三、Python基礎(高級變數型別篇)
目錄:
- 三、Python基礎(高級變數型別篇)
- 一、串列 list
- 1.串列的定義
- 2.串列的常用方法和操作
- 物件.方法名(引數)
- 3.for in對串列迭代遍歷
- 4.利用 for in 的輸出技巧
- 二、元組 tuple
- 1.元組的定義
- 2.元組的兩個方法和一個函式:count 、 index 和 len()
- 3.for in對串列迭代遍歷(較少使用)
- 4.元組的應用場景
- (1)print 的陳述句格式輸出
- (2)作為函式的 引數值 使用
- (3)作為函式的 回傳值 使用
- 5.元組 和 串列 之間的轉換
- list(元組)
- tuple(串列)
- 三、字典 dictionary
- 1.字典的定義
- 2.字典的常用方法和操作
- 3.for in對字典迭代遍歷(較少使用)
- 4.字典的應用場景
- (1)將多個字典嵌套在串列中,組成“ 結構體陣列/順序表 ”
- 四、字串 string
- 1.字串的定義
- 2.字串的常用方法和操作
- (1)訪問、統計與查找
- (2)型別判斷
- (3)查找和替換
- (4)文本對齊
- (5)去除空白字符
- (6)拆分和連接
- 3.for in對字串迭代遍歷(較少使用)
- 4.字串的切片
- 字串[開始下標:結束下標]
- 字串[開始下標:結束下標:步長]
- 五、高級資料型別的公共方法
- 1.Python的內置函式
- 2.切片
- 3.運算子
- 4.完整的for回圈語法
- 六、階段學習小結——綜合應用:名片管理系統
- 1.框架搭建
- 2.完善其余函式
- (1)building() -> dict 函式
- (2)listing(list) 函式
- (3)inquire(list) 函式
- 3.源代碼
- (1)administration_function.py 檔案:
- (2)administration_main.py 檔案:
- 上一篇文章
- 下一篇文章
一、串列 list
串列是 Python 中使用次數最頻繁的資料型別,在其他語言中其被稱為陣列
1.串列的定義
list_name = ["張三", "李四", "王二"]
- 利用下標/索引訪問串列中的內容,如:list_name[0] = “張三”
- 同其他語言一樣,串列的下標/索引從 0 開始
2.串列的常用方法和操作
方法的呼叫格式:
物件.方法名(引數)
- 方法和函式類似,同樣是封裝好了的獨立功能
- 方法需要通過物件來呼叫,表示針對這個物件要做的操作
- 其中串列表示串列名——屬于物件
- del() 和 len() 屬于函式,其他屬于方法
| 序號 | 分類 | 關鍵字/函式/方法 | 含義 |
|---|---|---|---|
| 1 | 增加 | 串列.insert(下標, 資料) | 在指定位置插入資料 |
| 串列.append(資料) | 在末尾追加資料 | ||
| 串列.extend(串列2) | 將串列2的資料追加到串列 | ||
| 2 | 修改 | 串列[下標] = 資料 | 修改指定下標的資料 |
| 3 | 查找 | 串列.index(資料) | 查找第一次出現資料的位置,回傳下標 |
| 4 | 洗掉 | del 串列[下標] | 洗掉指定下標的資料 |
| 串列.remove(資料) | 洗掉第一次出現的指定資料 | ||
| 串列.pop | 洗掉末尾資料 | ||
| 串列.pop(下標) | 洗掉指定下標的資料 | ||
| 串列.clear | 清空串列 | ||
| 5 | 統計 | len(串列) | 統計串列長度 |
| 串列.count(資料) | 統計資料在串列中出現的次數 | ||
| 6 | 排序 | 串列.sort() | 升序排序 |
| 串列.sort(reverse=True) | 降序排序 | ||
| 串列.reverse() | 逆序、反轉 |
- 注:由于串列是連續的,因此每次洗掉資料后,后面的資料會整體向前移動,來填補洗掉后的空缺,以此來保持串列的連續性(重要 )
同理,每次插入資料后,該位置和后面的資料會整體向后移動,來空出指定的位置用來插入資料,以此來保持串列的連續性(重要) - 查找中的 index(self, value, start, stop) 實際上是有四個引數的,以后會講到,若僅需查找資料則指定 串列.index(資料) 即可
- del 串列[下標] 和 串列.pop(下標) 的區別:del 本質上是用于清除記憶體的;而 pop 的定義是用與串列的,因此 del 還可以用于其他資料型別,例如:
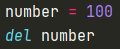
- del 串列 和 串列.clear 的區別:串列.clear 后,雖然串列被清空,但串列仍然存在(是個空串列),仍然可以用 print(串列) 來訪問;而 del 串列 后,串列的記憶體直接被清除,串列都不存在了,自然不能用 print(串列) 來訪問
- 在指定資料中,若指定的資料不存在,則PyCharm會直接報錯,如:若指定的資料不存在,則index會報錯(重要)
- 在 串列.append(資料) 中,若所追加的資料也是一個串列,那么Python就會把新的串列當成一個物件追加到串列中,如:[0, 1, 2, 3].append([4, 5]) = [0, 1, 2, 3, [4, 5]]
例:下面展示增刪改查以及各種操作的使用
list_name = ["張三", "李四", "王二", "李四"]
# 可以使用下標進行取值
print(list_name)
# 查找
print(list_name.index("李四"))
# 插入
list_name.insert(0, "老王")
print(list_name)
list_name.append("老樊")
print(list_name)
other_list = ["莫德凱撒"]
list_name.extend(other_list)
print(list_name)
# 修改
list_name[2] = "王五"
print(list_name)
# 洗掉
del list_name[0]
print(list_name)
list_name.remove("老樊")
print(list_name)
list_name.clear()
print(list_name)

例:查看 Python 中自帶的關鍵字個數
import keyword
print(len(keyword.kwlist))
3.for in對串列迭代遍歷
在 Python 中,為了提高串列的遍歷效率,專門提供的迭代 iteration 遍歷
使用 for 就能實作迭代遍歷,即按串列順序地把串列里的元素依次訪問獲取,放在指代詞中
"""for 回圈內部使用的變數 in 串列"""
for name in list_name:
"""回圈內部針對串列元素進行操作"""
print(name)
- 注:此處的 name 是隨意起的,其作用是用來分別在每一層遍歷中指代 list_name 里面的元素
迭代遍歷邏輯與格式如圖所示:

提示:Python 的串列是可以存放不同資料型別的元素的,但一般是存放相同資料型別的資料,更加便于迭代遍歷
4.利用 for in 的輸出技巧
例:
for data in ["姓名", "性別", "年齡", "學號"]:
print(data, end="\t\t\t")

二、元組 tuple
在SQL資料庫中,我們知道元組由若干個資料型別不盡相同的屬性組成,于是在 Python 中,或者說與串列不同地方在于,元組用于存盤資料型別不同的元素,并且元組內的元素不能更改
1.元組的定義
"""創建一個元組的兩種方式"""
info_tuple0 = ("張三", "男", 18, 20201111)
info_tuple1 = "張三", "男", 18, 20201111
"""創建一個空元組,極少使用"""
empty_tuple = ()
"""這不是一個元組"""
info_tuple2 = (5)
"""如果元組只有一個元素,可以這樣定義"""
info_tuple2 = (5, )
- 串列的定義是用 [ ] ,而元組的定義可以用 ( ) ,但 ( ) 并不唯一標識元組,而是逗號 " , "
- 但是,元組里的元素不能修改,它側重于儲存一組固定的資料,如:個人資訊
- 元組的下標 [ ] 同樣從 0 開始計數
- 元組內部可以嵌套串列,此時可以改變串列的值,這并不算改變元組
- 串列內部可以嵌套元組,此時可以組成一張關系表,而串列一般標記的可以是主碼
2.元組的兩個方法和一個函式:count 、 index 和 len()
| 序號 | 分類 | 函式/方法 | 含義 |
|---|---|---|---|
| 1 | 統計 | 元組.count(資料) | 統計資料在元組中出現的次數 |
| len(元組) | 統計元組中的元素個數 | ||
| 2 | 查找 | 元組.index(資料) | 查找資料第一次出現在元組的位置,回傳下標 |
例:
info_tuple = "張三", "男", 18, 2020111
print(info_tuple.count("張三"), end=" ")
print(info_tuple.index(18), end=" ")
print(len(info_tuple), end="")

3.for in對串列迭代遍歷(較少使用)
例:
"""定義一個元組"""
info_tuple = ("張三", "男", 18, 2020111)
"""迭代遍歷"""
for information in info_tuple:
print(information)
4.元組的應用場景
(1)print 的陳述句格式輸出
info_tuple = ("張三", "男", 18, 2020111)
print("學生名字叫 %s,性別 %s,今年 %d 歲,學號是 %d" % info_tuple)
"""欄位還可以被視為字串"""
info_str = "學生名字叫 %s,性別 %s,今年 %d 歲,學號是 %d" % info_tuple
print(info_str)

(2)作為函式的 引數值 使用
def info_function(temporary_tuple):
"""元組作為函式的引數值使用"""
print(temporary_tuple)
new_tuple = ("李紅", "女", 18, 20001111)
info_function(new_tuple)

(3)作為函式的 回傳值 使用
def info_function():
"""元組作為函式的回傳值使用"""
temporary_tuple = ("老王", "男", 36, 19991111)
return temporary_tuple
new_tuple = info_function()
print(info_function())

5.元組 和 串列 之間的轉換
list(元組)
把元組轉換成串列
tuple(串列)
把串列轉換成元組
三、字典 dictionary
字典是無序的物件集合,我們不關心其內容的順序,它類似于關系資料庫中的一張關系表,或者說是C語言中的一個結構體
1.字典的定義
student = {"name": "張三",
"sex": "男",
"height": 1.75,
"weight": 135}
- 字典通過鍵來訪問,如:student[“name”] = “張三”
- 字典的定義使用 { } ,其中 鍵 key 是索引/下標, 值 value 是資料,鍵必須是唯一的
- 鍵值對之間用逗號 " , " 分開,而 鍵 與 值 之間用冒號 " : " 分開
- 上述字典所定義的關系表為:
| 鍵 key | 值 value |
|---|---|
| name | 張三 |
| sex | 男 |
| height | 1.75 |
| weight | 135 |
2.字典的常用方法和操作
| 序號 | 分類 | 關鍵字/函式/方法 | 含義 |
|---|---|---|---|
| 1 | 訪問 | 字典[鍵] | 訪問字典中對應鍵的值 |
| 字典.get(鍵) | 訪問字典中對應鍵的值 | ||
| 2 | 增加 | 字典[鍵] = 值 | 其中鍵為原字典不存在的鍵,即可新增鍵值 |
| 字典.setdefault(鍵, 值) | 如果鍵存在,不會修改值;如果鍵不存在,則新建鍵值對 | ||
| 3 | 修改 | 字典[鍵] = 修改值 | 其中鍵為原字典存在的鍵,即可修改值,相當于重新賦值 |
| 4 | 洗掉 | 字典.pop(鍵) | 洗掉指定的鍵值對 |
| del 字典[鍵] | 洗掉字典中指定的鍵值對 | ||
| 字典.clear() | 清空字典 | ||
| del 字典 | 洗掉字典 | ||
| 字典.popitem() | 洗掉字典中的最后一個鍵值對 | ||
| 5 | 串列 | 字典.keys() | 依次列出所有的key |
| 字典.values() | 依次列出所有的value | ||
| 字典.items() | 依次列出所有的鍵值對,比 print(字典) 更好 | ||
| 6 | 合并 | 字典.update(字典2) | 將字典2合并到字典中 |
| 7 | 統計 | len(字典) | 統計鍵值對的數量 |
例:
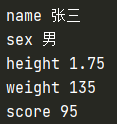
student = {"name": "張三",
"sex": "男",
"height": 1.75,
"weight": 135,
"score": 95}
print(student.keys())
print(student.values())
print(student.items())
print(student)

提示:由于各函式和方法簡單易懂、易使用,因此這里不再作詳細的示例
3.for in對字典迭代遍歷(較少使用)
迭代遍歷邏輯與格式如圖所示:

注:指代詞指代的是鍵,可用每層迭代的不同鍵來訪問不同值
例:
student = {"name": "張三",
"sex": "男",
"height": 1.75,
"weight": 135,
"score": 95}
for key in student:
print("%s %s" % (key, student[key]))
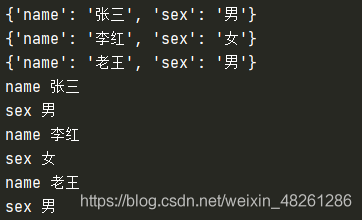
4.字典的應用場景
(1)將多個字典嵌套在串列中,組成“ 結構體陣列/順序表 ”
例:
student_list = [{"name": "張三",
"sex": "男"},
{"name": "李紅",
"sex": "女"},
{"name": "老王",
"sex": "男"}]
"""列印方式1"""
for table in student_list:
print(table)
"""列印方式2"""
for table in student_list:
for key in table:
print("%s %s" % (key, table[key]))
四、字串 string
實際上,我們在 二、Python基礎(基礎篇)已經大量使用過字串了
1.字串的定義
str1 = "歡迎來到 ~憲憲 的博客"
str2 = '歡迎來到"~憲憲"的博客'
- 一般來說,我們定義字串時使用的是雙引號 " "
- 但是如果我們想讓字串里面有 " " 的字符,那我們就使用單引號 ’ ’ 來定義
- 字串可以通過下標/索引來訪問字串中的字符,如:str1[0] = ”歡“,str1[1] = “迎”
2.字串的常用方法和操作
(1)訪問、統計與查找
| 序號 | 分類 | 關鍵字/函式/方法 | 含義 |
|---|---|---|---|
| 1 | 訪問 | 字串[下標] | 訪問字串中的字符 |
| 2 | 查找 | 字串.index(小字串) | 查找子字串第一次出現在大字串的位置,回傳下標 |
| 3 | 統計 | len(字串) | 統計字串的長度 |
| 字串.count(小字串) | 統計子字串在大字串中出現的次數 |
(2)型別判斷
這里的方法名很好理解,都是由 isXXX 構成,isXXX 就是“是XXX”的意思
| 序號 | 方法 | 含義 |
|---|---|---|
| 1 | string.isspace() | 如果string中只包含空白字符(空格、\t、\n、\r),則回傳True |
| 2 | string.isalnum() | 如果string至少有一個字符并且所有字符都是字母或數字則回傳True |
| 3 | string.isalpha | 如果string至少有一個字符并且所有字符都是字符則回傳True |
| 4 | string.isdecimal() | 如果string只包含數字則回傳True,全角數字 |
| 5 | string.isdigit() | 如果string只包含數字則回傳True,全角數字、⑴、\u00b2 |
| 6 | string.isnumeric() | 如果string只包含數字則回傳True,全角數字、漢字數字 |
| 7 | string.istitle() | 如果string是標題化的(每個單詞的首字母大寫)則回傳True |
| 8 | string.islower() | 如果string中包含至少一個區分大小寫的字符(如:字母),并且所有這些區分大小寫的字符(如:字母)都是小寫,則回傳True |
| 9 | string.isupper() | 如果string中包含至少一個區分大小寫的字符(如:字母),并且所有這些區分大小寫的字符(如:字母)都是大寫,則回傳True |
- 是則回傳True,否則回傳False
- 方法4、5、6都不能判斷小數,如:3.14(注意)
- 方法4:阿拉伯數字
- 方法5:阿拉伯數字、⑴⑵——unicode字串,無法直接通過鍵盤直接輸入,但可以通過輸入法輸入、\u00b2即:2——上標數字,無法直接通過鍵盤直接輸入,在Python中用 \u00bX 表示
- 方法6:阿拉伯數字、漢字數字
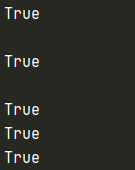
例:我們展示較為常用的幾個方法
str1 = " \n \t \r"
print(str1.isspace())
print()
str2 = "abc123"
print(str2.isalnum())
print()
str3 = "12345"
str4 = "4⑴23\u00b2"
str5 = "一千零一6六萬三千"
print(str3.isdecimal())
print(str4.isdigit())
print(str5.isnumeric())
(3)查找和替換
| 序號 | 方法 | 含義 |
|---|---|---|
| 1 | string.startswith(str) | 檢查字串是否以str開頭,是則回傳True |
| 2 | string.endswith(str) | 檢查字串是否以str結束,是則回傳True |
| 3 | string.find(str, start, end) | 檢測str是否包含在string內,如果start和end指定范圍,則檢查是否包含在指定范圍內,如果是則回傳str第一次出現時字符開始的下標,否則回傳-1 |
| 4 | string.rfind(str, start, end) | 類似于find()函式,不過是查找str在右邊第一次出現的位置(str可能出現多次) |
| 5 | string.index(str, start, end) | 跟find()方法類似,只不過如果str不再string會報錯 |
| 6 | string.rindex(str, start, end) | 類似于index(),不過是查找str在右邊第一次出現的位置(str可能出現多次) |
| 7 | string.replace(old_str, new_str, num | 把string中的old_str替換成new_str,如果num指定,則替換不超過num次 |
- str指的是string中的一段小字串
- 指定范圍 [start,end):start指的是開始的下標,end表示結束的下標,檢索start,但不檢索end
- 方法7:在執行完之后會回傳一個新的的字串,但不會把修改結果覆寫到string中(重要)
- 方法7:num 為可執行替換的最高次數,若num>len(string),則全部替換;若num<len(string),則替換前num個指定字串
- 如果要查找的資料不存在于string中,index 會報錯,而 find 會回傳-1不會報錯
例:我們展示較為常用的幾個方法
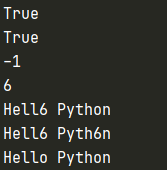
str1 = "Hello Python"
print(str1.startswith("He"))
print(str1.endswith("on"))
print(str1.find("Py", 6, 7))
print(str1.find("Py", 6, 8))
print(str1.replace("o", "6", 1))
print(str1.replace("o", "6"))
print(str1)
(4)文本對齊
| 序號 | 方法 | 含義 |
|---|---|---|
| 1 | string.ljust(width) | 回傳一個 原字串左對齊,并使用空格填充至長度width的 新字串 |
| 2 | string.rjust(width) | 回傳一個 原字串右對齊,并使用空格填充至長度width的 新字串 |
| 3 | string.center(width) | 回傳一個 原字串居中,并使用空格填充至長度width的 新字串 |
- 注:這些方法只是回傳一個新的字串,而不會覆寫原字串string
- ljust(width, str) 、rjust(width, str) 和 **center(width, str)**都有原型,當 str 預設時,會使用半角空格(一個英文長度的空格)來進行填充;當 str 指定后,會使用 str 指定的字符來進行填充
- 如果 width 的長度比 string 短,那么對齊可能無效
例:由于是中文的對齊,因此我們指定 str 為全角空格(一個中文長度的空格)來進行對齊
- 其中 " " 中的 | | 用于觀察 width 的長度,顯然長度都一致
"""假設以下文本是從網路上爬取的,要進行文本對齊"""
poem = ["歲月極美",
"在于它必然的流逝",
"我們將掌心攏起",
"也抓不住飄渺的云煙",
"攥不住流動的細沙",
"更留不住逝去的年華"]
for sentence in poem:
print("|%s|" % sentence.rjust(20, " "))
for sentence in poem:
print("|%s|" % sentence.ljust(20, " "))
for sentence in poem:
print("|%s|" % sentence.center(20, " "))

(5)去除空白字符
| 序號 | 方法 | 含義 |
|---|---|---|
| 1 | string.lstrip() | 截掉string左邊的(開始)的空白字符 |
| 2 | string.rstrip() | 截掉string右邊的(末尾)的空白字符 |
| 3 | string.strip() | 截掉string左右兩邊的空白字符 |
- 注:這些方法只是回傳一個新的字串,而不會覆寫原字串string
例:還是以poem為例,我們隨意地向詩句上面增加一些空白字符
"""假設以下文本是從網路上爬取的"""
poem = ["\n\t歲月極美",
"在于它必然的流逝",
"我們將掌心攏起\t\n",
"\t也抓不住飄渺的云煙",
"攥不住流動的細沙",
"更留不住逝去的年華"]
for sentence in poem:
"""我們去除空白字符,再進行文本對齊"""
print("|%s|" % sentence.strip().center(20, " "))

- 補充:在這個代碼中,我們首次展示了方法的連用:
print("|%s|" % sentence.strip().center(20, " "))
即首先通過 strip() 得到一個新的字串,再通過 center() 來對這個新字串再進行操作,從而形成了方法的連用,本質上,原字串和第一個新字串都是一個物件,它們均能夠使用方法
(6)拆分和連接
| 序號 | 方法 | 含義 |
|---|---|---|
| 1 | string.partition(str) | 把字串string分成一個3元素的元組(str前面,str,str后面) |
| 2 | string.rpartition(str) | 類似于partition()方法,不過是查找str在右邊第一次出現的位置(str可能有多個) |
| 3 | string.split(str, num) | 以str為分隔符拆分string,如果num有指定值,則僅分隔num+1個子字串(str預設時,str為空白字符\r、\t、\n和空格) |
| 4 | string.splitlines() | 按照行(\r、\n、\r\n)分隔,回傳一個包含各行作為元素的串列 |
| 5 | string.join(seq) | 以string作為分隔符,將seq(字串或元組)中所有的元素(的字串表示)合并為一個新的字串 |
- 注:這些方法只是回傳一個新的字串或元組,而不會覆寫原字串string
- 方法1、2、3、4的回傳值是一個元組
例:
str1 = "Hello World"
print(str1.partition("l"))
print(str1.rpartition("l"))
str2 = "\n\t歲月極美\t在于它必然的流逝\n我們將掌心攏起 也抓不住飄渺的云煙\n攥不住流動的細沙\t更留不住逝去的年華"
new_str = str2.split()
for information in new_str:
print(information)
print(" ".join(new_str))

3.for in對字串迭代遍歷(較少使用)
str = "歡迎來到 ~憲憲 的博客"
for char in str:
print(char, end='')

4.字串的切片
字串[開始下標:結束下標]
截取范圍 [開始下標,結束下標) 的字串
字串[開始下標:結束下標:步長]
可以從 開始下標~結束下標 的范圍對字串進行切片,其中步長指的是下一次切片時相對于這一次切片時的位置按步長的方向向后位移的元素個數(下標數),因此步長不能為0,否則切片的位置不動是顯然不正確的
- 當 步長>0 時:表示從左到右進行切片,此時范圍應滿足:開始下標<結束下標
- 當 步長<0 時:表示從右到左進行切片,此時范圍應滿足:開始下標>結束下標
- 當 步長預設時,則默認:步長=1
- 范圍:[開始下標,結束下標) 中,結束下標的字符不包含在范圍內
(1)若開始下標預設,則開始下標默認為字串的最左端或最右端,這個開始位置由切片的方向決定,若步長>0,則開始下標為字串最左端;若步長<0,則開始下標為字串最右端
(2)若結束下標預設,則按步長方向切片到字串的另一端盡頭 - 當不知道字串的長度時,開始下標或結束下標可用負數來指定,表示倒數第幾個元素,如-1就是倒數第1個字符(由于沒有-0之說,所以負下標是從-1開始)
- 步長,如:對"歡迎來到~憲憲的博客"進行步長為2的切片,從 [0,10) 的范圍進行切片,第一次切下的是"歡",由于步長為2,第二次切片的位置相對這一次切片時的位置向后位移2個下標(間隔1個字符),故第二次切下的是"來",第三次切下的是"~",接著"憲",“博”
——于是,上述截取的結果為:“歡來~憲博” - 當步長預設時,則默認為1,即每次切片向后位移一個下標的單位
例:str1[::]表示截取完整的字串
例:str1[::2]表示每次切片后下次切片時下標位移2個單位(間隔1個字符),截取范圍為整個字串
例:str1[-1]倒數第1個字符,即下標訪問
例:
str1 = "歲月極美 在于它必然的流逝 我們將掌心攏起 也抓不住飄渺的云煙 攥不住流動的細沙 更留不住逝去的年華"
print(str1)
print(new_str2[0:4])
"""從開始到結束,步長為2"""
print(new_str2[0::2])
print(new_str2[0:-2:2])

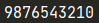
例:字串逆序輸出
str2 = "0123456789"
print(str2[-1::-1])
五、高級資料型別的公共方法
針對高級變數型別串列、元組、字典和字串都可以使用的方法稱為公共方法
1.Python的內置函式
| 函式 | 描述 | 備注 |
|---|---|---|
| len(item) | 計算容器中元素個數 | |
| del(item) | 洗掉變數 | del有兩種方式 |
| max(item) | 回傳容器中元素最大值 | 如果是字典,只針對key比較 |
| min(item) | 回傳容器中元素最小值 | 如果是字典,只針對key比較 |
| cmp(item1, item2) | 比較兩個值(-1小于/0相等/1大于) | Python3.X取消了cmp函式 |
- del的兩種方式分別是關鍵字和函式前面我們使用的是關鍵字,它們效果是完全相同的
- 比較字符的大小會按照ASCII碼和字典排序的方式來進行比較(不懂字典排序可自行百度)
- 在Python3.X中,可以通過比較運算子來代替cmp函式,比較運算子回傳值為True或False
- 兩個字典之間不能比較大小
- 串列和元組的比較大小,對串列或元組內的元素依次進行比較,當相同下標的元素第一次出現不同時,則回傳這個比較結果(按ASCII或字典排序比較),如果所有相同下標的元素都相等,則回傳相等結果(重要)
2.切片
除字串外,串列和元組的元素也可以通過下標來進行訪問,因此它們也可以進行切片操作
| 描述 | Python運算式 | 結果 | 支持的資料型別 |
|---|---|---|---|
| 切片 | “0123456789”[::-2] | “97531” | 字串、串列、元組 |
例:
"""其他型別的切片"""
list_name = [1, 2, 3, 4, 5, 6]
print(list_name[::-2])
info_tuple = ("張三", "男", 18, 1.75)
print(info_tuple[::-3])

3.運算子
| 運算子 | Python運算式 | 結果 | 描述 | 支持的資料型別 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字串、串列、元組 |
| * | [“Hi!”] * 4 | [“Hi!”, “Hi!”, “Hi!”, “Hi!”] | 重復 | 字串、串列、元組 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字串、串列、元組、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字串、串列、元組、字典 |
| >、>=、==、<、<= | (1, 2, 3) < (2, 2, 3) | True | 元素比較 | 字串、串列、元組 |
- 串列.extend(串列2) 會把串列2追加到串列上,而串列1 + 串列2會生成新的串列
4.完整的for回圈語法
完整的迭代遍歷邏輯與格式如圖所示:

- 注:continue 不會影響else的執行
例:
for num in [0, 1, 2, 3]:
if num == 3:
break
else:
print("這段代碼不會被執行")
完整的for else陳述句對求范圍內的素數時非常好用
常用應用場景:
例:在指定的字典串列中尋找資訊,如:查找李紅和李華的性別,如果沒找到則告訴用戶
student_list = [{"name": "張三",
"sex": "男"},
{"name": "李紅",
"sex": "女"},
{"name": "老王",
"sex": "男"}]
"""在字典中查找李紅的性別"""
for info_tuple in student_list:
if info_tuple["name"] == "李紅":
print("找到了李紅,性別:%s" % info_tuple["sex"])
break
else:
print("沒有找到李紅")
"""在字典中查找李華的性別"""
for info_tuple in student_list:
if info_tuple["name"] == "李華":
print("找到了李紅,性別:%s" % info_tuple["sex"])
break
else:
print("沒有找到李華")

六、階段學習小結——綜合應用:名片管理系統
名片資訊包含:姓名、電話、QQ、郵箱
需求:
- 新增名片
- 顯示所有名片
- 名片查詢——修改名片、洗掉名片
- 要有一個選擇的界面
1.框架搭建
我們約定用 administration_main.py 檔案作為名片管理系統的主函式
其次,用 administration_function.py 檔案作為名片管理系統封裝函式的檔案
于是, administration_main.py 檔案中搭建的功能代碼框架如下:
import administration_function
"""創建一個空串列,用于放置用戶的名片字典"""
list_card = []
"""保證用戶回圈輸入"""
while 1:
administration_function.welcome()
choice = input("請輸入您的選擇:")
if choice == "0":
exit(0)
elif choice == "1":
list_card.append(administration_function.building())
elif choice == "2":
administration_function.listing(list_card)
elif choice == "3":
administration_function.inquire(list_card)
else:
print("請輸入有效的選項!")
continue
下面介紹上述代碼中所出現的 administration_function.py 檔案中的函式:
- welcome():歡迎界面,用于指參考戶進行選擇
- building():新建名片,回傳一個字典
list_card.append(administration_function.building()) 表示把新建的字典追加到串列后 - listing(list):顯示所有名片( list_card )
- inquire(list):在 list_card 中查詢名片
administration_function.py 檔案中的 welcome() 歡迎界面函式代碼如下:
提示:print("******************************************************") 可以用 print(" * " * 50) 來表示
def welcome():
"""歡迎界面"""
print("******************************************************")
print("歡迎使用【名片管理系統】 V1.0")
print()
print("1.新建名片")
print("2.查看所有名片")
print("3.查詢名片")
print()
print("0.退出系統")
print("******************************************************")

輸入錯誤判斷:

于是,名片管理系統的總體框架我們已經搭建起來了
2.完善其余函式
(1)building() -> dict 函式
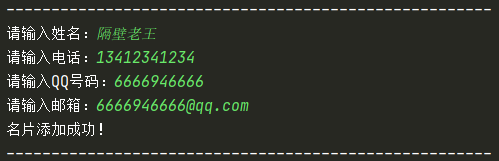
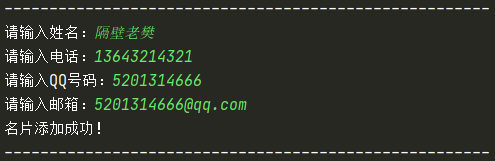
building() -> dict 函式用于新建名片,并且回傳一個字典,因此我們要求用戶輸入并獲取新建名片時輸入的資訊:姓名、電話、QQ和郵箱;新建一個字典,把獲得的資訊置于字典中,并回傳字典
def building():
"""新建名片"""
print("------------------------------------------------------")
temp_name = input("請輸入姓名:")
temp_phone = input("請輸入電話:")
temp_qq = input("請輸入QQ號碼:")
temp_email = input("請輸入郵箱:")
print("名片添加成功!")
print("------------------------------------------------------")
temp_dict = {"name": temp_name,
"phone": temp_phone,
"qq": temp_qq,
"email": temp_email}
return temp_dict
(2)listing(list) 函式
listing(list) 函式用于顯示所有名片,因此需要把由 名片字典 組成的 串列 list_card 作為引數傳入函式,當程式中沒有名片時我們要告訴用戶名片集為空,否則按照一定的文本格式來輸出程式中的名片
def listing(temp_list):
"""列出所有名片"""
"""用len()函式來判斷串列是否為空"""
if len(temp_list) == 0:
print("------------------------------------------------------")
print("名片為空!")
print("------------------------------------------------------")
return
"""控制輸出格式"""
print("******************************************************")
print("姓名".center(6, " "),
"電話".center(12, " "),
"QQ".center(12, " "),
"郵箱".center(12, " "))
for card in temp_list:
print(card["name"].ljust(6, " "),
card["phone"].ljust(12, " "),
card["qq"].ljust(12, " "),
card["email"].ljust(12, " "))
print("******************************************************")
當程式中名片為空時:

當程式中名片不為空時:
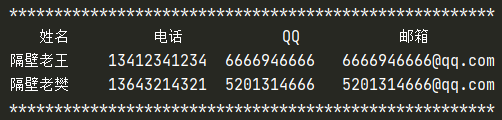
(3)inquire(list) 函式
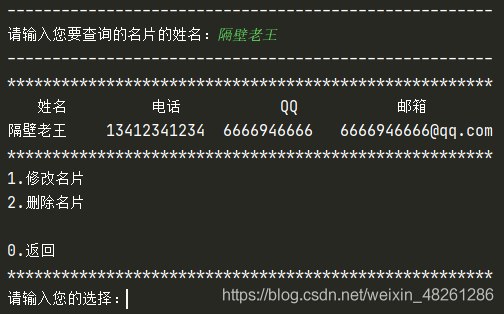
inquire(list) 函式用于查詢名片,因此需要判斷所查詢的名片是否存在,在查詢名片后,提供用戶兩個選擇:修改名片、洗掉名片,還有回傳到主選單,因此在 inquire(list) 函式中,又另外添加了一個函式:change(dict) 函式,主要用于修改名片中的值,因此需要傳入需要更改的名片字典作為引數
inquire(list) 函式代碼如下:
def inquire(temp_list):
"""查詢名片"""
print("------------------------------------------------------")
temp_name = input("請輸入您要查詢的名片的姓名:")
print("------------------------------------------------------")
"""根據用戶輸入的姓名查找名片,并列出名片資訊"""
for card in temp_list:
if card["name"] == temp_name:
print("******************************************************")
print("姓名".center(6, " "),
"電話".center(12, " "),
"QQ".center(12, " "),
"郵箱".center(12, " "))
print(card["name"].ljust(6, " "),
card["phone"].ljust(12, " "),
card["qq"].ljust(12, " "),
card["email"].ljust(12, " "))
print("******************************************************")
print("1.修改名片")
print("2.洗掉名片")
print()
print("0.回傳")
print("******************************************************")
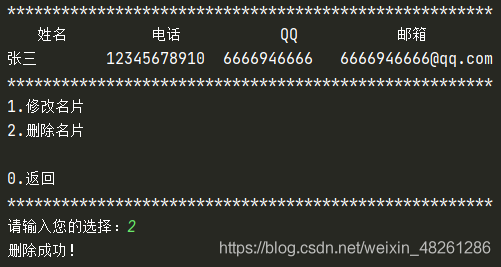
while 1:
temp_choice = input("請輸入您的選擇:")
if temp_choice == "0":
return
elif temp_choice == "1":
change(card)
break
elif temp_choice == "2":
# 洗掉名片
del temp_list[temp_list.index(card)]
print("洗掉成功!")
break
else:
print("請輸入有效的選項")
continue
break
else:
print("沒有找到該姓名的名片")
print("------------------------------------------------------")
- 注意指代詞card,由于無法直接通過指代詞card來洗掉串列中的元素,因此我們需要通過
串列.index(資料) 函式先找到需要洗掉的名片字典所在的下標,再用 del temp_list[下標] 才能正確洗掉串列中的名片字典
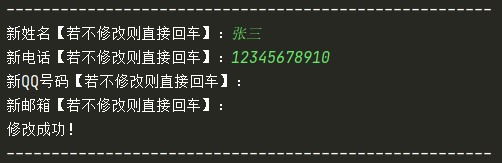
change(dict) 函式代碼如下:
直接傳入需要修改的字典即可修改名片字典
def change(temp_dict):
"""修改名片"""
print("------------------------------------------------------")
temp_name = input("新姓名【若不修改則直接回車】:")
if temp_name != "":
temp_dict["name"] = temp_name
temp_phone = input("新電話【若不修改則直接回車】:")
if temp_phone != "":
temp_dict["phone"] = temp_phone
temp_qq = input("新QQ號碼【若不修改則直接回車】:")
if temp_qq != "":
temp_dict["qq"] = temp_qq
temp_email = input("新郵箱【若不修改則直接回車】:")
if temp_email != "":
temp_dict["email"] = temp_email
print("修改成功!")
print("------------------------------------------------------")
- 當用戶直接按下回車時,表示輸入的內容為 “” 空,我們以此來表示用戶不想作修改時的選擇
最后,名片管理系統順利完成!
3.源代碼
(1)administration_function.py 檔案:
def welcome():
"""歡迎界面"""
print("******************************************************")
print("歡迎使用【名片管理系統】 V1.0")
print()
print("1.新建名片")
print("2.查看所有名片")
print("3.查詢名片")
print()
print("0.退出系統")
print("******************************************************")
def building():
"""新建名片"""
print("------------------------------------------------------")
temp_name = input("請輸入姓名:")
temp_phone = input("請輸入電話:")
temp_qq = input("請輸入QQ號碼:")
temp_email = input("請輸入郵箱:")
print("名片添加成功!")
print("------------------------------------------------------")
temp_dict = {"name": temp_name,
"phone": temp_phone,
"qq": temp_qq,
"email": temp_email}
return temp_dict
def listing(temp_list):
"""列出所有名片"""
if len(temp_list) == 0:
print("------------------------------------------------------")
print("名片為空!")
print("------------------------------------------------------")
return
print("******************************************************")
print("姓名".center(6, " "),
"電話".center(12, " "),
"QQ".center(12, " "),
"郵箱".center(12, " "))
for card in temp_list:
print(card["name"].ljust(6, " "),
card["phone"].ljust(12, " "),
card["qq"].ljust(12, " "),
card["email"].ljust(12, " "))
print("******************************************************")
def change(temp_dict):
"""修改名片"""
print("------------------------------------------------------")
temp_name = input("新姓名【若不修改則直接回車】:")
if temp_name != "":
temp_dict["name"] = temp_name
temp_phone = input("新電話【若不修改則直接回車】:")
if temp_phone != "":
temp_dict["phone"] = temp_phone
temp_qq = input("新QQ號碼【若不修改則直接回車】:")
if temp_qq != "":
temp_dict["qq"] = temp_qq
temp_email = input("新郵箱【若不修改則直接回車】:")
if temp_email != "":
temp_dict["email"] = temp_email
print("修改成功!")
print("------------------------------------------------------")
def inquire(temp_list):
"""查詢名片"""
print("------------------------------------------------------")
temp_name = input("請輸入您要查詢的名片的姓名:")
print("------------------------------------------------------")
for card in temp_list:
if card["name"] == temp_name:
print("******************************************************")
print("姓名".center(6, " "),
"電話".center(12, " "),
"QQ".center(12, " "),
"郵箱".center(12, " "))
print(card["name"].ljust(6, " "),
card["phone"].ljust(12, " "),
card["qq"].ljust(12, " "),
card["email"].ljust(12, " "))
print("******************************************************")
print("1.修改名片")
print("2.洗掉名片")
print()
print("0.回傳")
print("******************************************************")
while 1:
temp_choice = input("請輸入您的選擇:")
if temp_choice == "0":
return
elif temp_choice == "1":
change(card)
break
elif temp_choice == "2":
# 洗掉名片
del temp_list[temp_list.index(card)]
print("洗掉成功!")
break
else:
print("請輸入有效的選項")
continue
break
else:
print("沒有找到該姓名的名片")
print("------------------------------------------------------")
(2)administration_main.py 檔案:
import administration_function
list_card = []
while 1:
administration_function.welcome()
choice = input("請輸入您的選擇:")
if choice == "0":
exit(0)
elif choice == "1":
list_card.append(administration_function.building())
elif choice == "2":
administration_function.listing(list_card)
elif choice == "3":
administration_function.inquire(list_card)
else:
print("請輸入有效的選項!")
continue
上一篇文章
- 二、Python基礎(基礎篇)
下一篇文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/256797.html
標籤:python
上一篇:Web全堆疊~31.并發