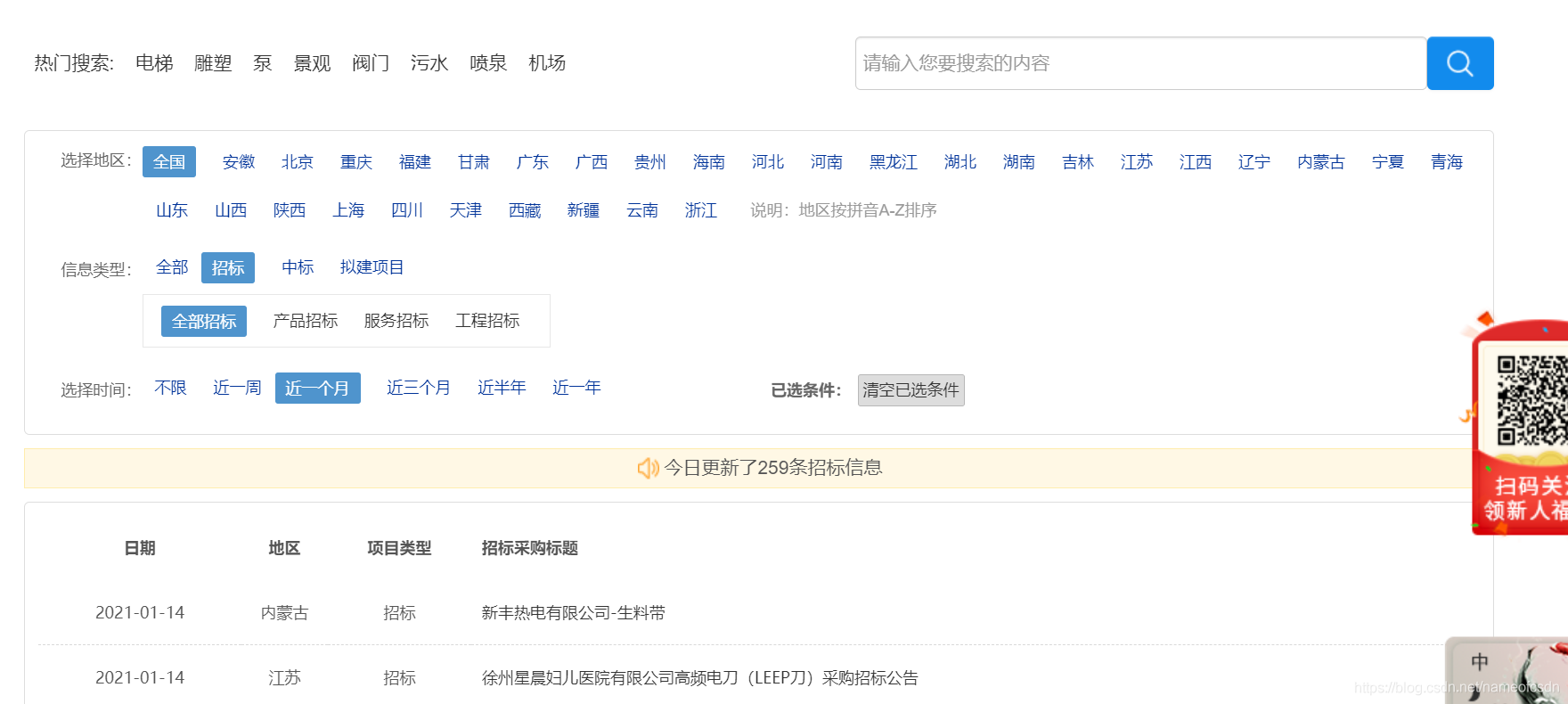
一,爬取目標
http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist

二,需求分析
需求很簡單,就是爬取所有資料,
當然,也可以順便提供一個,搜索某個關鍵詞之后,爬取所有資料的功能,
難點在于,無論點哪里,url看起來永遠是一樣的,這就增大了爬蟲的難度,
爬蟲需要做的事情:
1,爬取目標是ajax頁面,需要selenium+無頭瀏覽器
2,網頁里面的搜索框(可選功能)
3,選項按鈕
默認頁面中,資訊型別 和 選擇時間 都不是選全部,要想爬取所有資料,需要改這2個選項,
4,選擇頁面
三,關鍵技術
1,動態網頁:selenium+無頭瀏覽器
phantomjs.exe已經不能用了,所以這里用的是chromedriver.exe
安裝selenium,然后下載chromedriver.exe放到c盤根目錄,如下代碼即可用它打開網頁
base_url = "http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist"
driver = webdriver.Chrome(executable_path=r'C:\chromedriver.exe', options=chrome_options,service_args=['--load-images=no'])
driver.get(base_url)2,選項按鈕:find_element_by_xpath
查看網頁原始碼,搜索資訊型別

于是我們就有了點擊“全部”按鈕的代碼:
select_type_box = driver.find_element_by_xpath("//ul[@class='select_type_box clearfix']/li[1]")
select_type_box.click()同理,選擇時間

選擇時間的代碼:
select_time_box = driver.find_element_by_xpath("//ul[@class='fl select_time_box']/li[1]")
select_time_box.click()3,下一頁:onclick、JS分析、瀏覽器抓包
本來我以為很簡單:

next_page = driver.find_element_by_xpath("//div[@class='pagination']/ul[1]/li[11]")
next_page.click()然而執行報錯:Element is not clickable at point
也就是說,無頭瀏覽器可以輕松點擊button,但是對onclick卻沒那么容易,
于是,我開始扒拉JS,F12進除錯模式,可以看到一些東西,這個網站只能看到3個js
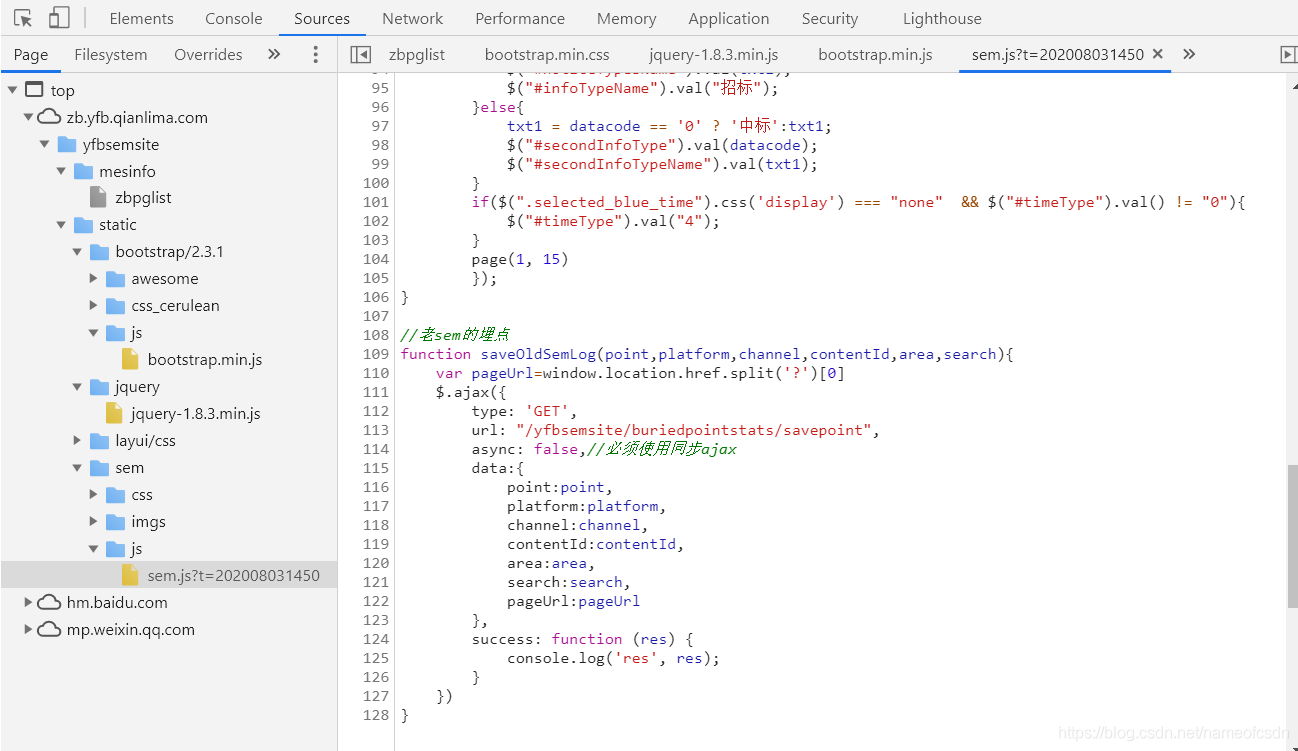
搜索了一些,并沒有找到page函式,不過在網頁原始碼中倒是找到了page函式

這里發現了一個鏈接!!!
我斗膽猜測,searchword就是搜索框,于是試了一下
http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist?searchword=5G
果然可以!
同樣的思路,又失敗了,再也找不到類似的鏈接了,
于是我又在網上找資料,找到一篇講瀏覽器抓包的文章:https://blog.csdn.net/weixin_39610722/article/details/110960576
先打開跟蹤,然后點擊第4頁:
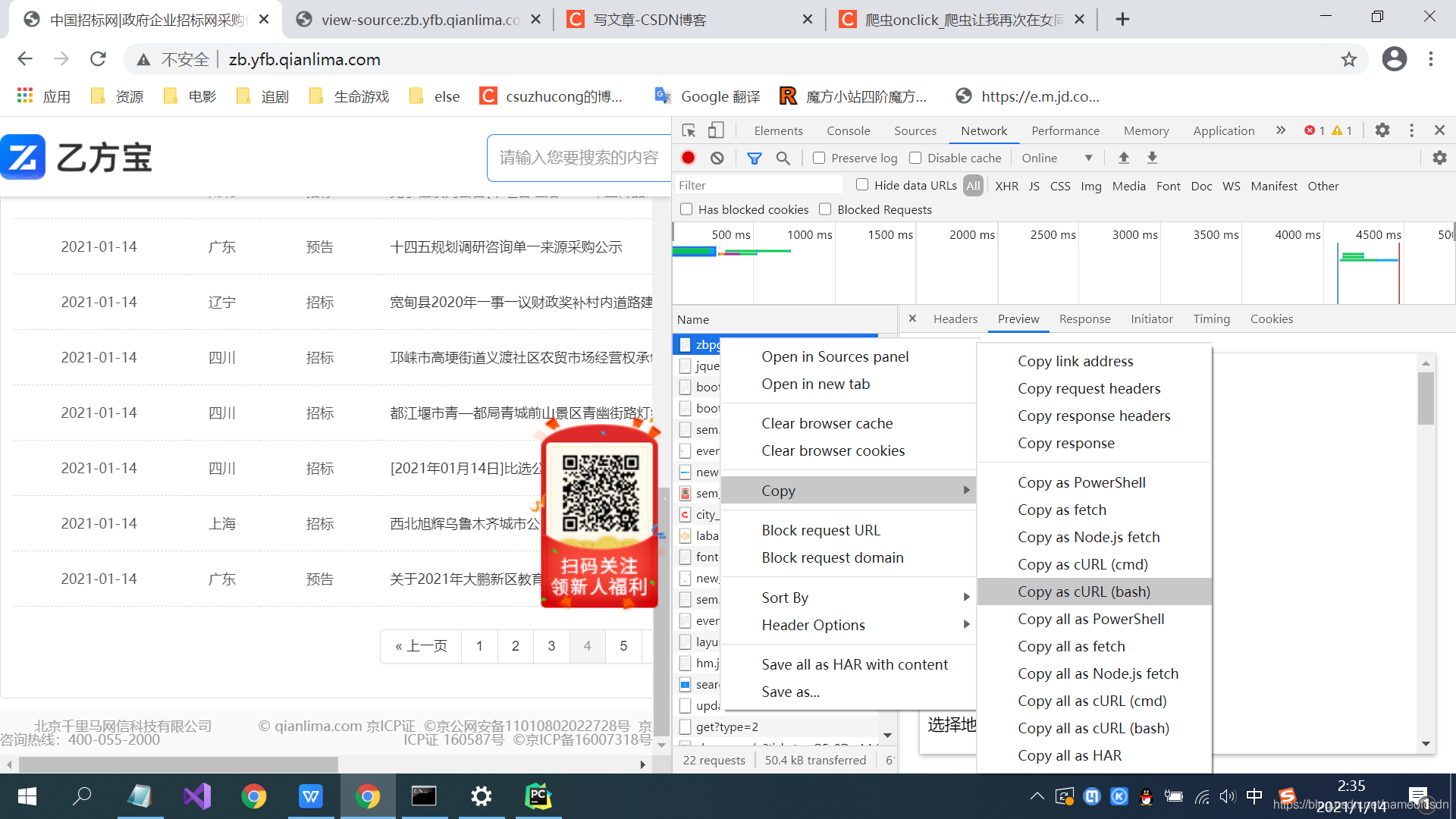
找到URL,右鍵copy as cURL,內容如下:
curl 'http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist' \
-H 'Connection: keep-alive' \
-H 'Cache-Control: max-age=0' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'Origin: http://zb.yfb.qianlima.com' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \
-H 'Referer: http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist' \
-H 'Accept-Language: zh-CN,zh;q=0.9' \
-H 'Cookie: JSESSIONID=C20E9758652DE1F141E51B349D4AE839; __jsluid_h=2b424c9697bd9692d2ad1451300a9c75; Hm_lvt_a31e80f5423f0ff316a81cf4521eaf0d=1610549640; pageSize=15; keywords=%E5%8D%83%E9%87%8C%E9%A9%AC%E6%8B%9B%E6%A0%87; keywordvaluess=""; laiyuan=3; Hm_lvt_0a38bdb0467f2ce847386f381ff6c0e8=1610550267; Hm_lpvt_0a38bdb0467f2ce847386f381ff6c0e8=1610550267; Hm_lvt_5dc1b78c0ab996bd6536c3a37f9ceda7=1610550268; Hm_lpvt_5dc1b78c0ab996bd6536c3a37f9ceda7=1610550268; UM_distinctid=176fc46d0a65b3-0c99d08cd43d87-31346d-e1000-176fc46d0a7d20; gr_user_id=97220f81-4919-4a9d-a198-24b3caf49796; pageNo=4; Hm_lpvt_a31e80f5423f0ff316a81cf4521eaf0d=1610560460' \
--data-raw 'pageNo=7&kwname=&pageSize=15&ipAddress=122.96.44.71&searchword=&searchword2=&hotword=&provinceId=&provinceName=&areaId=&areaName=&infoType=0&infoTypeName=¬iceTypes=¬iceTypesName=&secondInfoType=&secondInfoTypeName=&timeType=5&timeTypeName=%E8%BF%91%E4%B8%80%E5%B9%B4&searchType=2&clearAll=false&e_keywordid=&e_creative=&flag=0&source=baidu&firstTime=1' \
--compressed \
--insecure
還沒來得及仔細看,一眼就看出來里面有這么一個式子:pageNo=4
我斗膽猜測,這就是我們要找的東西了,試了一下http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist?pageNo=4,果然可以!
同理,我們還得到了infoType和timeType
于是,我們發現,對JS徹底分析之后,就不需要啥爬蟲了,直接按順序讀html即可,
然后我發現,不管搜什么,不管篩選什么,最多都只顯示30頁,多的就不顯示了,
新一輪的較量正在醞釀,,,
首先,我得到了這個鏈接
http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist?infoType=0&timeType=0&searchword=5G&pageNo=1&pageSize=1000
然后我一想,我都一頁1000條了,我還要pageNo干啥!
http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist?infoType=0&timeType=0&searchword=5G&pageSize=1000
這個資料足夠大的話,該關鍵詞搜索的全部結果就能顯示出來了,并沒有查詢數量限制,
四,代碼
爬蟲草稿:
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
base_url = "http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist?infoType=0&timeType=0&searchword=5G&pageNo=1"
driver = webdriver.Chrome(executable_path=r'C:\chromedriver.exe', options=chrome_options,service_args=['--load-images=no'])
driver.get(base_url)
select_type_box = driver.find_element_by_xpath("//ul[@class='select_type_box clearfix']/li[1]")
select_type_box.click()
select_time_box = driver.find_element_by_xpath("//ul[@class='fl select_time_box']/li[1]")
select_time_box.click()
print(driver.page_source)
while True:
next_page = driver.find_element_by_xpath("//div[@class='pagination']/ul[1]/li[11]")
next_page.click()
print(driver.page_source)
driver.close()因為暫時不需要這樣爬了,所以代碼先不更了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249480.html
標籤:python
上一篇:Python爬蟲淘寶基于selenium抓取淘寶商品資料2021年測驗過滑動驗證
下一篇:我的Python學習之路(6)