CSDN 2020 博客之星實時資料排名:csdn.itrhx.com
CSDN 一年一度的博客之星評選開始了,官網地址:https://bss.csdn.net/m/topic/blog_star2020 ,由于官網是按照隨機編號排序的,沒有按照票數多少排序,為了方便查看排名,可以使用 Python 爬蟲 + PyEcharts 來實作實時資料排名,
打開 Google Chrome 的審查工具,可以找到一個 getUsers 的請求,請求地址為:https://bss.csdn.net/m/topic/blog_star2020/getUsers,請求方式為 POST,回傳的是 JSON 格式的資料,里面包含了每一位博主的相關資訊,
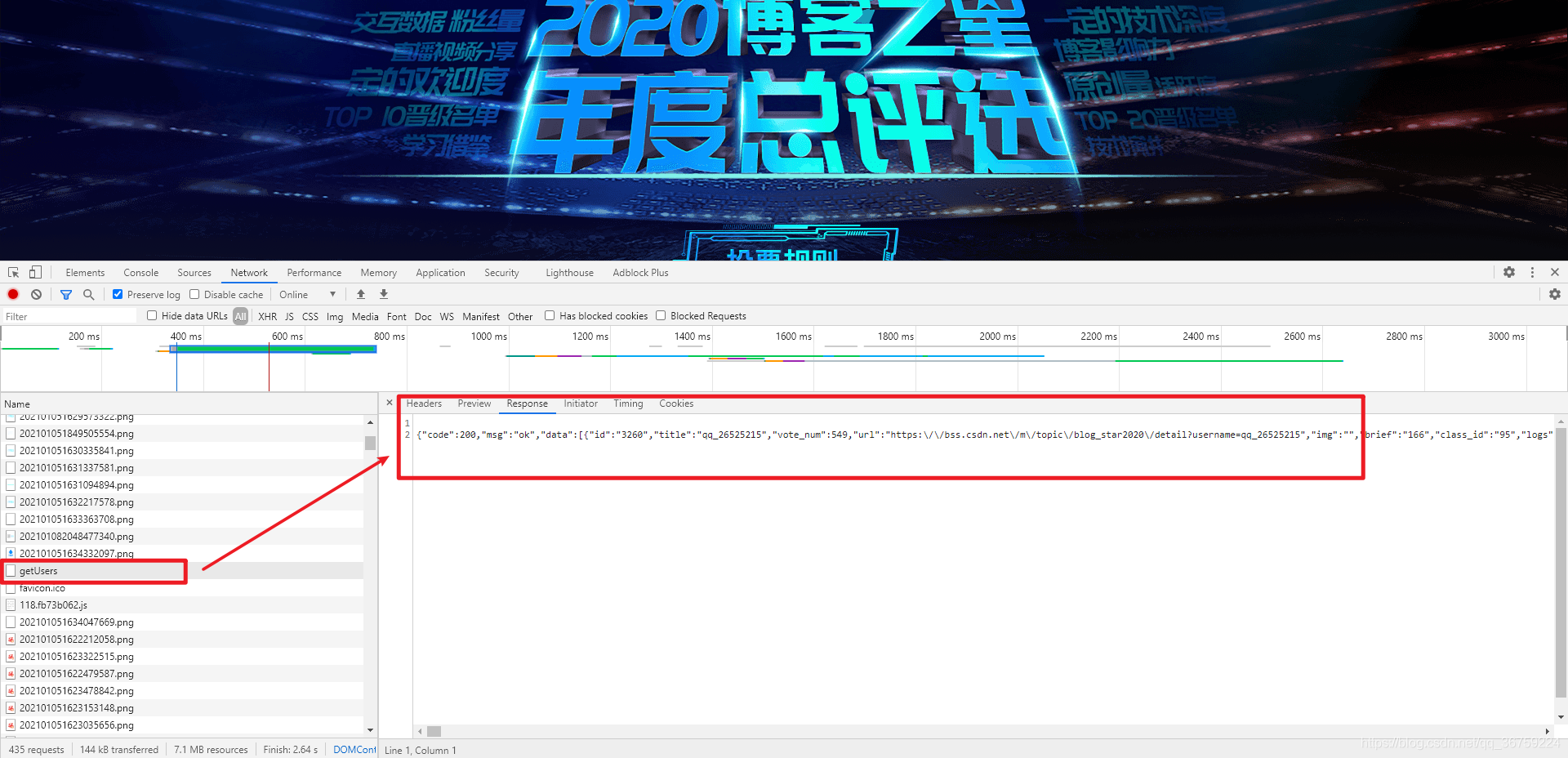
找到請求介面就不難了,使用 Python 爬蟲很容易將其爬取下來,然后對資料進行處理,按照票數進行排序,再配合 PyEcharts 就可以進行資料展示了,完整代碼如下:
# ====================================
# --*-- coding: utf-8 --*--
# @Time : 2021-01-12
# @Author : TRHX ? 鮑勃
# @Blog : www.itrhx.com
# @CSDN : itrhx.blog.csdn.net
# @FileName: csdn_blog_star_2020.py
# @Software: PyCharm
# ====================================
import json
import requests
from datetime import datetime
from pyecharts.components import Table
from pyecharts.options import ComponentTitleOpts
def crawl_data() -> dict:
url = 'https://bss.csdn.net/m/topic/blog_star2020/getUsers'
headers = {
'authority': 'bss.csdn.net',
'origin': 'https://bss.csdn.net',
'referer': 'https://bss.csdn.net/m/topic/blog_star2020',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
data = {
'number': ''
}
response = requests.post(url=url, headers=headers, data=data)
response_json = json.loads(response.text)
return response_json
def data_processing(data) -> list:
all_data = []
csdn_data = data['data']
for csdn in csdn_data:
vote_num = int(csdn['vote_num']) # 票數
number = csdn['number'] # 編號
csdn_id = csdn['title'] # CSDN ID
nick_name = csdn['nick_name'] # 昵稱
code_level = csdn['codeLevel'] # 碼齡
article_count = csdn['article_count'] # 文章數
csdn_url = 'https://blog.csdn.net/' + csdn_id # 主頁
url = csdn['url'] # 投票地址
# avatar = c['avatar'] # 頭像地址
personal_information = [vote_num, number, csdn_id, nick_name, code_level, article_count, csdn_url, url]
all_data.append(personal_information)
# 按照票數排序
all_data_sorted = sorted(all_data, key=lambda x: x[0], reverse=True)
# 添加排名
rank = 1
for a in all_data_sorted:
a.insert(0, rank)
rank += 1
# print(all_data_sorted)
return all_data_sorted
def create_table(data, crawl_time):
table = Table(page_title="TRHX丨CSDN 2020 博客之星實時資料")
headers = ["排名", "票數", "編號", "CSDN ID", "CSDN 昵稱", "碼齡", "文章數", "主頁", "投票地址"]
rows = data
table.add(headers, rows)
table.set_global_opts(
title_opts=ComponentTitleOpts(
title="CSDN 2020 博客之星實時資料排名(每10分鐘更新一次)",
subtitle='上次更新時間:' + str(crawl_time) + ' 資料來源:https://bss.csdn.net/m/topic/blog_star2020' + "\n\n作者:TRHX ? 鮑勃 為作者投上一票吧:https://bss.csdn.net/m/topic/blog_star2020/detail?username=qq_36759224",
title_style={"style": "font-size:20px; font-weight:bold; text-align: center"},
subtitle_style={"style": "font-size:15px; text-align: center"})
)
table.render("csdn_blog_star_2020.html")
if __name__ == '__main__':
time_now = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
json_data = crawl_data()
data_sorted = data_processing(json_data)
create_table(data_sorted, time_now)
打開生成的 csdn_blog_star_2020.html 檔案,如下圖所示:

我們可以將 Python 代碼部署至服務器,設定定時任務,每十分鐘爬取一次資料并更新進行展示,如果有域名的話,還可以做一個域名決議,這樣一個簡單的實時資料排名就做好啦!
實時資料排名查看地址:csdn.itrhx.com
博主有幸能夠進入 2020 博客之星 TOP200,如果我的文章對您有所幫助的話,煩請為我投上您寶貴的一票吧!(PS:每天都可以投哦!)
TRHX ? 鮑勃 投票地址:
https://bss.csdn.net/m/topic/blog_star2020/detail?username=qq_36759224
或者掃描以下二維碼為我投票:

一入 IT 深似海,從此學習無絕期!2021,加油!
TRHX ? 鮑勃
 CSDN認證博客專家
CSDN博客專家
網路爬蟲工程師
高校俱樂部主席
CSDN認證博客專家
CSDN博客專家
網路爬蟲工程師
高校俱樂部主席
CSDN認證博客專家
CSDN博客專家
網路爬蟲工程師
高校俱樂部主席
個人博客:www.itrhx.com,Python 網路爬蟲工程師,專攻資料挖掘、資料分析,資料可視化領域,Golang、前端以及開源技術愛好者,一入 IT 深似海,從此學習無絕期!求知若饑,虛心若愚,只談技術,莫問前程!注重細節,用心寫好文!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/248604.html
標籤:python
上一篇:深度學習 自組織映射網路 ——python實作SOM(用于聚類)
下一篇:怎樣讓程式在崩掉的時候記錄點東西