一篇:Python實作小游戲2048