現在是一個專業的時代,要早一點成為一個專家
空空蕩蕩而又滿滿當當<---------------------------------> 昏昏沉沉卻又明明白白

哈嘍,各位小伙伴大家好吶,這些天一直忙其它事情,回頭發現已經好幾天沒更新爬蟲專輯了,今天給大家整一首Python爬取微博評論,哈哈但是最后有點小丑(微博被封號了一段時間),下面大家一起來看操作!
一: 核心程序步驟
-
找api介面,獲取json文本資料
-
分析主評論與子評論url鏈接引數從而進行拼接
-
分別爬取主評論與子評論資料并匯入到execl表格中
二: Search評論介面
首先微博搜索一個博主,點擊進入博主發一條微博資訊界面!
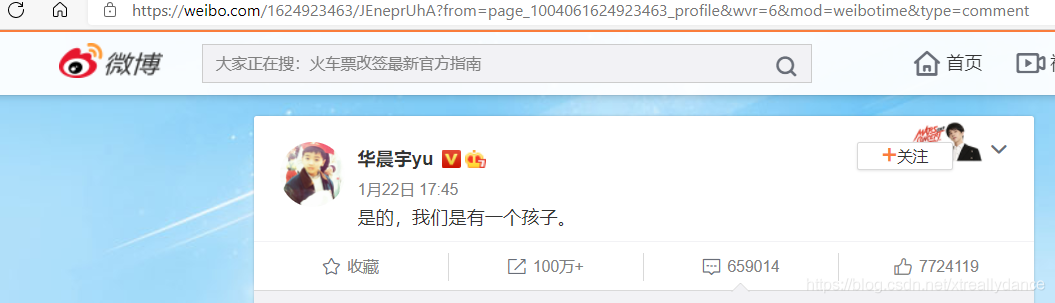
然后得從PC端觀看模式切換為手機端觀看模式,PC端引數過于復雜(小夜斗在PC端掙扎了三天結果最后拼接出來的url啥也沒有,但是手機端一天就就弄好了)!
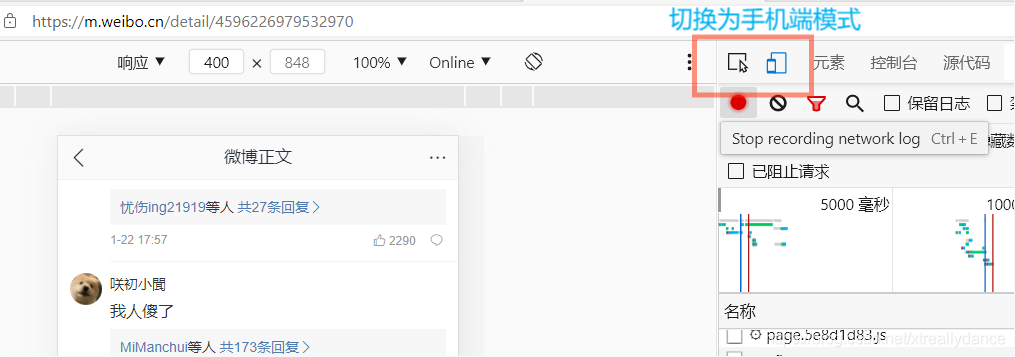
然后呢從一大堆檔案中找到存放評論資訊api介面(小夜斗這邊建議選擇xhr格式查找,一般都是ajax格式加載出的資訊)
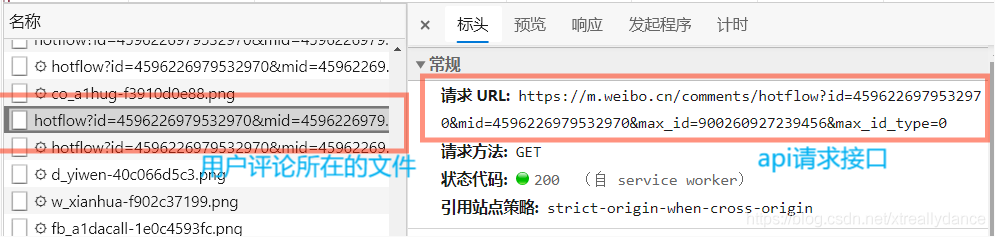
將這個url鏈接復制到網址鏈接上面,在將網址顯示出的內容復制粘貼到json.cn這個json格式加載網站,如圖所示:
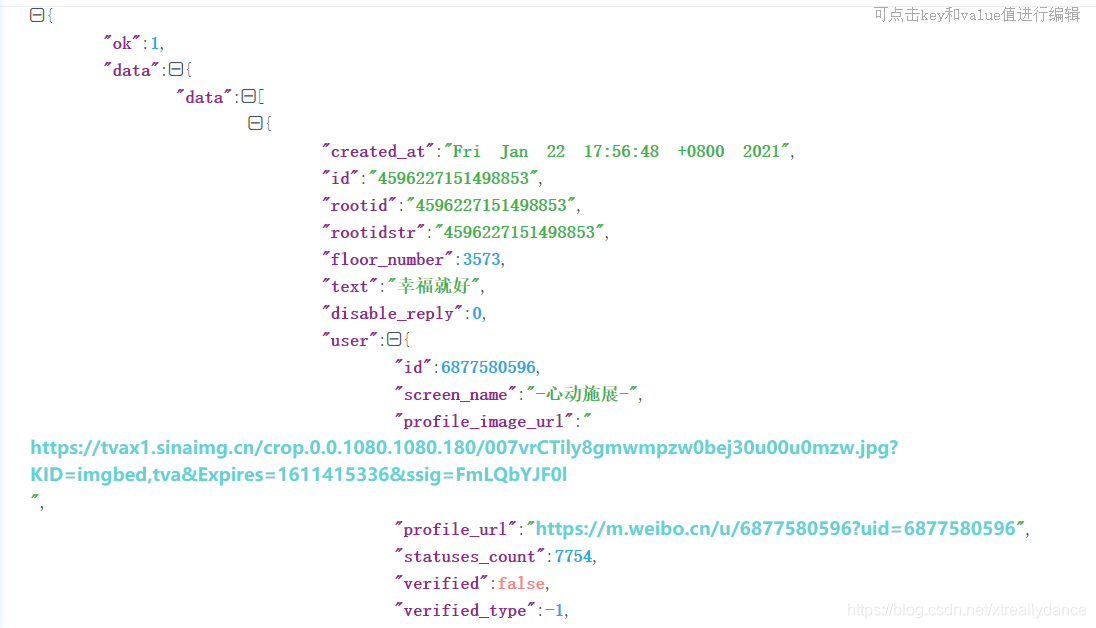
讓小夜斗先對這個json檔案資料進行爬取一下吧,小試牛刀先爬取一個url鏈接,需要爬取的資料如下所示:

核心資料抓取代碼,訪問介面,獲取json資料格式即可!
import requests
import json
from tqdm import tqdm
import datetime
import time
import random
import csv
?
# 一條主微博鏈接部分評論, 需要構造引數max_id獲取全部ajax
up_main_url = 'https://m.weibo.cn/comments/hotflow?id=4596226979532970&mid=4596226979532970&max_id_type=0'
headers = {
# ua代理
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
# 登錄資訊
'cookie': 'SINAGLOBAL=5702871423690.898.1595515471453; SCF=Ah2tNvhR8eWX01S-DmF8uwYWORUbgfA0U3GnciJplYvqE1sn2zJtPdkJ9ork9dAVV8G7m-9kbF-PwIHsf3jHsUw.; SUB=_2A25NDifYDeRhGeBK7lYS9ifFwjSIHXVu8UmQrDV8PUJbkNANLRmlkW1NR7rne18NXZNqVxsfD3DngazoVlT-Fvpf; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WhhI1TcfcjnxZJInnV-kd405NHD95QcSh-Xe0q41K.RWs4DqcjQi--ciK.RiKLsi--Ni-24i-iWi--Xi-z4iKyFi--fi-2XiKLhSKeEeBtt; wvr=6; _s_tentry=www.sogou.com; UOR=,,www.sogou.com; Apache=9073188868783.379.1611369496580; ULV=1611369496594:3:3:3:9073188868783.379.1611369496580:1611281802597; webim_unReadCount=%7B%22time%22%3A1611369649613%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A63%2C%22msgbox%22%3A0%7D'
}
response = requests.get(url=up_main_url, headers=headers)
if response.status_code == 200:
text = response.text.encode("gbk", "ignore").decode("gbk", "ignore") # 解決報錯雙重嚴格限制
content = json.loads(text) # 將文本轉為json格式
try:
data = content['data']['data'] # 獲取評論串列
for comment in tqdm(data, desc='花花評論爬取加載進度--->!'):
time.sleep(random.random())
text = str(comment['text']) # 獲取文本資訊
# 臥槽,我房子又塌了<span class="url-icon">
# 處理文本資訊,find函式找到<span開始的索引
if text.find('<span') != -1:
text = text[:text.find('<span')]
create_time = comment['created_at'] # 發布時間
# 格林威治時間格式字串 Wed Jul 10 20:00:09 +0800 2019 轉換為好理解的標準時間格式 2019-07-10 20:00:09
# Fri Jan 22 17:56:48 +0800 2021 轉換為標準時間格式 2021/1/22 17:56:48
std_transfer = '%a %b %d %H:%M:%S %z %Y' # 轉換的一個格式
std_create_time = datetime.datetime.strptime(create_time, std_transfer)
user_name = comment['user']["screen_name"] # 用戶姓名
user_id = comment['user']['id'] # 用戶id
user_followers_count = comment['user']['followers_count'] # 該用戶粉絲數
user_follow_count = comment['user']['follow_count'] # 該用戶關注數
user_gender = comment['user']['gender'] # 用戶性別
total_number = comment["total_number"] # 總回復數
like_count = comment["like_count"] # 點贊數
flag_id = comment["id"] # 二級評論url構造所需id
print('')
# print(f'內容: {text}')
# print(f'用戶名: {user_name}')
# print(f'評論時間: {std_create_time}')
# print(f'id:{user_id}')
# print(f'關注人數: {user_follow_count}')
# print(f'粉絲: {user_followers_count}')
# print(f'性別: {user_gender}')
# print(f'回復數量: {total_number}')
# print(f'點贊數: {like_count}')
# print(f'cid: {flag_id}')
#print('成功保存資訊!')
except:
print("啊這,今晚是上分局!被反爬了")
pass
上述代碼簡單的訪問api介面,獲取評論內容、評論用戶名、點贊數量、回復數、點贊時間等必要資訊,將其保存為csv檔案匯入execl表格中,表中部分資訊如圖所示:

上述代碼是一條微博下面部分主評論的資料爬取,還有一部分主評論是ajax加載出來的,需要引數構造url鏈接!主評論下面子評論回復資訊爬取與上述代碼類似,因篇幅問題就不過多展示,文末自取即可!
引數構造的url規律
爬取主評論api介面引數需要:max_id (可直接從第一個主評論api介面中的json資料中獲取得到)
爬取子評論api介面引數需要: cid(可直接從第一個主評論api介面中的json資料中獲取得到)、max_id(需要從子評論介面中json資料中獲取得到)
ps:兩個max_id引數來源不一樣:一個是從主評論api介面獲得,一個是從子評論api介面獲得
# 構造主評論url鏈接
# 獲取構造ajax主評論url全部max_id引數
def main_max_id():
# 以沒有內容報錯作為終止條件break跳出
while len(max_id_url_list) < 200:
print("正在休眠中")
time.sleep(random.randint(1, 3)) # 休眠
print("休眠完畢啦")
if (len(max_id_list) == 0):
main_url = 'https://m.weibo.cn/comments/hotflow?id=4596226979532970&mid=4596226979532970&max_id_type=0'
max_id_url_list.append(main_url)
else:
main_url = f'https://m.weibo.cn/comments/hotflow?id=4596226979532970&mid=4596226979532970&max_id={max_id_list[-1]}&max_id_type=0'
max_id_url_list.append(main_url)
try:
content = requests_json(main_url)
max_id = content['data']["max_id"] # 獲得主評論需要得引數max_id來構造url鏈接
max_id_list.append(max_id)
# TODO: 寫一個終止條件, 什么時候不在獲取max_id
data = content['data']['data'] # 獲取評論串列
for comment in data: # 回圈遍歷
cid = comment["id"] # 二級評論url構造所需id
cid_list.append(cid) # 添加
except:
print("最后一條max_id打底啦!該跳出走人咯!")
break
代碼運行如圖所示,采取雙執行緒方式進行爬取,成功獲取微博資料
以上就是本期分享地微博評論爬取啦,篇幅過長,想獲取全部原始碼的小伙伴們請持續關注小夜斗的微信公眾號:夜斗小神社
后臺回復"005微博資料"即可獲得全部原始碼!

請持續關注夜斗小神社,爬蟲路上不迷路!
《小夜斗滴爬蟲入門實戰案例》
- 在這個星球上,你很重要,請珍惜你的珍貴! ~~~夜斗小神社

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254951.html
標籤:python