今日學習內容
1.了解Python的組合資料型別,例如集合型別、序列型別(元組型別、串列型別)、字典型別
2.根據三種型別,撰寫代碼實作基本統計值的計算
3.安裝jieba庫并熟悉它的函式
4.根據jieba庫和學習的組合資料型別,實作文本的詞頻統計,根據英文文本的《哈姆雷特》和中文文本的《三國演義》,分別統計其中頻率最高的英文單詞和中文人物單詞
組合資料型別
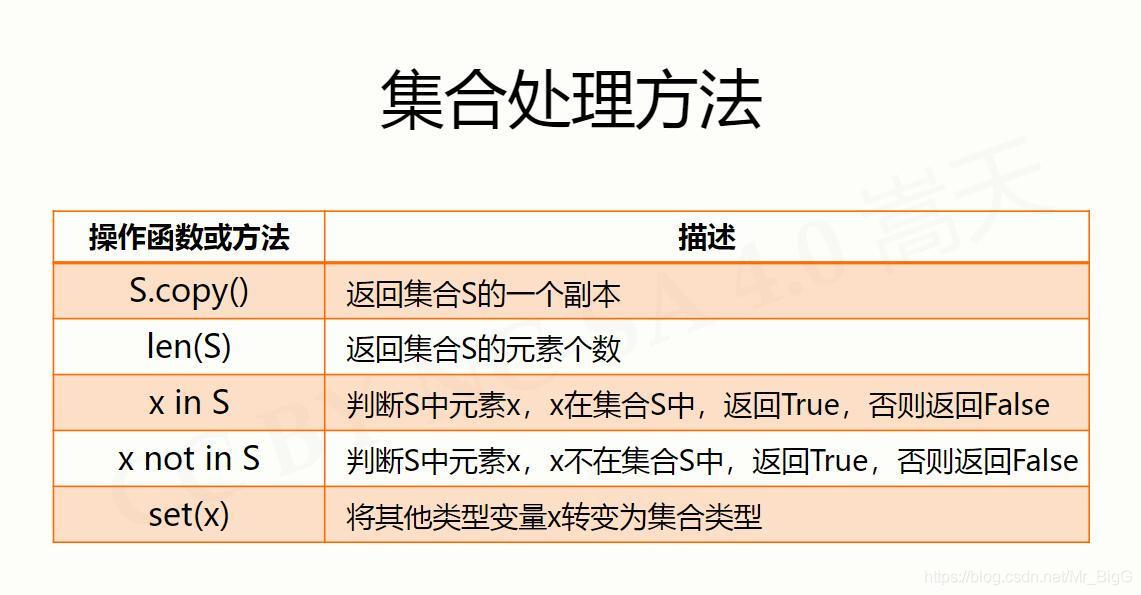
集合
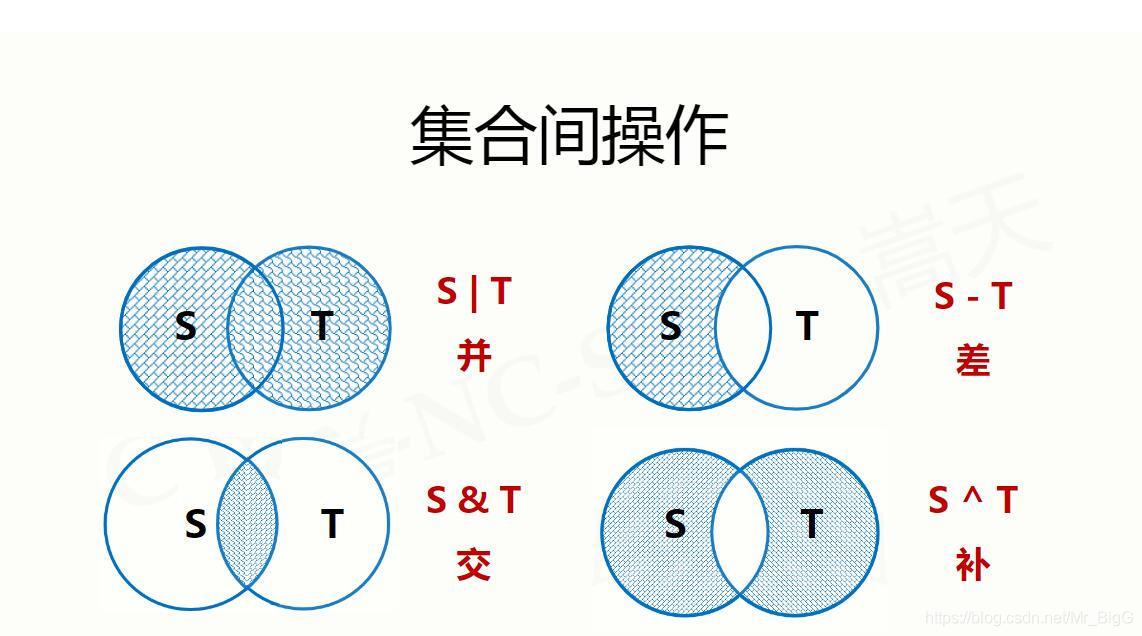
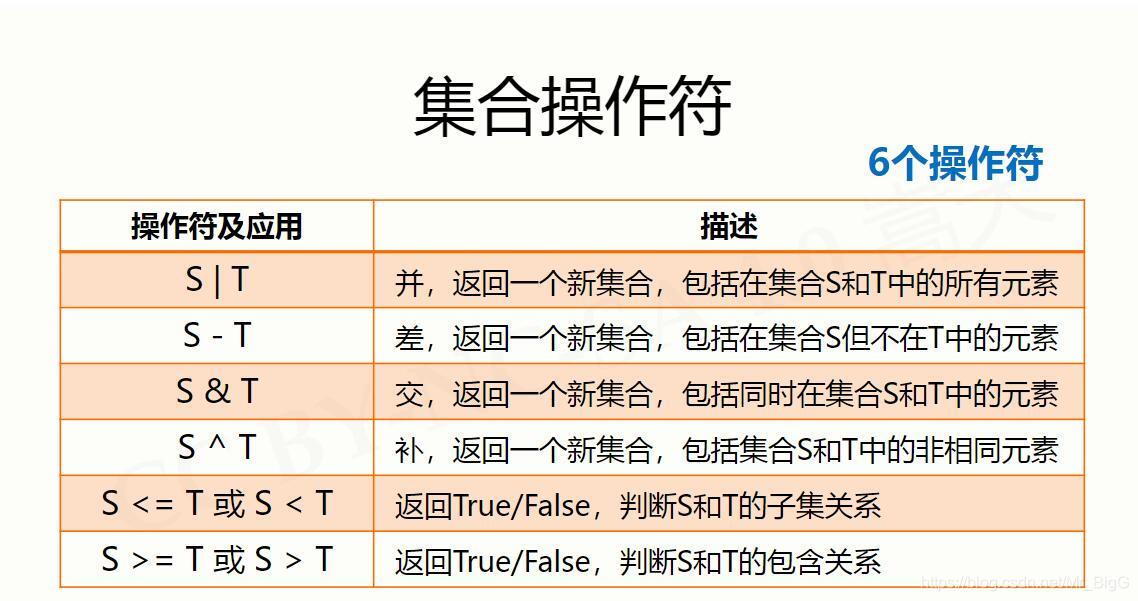
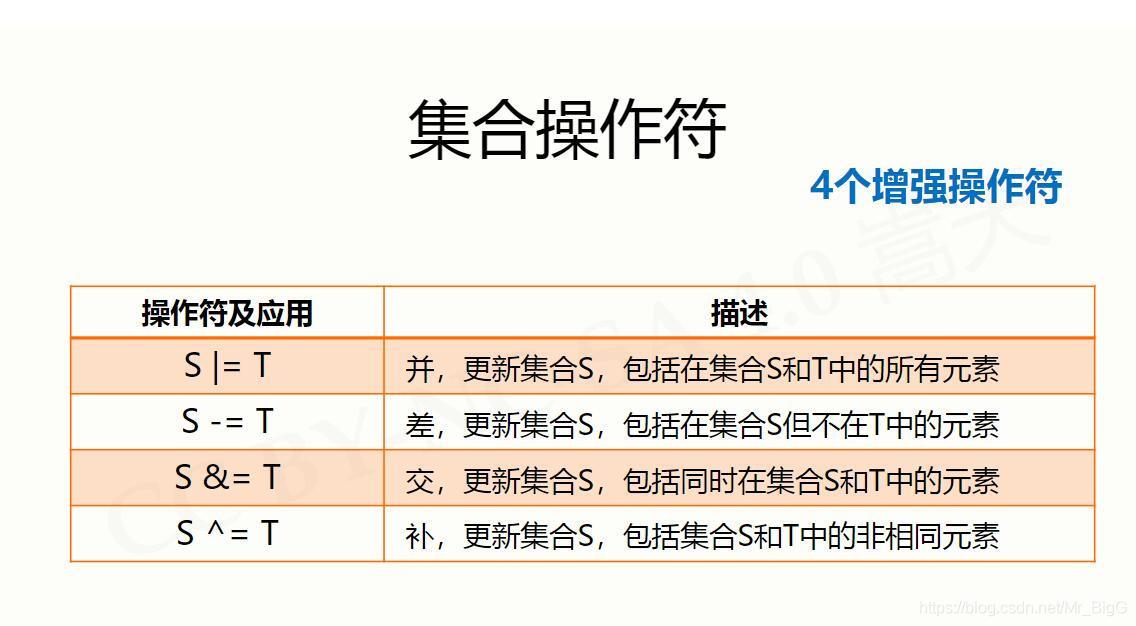
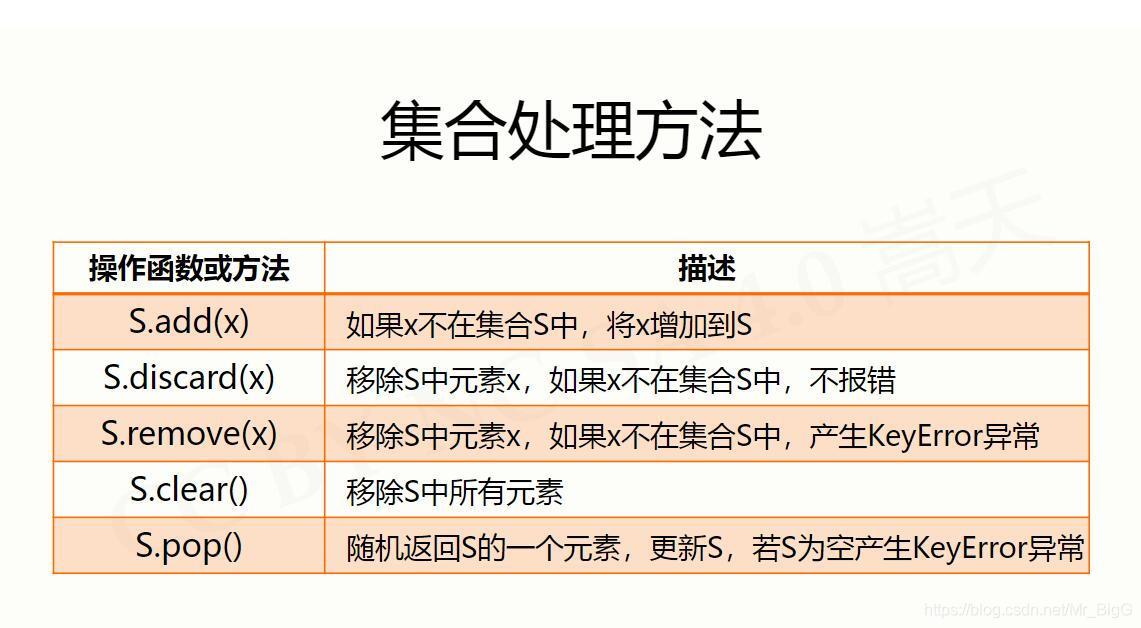
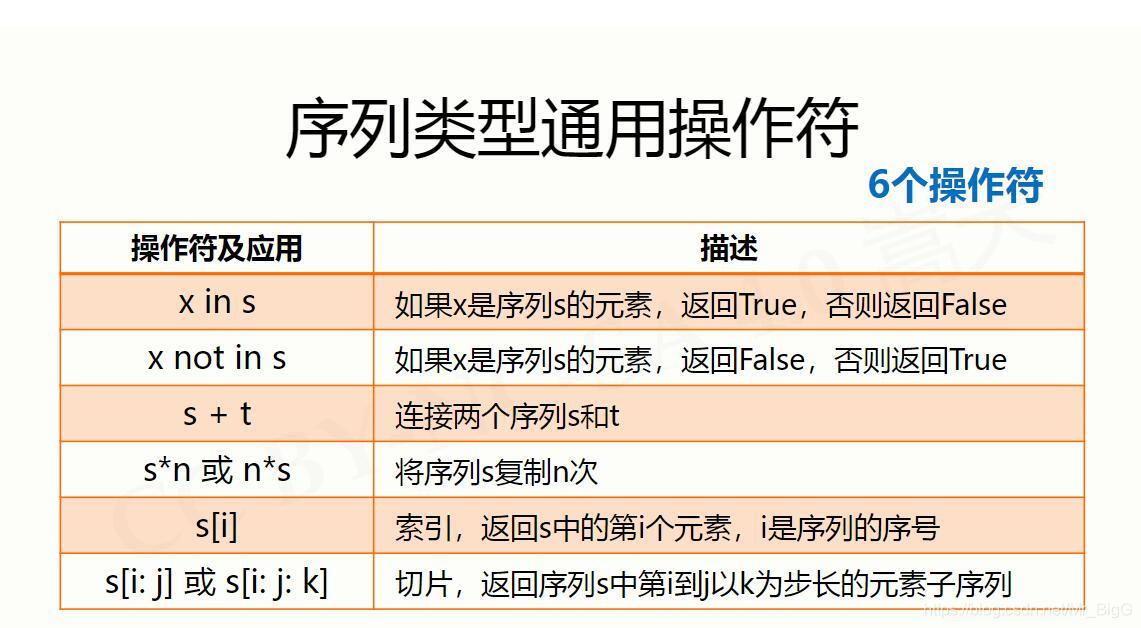
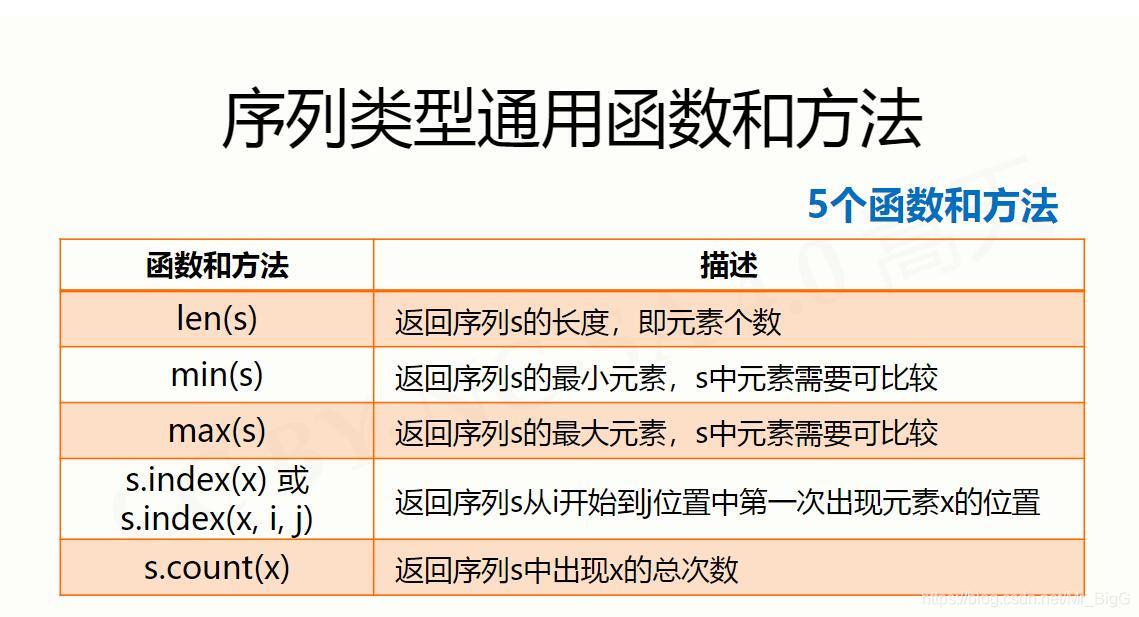
序列
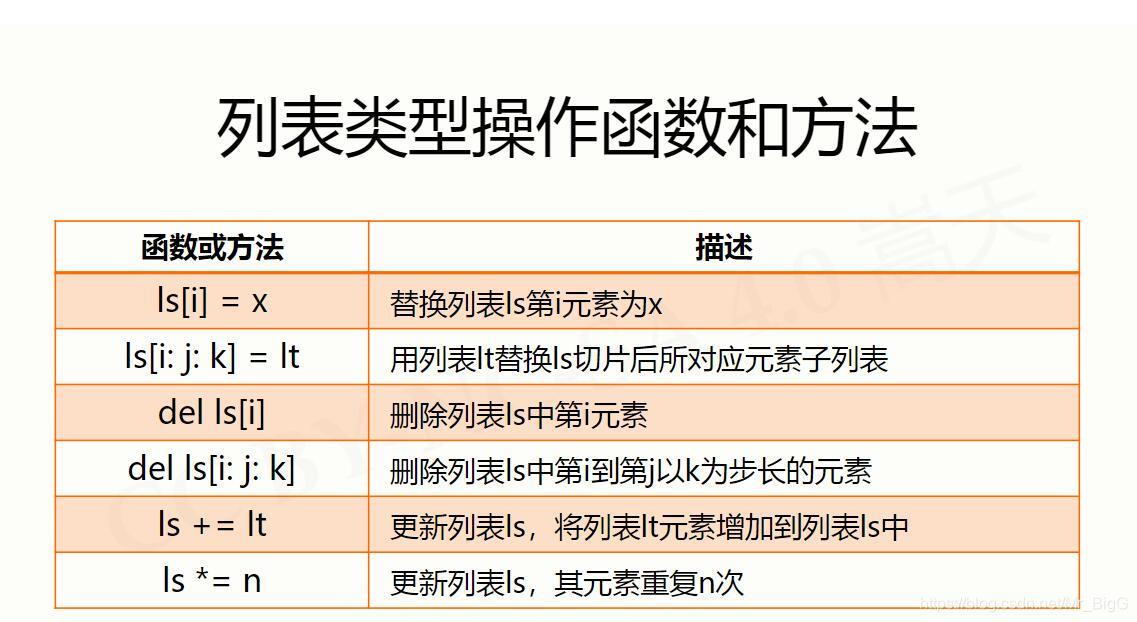
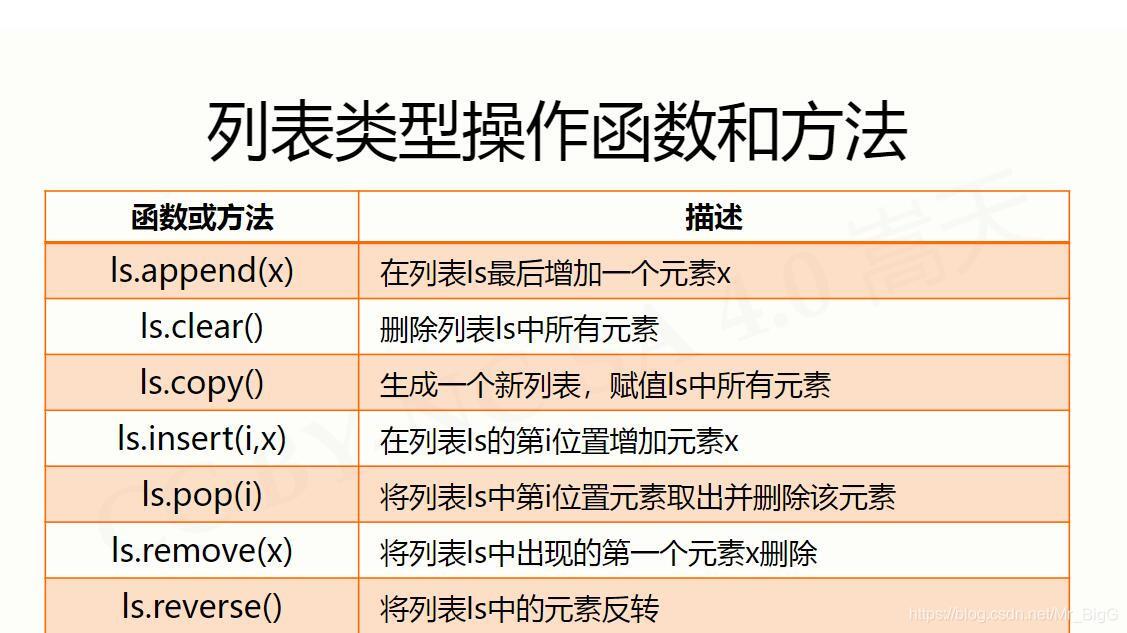
字典
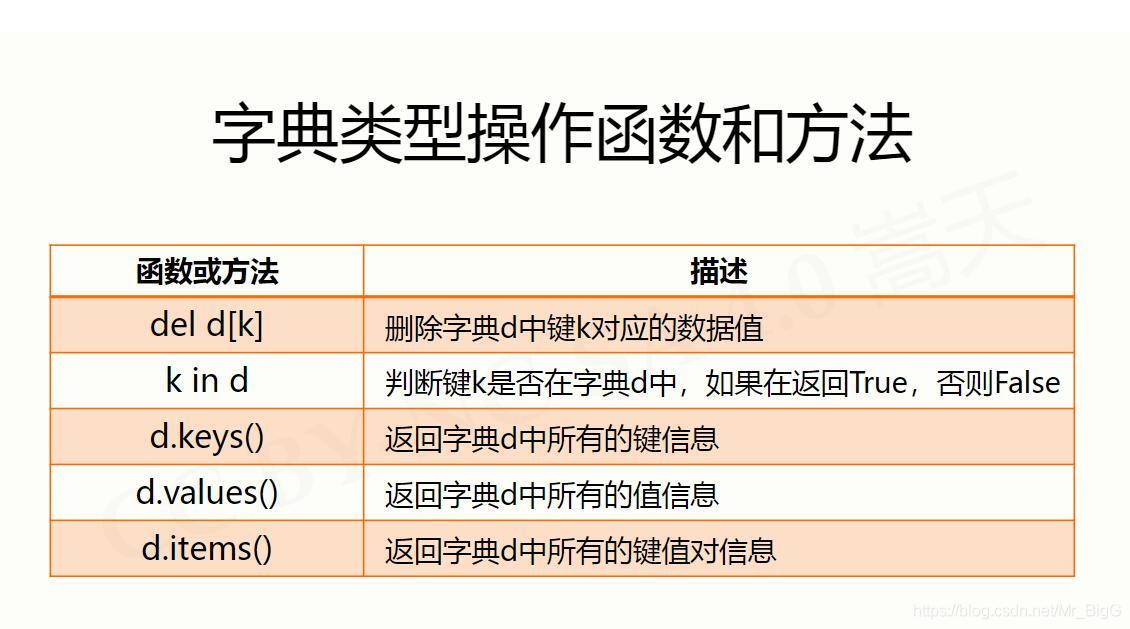
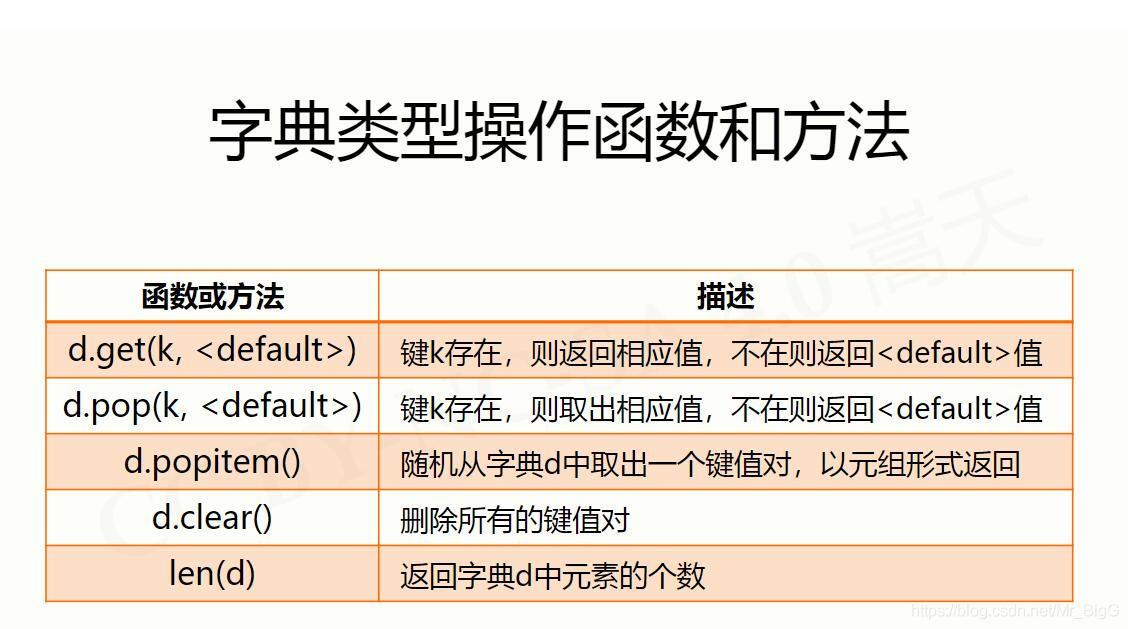
jieba庫的安裝
jieba庫是優秀的中文分詞第三方庫
安裝教程
win+r打開cmd控制臺,輸入命令 pip install jieba 安裝jieba庫
使用方法


文本詞頻統計
文本下載地址如圖所示:

進入上述網址后,頁面右鍵另存為本地的txt檔案即可
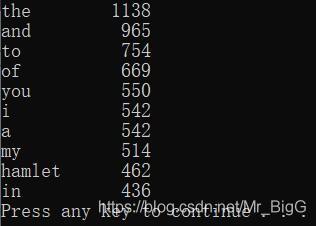
《哈姆雷特》詞頻統計
根據《哈姆雷特》的txt文本,統計其中出現頻率最高的英文詞匯
效果圖
源代碼
#CalHamlet.py
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") #將文本中的所有特殊符號換為空格
return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True) #按照從大到小,以鍵值對第二個位置為索引
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
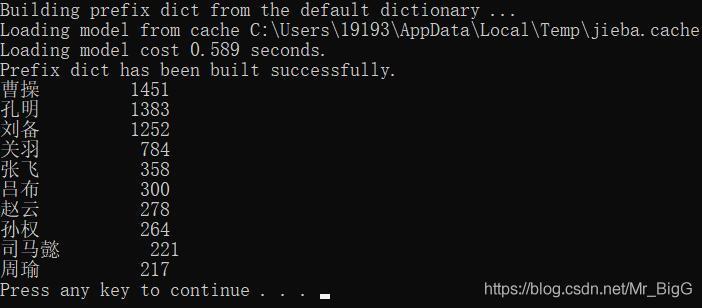
《三國演義》人物出現頻率統計
根據《三國演義》的txt文本,統計其中人物出現頻率最高的前10名
效果圖
源代碼
#CalThreeKingdoms.py
import jieba
txt = open("threekingdoms.txt", "r", encoding = "utf-8").read()
#exclude為排除詞庫,排除有可能組成中文單詞的卻不是人名的出現頻率較高的詞匯
excludes = {"將軍", "卻說", "荊州", "二人", "不可", "不能", "如此", "商議", "如何", "主公", "軍士", \
"左右", "軍馬", "引兵", "次日", "大喜", "天下", "東吳", "于是", "今日", "不敢", "魏兵", \
"陛下", "一人", "都督", "人馬", "不知", "漢中"}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "諸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "關公" or word == "云長":
rword = "關羽"
elif word == "玄德" or word == "玄德曰":
rword = "劉備"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
注:本文是博主本人學習的日常記錄,不進行任何商用所以不支持轉載請理解!如果你也對Python有一定的興趣和理解,歡迎隨時找博主交流~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249481.html
標籤:python
上一篇:python爬蟲