文章目錄
- 前言
- 資料爬取
- 測驗類別庫
- 1.urllib.request( 獲取網頁HTML源代碼)
- 2.re(匹配HTML源代碼)
- 3.bs4(HTML/XML的決議器)
- 搜索檔案樹
- CSS選擇器
- 4.xlwt(決議出的資料保存到Excel)
- 5.sqlite3(決議出的資料保存到sqlite資料庫)
- 執行流程
- 爬取結果
- 資料可視化
- Flask框架目錄結構
- 詞云
- Echarts圖表
前言
參考B站Python爬蟲基礎5天速成(2021全新合集)Python入門+資料可視化學習制作,以下是我學習程序中的心得體會,由于整個專案太大,部分代碼未做展示,感興趣的伙伴評論留言,可獲取源代碼或相關資源,
資料爬取
from bs4 import BeautifulSoup # 網頁決議,獲取資料
import re # 正則運算式,進行文字匹配
import urllib.request as urlre # 指定rul,獲取網頁資料
import xlwt # 操作Excel
import sqlite3 # 操作資料庫
測驗類別庫
1.urllib.request( 獲取網頁HTML源代碼)
import urllib.request
url = 'https://movie.douban.com/top250?start='
data = bytes(urllib.parse.urlencode({"":""}),encoding='utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
# 獲取網頁HTML源代碼
urllib.request.urlopen(urllib.request.Request(url=url,data=data,headers=headers,method='POST')).read().decode('utf-8')
# 獲取一個get請求
response = urlre.urlopen('http://www.baidu.com')
# 獲取網頁源代碼
print(response.read().decode('utf-8'))
# response = re.urlopen('http://www.baidu.com')
# 網頁狀態 200
# print(response.status)
# 當我們訪問網頁時瀏覽器會向服務器發送請求頭,里面包含瀏覽器版本等資訊
# 如果我們的爬蟲用get方式直接訪問就會被有反爬機制的服務器識破我們的身份
# 因此我們需要用post方式發送請求,使用代理重新設定headers,并且通過urllib.parse模擬用戶登錄
# print(response.getheaders())
# print(response.getheader('Server'))
# 超時處理
# try:
# response = re.urlopen('https://httpbin.org/get',timeout=0.5)
# print(response.read().decode('utf-8'))
# except Exception as e:
# print(e)
# 獲取一個post請求,模擬用戶登錄時使用
# import urllib.parse
# data = bytes(urllib.parse.urlencode({"":""}),encoding='utf-8')
# response = re.urlopen('https://httpbin.org/post',data=data)
# print(response.read().decode('utf-8'))
url = 'https://movie.douban.com/top250?start='
data = bytes(urllib.parse.urlencode({"":""}),encoding='utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
req = re.Request(url=url,data=data,headers=headers,method='POST')
response = re.urlopen(req)
print(response.read().decode('utf-8'))
2.re(匹配HTML源代碼)
# m = re.compile('aa').search('cab')
# m = re.search('aa','dadaa') # 前面是規則,后面是校驗物件
# <re.Match object; span=(3, 5), match='aa'>
m = re.findall('[a-c]','dkcfjsabaefaf') # 找到所有匹配的項
# ['c', 'a', 'a', 'a']
m = re.sub('a','A','asdfgdada') # 找到a,用A替換
# AsdfgdAdA
3.bs4(HTML/XML的決議器)
BeautifulSoup4將復雜HTML檔案轉換成一個復雜的樹形結構,每個節點都是Python物件,所有物件被歸納為4種:
- Tag 標簽及其內容(查找第一個符合要求的標簽)
對于 Tag,它有兩個重要的屬性,是 name 和 attrs - NavigableString string 標簽內容
- BeautifulSoup 整個檔案
- Comment 一個特殊型別的 NavigableString 物件,輸出的內容不包括注釋符號
搜索檔案樹
find_all(name, attrs, recursive, text, *kwargs)
在上面的栗子中我們簡單介紹了find_all的使用,接下來介紹一下find_all的更多用法-過濾器,這些過濾器貫穿整個搜索API,過濾器可以被用在tag的name中,節點的屬性等,
# 兩者是相等的# t_list = bs.find_all("a") => t_list = bs("a")
傳入引數:
-
字串過濾:會查找與字串完全匹配的內容
-
正則運算式過濾:如果傳入的是正則運算式,那么BeautifulSoup4會通過search()來匹配內容
-
串列:如果傳入一個串列,BeautifulSoup4將會與串列中的任一元素匹配到的節點回傳
-
方法:傳入一個方法,根據方法來匹配
CSS選擇器
BeautifulSoup支持發部分的CSS選擇器,在Tag獲取BeautifulSoup物件的.select()方法中傳入字串引數,即可使用CSS選擇器的語法找到Tag
通過標簽名查找
print(bs.select('title'))
屬性查找
print(bs.select('a[class="bri"]'))
更多見beautifulsoup菜鳥教程
4.xlwt(決議出的資料保存到Excel)
import xlwt # 操作Excel
workbook = xlwt.Workbook(encoding='utf-8') # 創建Excel作業表
worksheet = workbook.add_sheet('sheet1') # 創建作業簿
worksheet.write(0,0,'hello') # 在作業簿第一行第一列設定資料
workbook.save('student.xlsx') # 命名并保存作業表
5.sqlite3(決議出的資料保存到sqlite資料庫)
conn = sqlite3.connect('db.sqlite3') # 打開或創建資料庫檔案
cursor = conn.cursor() # 創建游標
# sql = '''
# create table company(
# id int primary key not null,
# name text not null,
# age int not null,
# address char(20),
# salary real
# );
# '''
# sql = '''
# insert into company values(1,'張三',10,'重慶',8888);
# '''
result = cursor.execute('select * from company')
for i in result:
print('id=',i[0])
print('id=',i[1])
print('id=',i[2])
print('id=',i[3])
# result = cursor.fetchall()
# print(result)
# conn.commit()
cursor.close()
conn.close()
執行流程
# 通過urllib.request決議一個指定url內容,回傳網頁HTML原始碼
def askUrl(url):
headers = { # 模擬瀏覽器頭部資訊,發送給豆瓣服務器,一般網站有反爬機制,檢測到爬蟲禁止訪問
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
# 用戶代理,避免被發現是爬蟲,告訴豆瓣瀏覽器我們是什么型別的機器(本質上是告訴瀏覽器我們可以接收什么水平的檔案內容)
}
req = urlre.Request(url=url, headers=headers)
try:
response = urlre.urlopen(req)
html = response.read().decode('utf-8')
# print(html)
except Exception as e:
print(e)
return html
# HTML原始碼中找到需要資訊的標簽,用正則模糊匹配
findLink = re.compile(r'<a href="(.*?)"') # 影片詳情鏈接
findImgSrc = re.compile(r'<img.*src="(.*?)"',re.S) # 影片圖片,re.S去掉換行符
......
# 找到子網頁的地址規律,給askUrl決議每個子網頁
# 通過bs4中的BeautifulSoup搜索每個子網頁的檔案樹
# 回圈遍歷每個子網頁,將資訊保存在串列中,最后將串列保存在存放串列的串列中
def getData(baseurl):
datalist = []
for i in range(10): # 獲取頁面資訊十次
url = baseurl + str(i*25)
html = askUrl(url) # 保存獲取到的網頁原始碼
# 逐一決議資料
soup = BeautifulSoup(html,'html.parser')
for item in soup.find_all('div',class_='item'): # 查找符合要求的字串,形成串列
# print(item)
data = [] # 保存一部電影的所有資訊
item = str(item)
# 七項資訊,其中titles占兩個位置,陣列中每八位保存一部電影資訊
# 影片詳情鏈接
link = re.findall(findLink,item)[0] # 查找指定字串
data.append(link)
.....
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data) # 將處理好的一部電影資訊放入datalist
# for i in data:
# print(i)
print('資料爬取成功')
return datalist
# 保存資料到excel
def saveData(dataList,savePath):
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('sheet1')
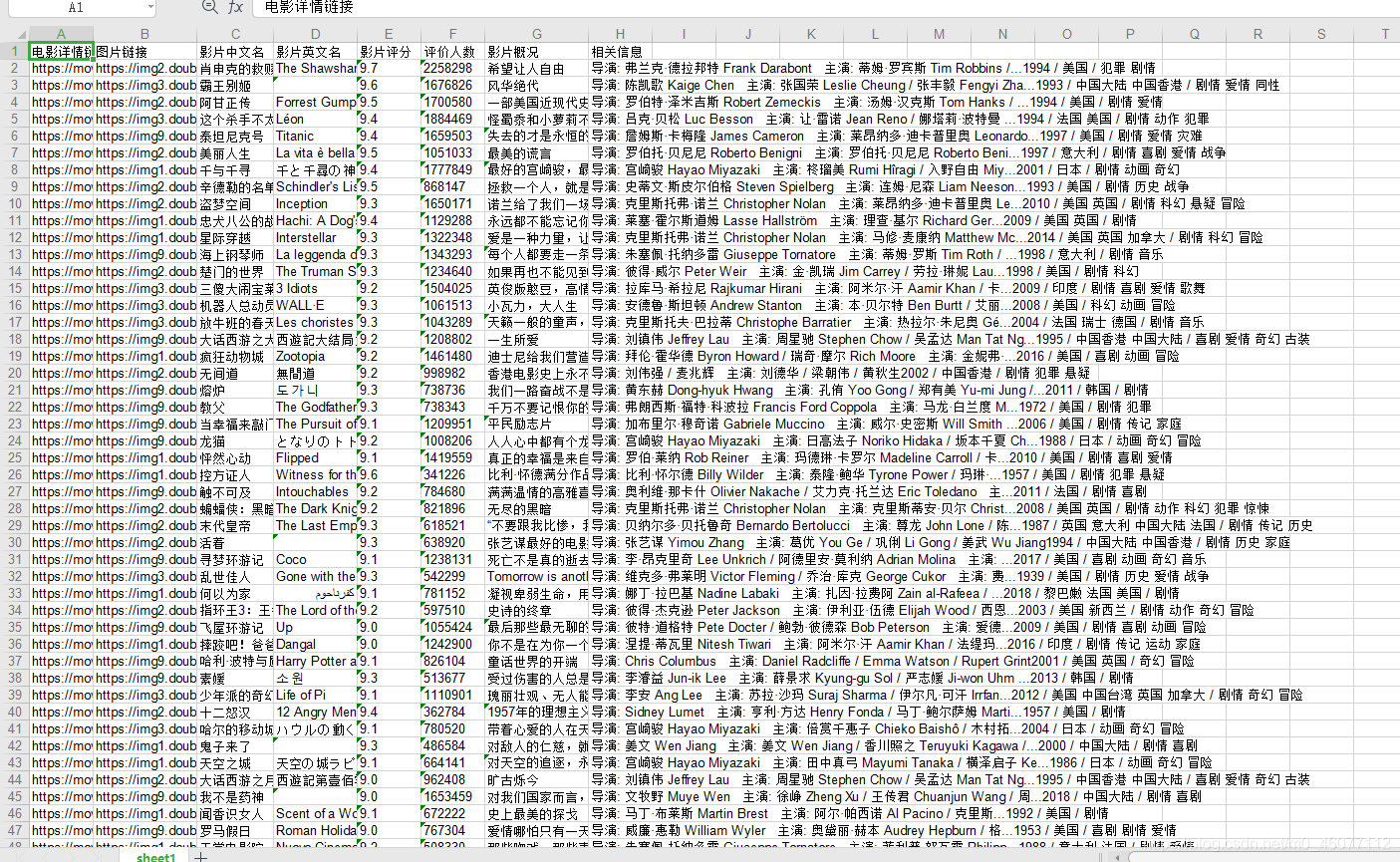
colTitle = ('電影詳情鏈接', '圖片鏈接', '影片中文名', '影片英文名', '影片評分', '評價人數', '影片概況', '相關資訊')
for i in range(8):
worksheet.write(0, i, colTitle[i])
for i in range(250):
item = dataList[i]
for j in range(8):
data = item[j]
worksheet.write(i + 1, j, data)
workbook.save(savePath)
# 保存資料到sqlite資料庫
def saveDataBase(dataList,savePath):
conn = sqlite3.connect(savePath) # 打開或創建資料庫檔案
cur = conn.cursor()
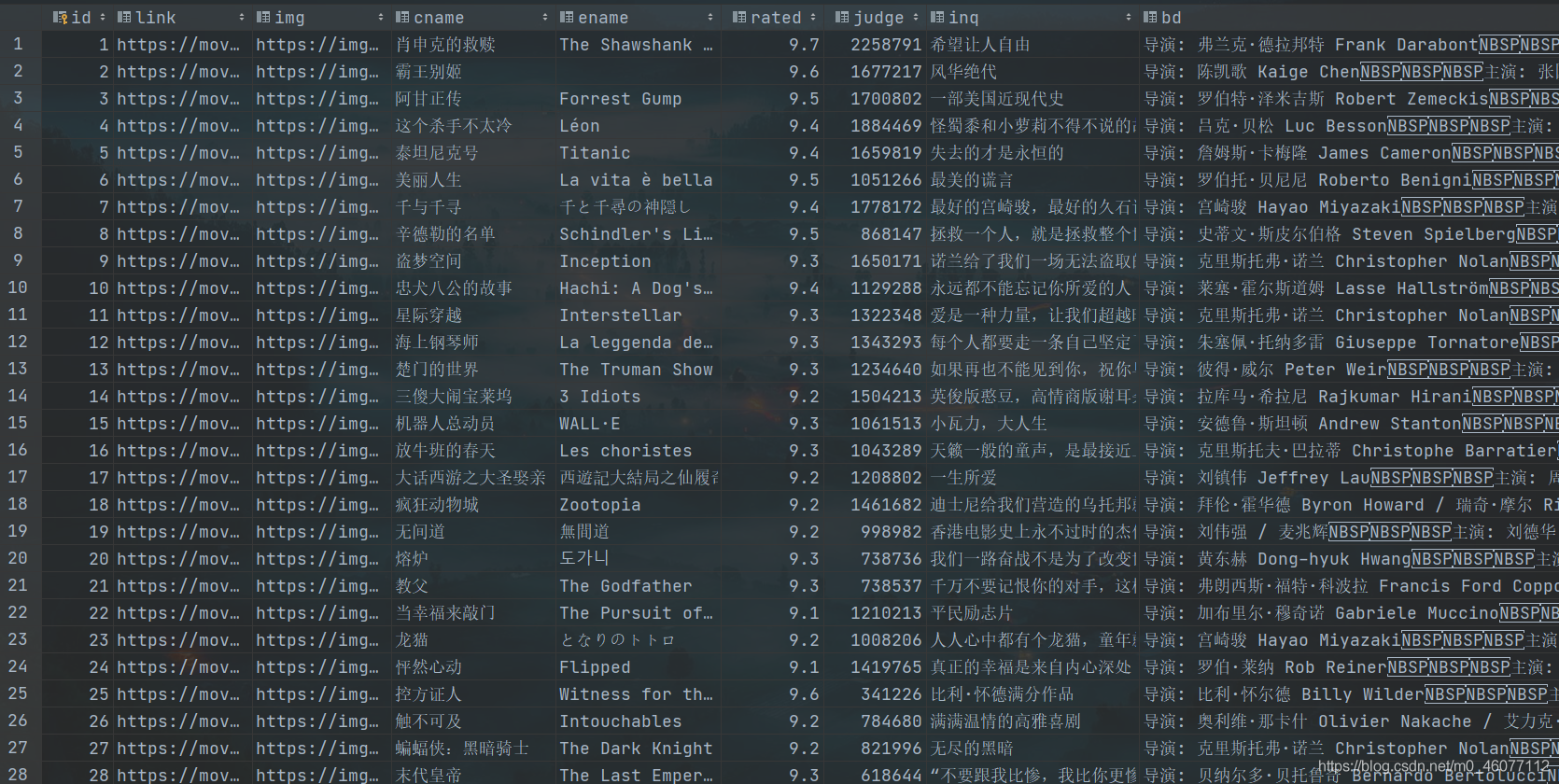
sqlCr = '''
create table db_top250 if not exists(
id int primary key autoincrement,
link text,
img text,
cname varchar,
ename varchar,
rated int,
judge int,
inq text,
bd text
);
'''
cur.execute(sqlCr)
for item in dataList:
for i in range(len(item)):
if i == 4 or i == 5:
continue
item[i] = '"'+item[i]+'"'
sqlIn = '''
insert into db_top250(link,img,cname,ename,rated,judge,inq,bd) values(%s)
''' % ','.join(item) # 將,添加在每個item之間
cur.execute(sqlIn)
conn.commit()
cur.close()
conn.close()
爬取結果
資料可視化
Flask框架目錄結構
詞云
import jieba # 分詞
from matplotlib import pyplot as plt # 繪圖,資料可視化
from wordcloud import WordCloud # 詞云
from PIL import Image # 圖形處理
import numpy as np # 矩陣運算
import sqlite3 # 資料庫
# 準備詞云所需的文本
con = sqlite3.connect('../../movie.db')
cur = con.cursor()
sql = 'select inq from db_top250'
data = cur.execute(sql)
text = ''
for item in data:
text = text + item[0]
# print(text)
cur.close()
con.close()
# 分詞
cut = jieba.cut(text)
print(cut) # 生成器<generator object Tokenizer.cut at 0x0CA06A38>
string = ' '.join(cut)
# print(len(string)) # 5543
img = Image.open('../../tree.jpg') # 打開遮罩圖片
img_array = np.array(img) # 將圖片轉化為陣列
wc = WordCloud(
background_color='white',
mask=img_array,
font_path='simfang.ttf' # 禹衛書法行書簡體.ttf
)
wc.generate_from_text(string)
# 繪制圖片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 坐標軸顯示
# plt.show()
plt.savefig('../../word.jpg',dpi=500)

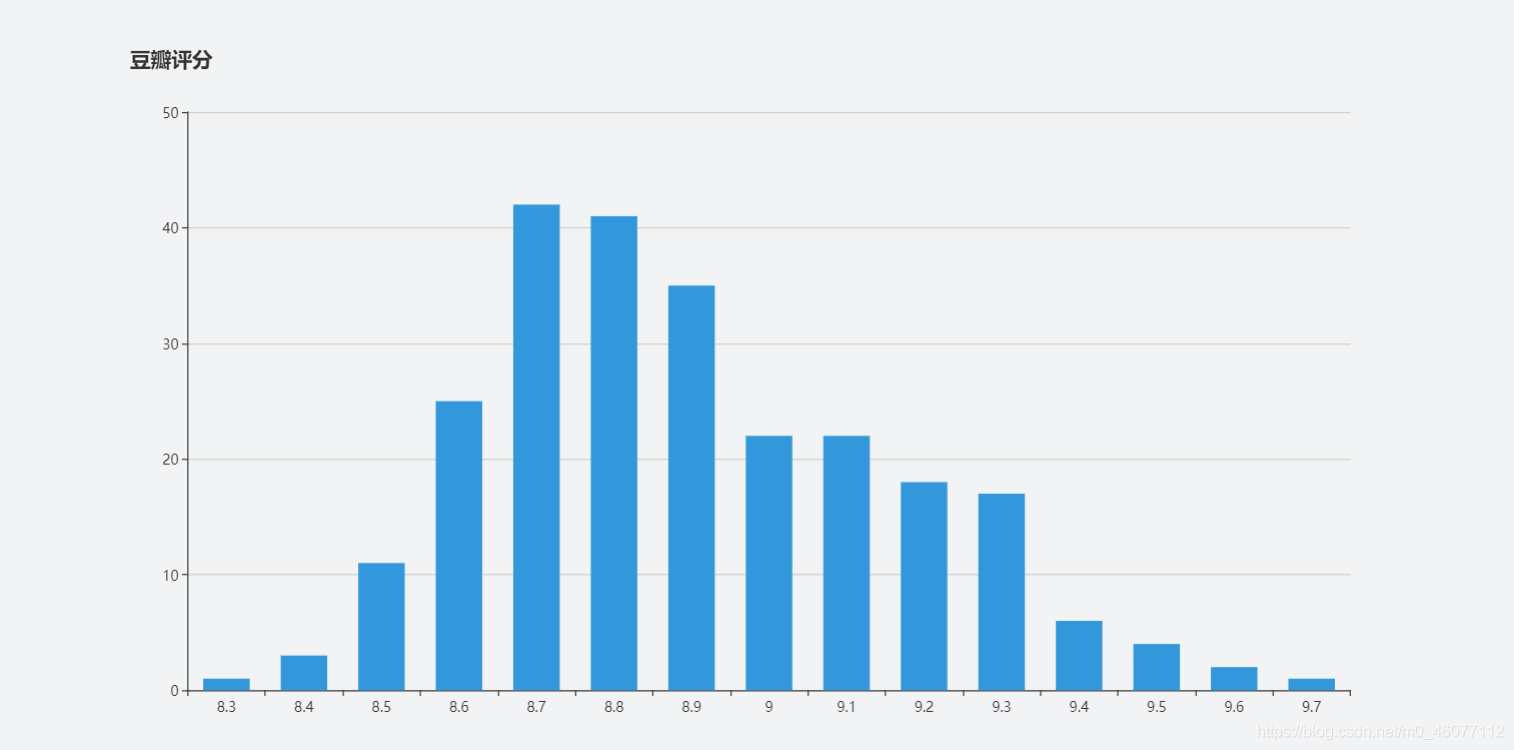
Echarts圖表
Echarts官網
# 需要下載匯入Echarts的js檔案
<script src="../static/js/echarts.min.js"></script>
<script type="text/javascript">
var myChart = echarts.init(document.getElementById('main-lb'));
// 指定圖表的配置項和資料
option = {
title:{
text:'豆瓣評分'
},
color:['#3398DB'],
tooltip: {
trigger: 'axis',
axisPointer: { // 坐標軸指示器,坐標軸觸發有效
type: 'shadow' // 默認為直線,可選為:'line' | 'shadow'
}
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: [
{
type: 'category',
data: {{ score|tojson }}
// ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'],
/*axisTick: {
alignWithLabel: true
}*/
}
],
yAxis: [
{
type: 'value'
}
],
series: [
{
name: 'score',
type: 'bar',
barWidth: '60%',
data: {{count}}
// [10, 52, 200, 334, 390, 330, 220]
}
]
};
// 使用剛指定的配置項和資料顯示圖表,
myChart.setOption(option);
</script>
{
type: 'value'
}
],
series: [
{
name: 'score',
type: 'bar',
barWidth: '60%',
data: {{count}}
// [10, 52, 200, 334, 390, 330, 220]
}
]
};
// 使用剛指定的配置項和資料顯示圖表,
myChart.setOption(option);
</script>
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/258960.html
標籤:python
上一篇:說說 Python 中的閉包