本文以此圖為例
列坐標中,第 0 列代表的是序號,第 1 列代表的會員的姓名,第 2 列代表年齡,第 3 列代表體重,第 4~6 列代表男性會員的三圍尺寸,第 7~9 列代表女性會員的三圍尺寸,
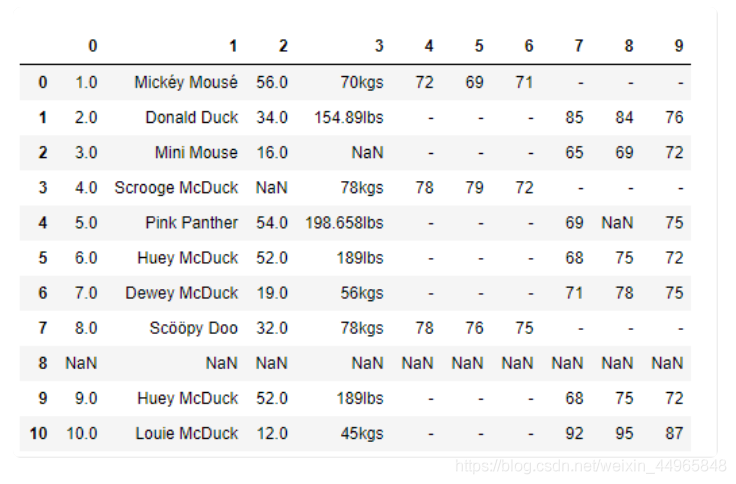
1.缺失值
在資料中有NaN和“-”,代表缺失值,如何補足缺失值呢?
- 洗掉資料缺失的記錄
- 使用當前列的均值
- 使用當前列出現頻率最高的資料
2.空行
一整行都為空:直接洗掉全空的行
df.dropna(how="all",inplace=True)
3.列資料單位不統一
在體重一列,出現的單位有:kg、lbs,我們需要統一單位,
# 獲取 weight 資料列中單位為 lbs 的資料
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
print(df[rows_with_lbs])
# 將 lbs轉換為 kgs, 2.2lbs=1kgs
for i,lbs_row in df[rows_with_lbs].iterrows():
# 截取從頭開始到倒數第三個字符之前,即去掉lbs,
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
4.非ASCII字符
直接洗掉非ASCII字符
# 洗掉非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
5.一列有多個引數
一列中包含不止一個引數的情況需要拆分欄位,盡量使欄位資訊不可再分,
# 切分名字,洗掉源資料列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
6.重復資料
需要去重
# 洗掉重復資料行
df.drop_duplicates(['first_name','last_name'],inplace=True)
7.完整代碼
import pandas as pd
from pandas import DataFrame
# 將Excel存入Dataframe
df = pd.read_excel('accountMessage.xlsx')
# print(df)
# 洗掉空行和沒用的列,這一步要在填充缺失值前做,不然填充完之后就沒空行了
df = df.drop(['\t', 0], axis=1)
df.dropna(how='all', inplace=True)
# print(df)
# 用均值填充年齡缺失值
df[2].fillna(df[2].mean(), inplace=True)
df[2] = df[2].apply(int)
# print(df)
# 統一體重列單位為kg
rows_lbs = df[3].str.contains('lbs').fillna(False)
# print(df[rows_lbs])
for i, lbs_row in df[rows_lbs].iterrows(): # 使用iterrows()對df進行遍歷
weight = int(float(lbs_row[3][:3]) / 2.2) # lbs->kg換算
df.at[i, 3] = '{}kg'.format(weight)
rows_kgs = df[3].str.contains('kgs').fillna(False) # 把kgs改成kg
for i, lbs_kgs in df[rows_kgs].iterrows():
weight = int(float(lbs_row[3][:3]))
df.at[i, 3] = '{}kg'.format(weight)
# print(df)
# 拆分姓名列
df[['first_name', 'last_name']] = df[1].str.split(expand=True)
df.drop(1, axis=1, inplace=True)
# print(df)
# 去重
df.drop_duplicates(['first_name', 'last_name'], inplace=True)
# print(df)
#改個列名,調整列順序
df.columns = ['Age', 'Weight', 'BWH1_man', 'BWH2_man', 'BWH3_man',
'BWH1_woman', 'BWH2_woman', 'BWH3_woman', 'first_name', 'last_name']
df = df[['first_name', 'last_name', 'Age', 'Weight', 'BWH1_man', 'BWH2_man', 'BWH3_man',
'BWH1_woman', 'BWH2_woman', 'BWH3_woman']]
# print(df)
#存入csv
df.to_csv('Message.csv')
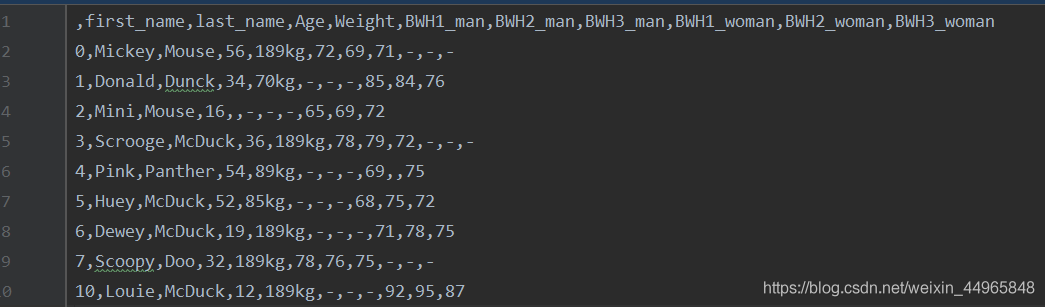
結果如下
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246852.html
標籤:python
上一篇:A 演算法 Python實作