深度學習 自組織映射網路 ——python實作SOM(用于聚類)
- 摘要
- python實作代碼
- 計算實體
摘要
SOM(Self Organizing Maps ) 的目標是用低維目標空間的點來表示高維空間中的點,并且盡可能保持對應點的距離和鄰近關系(拓撲關系),該演算法可用于降維和聚類等方面,本文通過python實作了該演算法在聚類方面的應用,并將代碼進行了封裝,方便讀者呼叫,
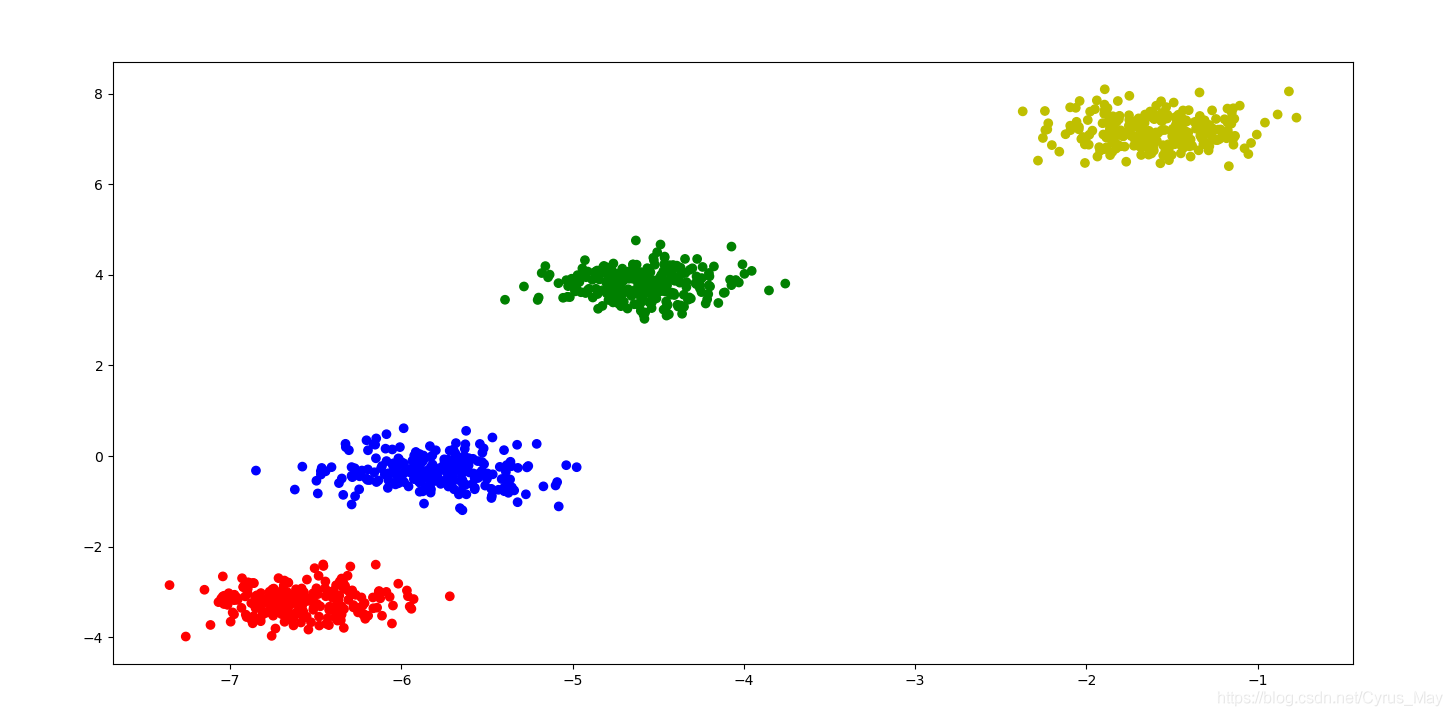
下圖為正文計算實體的可視化圖形,
python實作代碼
net:競爭層的拓撲結構,支持一維及二維,1表示該輸出節點存在,0表示不存在該輸出節點
epochs:最大迭代次數
.r_t:[C,B] 領域半徑引數,r = C*e**(-B * t/eoochs),其中t表示當前迭代次數
eps:[C,B] learning rate的閾值
用法:指定競爭層的拓撲結構、 最大迭代次數、領域半徑引數、學習率閾值(后三個引數也可不指定),競爭層的拓撲結構的節點數代表了聚類數目,然后直接呼叫fit(X) 進行資料集的聚類,
# -*- coding: utf-8 -*-
# @Time : 2021/1/12 22:37
# @Author : CyrusMay WJ
# @FileName: SOM.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/Cyrus_May
import numpy as np
import random
np.random.seed(22)
class CyrusSOM(object):
def __init__(self,net=[[1,1],[1,1]],epochs = 50,r_t = [None,None],eps=1e-6):
"""
:param net: 競爭層的拓撲結構,支持一維及二維,1表示該輸出節點存在,0表示不存在該輸出節點
:param epochs: 最大迭代次數
:param r_t: [C,B] 領域半徑引數,r = C*e**(-B*t/eoochs),其中t表示當前迭代次數
:param eps: learning rate的閾值
"""
self.epochs = epochs
self.C = r_t[0]
self.B = r_t[1]
self.eps = eps
self.output_net = np.array(net)
if len(self.output_net.shape) == 1:
self.output_net = self.output_net.reshape([-1,1])
self.coord = np.zeros([self.output_net.shape[0],self.output_net.shape[1],2])
for i in range(self.output_net.shape[0]):
for j in range(self.output_net.shape[1]):
self.coord[i,j] = [i,j]
print(self.coord)
def __r_t(self,t):
if not self.C:
return 0.5
else:
return self.C*np.exp(-self.B*t/self.epochs)
def __lr(self,t,distance):
return (self.epochs-t)/self.epochs*np.exp(-distance)
def standard_x(self,x):
x = np.array(x)
for i in range(x.shape[0]):
x[i,:] = [value/(((x[i,:])**2).sum()**0.5) for value in x[i,:]]
return x
def standard_w(self,w):
for i in range(w.shape[0]):
for j in range(w.shape[1]):
w[i,j,:] = [value/(((w[i,j,:])**2).sum()**0.5) for value in w[i,j,:]]
return w
def cal_similar(self,x,w):
similar = (x*w).sum(axis=2)
coord = np.where(similar==similar.max())
return [coord[0][0],coord[1][0]]
def update_w(self,center_coord,x,step):
for i in range(self.coord.shape[0]):
for j in range(self.coord.shape[1]):
distance = (((center_coord-self.coord[i,j])**2).sum())**0.5
if distance <= self.__r_t(step):
self.W[i,j] = self.W[i,j] + self.__lr(step,distance)*(x-self.W[i,j])
def transform_fit(self,x):
self.train_x = self.standard_x(x)
self.W = np.zeros([self.output_net.shape[0],self.output_net.shape[1],self.train_x.shape[1]])
for i in range(self.W.shape[0]):
for j in range(self.W.shape[1]):
self.W[i,j,:] = self.train_x[random.choice(range(self.train_x.shape[0])),:]
self.W = self.standard_w(self.W)
for step in range(int(self.epochs)):
j = 0
if self.__lr(step,0) <= self.eps:
break
for index in range(self.train_x.shape[0]):
print("*"*8,"({},{})/{} W:\n".format(step,j,self.epochs),self.W)
center_coord = self.cal_similar(self.train_x[index,:],self.W)
self.update_w(center_coord,self.train_x[index,:],step)
self.W = self.standard_w(self.W)
j += 1
label = []
for index in range(self.train_x.shape[0]):
center_coord = self.cal_similar(self.train_x[index, :], self.W)
label.append(center_coord[1]*self.coord.shape[1] + center_coord[0])
class_dict = {}
for index in range(self.train_x.shape[0]):
if label[index] in class_dict.keys():
class_dict[label[index]].append(index)
else:
class_dict[label[index]] = [index]
cluster_center = {}
for key,value in class_dict.items():
cluster_center[key] = np.array([x[i, :] for i in value]).mean(axis=0)
self.cluster_center = cluster_center
return label
def fit(self,x):
self.train_x = self.standard_x(x)
self.W = np.random.rand(self.output_net.shape[0], self.output_net.shape[1], self.train_x.shape[1])
self.W = self.standard_w(self.W)
for step in range(int(self.epochs)):
j = 0
if self.__lr(step,0) <= self.eps:
break
for index in range(self.train_x.shape[0]):
print("*"*8,"({},{})/{} W:\n".format(step, j, self.epochs), self.W)
center_coord = self.cal_similar(self.train_x[index, :], self.W)
self.update_w(center_coord, self.train_x[index, :], step)
self.W = self.standard_w(self.W)
j += 1
label = []
for index in range(self.train_x.shape[0]):
center_coord = self.cal_similar(self.train_x[index, :], self.W)
label.append(center_coord[1] * self.coord.shape[1] + center_coord[1])
class_dict = {}
for index in range(self.train_x.shape[0]):
if label[index] in class_dict.keys():
class_dict[label[index]].append(index)
else:
class_dict[label[index]] = [index]
cluster_center = {}
for key, value in class_dict.items():
cluster_center[key] = np.array([x[i, :] for i in value]).mean(axis=0)
self.cluster_center = cluster_center
def predict(self,x):
self.pre_x = self.standard_x(x)
label = []
for index in range(self.pre_x.shape[0]):
center_coord = self.cal_similar(self.pre_x[index, :], self.W)
label.append(center_coord[1] * self.coord.shape[1] + center_coord[1])
return label
計算實體
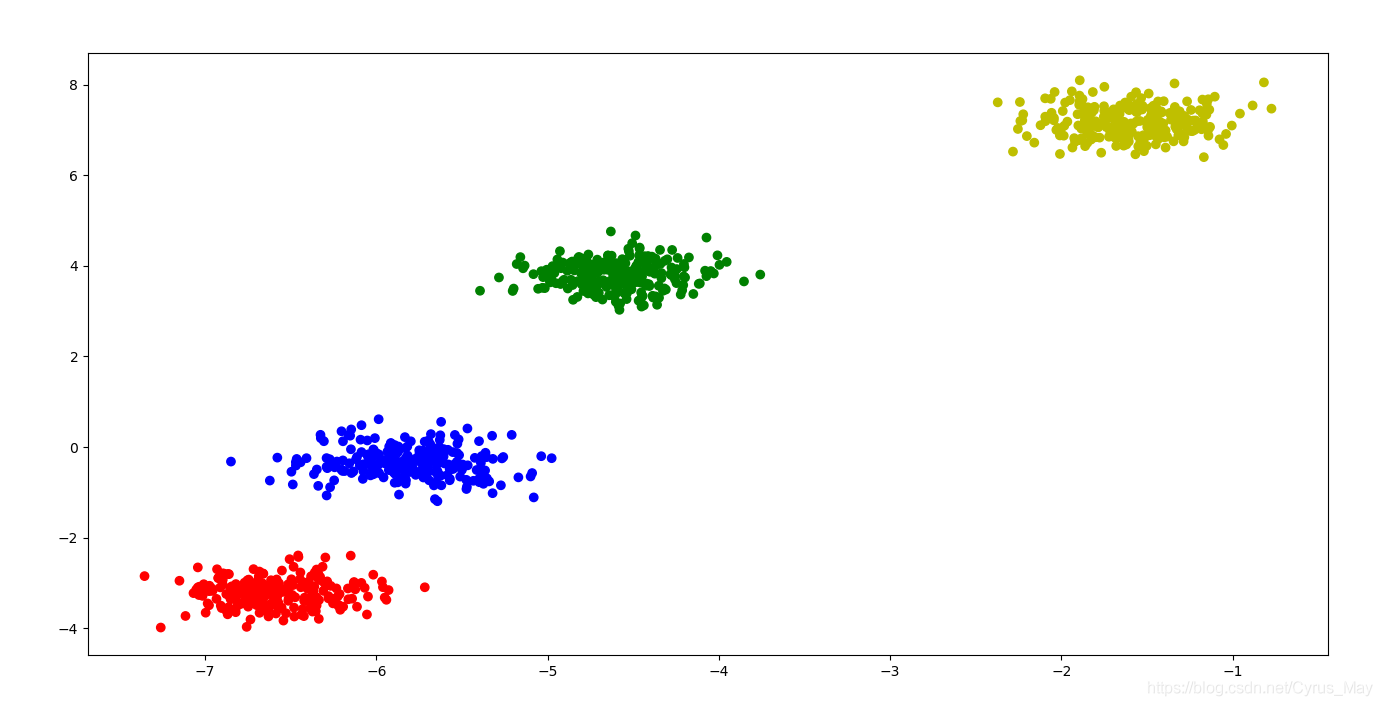
對簇形狀資料集進行聚類
僅需五步即可實作較好的聚類結果
from sklearn.datasets import load_iris,make_blobs
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
if __name__ == '__main__':
SOM = CyrusSOM(epochs=5)
data = make_blobs(n_samples=1000,n_features=2,centers=4,cluster_std=0.3)
x = data[0]
y_pre = SOM.transform_fit(x)
colors = "rgby"
figure = plt.figure(figsize=[20,12])
plt.scatter(x[:,0],x[:,1],c=[colors[i] for i in y_pre])
plt.show()
******** (4,998)/5 W:
[[[-0.90394221 -0.42765463]
[-0.99859415 -0.05300684]]
[[-0.77166042 0.63603475]
[-0.23064699 0.9730375 ]]]
******** (4,999)/5 W:
[[[-0.89968359 -0.4365426 ]
[-0.99859415 -0.05300684]]
[[-0.77166042 0.63603475]
[-0.23064699 0.9730375 ]]]
by CyrusMay 2021 01 13
最深刻 的故事
最永恒 的傳說
不過 是你 是我
能夠 平凡生活
——————五月天(因為你 所以我)——————
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/248603.html
標籤:python