本文是Python學期實訓時所寫的爬蟲專案,在這里分享給你,希望能對你有所幫助,
文章目錄
?
??找到網頁中有價值的內容及其所處在原始碼中的位置
?
??撰寫爬蟲代碼,將資訊爬取下來并保存到本地檔案中,
?
??將爬取到的資料進行分析,
?
內容部分:
?一.找到網頁中有價值的內容及其所處在原始碼中的位置
??英雄聯盟官方網址:?英雄聯盟全新官方網站-騰訊游戲
??英雄資料資訊網址:?游戲資料-英雄聯盟官方網站-騰訊游戲
??本小節操作的目的是:找出官網上對自己有價值的資訊及其所在網頁源代碼中的位置,
?第一步:分析網頁資訊
??所有的英雄頁:
??在英雄聯盟—游戲資料中,展示了所有的英雄資料,包括有原皮膚,英雄名以及英雄資訊資訊的網址鏈接,通過按下 F12 鍵我們可以查看到網頁的源代碼,展示如下:
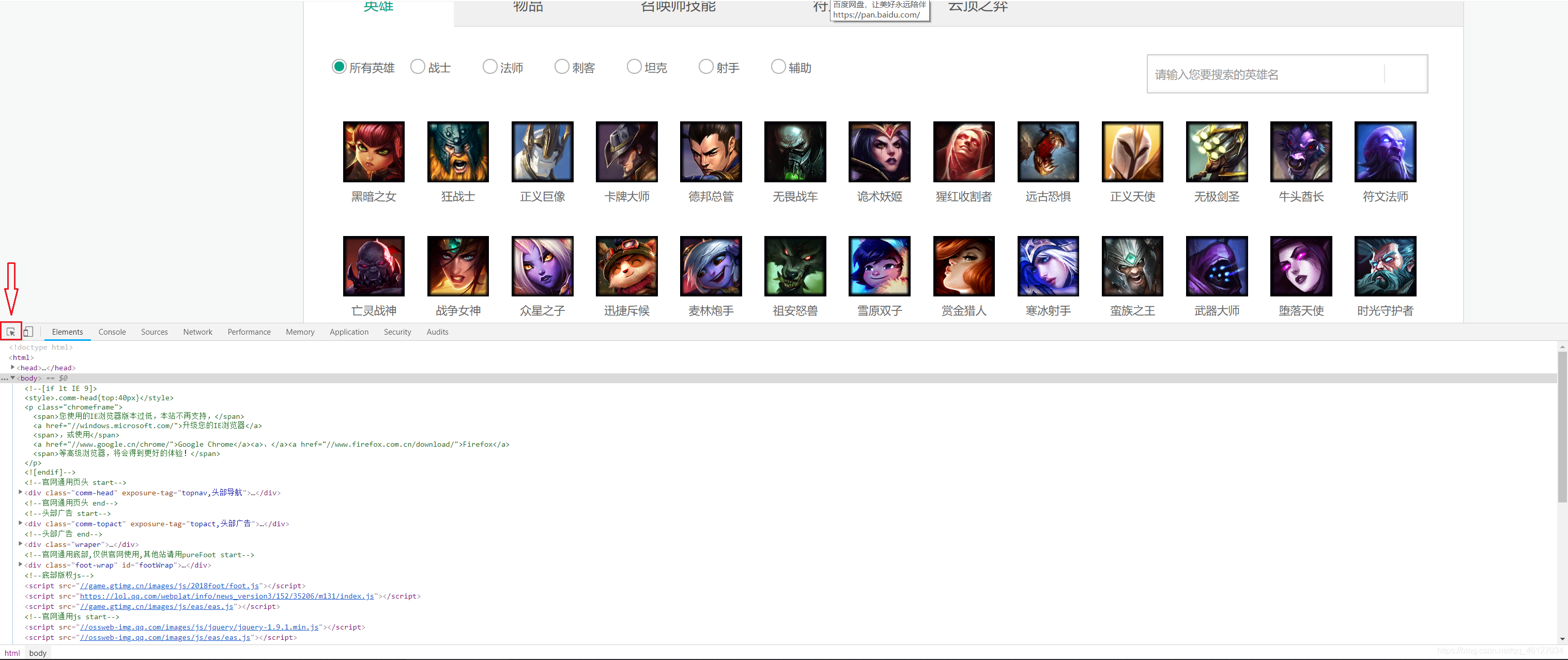
??為了方便我們快速獲取網頁中某一部分的原始碼資訊,我們可以點擊螢屏中間位置最左邊的箭頭圖示,去網頁中找到該部分對應資訊的源代碼,( 在這里小編以安妮為例 )
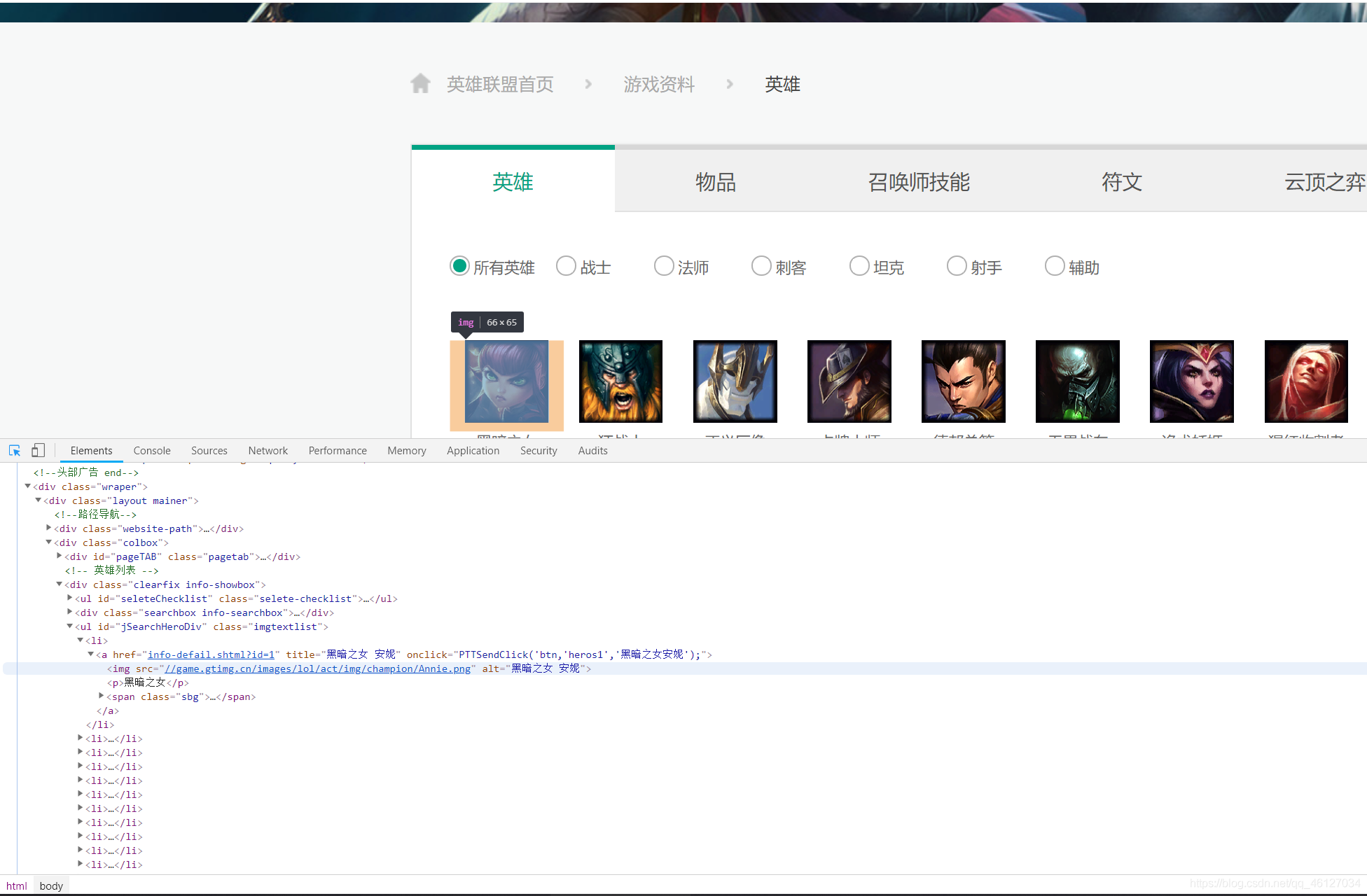
??在此我們可以分析得出,一個<li>標簽下放置著一個英雄的部分資訊,其中,英雄詳細資訊的地址鏈接放置在 a 標簽的 href 屬性中,英雄的姓名全稱放置在 a 標簽的 title 屬性中,英雄原皮膚圖片地址鏈接放置在 img 標簽下的 src 屬性中,英雄的簡稱姓名放置在 p 標簽中,
??當我們點擊進入英雄詳細資訊的展示頁面時,通過同樣的方法我們可以得到以下內容:
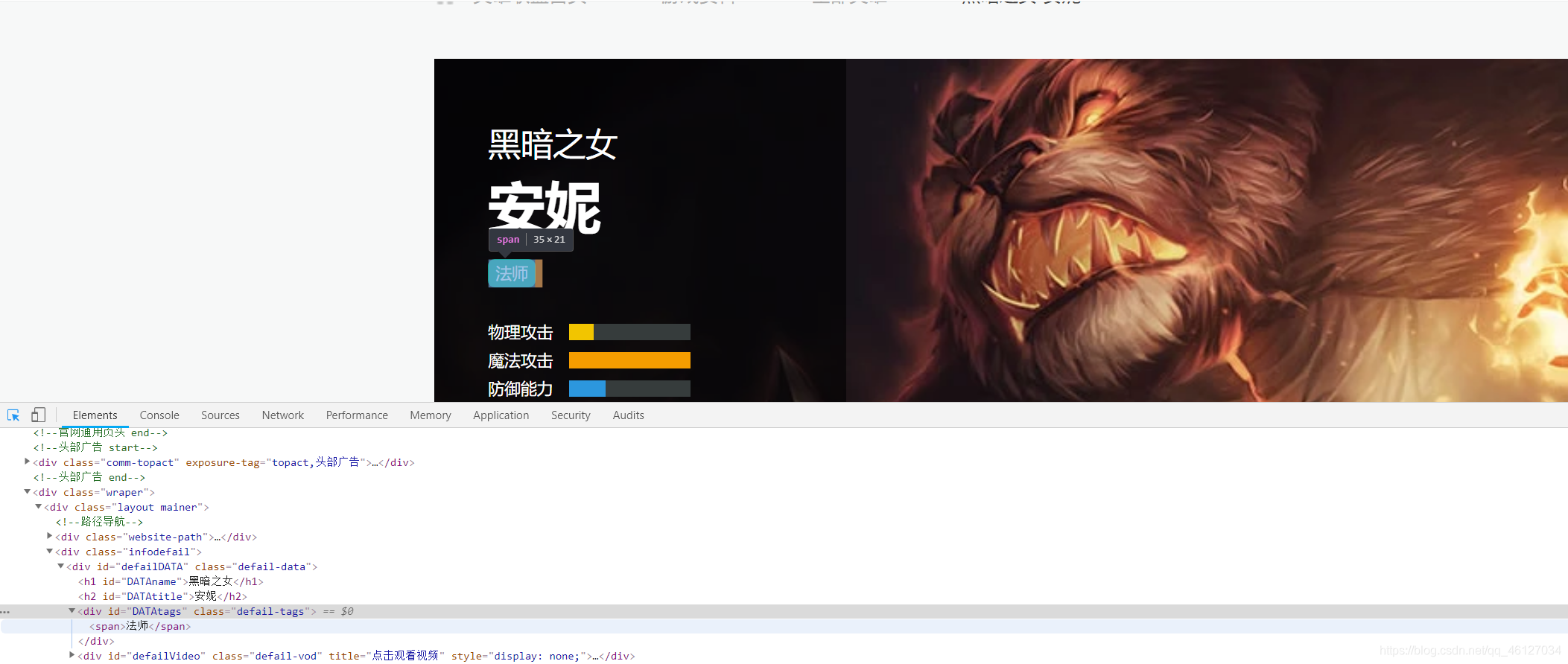
??單個英雄職業資訊:
??英雄的職業資訊是放置在 id 為 “DATA tags” 的 div 容器下的 span 標簽中,
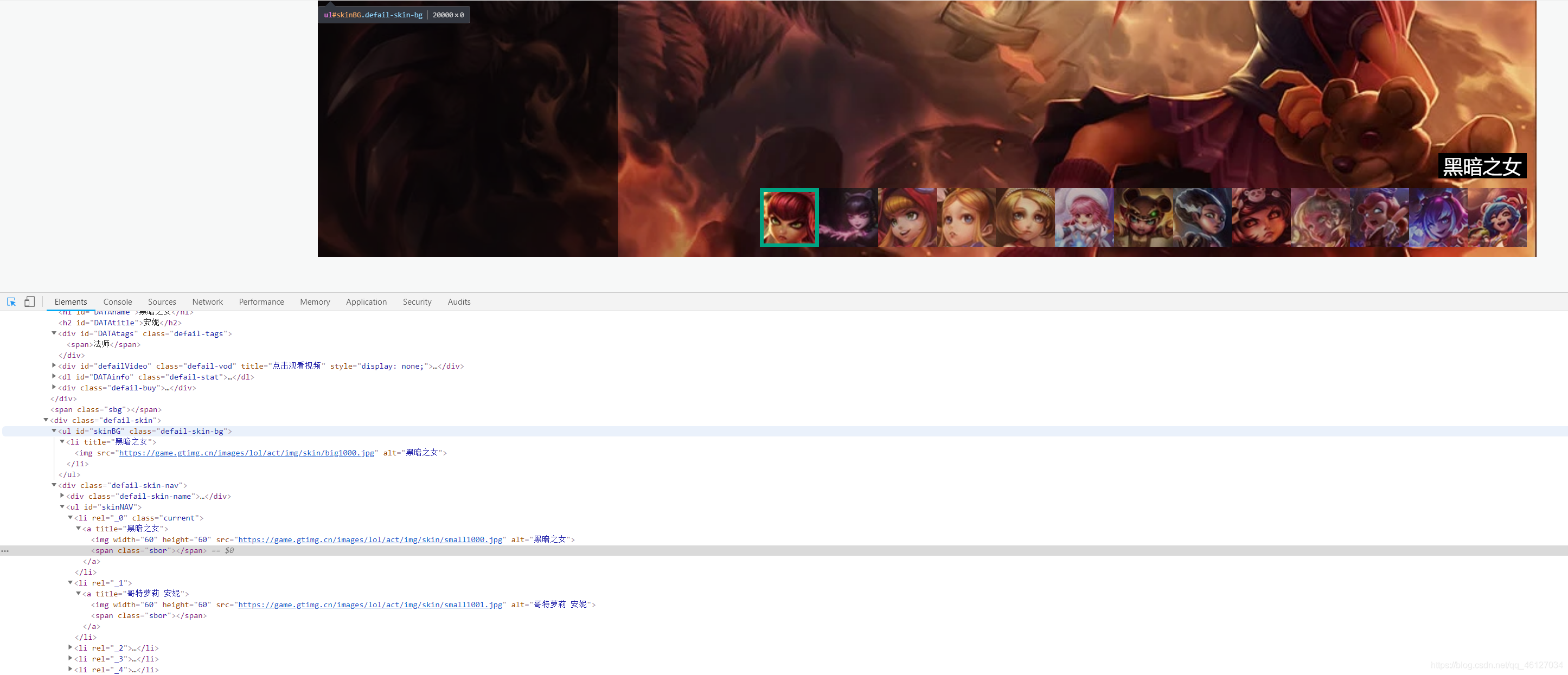
??單個英雄皮膚資訊:
??英雄的所有皮膚資訊被放置在 id 為 “skinNAV” 的 ul 容器下的 li 標簽中,在每一個 li 標簽內的 a 標簽內的 img 標簽中的 alt 屬性存放的是英雄皮膚的名字, src 屬性存放的是英雄每個皮膚的圖片網址,
??單個英雄背景故事:
??英雄的背景故事資訊被放置在 id 為 “DATAlore” 的 div 容器中,但是內容并不完整,通過點擊 id 為 “Gmore”的 a 標簽,可以將英雄的背景故事資訊完整的添加在 id 為 “DATAlore” 的 div 容器中展示出來,

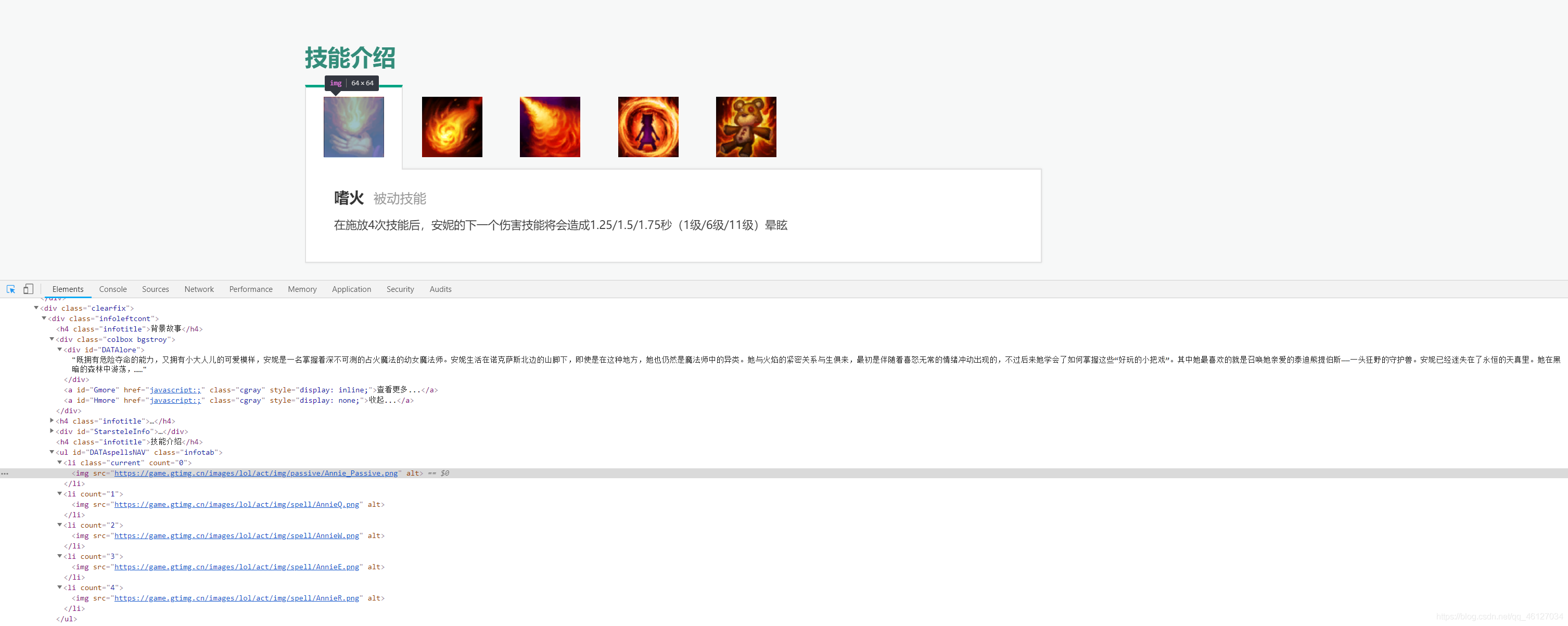
??單個英雄技能資訊:
??英雄技能資訊被放置在 class 名為 “skilltitle” 的 div 容器下,h5 標簽中放置的是英雄的技能名,em 標簽中放置的是技能觸發方式,通過點擊 id 為 “DATAspellsNAV” 的 ul 標簽下的每個 li 標簽,可以將 class 名為 “skilltitle” 的 div 容器中的資訊修改成別的技能介紹,
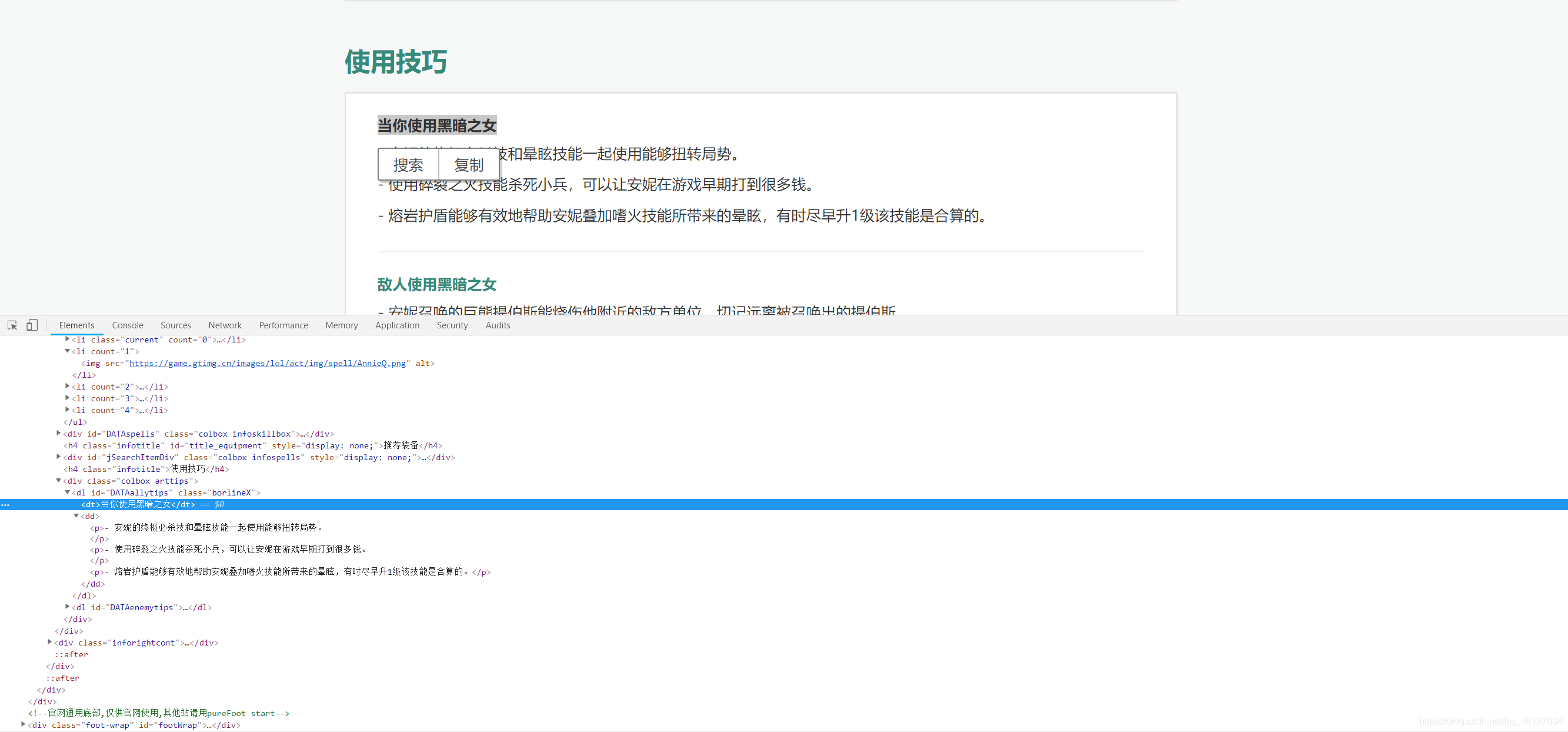
??當你使用某一英雄時的使用技巧:
??當你使用某一英雄時的使用技巧介紹被放在 id 為 “DATAallytips” 的 dl 標簽下的 dd 標簽下的所有 p 標簽中,
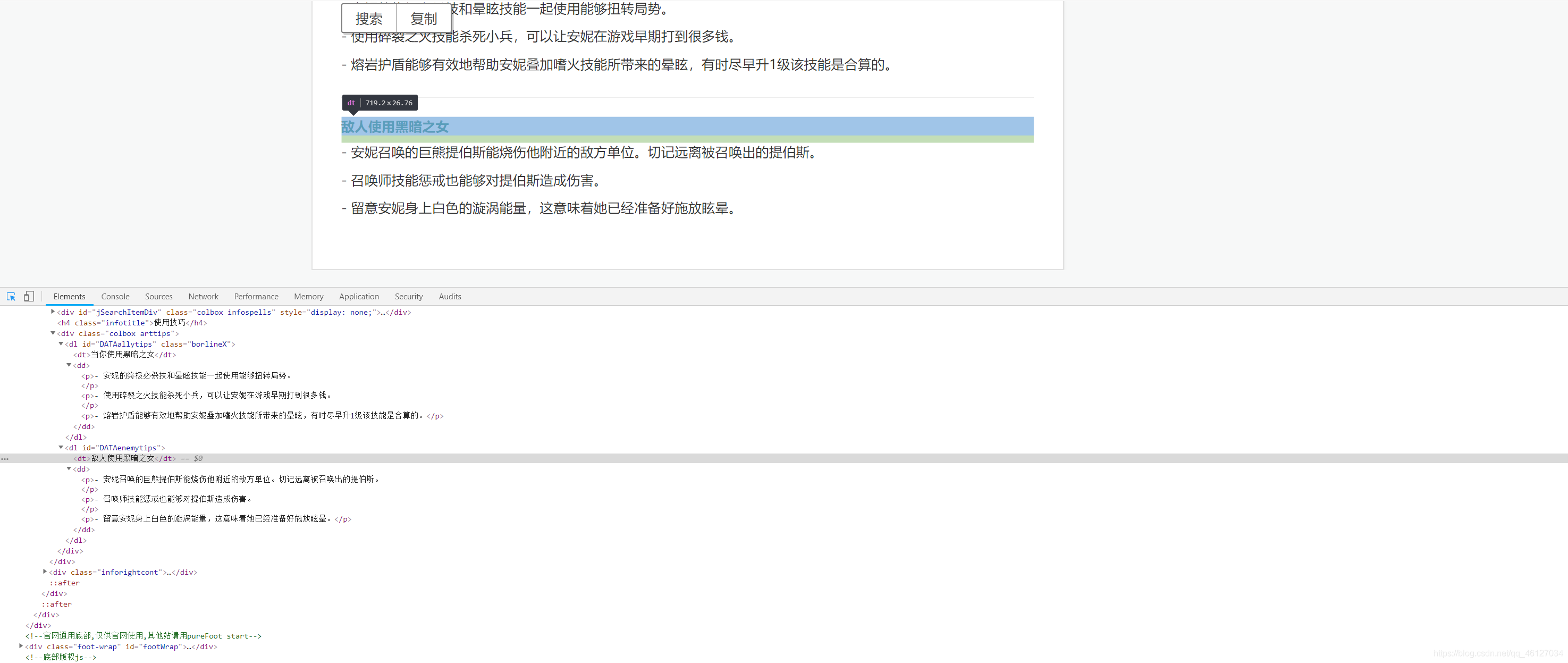
??當敵人使用某一英雄時的應對技巧:
??當敵人使用某一英雄時的應對技巧介紹被放在 id 為 “DATAenemytips” 的 dl 標簽下的 dd 標簽下的所有 p 標簽中,
??綜上所述,我們已經找到了對自己有用的資訊,也找到了資訊所在網頁原始碼中的位置,接下來要做的就是使用爬蟲代碼,將資訊爬取下來并保存到本地檔案中,
?二.撰寫爬蟲代碼,將資訊爬取下來并保存到本地檔案中,
```python
# 匯入必要的庫檔案
# 匯入selenium抓取動態網頁資訊
from selenium import webdriver
# 匯入時間控制器
import time
# 匯入正則運算式
import re
from urllib.request import urlretrieve
import os
from xlutils import copy
import xlrd
# 定義全域變數
# 所有的英雄全名及其詳細資訊的網址
allHeroParticularlyMessageUrl = []
heroNameList = []
heroJobList = []
heroSkinNumberList = []
heroPassiveSkillsList = []
heroQSkillsList = []
heroWSkillsList = []
heroESkillsList = []
heroRSkillsList = []
heroMessageList = []
# 主程式
def main():
# 定義一個計數器
count = 1
#定義存盤的起始位置
start = 1
#定義結束位置
end = ""
#創建皮膚圖片保存目錄
imageFilePath = 'C:/Users/24010/Desktop/skinImages'
if not os.path.exists(imageFilePath):
os.mkdir(imageFilePath)
print("...開始爬取資料...")
# 定義初始爬取網頁的URL
basciPageUrl = "https://lol.qq.com/data/info-heros.shtml"
print("...爬取所有的英雄全名及其詳細資訊的網址執行中...")
seleniumForGetAllHeroURL(basciPageUrl)
excel_path = './heroBasicInformationExcel.xls' # 檔案路徑
rbook = xlrd.open_workbook(excel_path, formatting_info=True) # 打開檔案
book = copy.copy(rbook) # 復制檔案并保留格式
sheet = book.get_sheet(0) # 索引sheet表
# 獲取每個英雄的詳細詳細資訊
for oneHeroUrl in allHeroParticularlyMessageUrl:
#保存中斷后,可修改start的值,繼續修改
if end == "":
if start <= count:
print("開始保存第" + str(count) + "個英雄的資料!")
saveDate("開始保存第" + str(count) + "個英雄的資料!", "a")
saveDate("", "a")
seleniumForGetHeroAllMessage(oneHeroUrl[1], count)
saveDateInExcel(count - 1, book, sheet)
else:
pass
else:
if start <= count <= end:
print("開始保存第" + str(count) + "個英雄的資料!")
saveDate("開始保存第" + str(count) + "個英雄的資料!", "a")
saveDate("", "a")
seleniumForGetHeroAllMessage(oneHeroUrl[1], count)
saveDateInExcel(count - 1, book, sheet)
else:
pass
count = count + 1
# 獲取所有的英雄全名及其詳細資訊的網址
def seleniumForGetAllHeroURL(basciPageUrl):
# 打開瀏覽器
browser = webdriver.Chrome()
# 訪問網頁
browser.get(basciPageUrl)
time.sleep(20)
# 查找資訊
getli = browser.find_element_by_id('jSearchHeroDiv').find_elements_by_tag_name('li')
for Everyone in getli:
EveryoneUrl = Everyone.find_element_by_tag_name('a').get_attribute('href')
EveryoneTitle = Everyone.find_element_by_tag_name('a').get_attribute('title')
allHeroParticularlyMessageUrl.append([EveryoneTitle, EveryoneUrl])
browser.close()
print("...爬取所有的英雄全名及其詳細資訊的網址并存盤完成...")
# 獲取該英雄的詳細資訊
def seleniumForGetHeroAllMessage(heroMessageUrl, count):
# 打開瀏覽器
browser = webdriver.Chrome()
while True:
# 訪問網頁
browser.get(heroMessageUrl)
time.sleep(5)
browser.execute_script('window.scrollTo(0, 0)')
time.sleep(2)
# 滑動頁面
browser.execute_script('window.scrollBy(0, document.body.scrollHeight*0.2)')
time.sleep(1)
browser.execute_script('window.scrollBy(0, document.body.scrollHeight*0.2)')
time.sleep(1)
browser.execute_script('window.scrollBy(0, document.body.scrollHeight*0.2)')
time.sleep(1)
browser.execute_script('window.scrollBy(0, document.body.scrollHeight*0.2)')
time.sleep(1)
# 獲取到查看更多按鈕
button = browser.find_element_by_class_name('cgray')
# 點擊上步按鈕
button.click()
# <---time.sleep()必須寫,網速不佳的話,適當延長時間--->
time.sleep(1)
if len(browser.find_element_by_id('skinNAV').find_elements_by_tag_name("li")) > 1:
break
else:
print("訪問此頁面時網路不佳-->" + heroMessageUrl)
time.sleep(10)
# 獲取基本資訊
findMostmessage(browser, heroMessageUrl)
# 獲取完基本資訊后再將頁面到滾動條的五分之三處
browser.execute_script('window.scrollTo(0, document.body.scrollHeight*0.6)')
# <---time.sleep()必須寫,網速不佳的話,適當延長時間--->
time.sleep(1)
# 獲取英雄技能
findHeroAllSkills(browser, count)
# ...查找...
def findMostmessage(browser, heroMessageUrl):
# ----------------------------------------查找資訊---------------------------------------------
# 英雄名
thisHeroName = browser.find_element_by_id('DATAname').text + browser.find_element_by_id('DATAtitle').text
# 英雄職業
thisHeroJob = browser.find_element_by_id('DATAtags').find_element_by_tag_name('span').text
# 英雄背景故事
thisHeroStory = browser.find_element_by_id('DATAlore').text
# 自己使用該英雄時的技巧
tipsForUsToUseThisHero = ""
# 敵人使用該英雄時的技巧
tipsForEnemyUseThisHero = ""
# 皮膚名稱及其圖片鏈接
heroSkinImgs = []
# -----------------------------------------查找資訊---------------------------------------------
# 技巧對應的英雄名
whileYouUseWhichHero = browser.find_element_by_id('DATAallytips').find_element_by_tag_name('dt').text
whileEnemyUseWhichHero = browser.find_element_by_id('DATAenemytips').find_element_by_tag_name('dt').text
# 自己使用時的技巧合集
tipListForUsToUseThisHero = browser.find_element_by_id('DATAallytips').find_element_by_tag_name(
'dd').find_elements_by_tag_name('p')
# 別人使用時的技巧合集
tipListForEnemyUseThisHero = browser.find_element_by_id('DATAenemytips').find_element_by_tag_name(
'dd').find_elements_by_tag_name('p')
# 自己使用時的技巧字串
for tip in tipListForUsToUseThisHero:
tipsForUsToUseThisHero = tipsForUsToUseThisHero + tip.text[1:len(tip.text)]
tipsForUsToUseThisHero = "4," + whileYouUseWhichHero + " : " + tipsForUsToUseThisHero
# 敵人使用時的技巧字串
for tip in tipListForEnemyUseThisHero:
tipsForEnemyUseThisHero = tipsForEnemyUseThisHero + tip.text[1:len(tip.text)]
tipsForEnemyUseThisHero = "5," + whileEnemyUseWhichHero + " : " + tipsForEnemyUseThisHero
# -------------------------------------查找圖片-------------------------------------------
heroSkinImg = browser.find_element_by_id('skinNAV').find_elements_by_tag_name('li')
heroSkillImgsLi = browser.find_element_by_id('DATAspellsNAV').find_elements_by_tag_name('li')
findHeroSkillSrcNumber = re.compile(r'act/img/skin/small(.*?).jpg')
#創建目錄
path1 = "C:/Users/24010/Desktop/skinImages/" + thisHeroName
if not os.path.exists(path1):
os.mkdir(path1)
#回圈該英雄皮膚url
for img in heroSkinImg:
heroSkinName = img.find_element_by_tag_name('a').get_attribute('title')
smalllImgsrc = img.find_element_by_tag_name('img').get_attribute('src')
HeroSkillSrcNumber = re.findall(findHeroSkillSrcNumber, str(smalllImgsrc))[0]
#重新拼接圖片url
heroSkinImgUrl = "https://game.gtimg.cn/images/lol/act/img/skin/big" + HeroSkillSrcNumber + ".jpg"
#拼接圖片保存地址
if heroSkinImgUrl != "https://game.gtimg.cn/images/lol/act/img/skin/big235010.jpg":
path2 = path1 + "/image" + HeroSkillSrcNumber + ".jpg"
#保存圖片為本地檔案
urlretrieve(heroSkinImgUrl, path2)
heroSkinImgs.append([heroSkinName, heroSkinImgUrl])
# 創建目錄
skillpath1 = "C:/Users/24010/Desktop/skinImages/" + thisHeroName + "/技能圖片"
if not os.path.exists(skillpath1):
os.mkdir(skillpath1)
jineng = ["被動技能", "Q技能", "W技能", "E技能", "R技能"]
i = 0
# 回圈該英雄技能url
for img in heroSkillImgsLi:
heroSkillImgUrl = img.find_element_by_tag_name("img").get_attribute('src')
# 拼接圖片保存地址
skillpath = skillpath1 + "/" + jineng[i] + ".png"
# 保存圖片為本地檔案
urlretrieve(heroSkillImgUrl, skillpath)
i = i + 1
# ----------------------------保存資料---------------------
saveDate(thisHeroName + " 詳細資訊網址 " + heroMessageUrl, "a")
heroMessageList.append(heroMessageUrl)
saveDate("", "a")
saveDate("1,英雄名:" + thisHeroName, "a")
heroNameList.append(thisHeroName)
saveDate("", "a")
saveDate("2,英雄職業:" + thisHeroJob, "a")
heroJobList.append(thisHeroJob)
saveDate("", "a")
saveDate("3,英雄背景故事:" + thisHeroStory, "a")
saveDate("", "a")
saveDate(tipsForUsToUseThisHero, "a")
saveDate("", "a")
saveDate(tipsForEnemyUseThisHero, "a")
saveDate("", "a")
#圖片個數
imgcount = 0
for img in heroSkinImgs:
imgcount = imgcount + 1
date = "6." + str(imgcount) + img[0] + " : " + img[1]
#保存皮膚名和圖片鏈接到txt檔案里面
saveDate(date, "a")
heroSkinNumberList.append(imgcount)
saveDate("", "a")
# ...查找英雄技能及其介紹
def findHeroAllSkills(browser, count):
# 獲取技能點擊串列
button = browser.find_element_by_id('DATAspellsNAV').find_elements_by_tag_name('li')
# 逐個點擊技能按鈕
#定義計數器
skillcount = 7
for i in range(0, 5):
# 點擊第i個按鈕
button[i].click()
# <---time.sleep()必須寫,網速不佳的話,適當延長時間--->
time.sleep(1)
skillName = browser.find_element_by_class_name('skilltitle').find_element_by_tag_name('h5').text
saveDate(str(skillcount) + ".1,技能名稱:" + skillName, "a")
skillTriggerMode = browser.find_element_by_class_name('skilltitle').find_element_by_tag_name('em').text
saveDate(str(skillcount) + ".2,技能觸發方式:" + skillTriggerMode, "a")
skillInformation = browser.find_element_by_id('DATAspells').find_element_by_tag_name('p').text
saveDate(str(skillcount) + ".3,技能內容介紹:" + skillInformation, "a")
saveDate("", "a")
skillcount = skillcount + 1
#存技能名
if i == 0:
heroPassiveSkillsList.append(skillName)
if i == 1:
heroQSkillsList.append(skillName)
if i == 2:
heroWSkillsList.append(skillName)
if i == 3:
heroESkillsList.append(skillName)
if i == 4:
heroRSkillsList.append(skillName)
saveDate("", "a")
saveDate("", "a")
# 關閉瀏覽器
browser.close()
print("第" + str(count) + "條英雄資料保存成功!")
# ------------------------------保存資料---------------------------------
def saveDate(date, mode):
filename = 'allHeroMessages.txt'
with open(filename, mode, encoding='utf-8') as f:
f.write(date + "\n")
#------------------------------保存到Excel-----------------------------
def saveDateInExcel(j, book, sheet):
col = ["英雄名稱", "英雄職業", "英雄皮膚數量", "被動技能名稱", "Q技能名稱", "W技能名稱", "E技能名稱", "R技能名稱", "英雄資訊鏈接"]
if j == 0:
for i in range(0, 9):
sheet.write(0, i, col[i])
sheet.write(j+1, 0, heroNameList[0])
sheet.write(j + 1, 1, heroJobList[0])
sheet.write(j + 1, 2, heroSkinNumberList[0])
sheet.write(j + 1, 3, heroPassiveSkillsList[0])
sheet.write(j + 1, 4, heroQSkillsList[0])
sheet.write(j + 1, 5, heroWSkillsList[0])
sheet.write(j + 1, 6, heroESkillsList[0])
sheet.write(j + 1, 7, heroRSkillsList[0])
sheet.write(j + 1, 8, heroMessageList[0])
heroNameList.clear()
heroJobList.clear()
heroSkinNumberList.clear()
heroPassiveSkillsList.clear()
heroQSkillsList.clear()
heroWSkillsList.clear()
heroESkillsList.clear()
heroRSkillsList.clear()
heroMessageList.clear()
book.save('./heroBasicInformationExcel.xls') # 保存檔案
# 呼叫主程式,開始執行本程式
if __name__ == "__main__":
main()
print("...執行完成...")
《解釋部分等我有時間再更新,如果你直接copy我的代碼到你編輯器,大概率你是運行不出來的,奸笑中~~》
?三.將爬取到的資料進行分析,
?資料如下:
如果覺得本文寫的還不錯的話,求贊、求收藏、求關注、求轉發、最重要的是給小博主點個大大的訂閱,你的鼓勵就是我前進的最大動力,我們下期再見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246853.html
標籤:python
上一篇:資料分析基礎01|資料清洗問題