使用python撰寫網路爬蟲
- 前言
- 1、為何使用爬蟲
- 2、撰寫爬蟲的知識要求
- 3、確定爬蟲使用的工具庫
- 4、確定要獲取的資料集
- 4.1 分析Url地址變化
- 4.2 獲取目標資料集所在的HTML區域
- 5、開始爬取頁面
- 5.1 模擬瀏覽器
- 5.2 獲取目標HTML區域中的資料
前言
此篇文章是本人撰寫爬蟲獲取資料的心得體會,涉及到資料收集、資料預處理,對于資料存盤、資料處理與分析、資料展示/資料可視化、資料應用部分請關注我的新文章,僅適用于新手python、爬蟲入門,
特別說明:
**1、本篇內容僅供個人學習交流用,禁止作為商業用途,【轉載請注明出處】 https://blog.csdn.net/qq_44092306/
2、本篇文章只是介紹爬蟲的思路,對于參考的模塊不做詳細解釋,模塊詳細解釋請大家查閱其他資料,謝謝!
1、為何使用爬蟲
簡單的說,使用爬蟲的目的就是為了降低作業量,舉個例子,當我們需要獲取一些資訊的時候,這些資訊存在于不同的網頁上面,而且資料量巨大,單純的靠人工去記錄則會浪費很多時間和精力,這時,我們就可以使用爬蟲作為工具去獲取這些資料集,大大減少了機械性作業的時間,在大資料中,資料的獲取往往離不開爬蟲,
2、撰寫爬蟲的知識要求
- python基礎知識:語法規則、控制陳述句、資料結構(字典、元組、串列)、函式 、模塊
- HTML基礎、CSS基礎、http、https協議
- 會靈活的字串處理、資料結構的處理
3、確定爬蟲使用的工具庫
本人使用的python版本為3
from bs4 import BeautifulSoup
import requests
import lxml
4、確定要獲取的資料集
資源定位:獲取貝殼網中的二手房房源資訊
說明: 我們在選擇目標網址的時候,盡量選擇正規,用戶使用量多的網站,雖然會遇到一些反爬措施,小網站盡量不要爬,因為小網站的網頁格式有些并不是固定的,當我們寫了爬蟲代碼后,運行起來會發現不能夠通用,從而使爬取復雜化,
要獲取的資料集: 房源標題、樓盤名稱、簡介、價格 (其他資料項也可獲取,這幾項只是作為例子)
4.1 分析Url地址變化

通過瀏覽網頁發現,底部有分頁導航欄,點擊下一頁時,url變化為
https://jn.ke.com/ershoufang/pg2/
因此,首頁為https://jn.ke.com/ershoufang/pg1/,至此url變化分析完畢,
分析URL地址變化的目的是: 通過request.get()方法回圈這些url,獲取到HTML頁面元素
4.2 獲取目標資料集所在的HTML區域
在目標網頁上面點擊F12進入開發者模式,我們只想取得房源資訊,因此其他HTML均為無用資料,無需獲取,我們所做的是盡量將目標區域縮小到最小范圍,
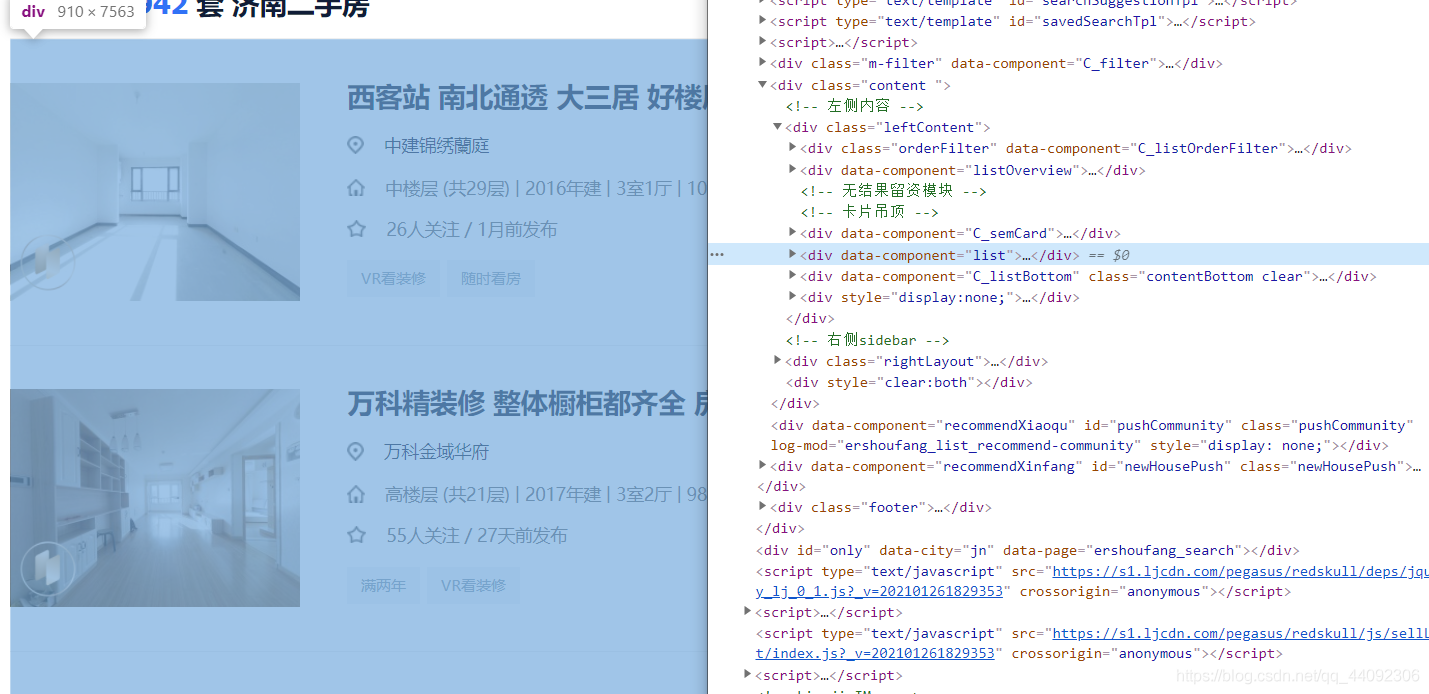
通過分析,房源串列項所在區域均在<div data-componet=’‘list’’>標簽中,通過瀏覽發現,還可以繼續縮小區域 ,最終,目標區域縮小到
5、開始爬取頁面
5.1 模擬瀏覽器
因為大部分的網站都有反爬取機制,所以我們需要讓程式去模擬瀏覽器,通過設定代理和請求頭,以及時間間隔,這幾種方法可以避免大多數的網站把我們的請求掛掉,
# 請求頭
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0Win64x64) AppleWebKit / 537.36(XHTML, likeGecko) Chrome '
'/ 11.1.1111.111Safari / 111.11'
}
# 設定代理 http-協議型別 101.4.136.34-代理ip 82-代理埠
proxy = {'http': 'http://101.4.136.34:82'}
r = requests.get(url, headers=headers, proxies=proxy)
r.encoding = 'gbk' #設定編碼格式
context = r.text
# 第一個引數表示被決議的html內容,第二個引數表示使用的決議器
soup = BeautifulSoup(context, 'lxml')
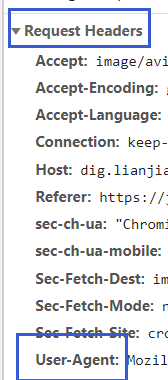
請求頭通過需要F12查看
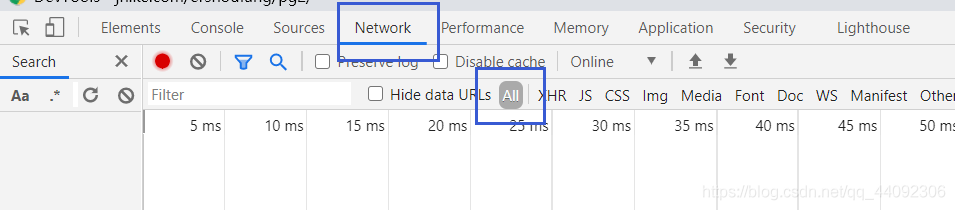
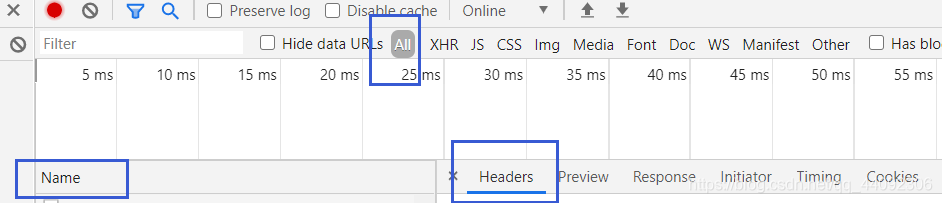
選擇Name中的一項,查看Headers,找到如下內容復制到代碼里面即可
soup即為我們決議后的HTML網頁,大家可以試著print(soup)看看是什么,
就是一個對應URL的HTML檔案
5.2 獲取目標HTML區域中的資料
通過前面的步驟,我們將資料集范圍區域縮小到了<div class=’‘info clear’’>標簽中,現在我們可以獲取到里面的內容了,
- 獲取一頁中所有的<div class=’‘info clear’’>項
info_clear_all = soup.find_all('div', _class='info clear')
- 遍歷info_clear_all
- 在迭代器的遍歷范圍內找到目標資料所在區域
- 獲取目標資料區域的具體內容
具體代碼如下:
from webbrowser import Mozilla
from bs4 import BeautifulSoup
import requests
import lxml
import random
import time
url = 'https://jn.ke.com/ershoufang/'
def getSoup(Url):
# 設定請求頭
headers = {
# headers中的內容為您瀏覽器的具體資訊,請參考上述補充
}
# 設定代理 http-協議型別 101.4.136.34-代理ip 82-代理埠
proxy = {'http': 'http://101.4.136.34:82'}
r = requests.get(Url, headers=headers, proxies=proxy)
# 獲取網頁的編碼格式
encode = r.encoding
# 獲取HTML網頁
context = r.text
# 決議網頁
soup = BeautifulSoup(context, 'lxml')
return soup
def getContext():
soup = getSoup(url)
# 獲取<div class='info clear'></div>所有標簽項
info_clear_all = soup.find_all('div', class_='info clear')
for a in info_clear_all:
# 獲取標題
label_a_title = a.find('a', class_='VIEWDATA CLICKDATA maidian-detail') # 獲取標題所在的a標簽
title = label_a_title.attrs['title'] # 獲取標題
print('標題:'+title)
# 獲取樓盤名稱
positionInfo = a.find('div', class_='positionInfo') # 縮小樓盤名稱所在范圍
label_a = positionInfo.find('a') # 獲取<a>標簽
building_name = label_a.text # 獲取樓盤名稱
print('樓盤名稱:' + building_name)
# 獲取樓盤簡介
houseInfo = a.find('div', class_='houseInfo') # 獲取簡介所在的div范圍
introduce = houseInfo.text.replace(' ', '').strip().replace('\n', '') # 獲取簡介
print('樓盤簡介:'+introduce)
# 獲取樓盤價格
totalPrice = a.find('div', class_='totalPrice') # 獲取樓盤價格所在div范圍
price = totalPrice.text # 獲取樓盤價格
print('樓盤價格:'+price+'\n')
if __name__ == "__main__":
getContext()
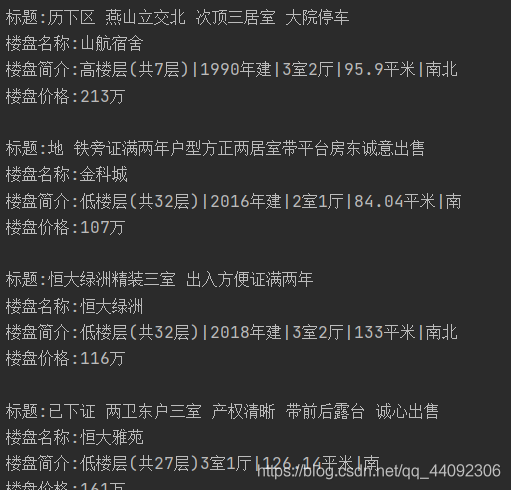
運行結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254079.html
標籤:python