配置一下"可能需要修改的引數",就可以食用底部代碼了
- 本文章代碼功能
- 準備作業
- Python用到的庫和準備作業
- 可能需要修改的引數
- 在CMD中打開一個Chrome瀏覽器并啟用埠給Selenium呼叫
- 匯入模塊
- 呼叫剛打開的Chrome瀏覽器與Python建立連接
- 全部代碼復制可用
本文章代碼功能
-
淘寶搜索關鍵詞,收集搜索到1到100頁根據銷量排名的各個商品資訊:
- 商品本次排名
- 商品鏈接
- 商品搜索頁的圖片鏈接
- 商品店鋪旺旺名稱
- 商品標題
- 商品價格
- 商品銷量
- 抓取的時間
- 商品ID
-
商品資訊寫入SQLite資料庫,資料庫表名為搜索的關鍵詞,
如果商品ID和銷量與表中的一樣則不寫入資料庫,如果商品ID有了但是銷量不一樣則添加這條新的資料,即防止出現完全重復的資料又能記錄每個商品在不同時間段銷量的變化, -
第一次寫文章,有什么不足的地方歡迎指點和探討,
-
有識訓的話點個贊,讓小弟知道還有人在看這篇文章,
-
代碼運行樣式:
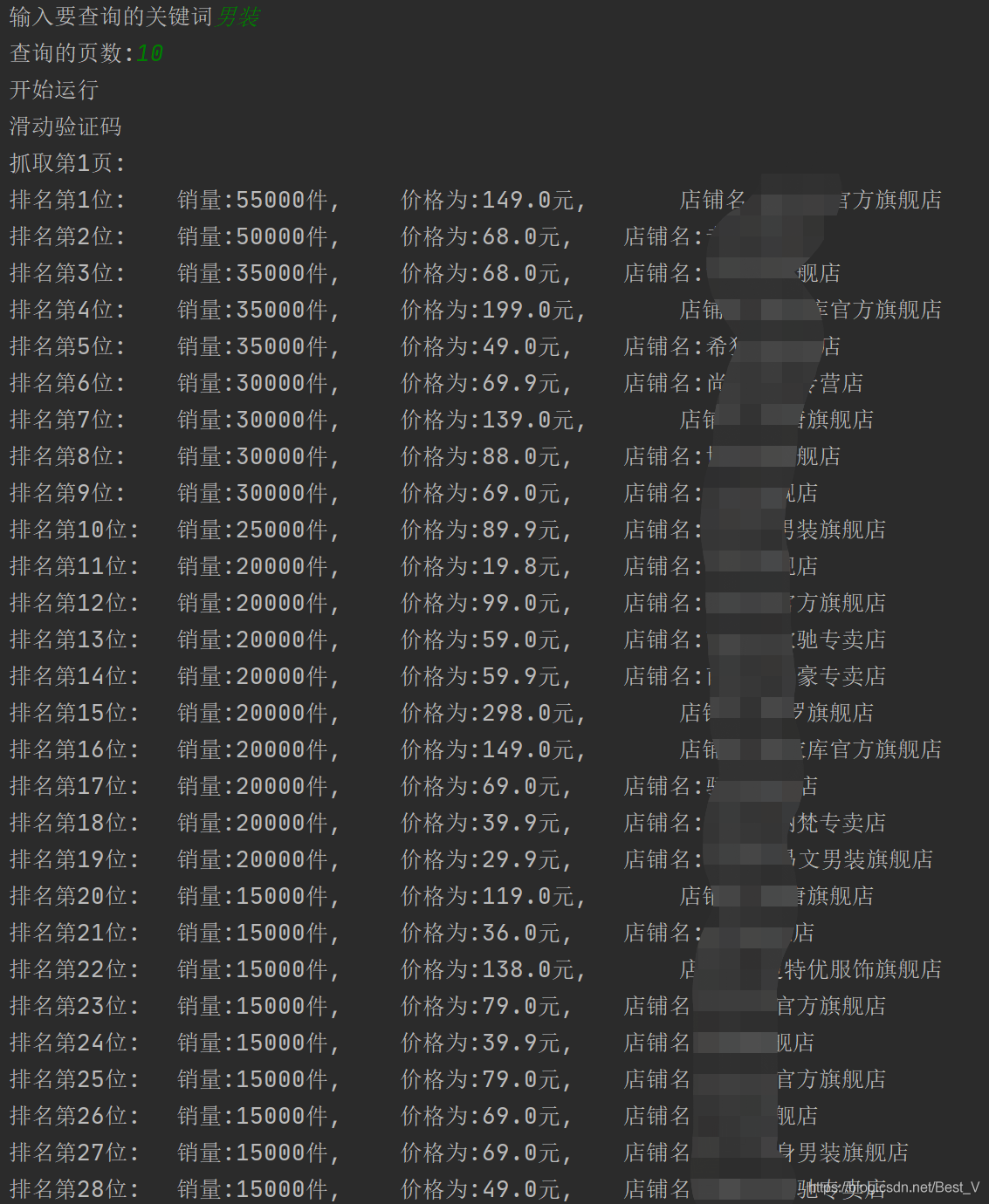
-
資料庫樣式:
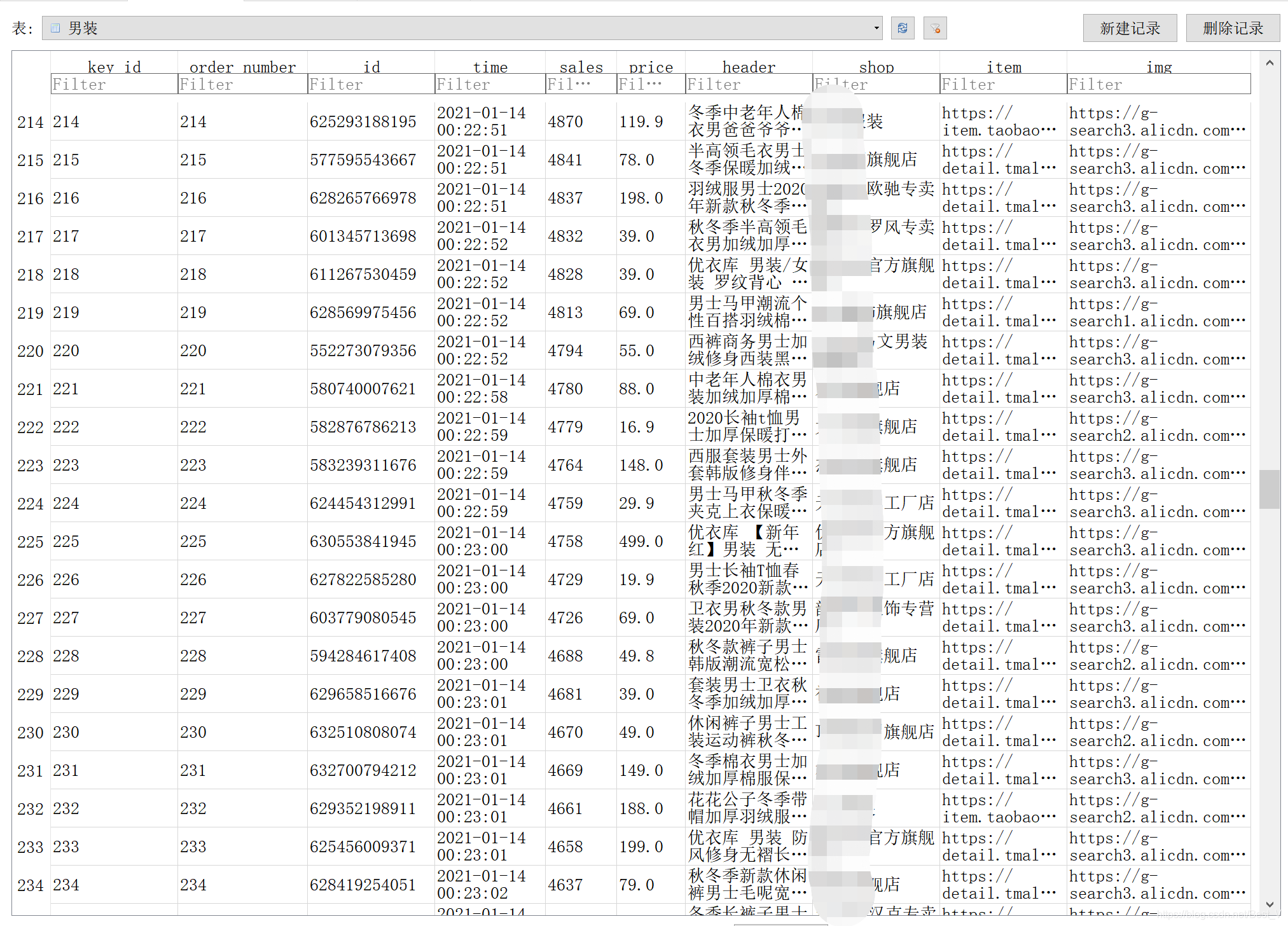
-
測驗查詢100頁沒有問題
準備作業
淘寶反爬蟲比較嚴格,所以使用Selenium比較貼近真實使用環境,出現驗證滑動條比較容易過,然后用了SQLite資料庫來儲存資料,要是覺得SQLite資料庫用的不方便可以在Python中加條函式匯出到Excel,
參考代碼:
from xlsxwriter.workbook import Workbook
import sqlite3
workbook = Workbook('output.xlsx')
worksheet = workbook.add_worksheet('男裝')
content=sqlite3.connect('content.db')
c=conn.cursor()
ti=c.execute("select * from '男裝'")
for i, row in enumerate(ti):
for j, value in enumerate(row):
worksheet.write(i, j, value)
workbook.close()
Python用到的庫和準備作業
- Python3.7開發環境
- re庫
- time庫
- sqlite3庫:
- Selenium庫 :呼叫Chrome瀏覽器的webdriver驅動檔案,點擊下載chromedrive ,將下載的瀏覽器驅動檔案chromedriver丟到Chrome瀏覽器目錄中的Application檔案夾下,配置Chrome瀏覽器位置到PATH環境,
Selenium 入門參考文獻; - SQLite資料庫,安裝和配置如下:
- SQLite下載鏈接 ,下載sqlite-tools-win32-**.zip 和 sqlite-dll-win32-*.zip 壓縮檔案,
- 在盤根目錄創建sqlite檔案夾,并添加到 PATH 環境變數,解壓上面兩個壓縮檔案(得到 sqlite3.def、sqlite3.dll 和 sqlite3.exe 檔案)到sqlite檔案夾,
- 在命令提示符下,使用 sqlite3 命令,顯示如下就是安裝成功了:
C:\>sqlite3 SQLite version 3.7.15.2 2013-01-09 11:53:05 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite>
可能需要修改的引數
在CMD中打開一個Chrome瀏覽器并啟用埠給Selenium呼叫
remote-debugging-port= 瀏覽器使用的埠,自己定義一個就行,
user-data-dir= 新打開的瀏覽器檔案目錄,自己創建一個就行,
示例代碼:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\App\Chrome"
第一次創建瀏覽器檔案,在打開瀏覽器之后最好去登錄一下淘寶
匯入模塊
from selenium import webdriver
import time
import re
import sqlite3
from selenium.webdriver.common.action_chains import ActionChains
呼叫剛打開的Chrome瀏覽器與Python建立連接
配置Chrome瀏覽瀏覽器
chromedriver.exe的目錄根據自己放的位置自行修改
增加一個js代碼,在頁面打開前修改windows.navigator.webdriver檢測結果為undefined
代碼如下:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
chrome_driver = r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
Chrome = webdriver.Chrome(chrome_driver, options=chrome_options)
# 設定位置和寬高
Chrome.set_window_position(x=1000, y=353)
Chrome.set_window_size(width=900, height=500)
# 攔截webdriver檢測代碼
Chrome.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""})
全部代碼復制可用
路徑配置沒問題的話,新建一個.py檔案就可以用了,
資料庫中的兩個值解讀:
- key_id :主鍵,自增加的不用理會
- order_number:本次運行中的排名,每次運行都是從1開始添加的
from selenium import webdriver
import time
import re
import sqlite3
from selenium.webdriver.common.action_chains import ActionChains
'''
在cmd中運行: chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\App\Chrome" 檔案夾目錄創建一個就好,用來存放新的Chrome瀏覽器資訊
根據關鍵詞,在淘寶搜索頁面按照銷量排序,收集商品資訊.
資料庫表查詢:先根據id選取商品唯一值,根據time時間排序,根據sales觀察銷量變化
'''
class ItemClass:
def __init__(self, url_keyword='男裝', user_page=100):
self.url_keyword = url_keyword
self.user_page = user_page
self.img_url = None
self.item_url = None
self.sales = None
self.price = None
self.detail_head = None
self.shop_name = None
self.order_number = 0
self.t_dic = []
self.conn = None
self.cursor = None
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
chrome_driver = r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
self.Chrome = webdriver.Chrome(chrome_driver, options=chrome_options)
# 設定位置和寬高
self.Chrome.set_window_position(x=1000, y=353)
self.Chrome.set_window_size(width=900, height=500)
# 攔截webdriver檢測代碼
self.Chrome.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""})
# 如果出現驗證碼攔截
def intercept(self):
if '驗證碼攔截' in self.Chrome.title:
print('滑動驗證碼')
try:
# 找到滑塊
slider = self.Chrome.find_element_by_xpath("//span[contains(@class, 'btn_slide')]")
# 判斷滑塊是否可見
if slider.is_displayed():
# 點擊并且不松開滑鼠
ActionChains(self.Chrome).click_and_hold(on_element=slider).perform()
# 往右邊移動258個位置
ActionChains(self.Chrome).move_by_offset(xoffset=258, yoffset=0).perform()
# 松開滑鼠
ActionChains(self.Chrome).pause(0.5).release().perform()
except Exception as err:
print('驗證碼滑動出錯:',err)
pass
time.sleep(1)
# 直接下拉到固定的最底欄
def scrolldown(self):
y_plus = 450
y = 0
for i in range(9):
y += y_plus
self.Chrome.execute_script("window.scroll(0,{})".format(y))
time.sleep(0.2)
# self.Chrome.execute_script("window.scroll(400,200)")
# 下拉到最底欄第二種,檢查是否到最底欄
def scrolldown_two(self):
t = True
y = 400
x = self.Chrome.execute_script("return document.body.scrollHeight;")
while t:
check_height = self.Chrome.execute_script("return document.body.scrollHeight;")
x += y
self.Chrome.execute_script("window.scroll(0,{})".format(x))
time.sleep(0.5)
check_height1 = self.Chrome.execute_script("return document.body.scrollHeight;")
if check_height == check_height1:
# print(str(check_height1))
t = False
self.Chrome.execute_script("window.scroll(0,200)")
# 按照銷量排序
def sales_sort(self):
time.sleep(1.5)
self.Chrome.find_element_by_xpath('//a[@data-value="sale-desc"]').click()
# 點擊下一頁
def click_next(self):
self.Chrome.execute_script("window.scroll(400,150)")
self.Chrome.find_element_by_xpath('//a[@title="下一頁"]').click()
time.sleep(1)
# 獲得商品串列資訊并儲存
def get_content(self):
time.sleep(2)
self.scrolldown()
time.sleep(0.5)
for item in self.Chrome.find_elements_by_xpath('.//*[@class="item J_MouserOnverReq "]'):
try:
self.order_number += 1
self.img_url = \
item.find_element_by_xpath('.//*[@class="J_ItemPic img"]').get_attribute('src').split('_360')[0]
self.item_url = item.find_element_by_xpath('.//*[@class="pic-link J_ClickStat J_ItemPicA"]')\
.get_attribute('href').split('&')[0]
sales_tem = item.find_element_by_xpath('.//*[@class="deal-cnt"]').text
self.sales = int(''.join(re.findall(r'\d*\d',sales_tem)))
self.price = float(item.find_element_by_xpath('.//*[@class="price g_price g_price-highlight"]/strong').text)
self.detail_head = item.find_element_by_xpath('.//*[@class="J_ItemPic img"]').get_attribute('alt')
self.shop_name = item.find_element_by_xpath('.//*[@class="shopname J_MouseEneterLeave J_ShopInfo"]').text
if '萬' in sales_tem:
self.sales = int(float(re.findall(r'\d+.\d*', sales_tem)[0])*10000)
if '.gif' in self.img_url:
print('排名第{}位:\t銷量:{}件,\t價格為:{}元, \t店鋪名:{}, \t圖片錯誤:{}'.format(self.order_number, self.sales, self.price, self.shop_name, self.img_url))
else:
print('排名第{}位:\t銷量:{}件,\t價格為:{}元, \t店鋪名:{}'.format(self.order_number, self.sales, self.price, self.shop_name))
self.t_dic = [self.item_url, self.img_url, self.shop_name, self.detail_head, self.price, self.sales]
# 儲存在多張表
# self.save_content()
# 儲存在一表
self.save_content_one()
except Exception as err:
print('第{}號出錯,出錯代碼為: '.format(self.order_number), err)
continue
# 儲存多張表
def save_content(self):
t_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
# 獲取商品id
id_and_table_name = int(self.item_url.split('=')[1])
# 字典里增加時間和id
self.t_dic.append(t_time)
self.t_dic.append(id_and_table_name)
# 創建表sql代碼,如果不存在則創建表
sql_if_exists = '''
CREATE TABLE IF NOT EXISTS [{}] (
sales INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
order_number INT,
id INT,
time TEXT,
price REAL,
header TEXT,
shop TXEXT,
item TEXT,
img TEXT);
'''
# 寫入表sql代碼,如果表里有匹配到的資料,則寫入否則不寫入
sql_insert_or_ignore = '''
INSERT INTO [{0}] (order_number,id,time,sales,price,header,shop,img,item) \
SELECT '{2}',{1[7]},'{1[6]}','{1[5]}','{1[4]}','{1[3]}','{1[2]}','{1[1]}','{1[0]}'
WHERE NOT EXISTS (SELECT *FROM [{0}] WHERE id='{1[7]}' AND sales='{1[5]}');
'''
# 執行創建表sql代碼,用商品id當表名
self.cursor.execute(sql_if_exists.format(id_and_table_name))
# 執行寫入表sql代碼
self.cursor.execute(sql_insert_or_ignore.format(id_and_table_name, self.t_dic, self.order_number))
# 保存
self.conn.commit()
# 字典歸零
self.t_dic = []
# 儲存在一張表中
def save_content_one(self):
# 時間
t_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
# 獲取商品id
t_id = int(self.item_url.split('=')[1])
# 字典里加入時間
self.t_dic.append(t_time)
# 字典里加入商品id
self.t_dic.append(t_id)
# 用搜索關鍵詞當表名
table_name = self.url_keyword
# 創建表sql代碼,如果不存在則創建表
sql_if_exists = '''
CREATE TABLE IF NOT EXISTS [{}] (
key_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
order_number INT,
id INT,
time TEXT,
sales INT,
price REAL,
header TEXT,
shop TXEXT,
item TEXT,
img TEXT);
'''
# 寫入表sql代碼,如果表里有匹配到的資料,則寫入否則不寫入
sql_insert_or_ignore = '''
INSERT INTO [{0}] (order_number,id,time,sales,price,header,shop,img,item) \
SELECT '{2}',{1[7]},'{1[6]}','{1[5]}','{1[4]}','{1[3]}','{1[2]}','{1[1]}','{1[0]}'
WHERE NOT EXISTS (SELECT *FROM [{0}] WHERE id='{1[7]}' AND sales='{1[5]}');
'''
# 執行創建表sql代碼
self.cursor.execute(sql_if_exists.format(table_name))
# 執行寫入表sql代碼
self.cursor.execute(sql_insert_or_ignore.format(table_name, self.t_dic, self.order_number))
# 保存
self.conn.commit()
# 字典歸零
self.t_dic = []
# 開始
def start(self, t_path=r'content.db'):
print('開始運行')
self.conn = sqlite3.connect(t_path)
self.cursor = self.conn.cursor()
get_page = 0 # 查詢到了多少頁
url = 'https://s.taobao.com/search?q={}'.format(self.url_keyword)
self.Chrome.get(url)
time.sleep(1)
self.intercept()
self.sales_sort() # 按銷量排序
try:
while get_page < self.user_page:
get_page += 1
print('抓取第{}頁:'.format(get_page))
self.get_content()
self.click_next()
except Exception as err:
print('出現錯誤:', err)
self.cursor.close()
self.conn.commit()
self.conn.close()
finally:
print('抓取結束一共抓取了{}位'.format(self.order_number))
self.cursor.close()
self.conn.commit()
self.conn.close()
if __name__ == '__main__':
browser = ItemClass(url_keyword=input('輸入要查詢的關鍵詞'), user_page=int(input('查詢的頁數:')))
# browser = ItemClass(user_page=50)
browser.start()
如果有識訓、點個贊哦
還是留一個聯系方式吧,萬一找不到我了呢~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249479.html
標籤:python
下一篇:python爬蟲