寒假在家,實在無事可做,就找到了崔慶才爬蟲52講的課程,鞏固一下爬蟲知識,最近也是學到了異步爬蟲,本來想按照視頻教的案例實踐一下就可以了,沒想到案例網站證書過期了,沒辦法進行實踐,只能去找別的網站實踐了,
一開始學習爬蟲就是看到別人爬取美女圖片(主要是因為圖片網站沒有什么反爬,絕對不是沖著圖片去的),就是剛開始都是一張一張下載的,速度及其的慢,既然學了異步爬蟲就想著能不能異步爬取圖片加速圖片的爬取,
說干就干,直接百度搜索電腦壁紙,隨機選取“幸運兒”,
有請我們的幸運兒:彼岸圖網
分析
我們直接進入4K動漫壁紙頁面,分析初始頁面的url,可以看到頁面的url
翻頁觀察一下

多翻幾個頁面,很明顯的可以總結出頁面url的變化規律:http://pic.netbian.com/4kdongman/index_{page}.html
可以看到初始url還是很簡單的,
接下來我們分析一下拿到圖片的鏈接
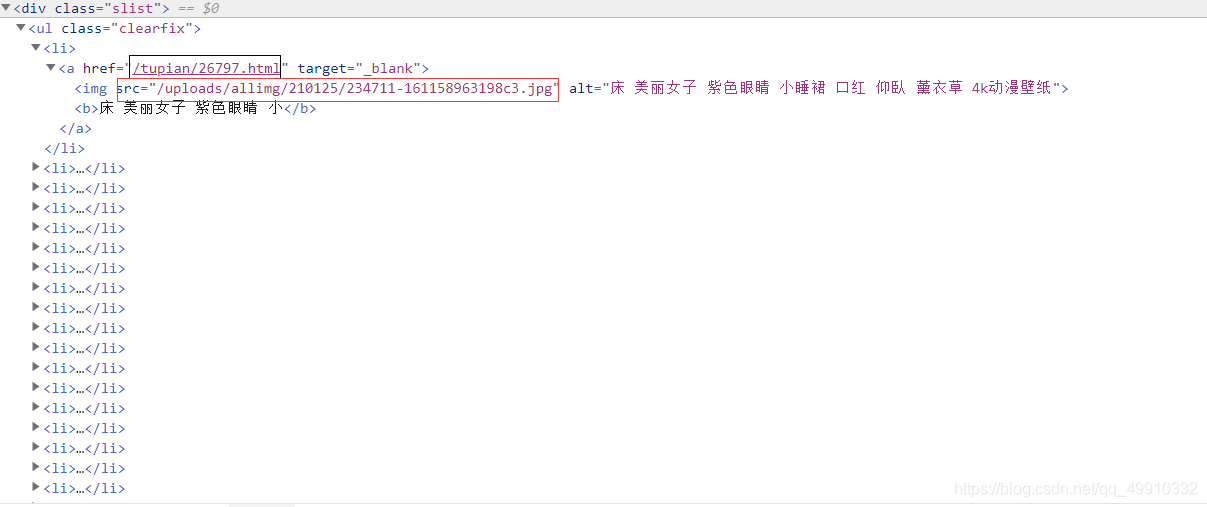
這里我先選擇了直接打開scr里面圖片鏈接,發現圖片非常的模糊,而且非常的小,這肯定是不適合做我們的電腦壁紙,
繼續往下分析,隨便打開一個圖片鏈接

發現剛好是初始地址加上面我們分析獲得的href屬性組成的,
即http://pic.netbian.com{id}.html
再分析一下源代碼
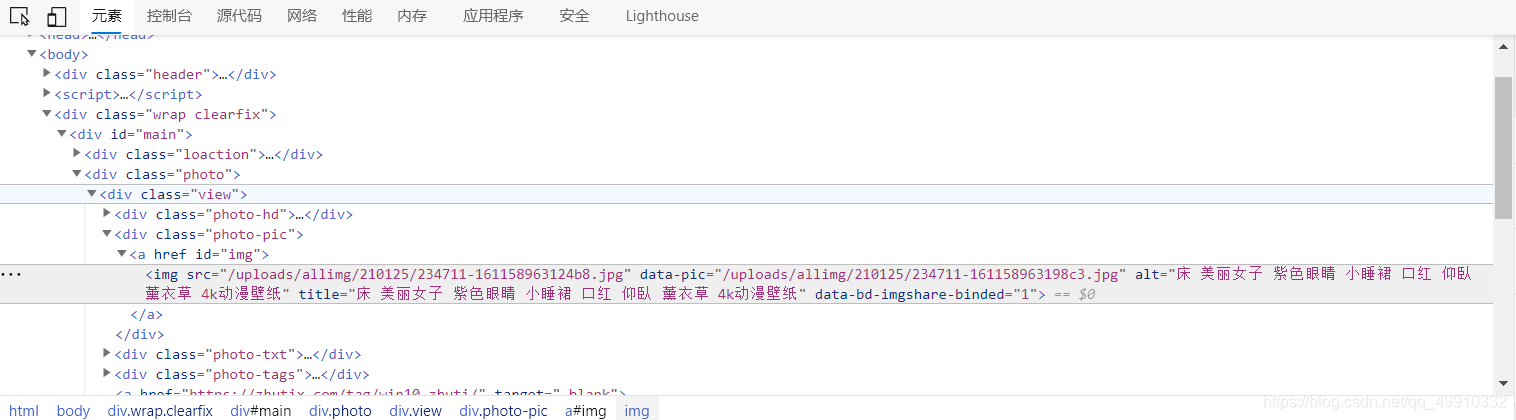
再次定位到src屬性,拼接上網站的初始url,瀏覽器打開圖片,果然是我們想要的圖片地址,
接下來用代碼實作就很簡單了,我們首先請求初始頁面,提取出詳情頁面的url,再請求詳情頁面,決議詳情頁面拿到圖片的鏈接和地址就可以了,(我這里用的是re暴力匹配的,也可以用bs4,lxml等方法)
代碼實作
import asyncio
import re
import aiohttp
import logging
import os
# 定義日志檔案
logging.basicConfig(level=logging.INFO,format="%(asctime)s-%(levelname)s:%(message)s")
# 定義初始頁的url
INDEX_URL = "http://pic.netbian.com/4kdongman/index_{page}.html"
# 定義詳情頁的url
DETAIL_URL = "http://pic.netbian.com{id}.html"
# 定義壁紙的初始url
IMG_URL = 'http://pic.netbian.com{img_url}'
# 定義將要爬取的頁數
PAGE_NUMBER = 147
# 定義爬取的信號量
CONCURRENCY = 5
# 構造存盤壁紙的路徑
PATH = "D:\img"
if not os.path.exists(PATH):
os.mkdir(PATH)
# 初始化信號量
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
# 此函式的功能是定義一個基本的抓取方法,傳入url即可回傳網頁的源代碼
async def scrape_api(url):
async with semaphore:
try:
logging.info('scraping %s',url)
async with session.get(url) as response:
return await response.text()
except aiohttp.ClientError:
logging.error('error occurred while scraping %s',url,exc_info=True)
# 此函式的功能是構造初始頁的url
async def scrape_index(page):
url = INDEX_URL.format(page=page)
return await scrape_api(url)
# 此函式的功能是定義詳情頁的url,并決議詳情頁,拿到img的url和名字
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
IMG = re.search('<img src="(.*?)" data-pic',data,re.S).group(1)
img_url = IMG_URL.format(img_url=IMG)
name = re.findall('<img.*?title="(.*?)"',data,re.S)[0]
return await scrape_save_img(img_url,name)
# 此函式的功能是訪問圖片的鏈接,并回傳二進制資料
async def scrape_save_img(url,name):
async with semaphore:
try:
logging.info('scraping %s',url)
async with session.get(url) as response:
img = await response.read()
return await save_data(img,name)
except aiohttp.ClientError:
logging.error('error occurred while scraping %s',url,exc_info=True)
# 此函式的功能是存盤圖片
async def save_data(img,name):
with open(f'D:\img\\{name}.jpg',"wb") as f:
print('正在存盤圖片')
f.write(img)
f.close()
print('圖片存盤成功')
# 主函式
async def main():
global session
# 初始化session
session = aiohttp.ClientSession()
# 定義爬取串列頁的所有task
scrape_index_tasks = [asyncio.ensure_future(scrape_index(page))for page in range(2,PAGE_NUMBER+1)]
# 呼叫asyncio.gather方法傳入task串列,將結果賦值給result,這個result就是所有task回傳結果的串列
result = await asyncio.gather(*scrape_index_tasks)
logging.info('result %s',result)
# 遍歷result
for index_data in result:
# 判斷index_data是否為空,防止出現空白index_data導致程式意外終止
if not index_data:continue
ids = re.findall('<li><a href="(.*?).html" target="_blank"><img',index_data,re.S)[1:20]
# 宣告爬取所有詳情頁task組成的串列
scrape_index_tasks = [asyncio.ensure_future(scrape_detail(id))for id in ids]
# 呼叫asyncio.wait方法呼叫執行,也可以用gather方法,效果一樣,回傳結果有差異
await asyncio.wait(scrape_index_tasks)
# 關閉session
await session.close()
# 程式開始運行
if __name__ == '__main__':
# 呼叫異步協程
asyncio.get_event_loop().run_until_complete(main())
代碼主要是仿照著教學視頻上面的風格寫的(感覺視頻上面的代碼邏輯十分清晰,就仿照這這種風格寫了),注釋什么的也寫的很清楚,不懂的可以自己看哈,
之后我又打開了幾個網站元氣壁紙,觀察了一下感覺這些圖片網站的結構都是一樣的,標簽頁,加詳情頁的格式,
標簽頁:
規則:https://bizhi.ijinshan.com/2/index_{page}.shtml
詳情頁:
規則:https://bizhi.ijinshan.com/2/{id}.shtml
其中的邏輯基本都是一樣的:請求初始頁面,提取出詳情頁面的url,再請求詳情頁面,決議詳情頁面拿到圖片的鏈接和地址,
又看了一樣代碼,好像改兩三個地方就直接可以爬了,臥槽…
說干就干,一頓分析之后,改了三個地方,直接就可以爬取別的網站了,
# 定義初始頁的url
INDEX_URL = "https://bizhi.ijinshan.com/2/index_{page}.shtml"
# 定義詳情頁的url
DETAIL_URL = "https://bizhi.ijinshan.com/2/{id}.shtml"
# 定義壁紙的初始url
IMG_URL = 'https://wallpaperm.cmcm.com/{img_url}'
# 定義將要爬取的頁數
PAGE_NUMBER = 100
# 此函式的功能是定義詳情頁的url,并決議詳情頁,拿到img的url和名字
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
IMG = re.search('<img src="https://wallpaperm.cmcm.com/(.*?)" alt="(.*?)">',data).group(1)
img_url = IMG_URL.format(img_url=IMG)
name = re.search('<img src="https://wallpaperm.cmcm.com/(.*?)" alt="(.*?)">',data).group(2)
return await scrape_save_img(img_url,name)
ids = re.findall('data-image-id="(.*?)"',index_data,re.S)
之后再次運行,成了!
哇!崔神的代碼格式就是不一樣,這明明就是一個代碼模板啊!
感興趣的小伙伴可以試一下別的網站,
附上
運行程序
爬取的結果
總共爬取了近萬張的4K圖片,用了不到一個20分鐘,
PS:新人第一次發博客,不足的地方多多包涵,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/255907.html
標籤:python
上一篇:Tensorflow+YOLO V4框架使用教程+YOLO V4獲取識別框高度+基于相似三角形演算法的物體距離測量