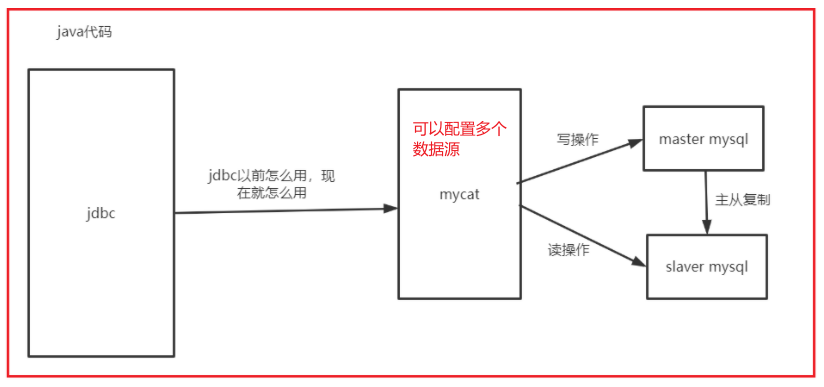
前面已經配置了mysql的主從復制,其實很容易,主節點寫入了資料,從節點進行同步,所以寫操作使用主節點,讀操作使用從節點,這樣就有效降低了資料庫的壓力
但是我們用java程式不可能去連接多個資料源,執行sql的時候還要判斷是使用主節點還是從節點,所以使用mycat,一端對java提供一個統一的介面,另外一端可以連接多個資料源,最好是我們可以跟以前一樣連接資料庫一樣,讓使用者感覺不到mycat的存在;
mycat就是實作了這些功能,把連接多個資料庫的操作交給了mycat,在mycat中配置哪個節點是讀,哪個是寫,在執行sql的時候就會自動的去連接該節點;
還有一點,mycat是國人使用java開發并開源了的,啟動mycat需要jdk環境
1.mycat安裝
本來是想用linux版的mycat的,由于云服務器只有一臺,在服務器上沒法鏈接上本地的mysql,就是用了windows版的mycat,用法和組態檔和linux版的都是一樣的;
mycat官網
mycat的github
自行下載對應的版本,這里下載的是1.6.7.4版本,解壓之后的目錄:
2. mycat的配置
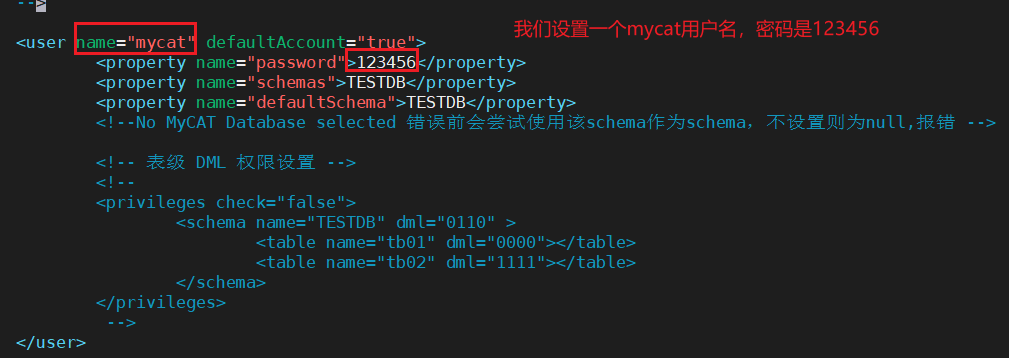
首先我們修改一下mycat的用戶名和密碼,在安裝目錄/conf/server.xml中
然后需要配置一下schema.xml:
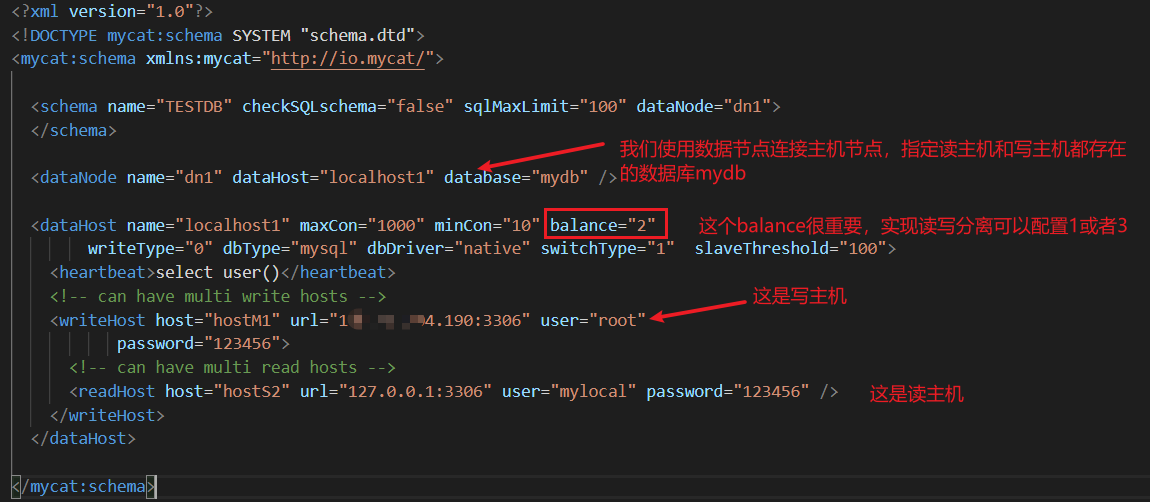
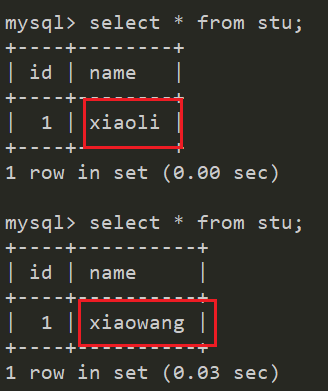
我這里測驗用的是balance="2",將主節點和從節點中mydb資料庫stu表中相同id的資料改成不一樣的,然后去連接mycat查詢該表資料,每次查詢都不一樣
想測驗讀寫分離,這里設定為1或者3
balance="0": 不開啟讀寫分離,讀操作和寫操作都是用的writeHost;
balance="1": 開啟讀寫分離,這種情況是存在多主多從的時候,一個主節點提供寫操作,其他的主節點和所有從節點提供負載均衡的讀操作
balance="2": 讀操作隨機讀選擇主節點和從節點
balance="3": 開啟讀寫分離,寫操作使用寫主機(主節點也就是寫主機,從節點是讀主機),讀操作使用讀主機
3. mycat啟動
進入mycat安裝目錄下的bin目錄,兩種方式:
(1)前臺啟動,可以看到啟動情況:./mycat.bat console
(2)后臺啟動: ./mycat.bat start

連接mycat,就跟連接mysql一樣,打開cmd,mysql -umycat -p123456 -h 127.0.0.1 -P 8066 //注意埠是8066埠
使用mycat向stu表插入一條資料,然后將主節點和從節點資料資料改成不一樣的,你再去讀幾次,可以看到是隨機的,說明我們mycat配置的沒問題;
還是說一句,想測驗讀寫分離的,記得把schema.xml中設定為balance="1"或者balance="3"
4 資料分片
資料分片也就是俗話說的分庫分表
4.1 分庫
當一個資料庫中的資料太多了,效率也就低了,我們需要將后續插入A主機中mydb資料庫中表tab1的資料,都插入到B主機中mydb資料庫tab1表中,除此之外,還需要將A主機中的tab1中的資料遷移到B主機中
至于資料遷移工具,可以看看這個老哥博客,寫得挺不錯的
schema.xml檔案
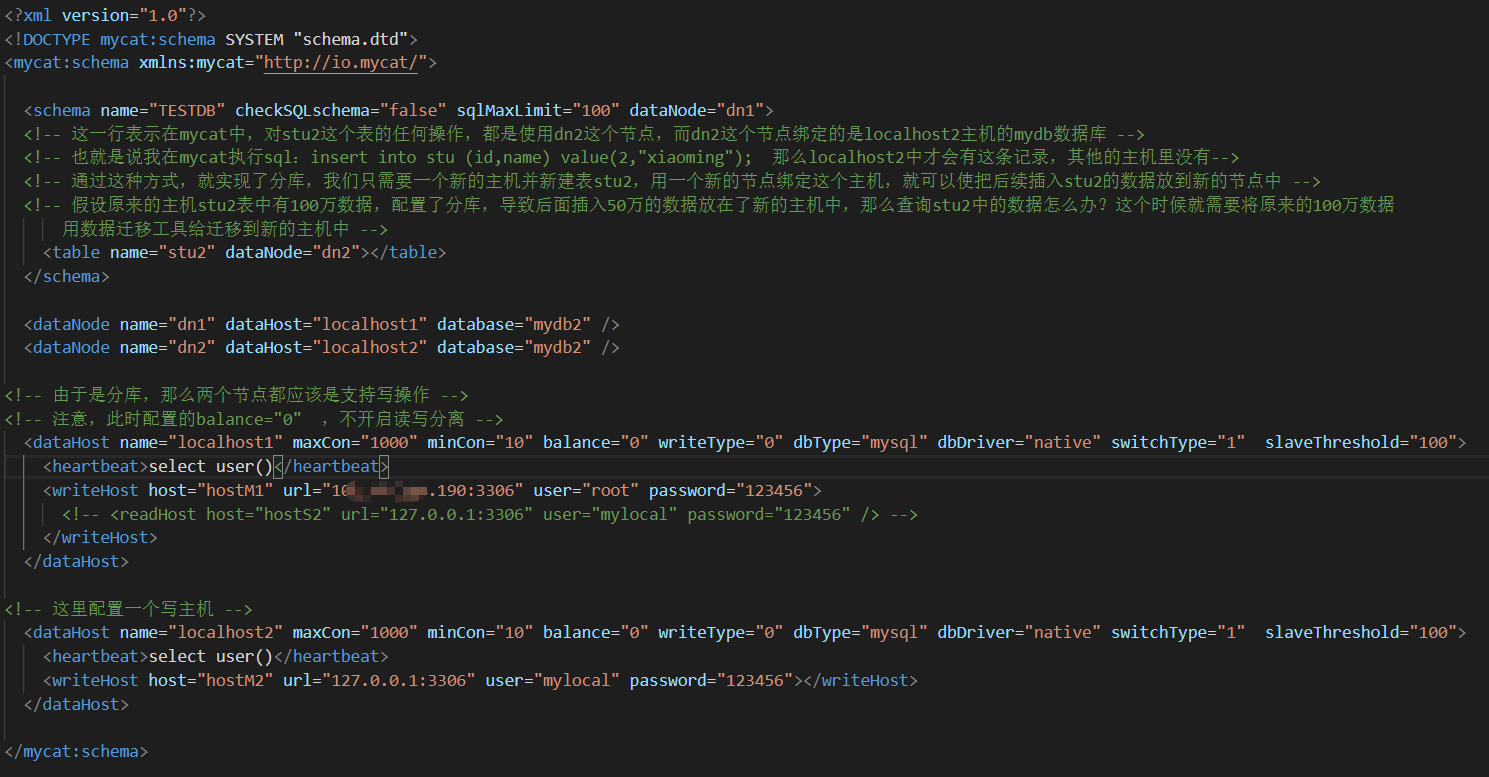
然后測驗在mycat中只要是對stu2表的任何操作,都是使用的是第二個主機,從而實作了分庫
4.2 分表
分庫:X主機中A資料庫中有表tab1,tab2,tab3,由于每個表資料都很多,根據分析可以將tab1拿出來,放到Y主機中A資料庫下,使得以后所有對tab1的所有操作都是來訪問Y主機
分表:X主機A資料庫中有表tab4,但是這個tab4中資料有一千萬條,我們將這個表用一定的方法,分成兩份,分別放到當前主機中和Y主機中A資料庫表tab4
不管分庫還是分表,都要配合資料遷移工具才能實作的!
首先配置schema.xml檔案
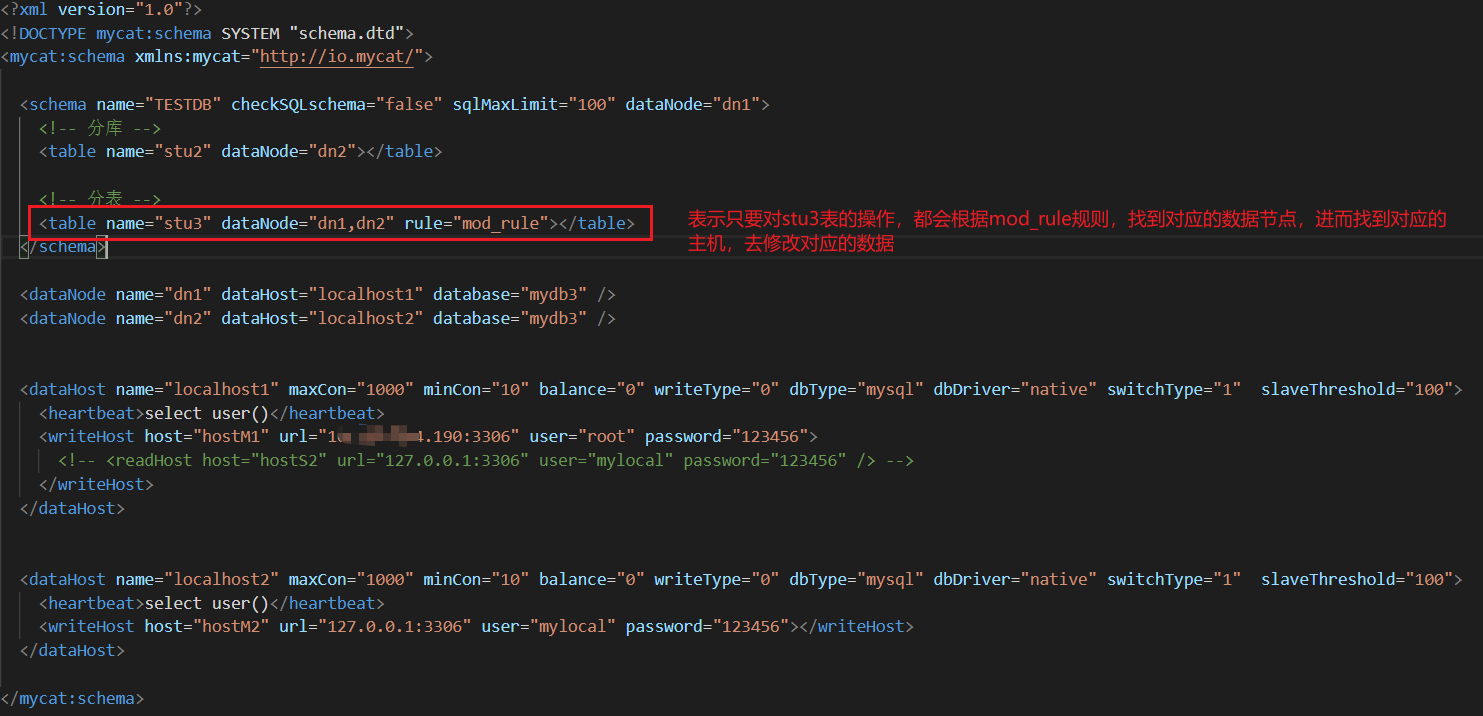
然后配置rule.xml,這種規則其實很好立理解,就是取余,在mycat中向stu3中插入資料,會根據id對2進行取余,得到的結果肯定是0或者1,當等于0時就放在一臺主機中,等于1就放在另外一個主機中,這個跟redis集群放入資料一樣;

4.3 測驗
我們在mycat中執行以下6條sql:
insert into stu3 (id,name) values(1,"jack01"); insert into stu3 (id,name) values(2,"jack02"); insert into stu3 (id,name) values(3,"jack03"); insert into stu3 (id,name) values(4,"jack04"); insert into stu3 (id,name) values(5,"jack05"); insert into stu3 (id,name) values(6,"jack06");
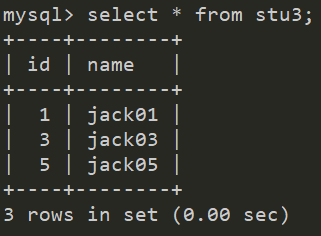
然后我們就可以分別在兩臺主機中各看到三條資料:
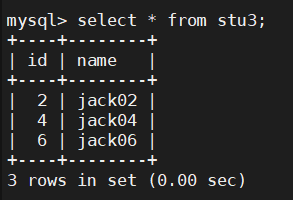
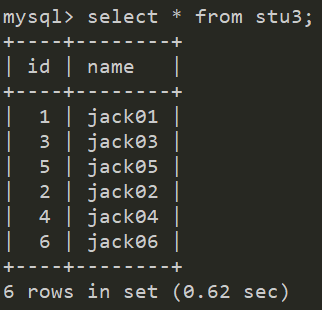
然后我們在mycat中查詢所有的資料,可以看到id沒有經過排序,只是將主機A中的stu3的資料+主機B中stu3中的資料,所以使用mycat查詢分表之后的資料,就是將所有該表所在的主機中資料都查出來,然后再進行拼接;
4.4 關聯表分表
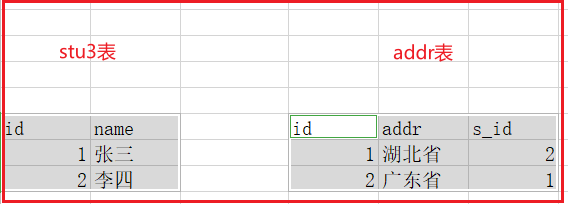
舉個例子:現在我們是對stu3表進行分表,但是現在有個addr表記錄這每個用戶的具體住址,stu3和addr是一對一,兩個表通過s_id關聯
在查詢addr表的時候肯定會根據s_id查詢用戶姓名,那么分表肯定需要相同的規則進行分,比如將stu3表中id=1的資料分到A主機中,那么addr表中id=2的資料也就要分到A主機中,不然跨主機做連表查詢就太麻煩了
我們需要在schema.xml中進行配置,這樣配置了之后每次向addr表中插入資料的時候,會根據s_id找到對應的stu3表中記錄是在哪個主機上,就把addr資料也放在那個主機上
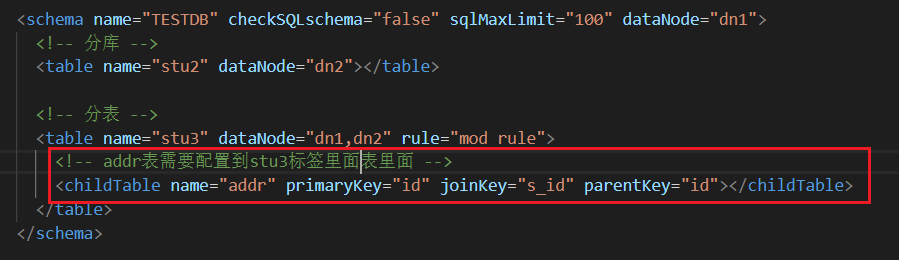
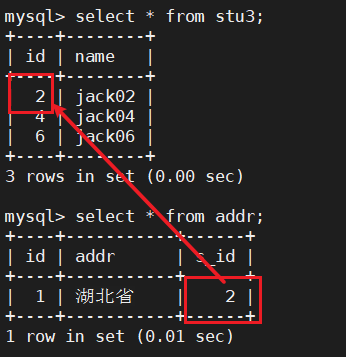
測驗了一下,是可以的,這樣的話可以保證有關聯的表即使分表也會相應的分到同一個主機中,去連表查詢的時候效率會高點
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/256608.html
標籤:Java
上一篇:mysql進階學習二之搭建主從