python爬取下廚房每周最受歡迎菜譜
1、分析程序
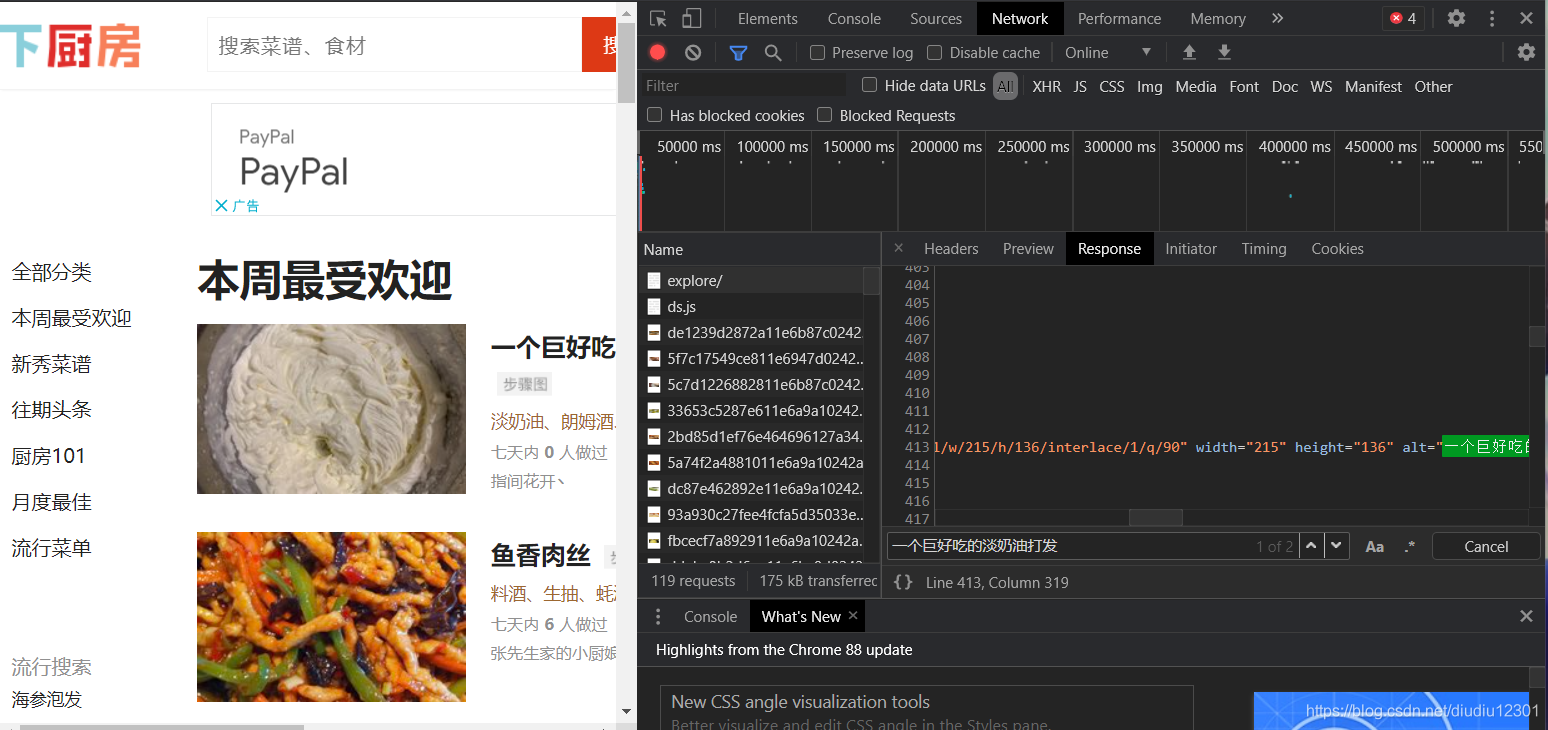
1、進入網頁——下廚房,右鍵->檢查->Network->All,重繪網頁點擊第0個請求,再點擊response,按下ctrl+f查找任意一個菜名,如能在response中找到,則資料放在html里,則可回傳觀察網頁源代碼,點擊Elements,
注:如果在response中找不到資料,則資料應在XHR里,那么就要使用另一種方式抓取資料,本文只介紹在html里抓取資料
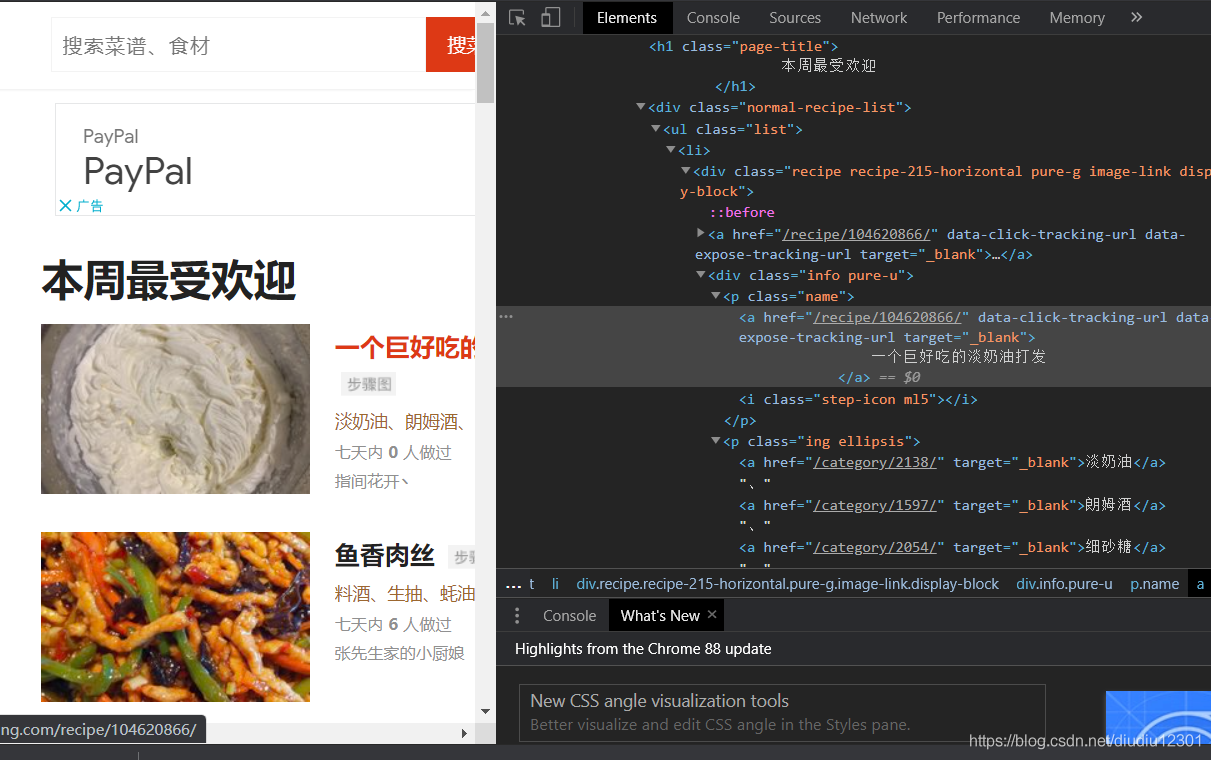
2、在Elements里找到我們需要抓取的資料(菜名、用料、鏈接),可以在菜名這里點擊右鍵檢查快速找到,可以發現菜名和鏈接放在標簽
[p class=’‘name’’]里,用料則放在標簽 [p class=“ing ellipsis”] 里,根據菜名的路徑、URL的路徑、食材的路徑,我們可以找到這三者的最小共同父級標簽,是:[div class=“recipe recipe-215-horizontal pure-g image-link display-block”], 菜名和食材我們可以通過提取標簽里的文本(text)得到,鏈接我們可以提取標簽里的herf與https://www.xiachufang.com/做拼接獲得,本周最受歡迎菜譜里一共有20頁,觀察網址我們發現,只需要通過改變鏈接末尾的page=的數值即可實作翻頁,
2、代碼實作
1、模塊匯入
#沒有模塊的請先下載相關模塊,可以在終端輸入 **pip installer 模塊名** 下載,或者在pycharm軟體中點擊
File->Setting->project->python interpreter 里下載,
#使用request來獲取資料,使用BeautifulSoup來決議資料,使用csv或者openpyxl來存盤資料,
import requests,csv,openpyxl
from bs4 import BeautifulSoup
2、獲取決議資料
#獲取所有目標url,本周最受歡迎菜譜里一共有20頁,觀察網址我們發現,只需要通過改變鏈接末尾的page=的數值即可實作翻頁,
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'} #添加request headers,偽裝成瀏覽器登錄,若不添加則會被瀏覽器認出來是爬蟲,而有的瀏覽器會限制爬蟲,比如下廚房,
foods_list = [] #存盤食物資料
for i in range(1,21):
url = 'https://www.xiachufang.com/explore/?page='+str(i) #通過改變i的數值達到爬取所有網頁的目的
res = requests.get(url,headers=headers) #獲取資料
soup = BeautifulSoup(res.text,'html.parser') #決議資料
inf = soup.find_all('div',class_="recipe recipe-215-horizontal pure-g image-link display-block") #找到最小父級共同標簽
for food in inf:
food_name = food.find('img')['alt'] #菜名
food_ingredients = food.find('p',class_='ing ellipsis').text #食材
food_href = 'https://www.xiachufang.com/'+ food.find('a')['href'] #鏈接
foods_list.append([food_name,food_href,food_ingredients]) #把獲取的資料添加到串列
print('菜名:\t%s\n用料:\t%s鏈接:\t%s\n'%(food_name,food_ingredients,food_href)) #列印
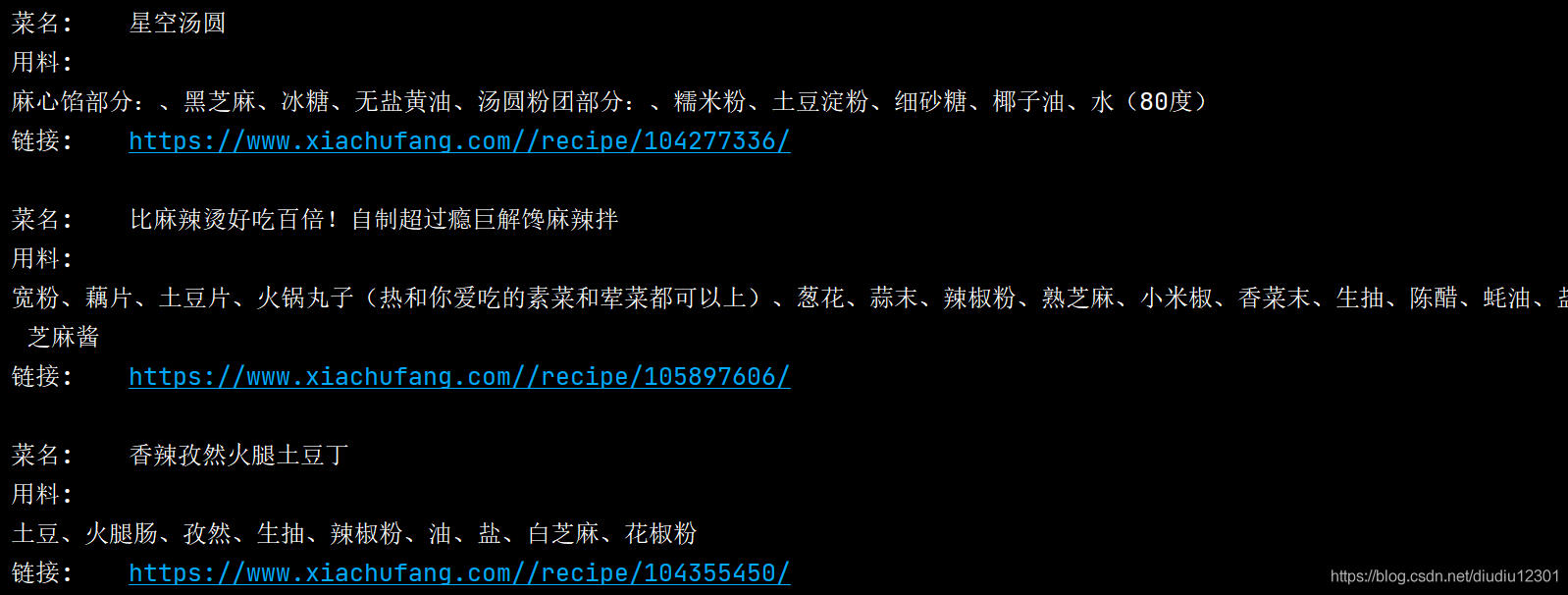
代碼寫到這里可進行編譯(編譯結果部分截圖):
3、資料存盤
存盤為xlsx格式
#使用xlsx存盤,需要匯入openxlsx模塊
wb = openpyxl.Workbook() #創建作業薄
sheet = wb.active #獲取作業薄活動表
sheet.title = 'menu' #命名
headers = ['菜品','鏈接','用料'] #表頭
sheet.append(headers)
for food in foods_list:
sheet.append(food) #添加資料
wb.save('xiachufang.xlsx') #保存

存盤為csv格式
#使用csv保存,需要匯入csv模塊,
#呼叫open()函式打開csv檔案,引數為: 檔案名'下廚房.csv',寫入模式 'w',newline='',encoding='utf-8',
with open('下廚房.csv','w',newline='',encoding='utf-8')as file:
header = ['菜品','鏈接','用料'] #表頭
writer = csv.writer(file) #創建writer物件
writer.writerow(header) #添加表頭
for food in foods_list:
writer.writerow(food) #添加資料

4、完整代碼
import requests,pprint,csv,openpyxl
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'} #添加request headers,偽裝成瀏覽器登錄,若不添加則會被瀏覽器認出來是爬蟲,而有的瀏覽器會限制爬蟲,比如下廚房,
foods_list = [] #存盤食物資料
for i in range(1,21):
url = 'https://www.xiachufang.com/explore/?page='+str(i) #通過改變i的數值達到爬取所有網頁的目的
res = requests.get(url,headers=headers) #獲取資料
soup = BeautifulSoup(res.text,'html.parser') #決議資料
inf = soup.find_all('div',class_="recipe recipe-215-horizontal pure-g image-link display-block") #找到最小父級共同標簽
for food in inf:
food_name = food.find('img')['alt'] # 菜名
food_ingredients = food.find('p', class_='ing ellipsis').text # 食材
food_href = 'https://www.xiachufang.com/' + food.find('a')['href'] # 鏈接
foods_list.append([food_name, food_href, food_ingredients]) # 把獲取的資料添加到串列
print('菜名:\t%s\n用料:%s鏈接:\t%s\n' % (food_name, food_ingredients, food_href)) # 列印
wb = openpyxl.Workbook() #創建作業薄
sheet = wb.active #獲取作業薄活動表
sheet.title = 'menu' #命名
headers = ['菜品','鏈接','用料'] #表頭
sheet.append(headers)
for food in foods_list:
sheet.append(food) #添加資料
wb.save('xiachufang.xlsx') #保存
3、總結
代碼及xlsx,提取碼:3xx2
over,新手小白,多多指教,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/261384.html
標籤:python
上一篇:深入學習Redis_(一)五種基本資料型別、RedisTemplate、RedisCache、快取雪崩等
下一篇:爬取美女壁紙