4399知名游戲-賽爾號圖鑒的爬取
面向物件:
1.疫情居家無聊之人
2.python略懂一點點就行
頭檔案引入:
如果沒有下面的頭檔案不要慌,打開你的python終端pip install +包名即可
from bs4 import BeautifulSoup
import requests
import json
import os
import sys
爬取賽爾號圖鑒:
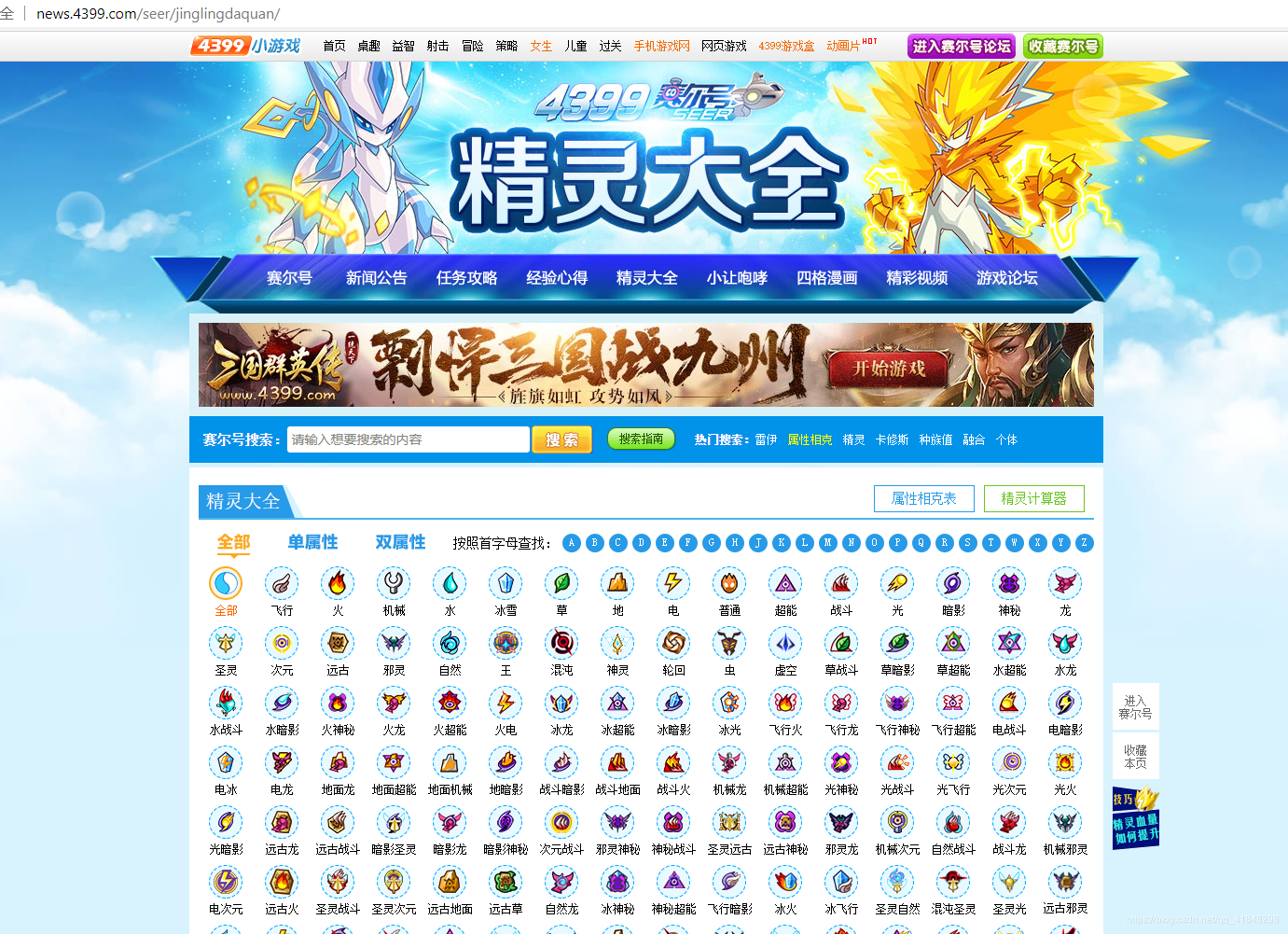
右鍵查看網頁源代碼你會發現編碼方式為’GBK’且有個script,省的我們動態獲取鏈接,可以看到petData是一個二維串列,petData[:,1]是圖鑒詳情頁,點進去看如下所示

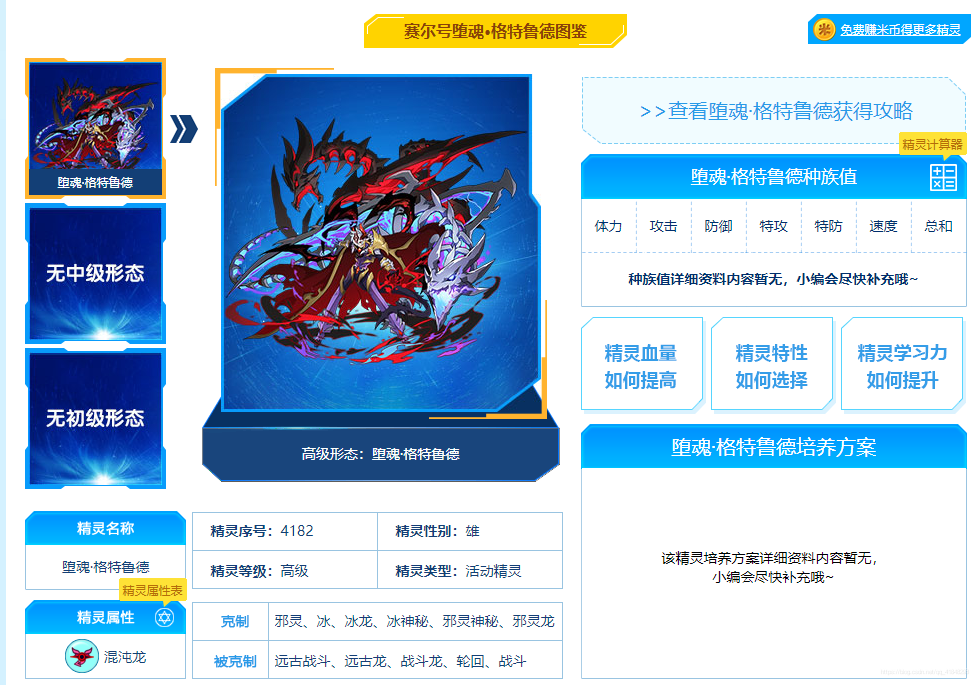
target = 'http://news.4399.com/seer/jinglingdaquan/'
req = requests.get(target).content.decode('gbk')
html = req
print('開始爬取...')
bf = BeautifulSoup(html)
t = bf.select('body > script') #圖鑒頁面的詳情資訊
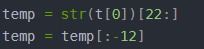
temp = str(t[0])[22:]
temp = temp[:-12]
lis = json.loads(temp) #str格式的list轉list
print('獲取圖片html...')
length = len(lis)
html_list = []
for i in range(length):
html_list.append(lis[i][1]) #把詳情url先存起來
print('載入成功,準備保存...')
先用html_list存盤詳情頁的url,當然可以直接進行下面的轉換不用先存

F12選中圖片發現圖片url竟在之中,get后保存本地即可,保存函式如下
def save_img(name,url): # 保存圖片
img = requests.get(url)
f = open(name, 'ab')
f.write(img.content)
print(name, '檔案保存成功!')
f.close()
dirname = input('請輸入存圖片的檔案夾名')
flag = os.path.exists('./'+dirname)
if not flag:
os.makedirs('./'+dirname)
else:
print('當前檔案夾下有同名目錄')
for i in range(length):
temp = requests.get(html_list[i]).content.decode('gbk')
temp_bf = BeautifulSoup(temp)
img = temp_bf.select('#state > div.focus.cf > div:nth-child(2) > img')
lis_img = str(img).split('"')
save_img('./'+dirname+'/'+lis_img[1]+'.jpg',lis_img[3])
now = os.getcwd()
print('爬取完畢!存于'+str(now)+'/'+str(dirname))
寫在最后:
當然你們可以不看博客直接復制下面的代碼
from bs4 import BeautifulSoup
import requests
import json
import os
import sys
def save_img(name,url): # 保存圖片
img = requests.get(url)
f = open(name, 'ab')
f.write(img.content)
print(name, '檔案保存成功!')
f.close()
target = 'http://news.4399.com/seer/jinglingdaquan/'
req = requests.get(target).content.decode('gbk')
html = req
print('開始爬取...')
bf = BeautifulSoup(html)
t = bf.select('body > script')
temp = str(t[0])[22:]
temp = temp[:-12]
lis = json.loads(temp)
print('獲取圖片html...')
length = len(lis)
html_list = []
for i in range(length):
html_list.append(lis[i][1])
print('載入成功,準備保存...')
dirname = input('請輸入存圖片的檔案夾名')
flag = os.path.exists('./'+dirname)
if not flag:
os.makedirs('./'+dirname)
else:
print('當前檔案夾下有同名目錄')
#sys.exit(0)
for i in range(967,length):
print(i,end = '')
try: #用于爬取精靈(多形態需要額外判斷select條件,我懶),有些不符合的get請求結果直接跳過
temp = requests.get(html_list[i]).content.decode('gbk')
temp_bf = BeautifulSoup(temp)
img = temp_bf.select('#state > div.focus.cf > div:nth-child(2) > img')
lis_img = str(img).split('"')
save_img('./'+dirname+'/'+lis_img[1]+'.jpg',lis_img[3])
except:
continue
now = os.getcwd()
print('爬取完畢!存于'+str(now)+'/'+str(dirname))
幾個注意的地方:
1.這里的切片位置可能會變,你可以選擇更加智能的切片,當然,是因為我懶,
2.這里的select,推薦EDGE瀏覽器F12選中目標標簽,右鍵復制SELECT即可

3.為什么要爬賽爾號圖鑒呢?
吃飽了撐的,當然不是,準備搭建簡易生成對抗網路就叫它SEERGAN吧(手動滑稽)隨機生成精靈,效果好的話就好玩了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/256799.html
標籤:python