【Python爬蟲】單執行緒爬取微博熱搜
最近有很多小伙伴們都天天在微博上吃到各種不少的瓜吧,一打開微博熱搜榜就是當下的熱點頭條,那么我們怎么用程式來爬取微博熱搜的內容呢?
今天我就來教會大家怎么用爬蟲爬取微博熱搜上的內容,可以隨時隨地在自己電腦上run一下就可以獲取到當下微博熱搜,
首先,什么是爬蟲呢?
網路爬蟲(又稱為網頁蜘蛛,網路機器人,在FOAF社區中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取萬維網資訊的程式或者腳本,另外一些不常使用的名字還有螞蟻、自動索引、模擬程式或者蠕蟲, ——《百度百科》
我們寫爬蟲用的是Python語言(一般寫爬蟲程式都是選擇Python)
關于Python如何安裝我就不在這里贅述了,大家可自行到網上去百度下載,網上也有各種教程教你安裝Python環境,安裝起來也很簡單,
寫爬蟲程式一般要用到一些第三方庫,比如requests,bs4,xpath…
安裝方法:打開cmd;輸入:
pip install requests #例如安裝requests
寫爬蟲第一步,匯入需要的第三方庫(也可以什么時候需要什么時候加)
import requests
from bs4 import BeautifulSoup
from urllib import parse
import time
- 然后,我們需要微博熱搜的網址,即url,URL=https://s.weibo.com/top/summary?cate=realtimehot
- 所謂爬蟲就是我們用程式模擬人類行為去請求訪問服務器,然后服務器會給我們回應,回傳網頁內容,
定義第一個函式:請求網頁內容,這里我們先給出一部分代碼:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
} #模擬瀏覽器行為
def get_url(url):
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return ""
當我們得到請求的網頁內容后,我們需要將網頁內容轉換為我們所要的格式來輸出,(網頁內容即網頁源代碼,瀏覽器經過JavaScript渲染后就是我們在瀏覽器上看到的豐富的頁面內容,爬蟲里沒有JavaScript的支持,所以回傳的是網頁源代碼)
下面我們來定義第二個函式:獲取網頁內容
這里我們需要用到BeautifulSoup庫,將源代碼變成我們要的資料格式,
這部分代碼如下:
def get_html(html):
soup = BeautifulSoup(html,'lxml')
trs = soup.select('table tbody tr')
for tr in trs:
title = tr.select_one('td a').text
link = tr.select_one('td a')['href']
link = parse.urljoin('https://s.weibo.com/',link)
print(title,link)
最后,程式需要一個主函式,即main(),主函式用來呼叫函式,另外URL等內容也可以放在主函式中,
if __name__ == '__main__':
start = time.time()
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
url2 = 'https://s.weibo.com/top/summary?cate=socialevent'
html = get_url(url)
get_html(html)
html2 = get_url(url2)
get_html(html2)
print(time.time()-start) #用來檢測程式運行時間
完整代碼如下
import requests
from bs4 import BeautifulSoup
from urllib import parse
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
} #模擬瀏覽器行為
def get_url(url):
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
else:
return ""
def get_html(html):
soup = BeautifulSoup(html,'lxml')
trs = soup.select('table tbody tr')
for tr in trs:
title = tr.select_one('td a').text
link = tr.select_one('td a')['href']
link = parse.urljoin('https://s.weibo.com/',link)
print(title,link)
if __name__ == '__main__':
start = time.time()
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
url2 = 'https://s.weibo.com/top/summary?cate=socialevent'
html = get_url(url)
get_html(html)
html2 = get_url(url2)
get_html(html2)
print(time.time()-start)
展示效果如下
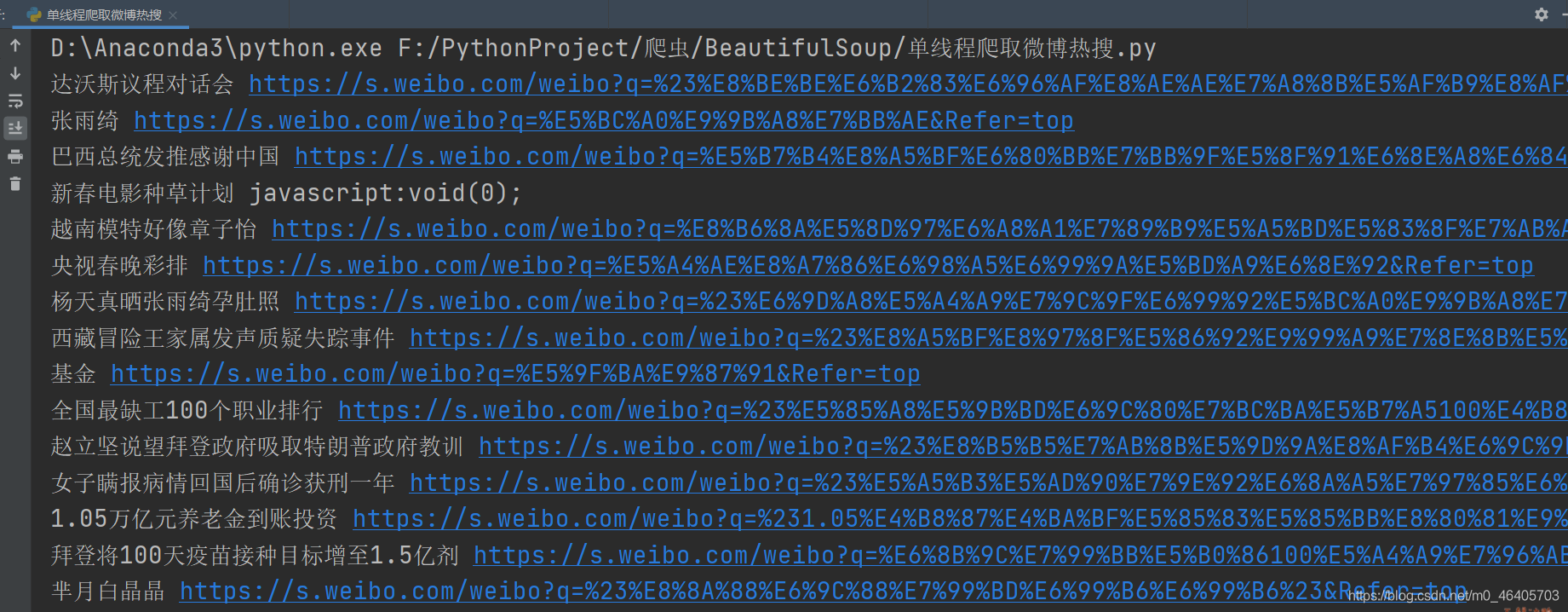
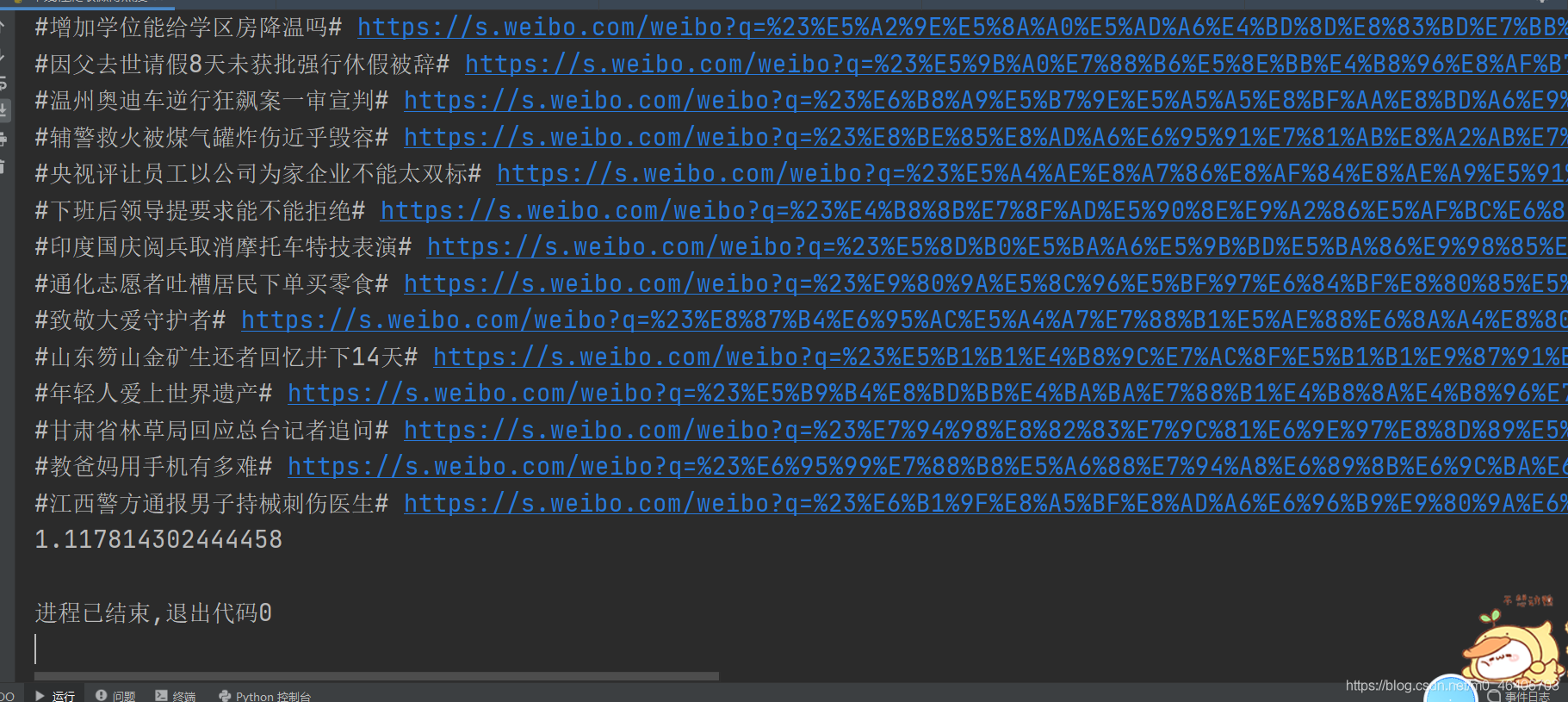
有疑問的可以在評論區評論,歡迎大家積極討論,也可以私信博主哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/253098.html
標籤:python