Tensorflow+YOLO V4框架使用教程+YOLO V4獲取識別框高度+基于相似三角形演算法的物體距離測量
- Tensorflow+YOLO V4框架使用教程+YOLO V4獲取識別框高度+基于相似三角形演算法的物體距離測量
- Tensorflow+YOLO V4框架使用教程
- YOLO V4獲取識別框高度
- 基于相似三角形演算法的物體距離測量
Tensorflow+YOLO V4框架使用教程+YOLO V4獲取識別框高度+基于相似三角形演算法的物體距離測量
先來講講我寫該博客的原因吧!!
由于近期我在從事相關演算法專案上的內容以及本人所在團隊的中有一些學弟學妹反饋初次接觸Tensorflow以及YOLO V4,再加之結合自己近期的開發專案結果,最后寫了這一篇博客,
下面首先讓我來介紹一下Tensorflow+YOLO V4框架的使用教程吧!!(這已經是本人接觸演算法下來半年以前的東西了,同樣的方法對YOLO V3也適用)
首先要提一句:本人的Tensorflow的version(版本)是:
tensorflow_version=1.14.0
其中的一些主要的庫的版本如下:
numpy_version=1.17.2
keras_version=2.1.5
pandas_version=1.1.4
對于安裝這些庫我們可以運用清華源的安裝,安裝代碼如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 相應的庫的名稱
因為原始的pip install 相應的庫的名稱速度較慢,在這里建議使用上方的清華源的安裝,
接下來,開始進入我們的正題!!
Tensorflow+YOLO V4框架使用教程
在這里如何安裝anaconda和tensorlow在這里就不詳細介紹了,大家可以借鑒這篇博客,來完成相應的配置和安裝:https://blog.csdn.net/medusa_zj/article/details/102935687?utm_source=app
大家將以上網址輸入瀏覽器的網址欄即可,
以上是anaconda和tensorflow的相關的安裝
安裝完后,將該環境配置到VS Code上(本人用的IDE是VS Code),配置的相應的操作大家可以參考:
https://blog.csdn.net/shichimiyasatone/article/details/93600361?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522161227025116780262525522%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fall.%252522%25257D&request_id=161227025116780262525522&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-2-93600361.first_rank_v2_pc_rank_v29_10&utm_term=vs+code+tensorflow%25E7%258E%25AF%25E5%25A2%2583%25E9%2585%258D%25E7%25BD%25AE
https://blog.csdn.net/qq_41662115/article/details/86420983?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522161227025116780262577286%252522%25252C%252522scm%252522%25253A%25252220140713.130102334..%252522%25257D&request_id=161227025116780262577286&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-1-86420983.first_rank_v2_pc_rank_v29_10&utm_term=vs+code+tensorflow%25E7%258E%25AF%25E5%25A2%2583%25E9%2585%258D%25E7%25BD%25AE
以上兩篇博客,
同時我們也需要下載相關YOLO V4的框架,下載地址為:
https://github.com/bubbliiiing/yolov4-keras
大家可以在這里下載,但是使用github下載的話可能會花較多的時間,大家可以使用淘寶找客服下載,這樣較快,
下載完后,記得解壓縮!!!
在這之后,我們使用VS Code打開剛下載檔案
點擊打開檔案,選擇剛才下載的檔案并打開,
打開后,我們會看到相應的目錄:
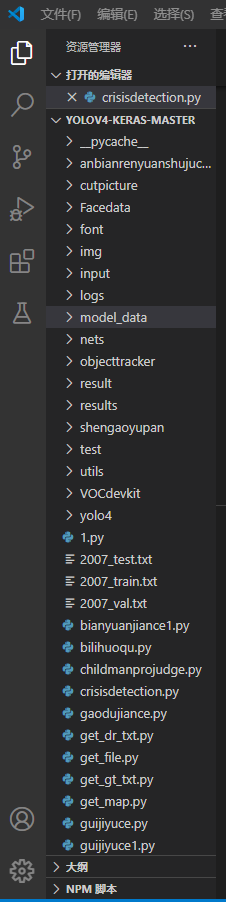
點擊左下方的按鈕(已經用紅框標出)可以切換python版本,如圖所示:
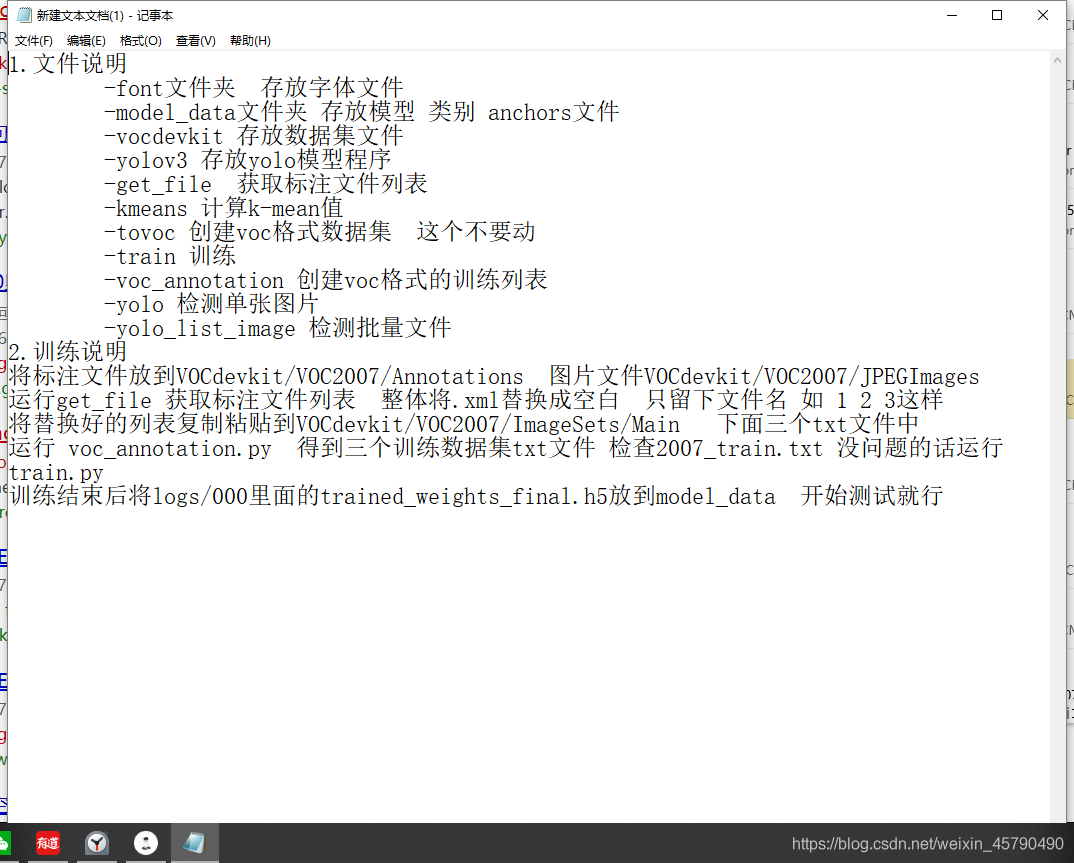
開始介紹YOLO V4框架的使用流程(在這里我們可以借鑒YOLO V3框架的使用流程)如圖所示:
在此之前,我們需要用爬蟲去往上爬一些用于訓練的圖片,爬蟲代碼在這里就不公示了,因為涉及到專案的封閉性,大家可以自行去網上查找一些爬取圖片的代碼!
爬取到相關的圖片之后,需要對圖片打標簽,本人使用的軟體是LabelImage:
這是比較好的打標軟體,本人強力推薦!
在此之后,我們將打標完后的標簽檔案全部轉移到在yolov4-keras-master\VOCdevkit\VOC2007\Annotations目錄下,按照上面的程序知道訓練結束,在這里需要注意的是將我們所要分類的類名add到model_data檔案夾下的coco_class.txt和voc_class.txt檔案夾下,
大家就能夠完成相應的訓練程序,之后是測驗程序,在測驗程序中我們主要運用的檔案是yolo.py,
yolo.py中的代碼現在公式如下:
import os
import numpy as np
import copy
import colorsys
from timeit import default_timer as timer
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from nets.yolo4 import yolo_body,yolo_eval
from utils.utils import letterbox_image
import matplotlib.pyplot as plt
#--------------------------------------------#
# 使用自己訓練好的模型預測需要修改2個引數
# model_path和classes_path都需要修改!
#--------------------------------------------#
class YOLO(object):
_defaults = {
"model_path": 'model_data/trained_weights_stage_1.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/coco_classes.txt',
"score" : 0.2,
"iou" : 0.3,
# 顯存比較小可以使用416x416
# 顯存比較大可以使用608x608
"model_image_size" : (416, 416)
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
#---------------------------------------------------#
# 初始化yolo
#---------------------------------------------------#
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
#---------------------------------------------------#
# 獲得所有的分類
#---------------------------------------------------#
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
#---------------------------------------------------#
# 獲得所有的先驗框
#---------------------------------------------------#
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
#---------------------------------------------------#
# 獲得所有的分類
#---------------------------------------------------#
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# 計算anchor數量
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
# 載入模型,如果原來的模型里已經包括了模型結構則直接載入,
# 否則先構建模型再載入
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path)
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# 畫框設定不同的顏色
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
# 打亂顏色
np.random.seed(10101)
np.random.shuffle(self.colors)
np.random.seed(None)
self.input_image_shape = K.placeholder(shape=(2, ))
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
num_classes, self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
#---------------------------------------------------#
# 檢測圖片
#---------------------------------------------------#
def detect_image(self, image):
start = timer()
# 調整圖片使其符合輸入要求
new_image_size = self.model_image_size
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
# 預測結果
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
# 設定字體
font = ImageFont.truetype(font='font/simhei.ttf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
small_pic=[]
for i, c in list(enumerate(out_classes)):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
top, left, bottom, right = box
top = top - 5
left = left - 5
bottom = bottom + 5
right = right + 5
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
# 畫框框
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
print(label)
middle_x=(left+right)/2
middle_y=(bottom+top)/2
#取識別框中人像的中心點位置
print(middle_x)
print(middle_y)
print("-----------------------------")
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
end = timer()
print("程式運行時間為:")
print(end - start)
return image
def close_session(self):
self.sess.close()
def detect_video(yolo, video_path, output_path=""):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError("Couldn't open webcam or video")
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC))
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != "" else False
if isOutput:
print("!!! TYPE:", type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = "FPS: ??"
prev_time = timer()
while True:
return_value, frame = vid.read()
image = Image.fromarray(frame)
image = yolo.detect_image(image)
result = np.asarray(image)
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
if accum_time > 1:
accum_time = accum_time - 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_NORMAL)
cv2.imshow("result", result)
if isOutput:
out.write(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session()
if __name__ == '__main__':
#for l in range(600,607):
image = Image.open("D:/yolov4-keras-master/yolov4-keras-master/VOCdevkit/VOC2007/JPEGImages/4.jpg") #讀取圖片
#"+str(l)+"
#image = detect_video(YOLO(),r'D:/yolov4-keras-master/yolov4-keras-master/VOCdevkit/VOC2007/video/1.mp4')
image = image.convert('RGB') # 將灰度圖轉化為三通道影像 以便顯示彩色的邊框
image=YOLO.detect_image(YOLO(),image) #進行檢測
image.show()
#image.save('D:/yolov4-keras-master/yolov4-keras-master/VOCdevkit/VOC2007/ends/'+str(l)+'.jpg')
里面具體的一些代碼就不詳細介紹了,我們來將一種情況,就是拿到訓練的模型后,我們將呼叫模型來完成初步的物體識別作業,但由于基本引數的一些配置,容易是的識別框顯示較多或者直接不顯示識別框,大家其實都會認為是模型訓練的不夠好,其實這個答案并不一定準確,下識別框的顯示其實和下面的兩個引數有很大關系,大家可以直接通過修改一下兩個引數就能夠解決上述問題:(引數如下)
"model_path": 'model_data/trained_weights_stage_1.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/coco_classes.txt',
"score" : 0.2,
"iou" : 0.3,
在這里是要修改score和iou即可,如果遇到沒有識別框的情況,我們可以適當減小他們的值;如果遇到識別框較多的情況我們可以增大相應的值,
到這里,我們就完成了對Tensorflow+YOLO V4框架使用,
YOLO V4獲取識別框高度
在這里獲取識別框的高度較為簡單,
因為在YOLO V4完成相應識別框的繪制時,就已經提供了相應的引數top、bottom、letf和right,我們只需將bottom減去top再將其顯示在識別框上或者直接print()輸出即可完成任務,顯示在識別框上的代碼如下,在這里提供一下類似代碼,大家可以進行修改:
draw.text((int(middle_x),int(top)),"離岸距離為"+str(abs(int(x_dist)))+"cm", (255, 0, 0), font=font)
那么獲取識別框的高度的任務就完成了!!
接下來就是我們利用相似三角形來獲取距離,
(由于保證專案的封閉性,本人在這里不提供相應完整的代碼)
基于相似三角形演算法的物體距離測量
好!開始進入正題!!!!!!由于牽扯到相機(攝像頭),首先需要設定相應的相機內參:
#影像解析度
frame_width = 1280
frame_height = 720
#相機內參
camera_cx = 628.060
camera_cy = 345.411
camera_fx = 716.168
camera_fy = 715.988
#標定點像素、相機高度、標定點實際距離
cab_pixel_y = 650
camera_h = 0.735*100
cab_dist = 1.61*100
#求主點對應的實際距離,與相機的角度
a1 = math.atan(camera_h / cab_dist)
a2 = math.atan((cab_pixel_y - camera_cy) / camera_fy)
a3 = a1 - a2
op_dist = camera_h * math.atan(a3)
#以上為相機(攝像頭)的初始設定,據具體情況而定可修改
然后,開始計算相應的距離:
#運用相似三角形
#由于y上的數值在后續的x上計算上有用到所以先將求y上的距離放在前面
#求任意像素點的y方向實際距離
b1 = math.atan((middle_y - camera_cy) / camera_fy) #呼叫人像y軸方向上的中點
b2 = a3 + b1
y_dist = camera_h / math.tan(b2)
print(y_dist)
#求該像素點的x方向實際距離
pixel_y_dist = math.sqrt(pow((middle_y - camera_cy), 2) + pow(camera_fy, 2))
dist_y_slope = camera_h / math.sin(b2)
x_dist = dist_y_slope * (middle_x - camera_cx) / pixel_y_dist
print(x_dist)
具體介紹大家可以看相應的注釋,這是較為簡單的相似三角形測距的實戰,
爭對相似三角形測距的原理大家可以參考:https://blog.csdn.net/weixin_43159148/article/details/83507950?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522161227451516780271525620%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fall.%252522%25257D&request_id=161227451516780271525620&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-2-83507950.first_rank_v2_pc_rank_v29_10&utm_term=%25E5%258D%2595%25E7%259B%25AE%25E7%259B%25B8%25E4%25BC%25BC%25E4%25B8%2589%25E8%25A7%2592%25E5%25BD%25A2%25E6%25B5%258B%25E8%25B7%259D%25E5%258E%259F%25E7%2590%2586
今天就給我大家講解到這里,因為本人學弟學妹的需要所以較為注重講述前面第一大部分的知識,也希望大家能夠學習,多多支持,我會一直在進步的路上,

THANK YOU!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/255906.html
標籤:python