上期博客我們通過Python爬蟲獲取了京東商城的手機價格及其詳細配置資料, 這期我們試著通過爬蟲在房天下(房天下烏魯木齊網址)上獲取烏魯木齊的二手房資訊, 同時利用之前已經測驗過的坐標查詢代碼來獲得每一個二手房的詳細位置.
分析URL
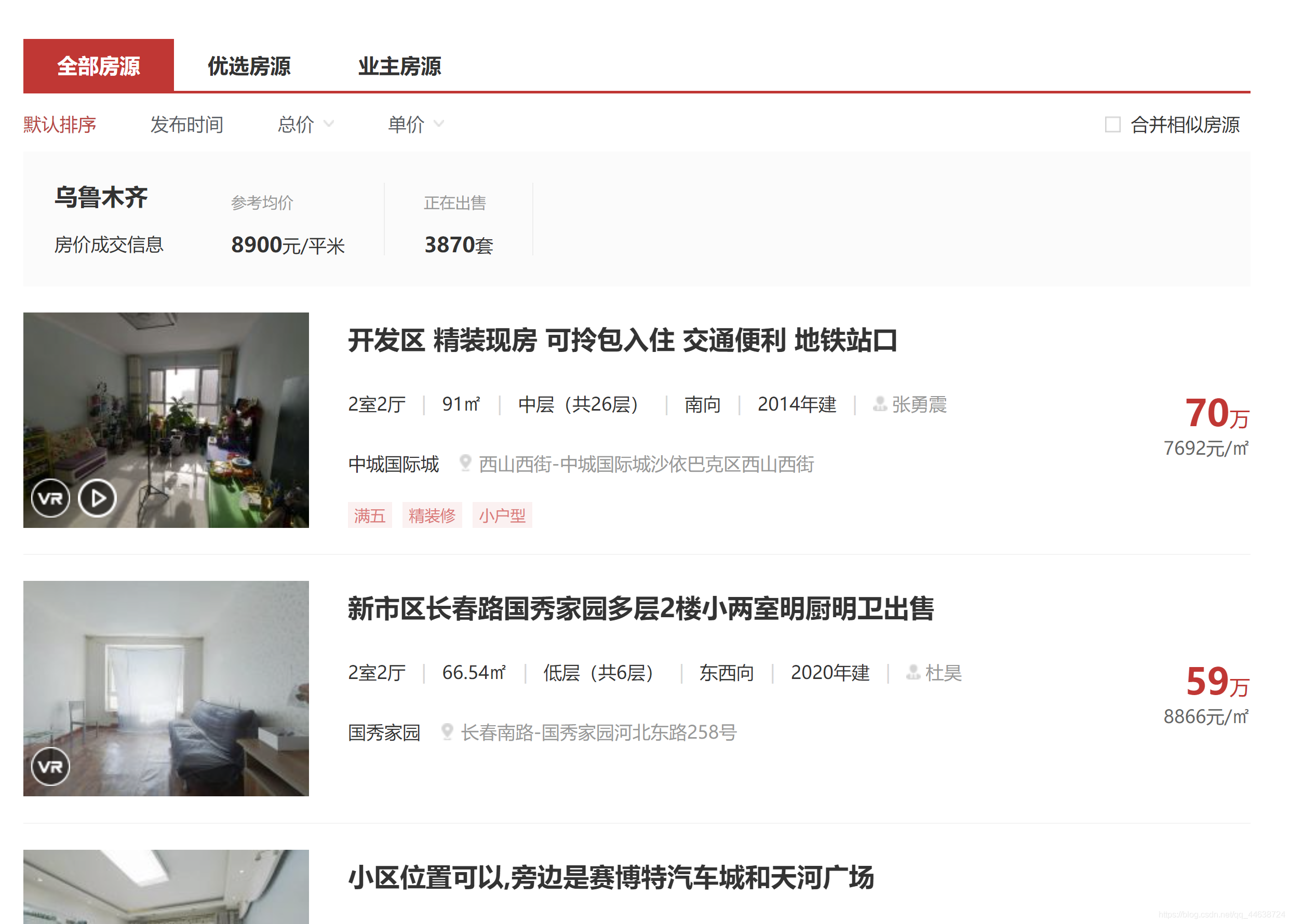
進入二手房的銷售串列URL, 其中包括房屋的售賣標題、戶型、面積、樓層情況、朝向、建成年份、售價、位置等資訊. 那么本期就先從房屋的基本屬性開始爬取, 關于其詳細資訊的爬取會在(下)中給出.
- 進入開發者工具
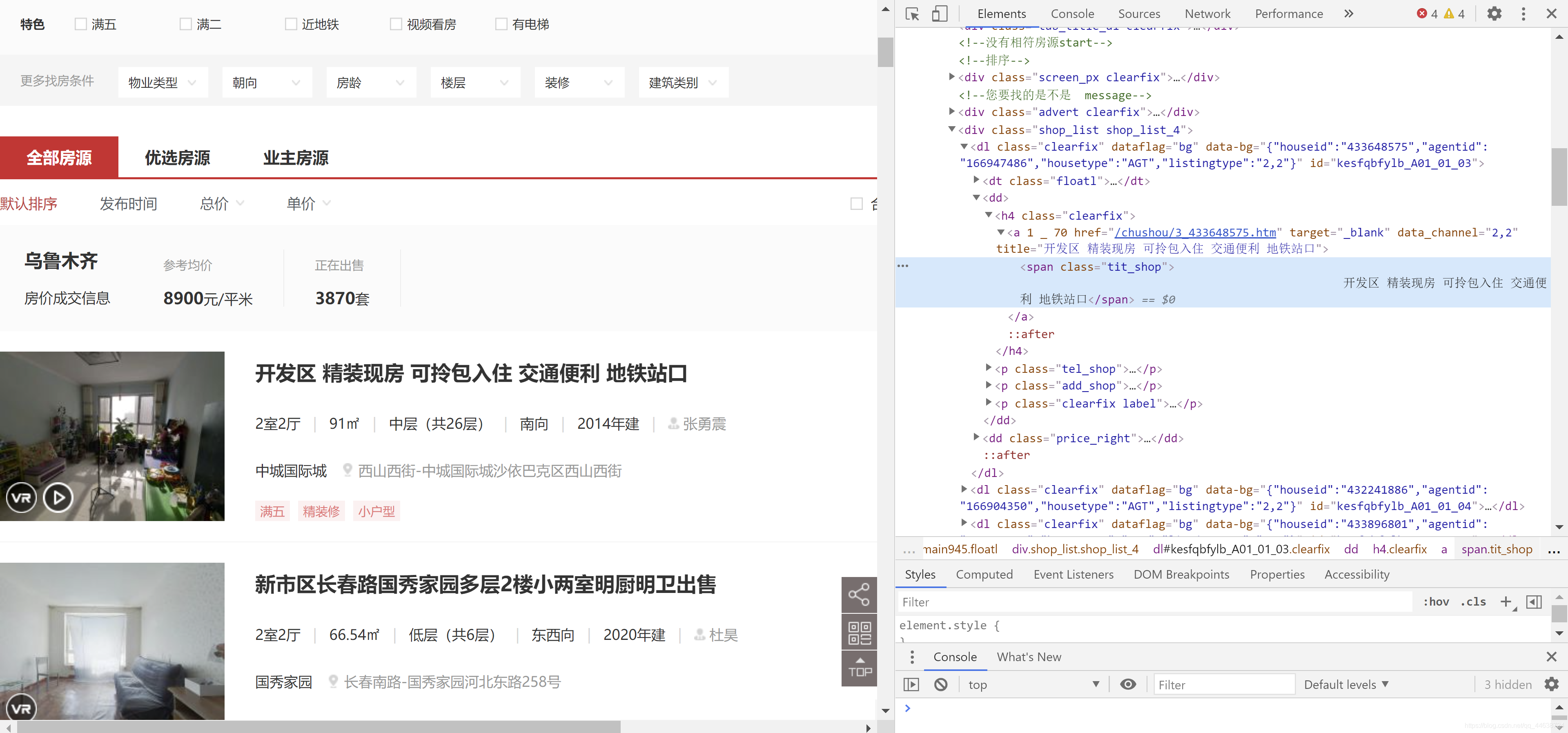
不難看出, 存放這些資訊的標簽很容易就可以找到, 那么就很容易了, 先給出結果:
import numpy as np
import matplotlib.pyplot as plt
import os
import pandas as pd
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
#https://xj.esf.fang.com/house/i31/ http example
#url = 'https://xj.esf.fang.com'
meanUrl = "https://xj.esf.fang.com/house/i31"
meanPage = requests.get(meanUrl, headers=headers)
print("頁面狀態碼:{0}".format(meanPage.status_code))
soup = BeautifulSoup(meanPage.text, "html.parser")
tag = soup.find_all("script")[3]
a = str(tag).find("rfss")
var_t4 = meanUrl
var_t3 = str(text)[a:a + 28]
newUrl = var_t4 + "?" + var_t3
print("當前訪問為 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text, "html.parser")
#print(newSoup)
fangData = []
attrs = ["戶型", "面積", "樓層", "朝向", "建成時間", "經紀人", "地址", "單價"]
df = pd.DataFrame(columns=attrs)
def process_bar(percent, start_str='', end_str='', total_length=0):
bar = ''.join(
["\033[31m%s\033[0m" % ' '] * int(percent * total_length)) + ''
bar = '\r' + start_str + bar.ljust(total_length) + ' {:0>4.1f}%|'.format(
percent * 100) + end_str
print(bar, end='', flush=True)
n = 10
for i in range(n):
try:
p = newSoup.find_all("dl", {"class": "clearfix"})[i].dd.p #首頁資訊
span = newSoup.find_all("p", {"class": "add_shop"})[i] #地址資訊
info = p.text.replace("\t", "").replace("\n",
"").split("|") #資訊匯總(list)
price = newSoup.find_all("dd", {"class": "price_right"})[i] #單價
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df.loc[i] = info
except:
pass
end_str = '100%'
process_bar(i/(n-1), start_str='', end_str=end_str, total_length=15)
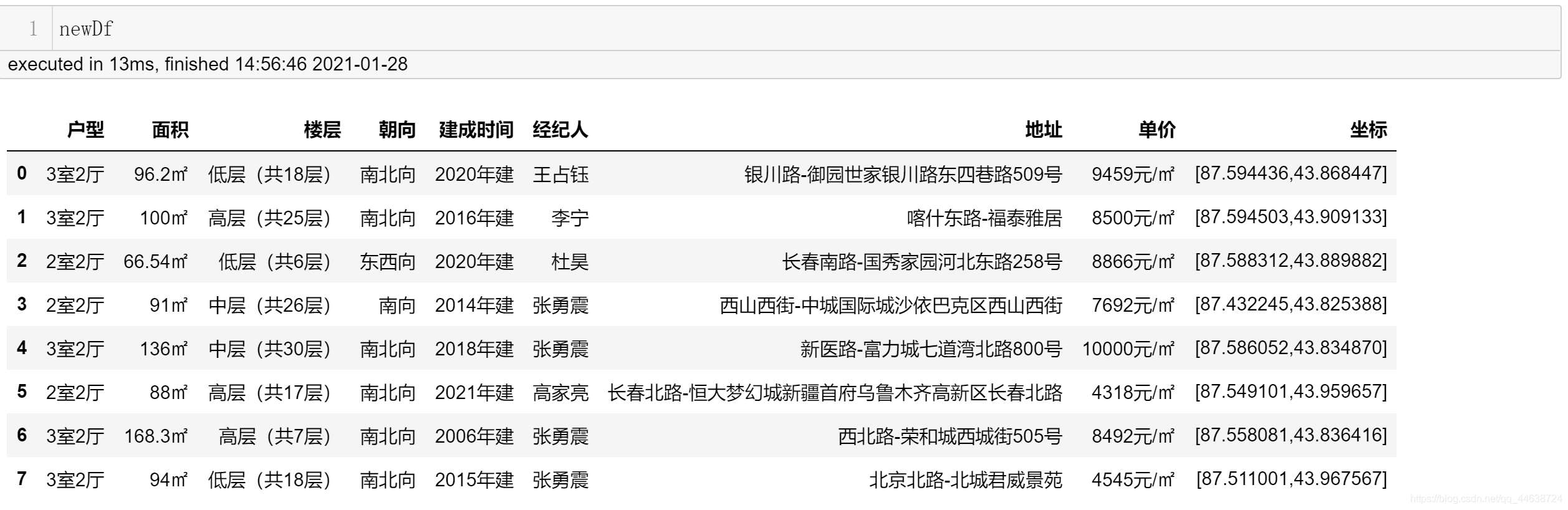
newDf = df.reset_index(drop=True)
print(newDf)
運行結果
代碼中坐標查詢部分可以查看我的這期博客: 通過Python實作目標點經緯度的自動查詢.
- tips
需要注意的是我只爬取了第一頁上的房價資訊, 而在代碼中給出URL則是https://xj.esf.fang.com/house/i31而不是開始提到的https://xj.esf.fang.com/
這是因為在測驗代碼的程序中, 我發現上述兩個URL都指向第一頁的內容, 但兩者給出的商品房資訊則是不盡相同的, 下圖是https://xj.esf.fang.com/house/i31給出的內容(從第二條資訊開始就不相同了)
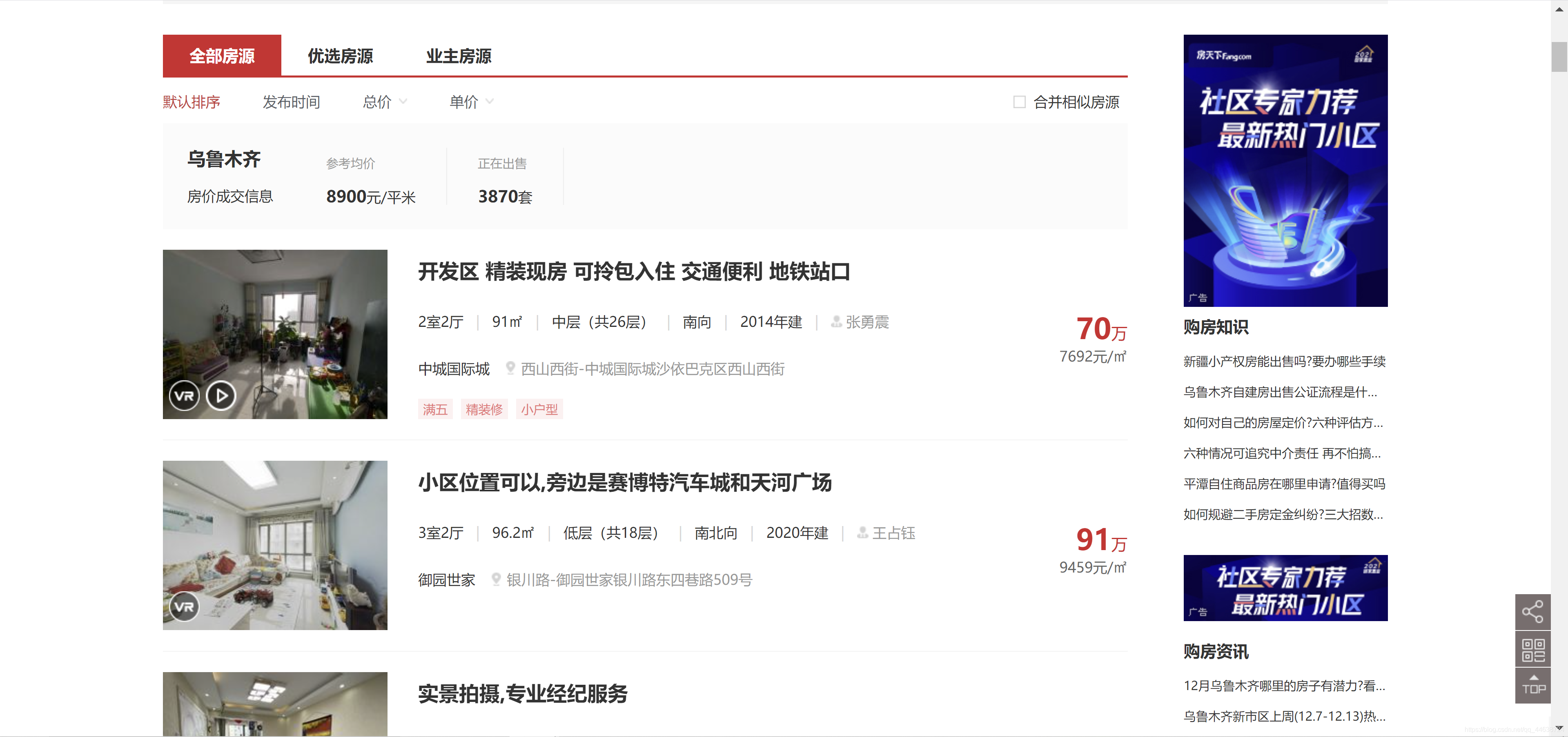
另外一點. 當我們通過request.get方法來訪問https://xj.esf.fang.com/house/i31時是無法獲得上述圖片中的資訊的, response物件被指向了其他的URL, 內容為
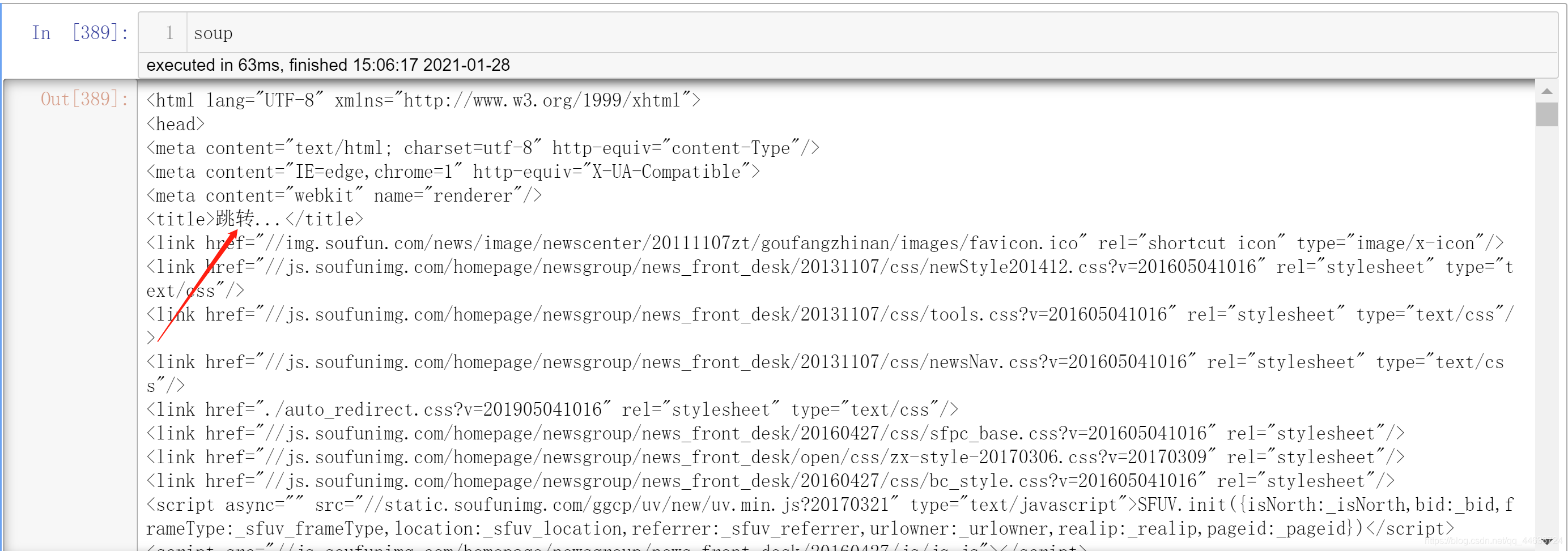
顯然URL發生了跳轉, 那么跳轉后的地址是什么呢?其實通過瀏覽器來訪問https://xj.esf.fang.com/house/i31就會得到跳轉后的URL為https://xj.esf.fang.com/house/i31?rfss=1-44a29fbb0a420c8e8b-38, 顯然這是一個反爬蟲策略, 我們是否在每次訪問串列的時候都要手動獲取跳轉后的URL呢?當然不是, 不然爬蟲就失去了意義. 讓我們來分析這個錯誤的URL
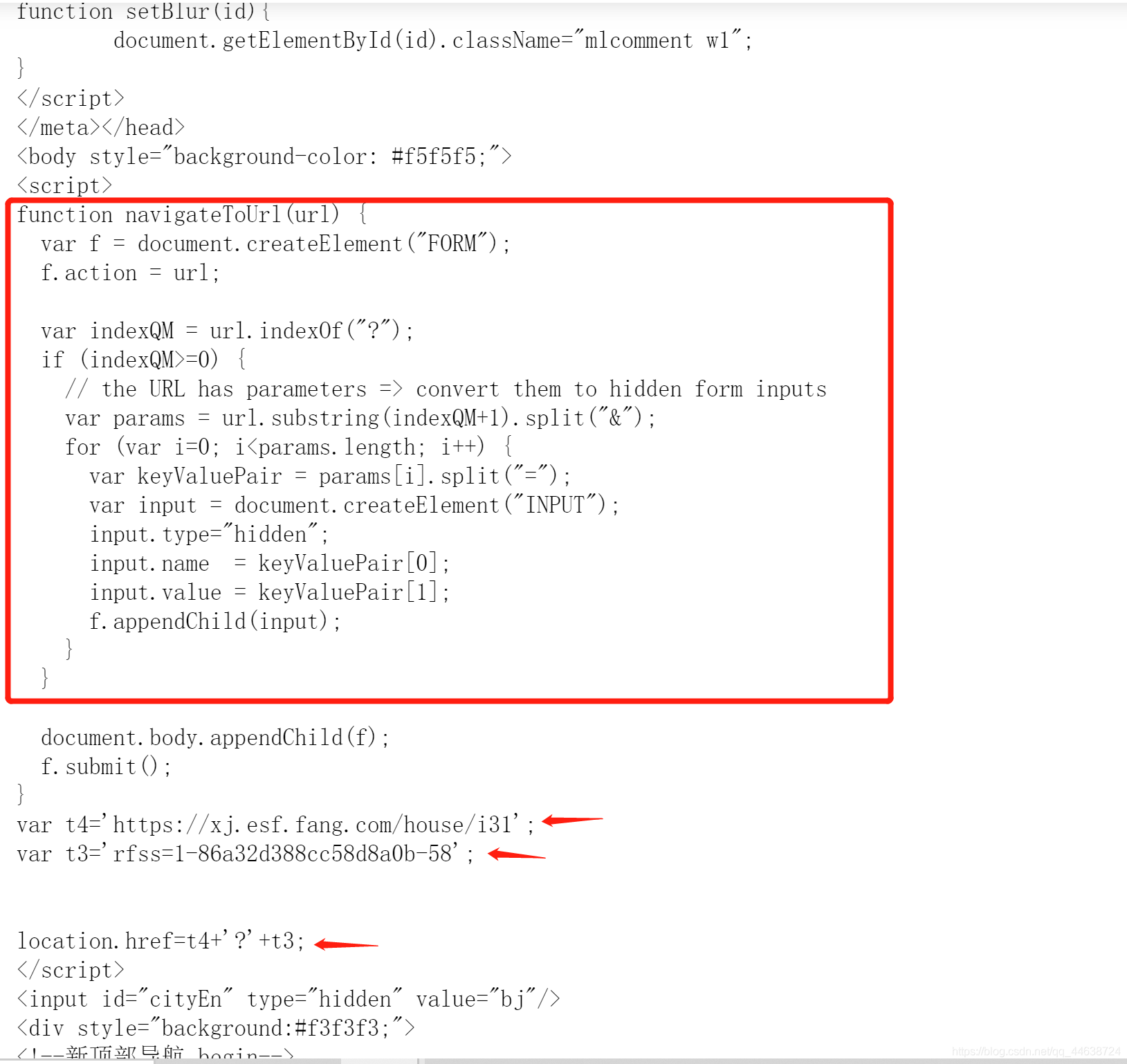
顯然這段JS代碼中的**function navigateToUrl(url)**就是為訪問地址提供加密服務. 下面的var t4、var t3正是加密后的結果, 所以跳轉后的URL為t4 + ? + t3. 那么直接上代碼把它抓下來
tag = soup.find_all("script")[3]
a = str(tag).find("rfss")
var_t4 = meanUrl
var_t3 = str(text)[a:a + 28]
newUrl = var_t4 + "?" + var_t3
這樣就能保證正確的訪問我們需要的URL了
在爬取的程序中還存在著另外一個問題, 即有些標簽內并不含有我們需要的資訊, 導致find_all()無法回傳結果就會報錯, 所以我們采用try except的代碼形式來跳過錯誤或不完整資訊
try:
p = newSoup.find_all("dl", {"class": "clearfix"})[i].dd.p #首頁資訊
span = newSoup.find_all("p", {"class": "add_shop"})[i] #地址資訊
info = p.text.replace("\t", "").replace("\n",
"").split("|") #資訊匯總(list)
price = newSoup.find_all("dd", {"class": "price_right"})[i] #單價
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df.loc[i] = info
except:
pass
這雖然能保證代碼的正常運行, 但跳過一些標簽也導致了最后回傳DataFrame時資料的索引并不是無間斷排序的, 所以還需要加一段
newDf = df.reset_index(drop=True)
來使索引重新排序. 這樣一頁內容的爬取就完成了, 其他頁內的內容只需要在此基礎上加上一個回圈, 將https://xj.esf.fang.com/house/i31按i32 i33 i34的順序回圈即可.
- 一點說明
def process_bar(percent, start_str='', end_str='', total_length=0):
bar = ''.join(
["\033[31m%s\033[0m" % ' '] * int(percent * total_length)) + ''
bar = '\r' + start_str + bar.ljust(total_length) + ' {:0>4.1f}%|'.format(
percent * 100) + end_str
print(bar, end='', flush=True)
這段代碼是加入了爬取的進度條, 并不是出于美觀, 而是大規模爬蟲時進度條能很快的反映程式有沒有出錯, 錯誤在哪一次回圈, 好讓我們快速的debug.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254080.html
標籤:python
上一篇:使用python撰寫網路爬蟲