??我們知道,python的變數是有型別的,對于python變數的幾種資料型別,我們在寫python時是必須要有一定的概念的,知道資料型別就要知道變數資料型別怎么存盤,可是為什么python的變數不需要宣告資料型別就可以直接賦值?變數如果有資料型別,那變數不是可以為任意資料型別?那真正的資料型別如int在記憶體存盤的位元組大小應該為多少?等等諸如一系列的問題讓我提起了的興趣,經過網上不斷查找學習后,在此將我所了解到的內容在此做個總結歸納,
文章目錄
- 一、變數的資料型別
- 1、什么是變數的資料型別
- 2、python五大標準資料型別
- 二、python變數的存盤
- 1、變數與儲存地址的關系
- 2、復雜資料型別的存盤方式
- 3、變數的賦值——淺拷貝和深拷貝
- 三、python變數資料型別的大小
- 總結
一、變數的資料型別
1、什么是變數的資料型別
??我們先捋一捋什么是變數,變數從字面上理解就是可以變化的量,我們可以隨時改變這個變數的值,使得我們可以呼叫同一個變數而獲得不同的值,與之對應的是常量,那么對于一個可變的變數,它有可能表示是一個字串,一個數字或者是一個小數,因為這些在計算機記憶體里存放的方式是不一樣的,所以簡單理解就是變數的資料型別不同就是對應的資料在計算機記憶體中存放方式的不同,這種方式表現在按多少位元組存盤,是否連續存盤等,
??我們都知道,c是靜態型別語言,一種在編譯期間就確定資料型別的語言,也就是我們需要對變數先宣告其資料型別后才能使用,并且在使用程序中一般不能賦值一些超過該資料型別數值,比如:int a = 1.2,當然大型別是可以轉向小型別的,如:double a = 1 (double型別接收整形數值),可以肯定的,大多數靜態型別語言都這么干,
??當然,python語言也有資料型別,但python語言不同,它是一種動態型別語言,又是強型別語言,它們確定一個變數的資料型別是在你第一次給它賦值的時候,也就是說你賦值給變數什么資料型別的數值,變數就是什么資料型別的,所以,對比之下,c語言變數的資料型別是事先定義的,而python是后天接受的,
2、python五大標準資料型別
??在講變數存盤之前,這里先簡單總結下python的五大標準資料型別,為了方便展示,我們采用type方法顯示變數的資料型別,
(1)Numbers(數字)
??數字資料型別用于存盤數值,他們是不可改變的資料型別,可簡單分為以下四種:(注意這里十六進制,八進制都屬于int整形,)
int(整型):
var = 520
print(type(var)) # <class 'int'>
float(浮點型):
var = 5.20
print(type(var)) # 輸出:<class 'float'>
bool(布爾型):
var = true
print(type(var)) # 輸出:<class 'bool'>
complex(復數):
var = complex(13,14)
print(type(var)) # 輸出:<class 'complex'>
(2)String(字串)
??字串或串是由數字、字母、下劃線組成的一串字符,用‘’,“”,“‘ ’”都可表示,三者的使用可參考這篇文章: python字串的各種表達方式.
??如下方代碼所示,獲得的型別為str型別,另外也順便提一個小知識點,要訪問字串可以正向訪問也可以反向訪問,即正向時,var[0] = ‘p’,var[1] = ‘i’,var[2] = ‘g’;而反向時,var[-1] = ‘g’,var[-2] = ‘i’,var[-3] = ‘p’,
var = “pig”
print(type(var)) # 輸出:<class 'str'>
print(var[0:3]) # 正向訪問,輸出:'pig'
print(var[-1]) # 反向訪問,輸出:'g'
(3)List(串列)
??串列是 Python 中使用最頻繁的資料型別,用 [ ] 標識,串列可以完成大多數集合類的資料結構實作,它可以同時包含字符,數字,字串甚至可以包含串列(即嵌套),如下方代碼所示,串列的處理方式和字串類似,
var = [ 'pig' , 1 , 2.2 ]
print(type(var)) # 輸出:<class 'list'>
print(var[0]) # 獲得第一個元素,輸出:'pig'
print(var+var) # 列印組合的串列,輸出:[ 'pig', 1 , 2.2,'pig', 1 , 2.2 ]
(4)Tuple(元組)
??元組類似于 List(串列),元組用 () 標識,內部元素用逗號隔開,但是元組不能二次賦值,相當于只讀串列,
var = ( 'pig', 1 , 2.2 )
print(type(var)) # 輸出:<class 'tuple'>
print(var[0]) # 獲得第一個元素,輸出:'pig'
print(var+var) # 列印組合的元組,輸出:( 'pig', 1 , 2.2,'pig', 1 , 2.2 )
var[0] = 'dog' # 出錯!不能被二次賦值
(5)Dictionary(字典)
??字典的相對于串列來說,串列是有序的物件集合,而字典是無序的物件集合,兩者之間的區別在于字典當中的元素是通過鍵來存取的,而不是通過偏移存取,字典用"{ }"標識,字典由索引key和它對應的值value組成,
dic = {'name':'張三','age':18}
print(dic ['name']) # 得到鍵為'name' 的值,輸出:'張三'
print(dic [age]) # 得到鍵為'age' 的值,輸出:18
print(dic) # 得到完整的字典,輸出:{'name':'張三','age':18}
print(dic.keys()) # 得到所有鍵,輸出:dict_keys:(['name','age'])
print(dic.values()) # 輸出所有值,輸出:dict_values:(['張三',18])
二、python變數的存盤
1、變數與儲存地址的關系
??在高級語言中,變數是對記憶體及其地址的抽象,以c語言舉例, 變數事先定義好一種資料型別,于是編譯器為變數分配一個對應型別的地址空間和大小(如int 4位元組,char 1位元組),當該變數改變值時,改變的只是這塊地址空間中保存的值,即在程式運行中,變數的地址就不能再發生改變了,這種存盤方式稱為值語意,如下代碼用VS2015運行,由結果可知,test變數的值被存盤在0x0020FDC8,當變數改變時,地址不變,地址中對應的值發生改變,
#include<iostream>
using namespace std;
int main()
{
int test = 1;
cout << &test << ":" << test << endl;
test = 2;
cout << &test << ":" << test << endl;
return 0;
}
運行結果:
0020FDC8:1
0020FDC8:2
??這里就存在一個問題,每次新建一個變數,編譯器就會開辟一塊對應資料型別大小的記憶體,然后給那塊記憶體取個名字(變數名),除非一塊記憶體被釋放,那么該變數才能釋放,不然一個變數就只能固定地對應一個資料型別,
??對此,python做出了改變,它采用了與高級語言截然不同的方式,在python中,一切變數都是物件,變數的存盤采用了參考語意的方式,存盤的只是一個變數的值所在的記憶體地址,而不是這個變數的值本身,簡單理解就是,python變數只是某個資料的參考(可以理解成C語言的指標),當python變數賦值時,解釋器(因為python為解釋性語言)先為數值開辟一塊空間,而變數則指向這塊空間,當變數改變值時,改變的并不是這塊空間中保存的值,而是改變了變數的指向,使變數指向另一個地址空間,這種存盤方式稱為物件語意或指標語意,舉個例子:
str = 'girls are pig'
print(id(str))
str = 'boys are dog'
print(id(str))
運行結果:
113811696
113812464
??id()方法可以獲得變數指向的地址,由運行結果所示,一開始變數指向了113811696這個地址,這個地址存放了‘girls are pig’這個字串,當變數發生改變時,即該變數的指向改變了,指向地址113812464,該地址存放有‘boys are dog’這個字串,這兩個字串都是一開始解釋器先在記憶體開辟好的,
??所以,這也就解釋了為什么python的變數被整形賦值就成了整形,被串列賦值就成了串列,變數可以為任意資料型別的,因為python的變數只是對編譯器事先在記憶體存放好的資料的參考,
??python采用這種方式,好處就體現在,對于解釋器來說,變數就只是一個地址的參考,而這個參考是可以隨時改變的,那么就可以做到一個變數用來指向各種各樣的資料型別,只要每次記錄變數與哪個資料型別連接就行了,效率不就提升了嘛~,而對于c語言的編譯器來說,一個變數就只能與一個資料型別長相廝守,所以它望著記錄了各種各樣變數名與記憶體值對應的表格,一邊編譯,一邊陷入了沉思…(這里注意一點牛角尖,變數名只是給解釋器看的東西,在記憶體是不做存盤的,真正存盤的是變數名對應的內容,上面說的變數都是int a中a這個個體)
2、復雜資料型別的存盤方式
??這里說的復雜資料型別主要是像串列,字典等這種可以改變內部資料的資料型別,以串列作為例子舉例,代碼如下所示:
list1 = [1,2,3]
print(list1) #輸出:[1,2,3]
print(id(list1)) #輸出:112607104(不同電腦分配給變數的地址不同)
list1[0] = "hello"
print(list1) #輸出:['hello',2,3]
print(id(list1)) #輸出:112607104
list1.append(4)
print(list1) #輸出:['hello',2,3,4]
print(id(list1)) #輸出:112607104
list1 = ['hello',4]
print(list1) #輸出:['hello',4]
print(id(list1)) #輸出:112925120
??由運行結果所示,無論對串列list1進行什么增刪改查操作,都不會影響list1本身的存盤,只是改變了存盤的內容,但list1重新賦值時,地址則發生改變,這個為了更好地解釋清楚一點,就拿出我自豪的畫畫天賦吧(手動狗頭,咳咳),上圖~,
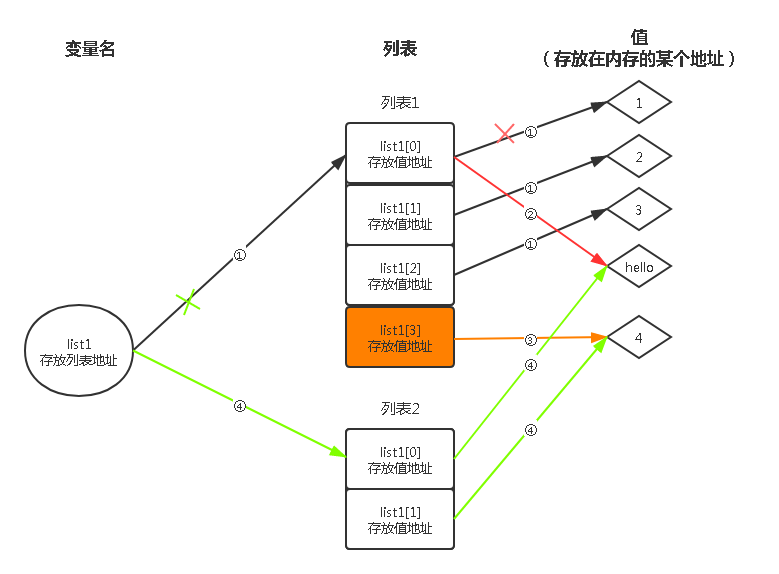
??先宣告一點,一個變數存有某一個物件的地址即等于該變數指向了這個物件,上面解釋了,list1變數存放的是某個資料型別的參考,換種說法就是存放某個物件的地址,這里就是存放一個串列的地址,即list1變數指向了串列,如圖所示,第一步,list1變數指向串列1,該串列存放著三個可變元素list1[0],list1[1],list1[2],它們分別存放著不同物件(值)的地址,第二步,串列的第一個元素list1[0]發生改變,變成存放hello這個字串物件的地址,第三步,串列新增了一個元素,該元素存放了新的整形物件4的地址,第四步,串列變數list1重新賦值,指向了新的串列2,串列2元素又指向了hello和4這兩個物件,
??因此,前面三步,因為都是改變了串列元素的指向,變數本身的指向沒有變化,即變數的地址也沒有變化,但第四步,變數進行重新的賦值,即指向了新的串列,那么變數的地址變發生了變化,
??這里也有重要的一點是,串列2和串列1指向的物件hello和4是一致的,因為它們的物件是一樣的,所以它們共用一個物件,從下面代碼可以體現,輸出的結果是一致的,
list1 = ['hello',2,3,4]
print(id(list1[0])) #輸出:112926064
print(id(list1[3])) #輸出:8791404644096
list2 = ['hello',4]
print(id(list2[0])) #輸出:112926064
print(id(list2[1])) #輸出:8791404644096
3、變數的賦值——淺拷貝和深拷貝
(1)變數賦值的安全隱患
??因為python的這種變數是一個物件的參考的機制,必然導致的結果是兩個變數賦值時會產生相互牽連的現象,舉個例子,list1賦值為[1,2,3],然后將其賦值給list2,改變list1時,我們可以發現list2也發生改變,代碼如下,
list1 = [1,2,3]
list2 = list1
print(list1) #輸出:[1,2,3]
print(list2) #輸出:[1,2,3]
print(id(list1)) #輸出:112607104
print(id(list2)) #輸出:112607104
list1[0] = 'hello'
print(list1) #輸出:['hello',2,3]
print(list2) #輸出:['hello',2,3]
print(id(list1)) #輸出:112607104
print(id(list2)) #輸出:112607104
??解釋圖如下,第一步,list1變數指向了串列1,經過賦值后,變數list2也指向了串列1,因此兩者地址相同,第二步,變數list1改變第一個串列元素的值,使其指向‘hello’,這時我們訪問list2內容時,因為list1和list2指向的串列一致,所以list2就變成改變后的值,
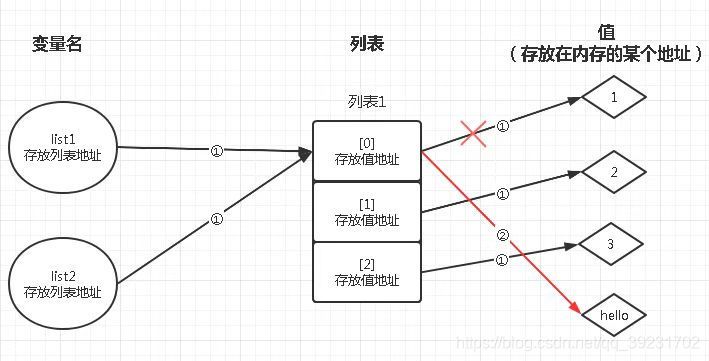
??由此引出主題深拷貝和淺拷貝,所謂深拷貝呢,就是一個變數的內容賦值給另一個變數時,是把全部資源重新復制一份再賦值給新的變數,而淺拷貝則不然,它的賦值只是將資源的地址給新的變數,二者同時共享該資源,顯然,上面的賦值運算例子就是一個淺拷貝,
(2)淺拷貝
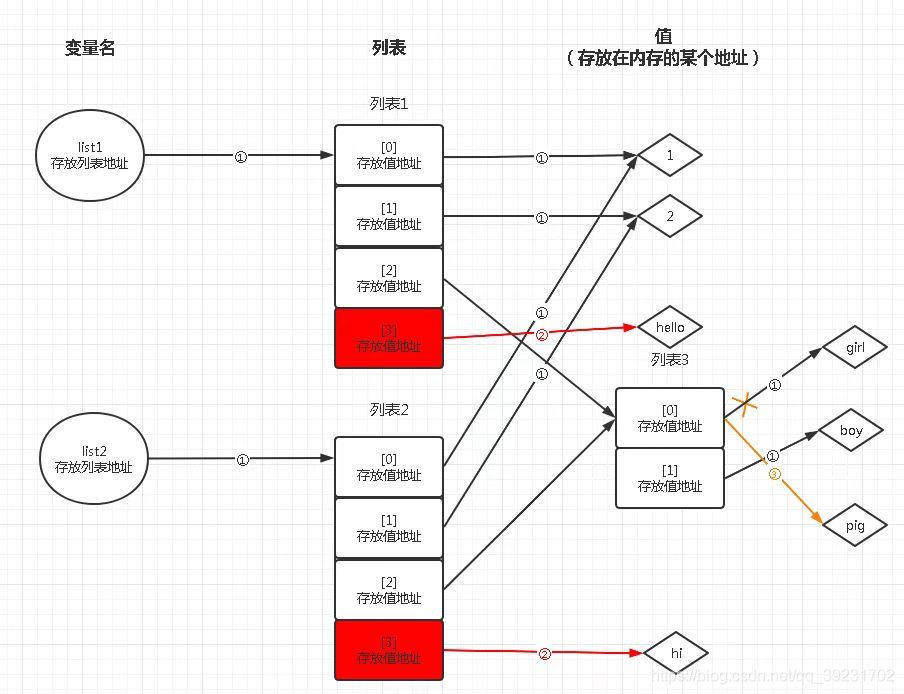
??為了更加深入了解二者,舉一個稍微復雜一丟丟的例子,這里我們需要用到外部包,copy包,它的方法copy()就是一個淺拷貝,而deepcopy()就是一個深拷貝,先舉例淺拷貝,這次采用嵌套串列并且使用copy方法來進行拷貝,對比輸出結果可以看到對串列list1和list2進行操作時,兩者沒影響,但對peope這個串列操作時,則兩個串列都有影響,
import copy
people = ['girl','boy']
list1 = [1,2,people]
list2 = copy.copy(list1)
print(list1) #輸出:[1,2,['girl','boy']]
print(list2) #輸出:[1,2,['girl','boy']]
list1.append('hello')
list2.append('hi')
print(list1) #輸出:[1,2,['girl','boy'],'hello']
print(list2) #輸出:[1,2,['girl','boy'],'hi']
people[0] = 'pig'
print(list1) #輸出:[1,2,['pig','boy'],'hello']
print(list2) #輸出:[1,2,['pig','boy'],'hi']
??由下圖可知,第一步,list1和list2分別指向串列1和串列2,其元素也指向對應的值,但個串列的第三個元素都指向了同個串列,第二步,list1產生新元素,指向‘hello’,list2產生新的元素,指向‘hi’,第三步,people這個串列的第一元素地址指向從‘girl’變成了‘pig’(狗頭保命),因為是共用串列,所以list1和list2這兩個變數都產生了變化,從中也可以分析得到,copy這個方法不像‘=’這種賦值運算,它拷貝了資源的第一層,但如果有該資源有第二層時,則變成共用資源,這也是比較容易被忽略的一點,
(3)深拷貝
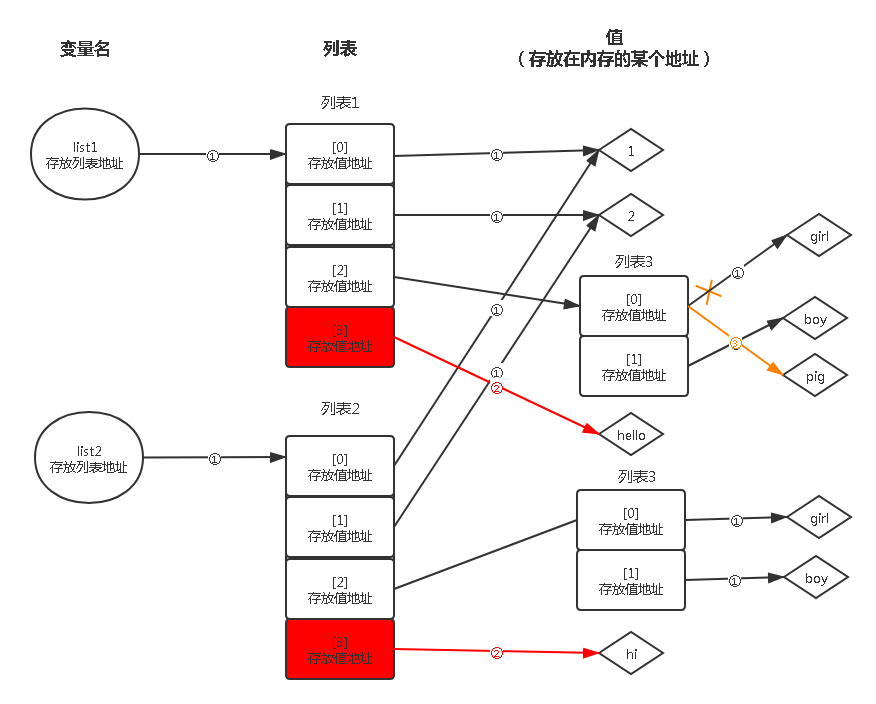
??為了解決淺拷貝帶來的安全隱患,有時我們需要采用深拷貝來拷貝我們的資源,即python的copy模塊提供的另一個deepcopy方法,深拷貝會完全復制原變數相關的所有資料,在記憶體中生成一堆一模一樣的資源,在這個程序中我們對這兩個變數中的一個進行任意修改都不會影響其他變數,我們來測驗一下,
import copy
people = ['girl','boy']
list1 = [1,2,people]
list2 = copy.deepcopy(list1)
print(list1) #輸出:[1,2,['girl','boy']]
print(list2) #輸出:[1,2,['girl','boy']]
list1.append('hello')
list2.append('hi')
print(list1) #輸出:[1,2,['girl','boy'],'hello']
print(list2) #輸出:[1,2,['girl','boy'],'hi']
people[0] = 'pig'
print(list1) #輸出:[1,2,['pig','boy'],'hello']
print(list2) #輸出:[1,2,['girl','boy'],'hi']
??流程如下圖所示,其步驟和淺拷貝的步驟一致,但不同的一點是,步驟三的people串列改變時,只有list1變數的people串列中‘girl’變成‘pig’,而list2變數沒什么影響,二者完全獨立,
三、python變數資料型別的大小
??本來探索到上面已經差不多要結束,鬼知道我腦子又冒出了個奇怪的想法,python的int型別到底要占有電腦的多少個位元組呢,畢竟習慣了c語言,而python對變數神奇的設計總是散發著它獨特的魅力,所以找啊找,找到一個可以顯示資料大小的API函式getsizeof(),只要匯入sys包即可,那么寫個例子:
import sys
print(sys.getsizeof(0)) # 輸出:24
print(sys.getsizeof(1)) # 輸出:28
print(sys.getsizeof(2)) # 輸出:28
print(sys.getsizeof(2**15)) # 輸出:28
print(sys.getsizeof(2**30)) # 輸出:32
print(sys.getsizeof(2**128)) # 輸出:44
??看到輸出結果,屬實讓人震驚,一個int型的數值,居然用高達24個位元組來存盤,而且在電腦存盤大小居然是不限定的,是自增長的,喝口水壓壓驚后,讓我想到c++的STL容器,可以使用堆疊頂指標,當檢測到容量超出時,則洗掉舊記憶體而去開辟一塊新的記憶體,確實可以實作這種效果,
??扯完犢子,那么這里首先先解決第一個問題,int型別這個變數什么時候記憶體會變大?我在這篇博客中提到的文章找到了答案: 點此處跳轉,重點就是下面這張圖,簡單來說就是int型別每多2^30(1073741824 )就會增加四個位元組,這也驗證了上面例子getsizeof(2**30)是32位元組,而比它小的是28個位元組的原因,當然零除外,其他型別也可以在下面找到答案,

??那么它的自增長問題呢,這個可能要去看python的原始碼才能解決,還好有大佬已經提前給我們鋪了下路,這里我就沒這個能力去了解太深入了,直接參考大佬的結論就可以了,具體可以參考這篇文章:點此處跳轉,在64位python的解釋器中,int型別的定義是通過一個結構體來定義的,簡化后的結構體如下所示:
struct PyLongObject {
long ob_refcnt; // 8 bytes
struct _typeobject *ob_type; // 8 bytes
long ob_size; // 8 bytes
unsigned int ob_digit[1]; // 4 bytes * abs(ob_size)
};
??ob_refcnt參考計數8個位元組,ob_type型別資訊8個位元組(指標),ob_size變長部分元素的個數8個位元組,ob_digit變長的資料部分,位元組數為4 * abs(ob_size),ob_size可以為0,所以ob_digit這部分可以占0位元組,那么最少int就為8 + 8 + 8 = 24個位元組,每次增量都是4(unsigned int)的倍數,
??對于32位的版本與64位又有所不同,定義如下,最少12個位元組,增量為2個位元組,
struct PyLongObject {
int ob_refcnt; // 4 bytes
struct _typeobject *ob_type; // 4 bytes
int ob_size; // 4 bytes
unsigned short ob_digit[1]; // 2 bytes * abs(ob_size)
};
??至于其他型別實際大小,也是一個類似的方案,這里也不探討太多東西了,學無止境吧~
總結
??這篇文章從變數的角度切入,首先談談什么是變數的型別,并且舉例了python中常用的基本資料型別,接著討論了變數在記憶體中的存盤,說白了就一句話,變數就是某一個物件的參考,物件在記憶體愛怎么放怎么放與變數無關,最后討論了int型別占有電腦的位元組數,
Tips:本人能力有限,如有錯誤之處麻煩指出,放棄不難,但堅持一定很酷!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254950.html
標籤:python
上一篇:ML之xgboost:解讀用法之xgboost庫的core.py檔案中的get_score(importance_type=self.importance_type)方法