本文將以嗶哩嗶哩–乘風破浪視頻為例,you-get下載視頻,同時利用python爬取B站視頻彈幕,并利用opencv對視頻進行分割,百度AI進行人像分割,moviepy生成詞云跳舞視頻,并添加音頻,
1. 匯入模塊
1.1 下載所需模塊
我們需要下載很多的模塊,所以我們可以使用os.system()方法來自動安裝所需模塊,當然也有可能下載失敗,特別是opencv-python,多安裝幾次就好啦.
import os
import time
libs = {"lxml","requests","pandas","numpy","you-get","opencv-python","pandas","fake_useragent","matplotlib","moviepy"}
try:
for lib in libs:
os.system(f"pip3 install -i https://pypi.doubanio.com/simple/ {lib}")
print(lib+"下載成功")
except:
print("下載失敗")1.2 匯入模塊
在這里統一先匯入所需的模塊
import os
import re
import cv2
import jieba
import requests
import moviepy
import pandas as pd
import numpy as np
from PIL import Image
from lxml import etree
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from fake_useragent import UserAgent2. 視頻處理
2.1 下載視頻
從B站視頻下載舞蹈視頻:
https://blog.csdn.net/qq_45176548/article/details/113379829
使用you-get方法獲取B站視頻

2.2 視頻分割
使用opencv,將視頻的分隔為圖片,本文截取 800 張圖片來做詞云,
opencv中通過VideoCaptrue類對視頻進行讀取操作以及呼叫攝像頭
2.2.1代碼展示
# -*- coding:utf-8 -*-
# @File : 視頻分割.py
# @Software : PyCharm
import cv2
cap = cv2.VideoCapture(r"無價之姐~讓我乘風破浪~~~.flv")
while 1:
# 逐幀讀取視頻 按順序保存到本地檔案夾
ret,frame = cap.read()
if ret:
cv2.imwrite(f".\pictures\img_{num}.jpg",frame)
else:
break
cap.release() # 釋放資源2.2.2 結果展示

很多人學習python,不知道從何學起,
很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手,
很多已經做案例的人,卻不知道如何去學習更加高深的知識,
那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!
QQ群:810735403
2.3 人像分割
2.3.1創建應用
利用百度AI,創建一個人像分割的應用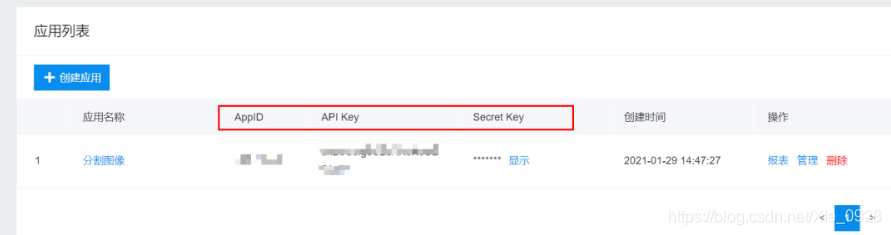
2.3.2 Python SDK參考檔案
利用參考檔案(https://cloud.baidu.com/doc/BODY/s/Rk3cpyo93?_=5011917520845),來進行人像分割
2.3.3 代碼展示
# -*- coding:utf-8 -*-
# @File : 人像分割.py
# @Software : PyCharm
"""原文鏈接:"""
import cv2
import base64
import numpy as np
import os
from aip import AipBodyAnalysis
import time
import random
APP_ID = '******'
API_KEY = '*******************'
SECRET_KEY = '********************'
client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY)
# 保存影像分割后的路徑
path = './mask_img/'
# os.listdir 列出保存到圖片名稱
img_files = os.listdir('./pictures')
print(img_files)
for num in range(1, len(img_files) + 1):
# 按順序構造出圖片路徑
img = f'./pictures/img_{num}.jpg'
img1 = cv2.imread(img)
height, width, _ = img1.shape
# print(height, width)
# 二進制方式讀取圖片
with open(img, 'rb') as fp:
img_info = fp.read()
# 設定只回傳前景 也就是分割出來的人像
seg_res = client.bodySeg(img_info)
labelmap = base64.b64decode(seg_res['labelmap'])
nparr = np.frombuffer(labelmap, np.uint8)
labelimg = cv2.imdecode(nparr, 1)
labelimg = cv2.resize(labelimg, (width, height), interpolation=cv2.INTER_NEAREST)
new_img = np.where(labelimg == 1, 255, labelimg)
mask_name = path + 'mask_{}.png'.format(num)
# 保存分割出來的人像
cv2.imwrite(mask_name, new_img)
print(f'======== 第{num}張影像分割完成 ========')2.3.4 結果展示
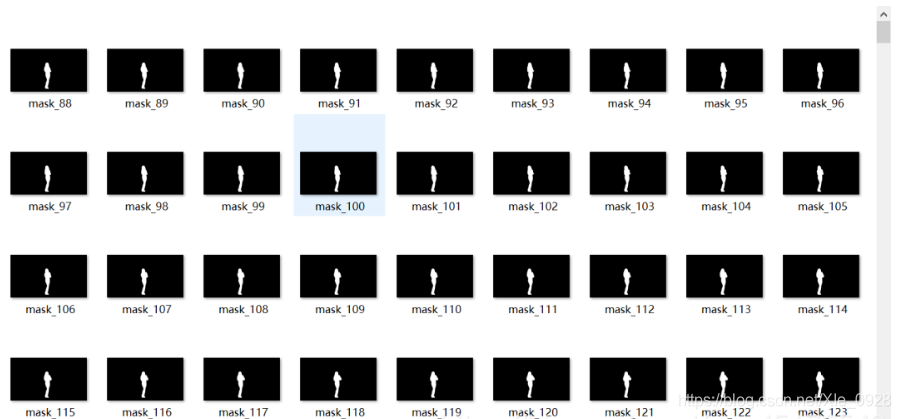
3. 彈幕爬取
由于技術原因,我們改為此視頻來獲取彈幕,視頻鏈接(https://www.bilibili.com/video/BV1jZ4y1K78N/?spm_id_from=333.788.recommend_more_video.0),哈哈哈哈哈,
3.1 網頁分析
通過F12,找到pagelist,通過原始url,找到cid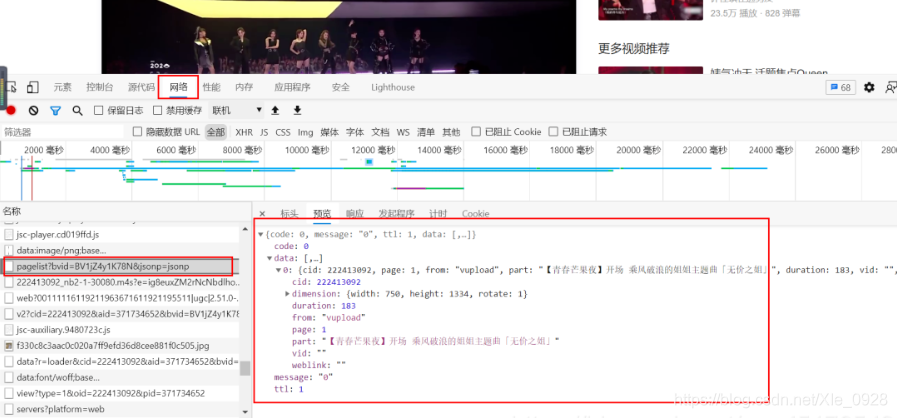
3.2 觀察歷史彈幕
清楚元素,展開彈幕串列
日期串列,只有2021年的,點擊其他日期,出來了history請求,點擊查看
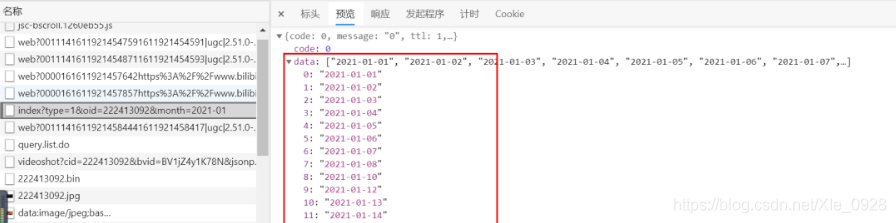
3.3爬取彈幕
3.3.1構造時間序列
該視頻發布于2020-08-09,本文爬取該視頻2020-08-08到2020-09-08日的歷史彈幕資料,構造出時間序列:???????
import pandas as pd
a = pd.date_range("2020-08-08","2020-09-08")
print(a)
DatetimeIndex(['2020-08-08', '2020-08-09', '2020-08-10', '2020-08-11',
'2020-08-12', '2020-08-13', '2020-08-14', '2020-08-15',
'2020-08-50', '2020-08-17', '2020-08-18', '2020-08-19',
'2020-08-20', '2020-08-21', '2020-08-22', '2020-08-23',
'2020-08-24', '2020-08-25', '2020-08-26', '2020-08-27',
'2020-08-28', '2020-08-29', '2020-08-30', '2020-08-31',
'2020-09-01', '2020-09-02', '2020-09-03', '2020-09-04',
'2020-09-05', '2020-09-06', '2020-09-07', '2020-09-08'],
dtype='datetime64[ns]', freq='D')3.3.2 爬取資料
# -*- coding:utf-8 -*-
# @File : 彈幕爬取.py
# @Software : PyCharm
import requests
import pandas as pd
import re
import csv
from fake_useragent import UserAgent
from concurrent.futures import ThreadPoolExecutor
import datetime
ua = UserAgent()
start_time = datetime.datetime.now()
def Grab_barrage(date):
headers = {
"origin": "https://www.bilibili.com",
"referer": "https://www.bilibili.com/video/BV1jZ4y1K78N?from=search&seid=1084505810439035065",
"cookie": "",
"user-agent": ua.random(),
}
params = {
'type': 1,
'oid' : "222413092",
'date': date
}
r= requests.get(url, params=params, headers=headers)
r.encoding = 'utf-8'
comment = re.findall('<d p=".*?">(.*?)</d>', r.text)
for i in comments:
df.append(i)
a = pd.DataFrame(df)
a.to_excel("danmu.xlsx")
def main():
with ThreadPoolExecutor(max_workers=4) as executor:
executor.map(Grab_barrage, date_list)
"""計算所需時間"""
delta = (datetime.datetime.now() - start_time).total_seconds()
print(f'用時:{delta}s')
if __name__ == '__main__':
# 目標url
url = "https://api.bilibili.com/x/v2/dm/history"
start,end = '20200808','20200908'
date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')]
count = 0
main()3.3.3結果展示

4.生成詞云圖
4.1 評論內容機械壓縮去重
對于一條評論來說,有些人可能手誤,或者湊字數,會出現將某個字或者詞語,重復說多次,因此在進行分詞之前,需要做“機械壓縮去重”操作,???????
def func(s):
for i in range(1,int(len(s)/2)+1):
for j in range(len(s)):
if s[j:j+i] == s[j+i:j+2*i]:
k = j + i
while s[k:k+i] == s[k+i:k+2*i] and k<len(s):
k = k + i
s = s[:j] + s[k:]
return s
data["短評"] = data["短評"].apply(func)4.2 添加停用詞和自定義詞組???????
import pandas as pd
from wordcloud import WordCloud
import jieba
from tkinter import _flatten
import matplotlib.pyplot as plt
jieba.load_userdict("./詞云圖//add.txt")
with open('./詞云圖//stoplist.txt', 'r', encoding='utf-8') as f:
stopWords = f.read()4.3生成詞云圖
# -*- coding:utf-8 -*-
# @File : 跳舞詞云圖生成.py
# @Software : PyCharm
from wordcloud import WordCloud
import collections
import jieba
import re
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
with open('barrages.txt') as f:
data = f.read()
jieba.load_userdict("./詞云圖//add.txt")
# 讀取資料
with open('barrages.txt') as f:
data = f.read()
jieba.load_userdict("./詞云圖//add.txt")
# 文本預處理 去除一些無用的字符 只提取出中文出來
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分詞
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('./詞云圖/stoplist.txt', encoding='utf-8') as f:
con = f.read().split('\n')
stop_words = set()
for i in con:
stop_words.add(i)
for word in seg_list_exact:
# 設定停用詞并去除單個詞
if word not in stop_words and len(word) > 1:
result_list.append(word)
# 篩選后統計詞頻
word_counts = collections.Counter(result_list)
path = './wordcloud/'
img_files = os.listdir('./mask_img')
print(img_files)
for num in range(1, len(img_files) + 1):
img = fr'.\mask_img\mask_{num}.png'
# 獲取蒙版圖片
mask_ = 255 - np.array(Image.open(img))
# 繪制詞云
plt.figure(figsize=(8, 5), dpi=200)
my_cloud = WordCloud(
background_color='black', # 設定背景顏色 默認是black
mask=mask_, # 自定義蒙版
mode='RGBA',
max_words=500,
font_path='simhei.ttf', # 設定字體 顯示中文
).generate_from_frequencies(word_counts)
# 顯示生成的詞云圖片
plt.imshow(my_cloud)
# 顯示設定詞云圖中無坐標軸
plt.axis('off')
word_cloud_name = path + 'wordcloud_{}.png'.format(num)
my_cloud.to_file(word_cloud_name) # 保存詞云圖片
print(f'======== 第{num}張詞云圖生成 ========')5. 合成視頻
如官方檔案所介紹的,moviepy是一個用于視頻編輯Python庫,可以切割、拼接、標題插入,視頻合成(即非線性編輯),進行視頻處理和自定義效果的設計,總的來說,可以很方便自由地處理視頻、圖片等檔案,
5.1圖片合成
# -*- coding:utf-8 -*-
# @File : 跳舞詞云圖生成.py
# @Software : PyCharm
import cv2
import os
# 輸出視頻的保存路徑
video_dir = 'result.mp4'
# 幀率
fps = 30
# 圖片尺寸
img_size = (1920, 1080)
fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4會有警告但可以播放
videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)
img_files = os.listdir('.//wordcloud')
for i in range(88, 888):
img_path = './/wordcloud//wordcloud_{}.png'.format(i)
frame = cv2.imread(img_path)
frame = cv2.resize(frame, img_size) # 生成視頻 圖片尺寸和設定尺寸相同
videoWriter.write(frame) # 寫進視頻里
print(f'======== 按照視頻順序第{i}張圖片合進視頻 ========')
videoWriter.release() # 釋放資源結果展示:

5.2 音頻添加
# -*- coding:utf-8 -*-
# @File : 跳舞詞云圖生成.py
# @Software : PyCharm
import moviepy.editor as mpy
# 讀取詞云視頻
my_clip = mpy.VideoFileClip('result.mp4')
# 截取背景音樂
audio_background = mpy.AudioFileClip('song.mp3').subclip(0,25)
audio_background.write_audiofile('song1.mp3')
# 視頻中插入音頻
final_clip = my_clip.set_audio(audio_background)
# 保存為最終的視頻 動聽的音樂!漂亮小姐姐詞云跳舞視頻!
final_clip.write_videofile('final_video.mp4')
在這里還是要推薦下我自己建的Python開發交流學習(qq)群:810735403,群里都是學Python開發的,如果你正在學習Python ,歡迎你加入,大家都是軟體開發黨,不定期分享干貨(只有Python軟體開發相關的),包括我自己整理的一份2021最新的Python進階資料和高級開發教程,歡迎進階中和想深入Python的小伙伴!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/256800.html
標籤:python