疲憊的生活我們需要些許的溫柔
我會帶大家進行美女壁紙的爬取,來給生活增添色彩,生活需要有理想和愛人或者說是相互扶持的人,生活才有溫度,因為愛生活才會有希望,
壁紙案例
- 疲憊的生活我們需要些許的溫柔
- 前言
- 一、requests是什么?
- 二、使用步驟
- 1.引入庫
- 2.請求資料
- 3.決議資料
- 4.保存資料
- 5.本地展示
- 6.全部代碼實作
- 總結
前言
例如:隨著大資料的不斷發展,爬蟲技術也越來越重要,很多人都開啟了學習爬蟲,本文就介紹了爬蟲的使用,以下是本篇文章正文內容
一、requests是什么?
Requests 是一個 Python 的 HTTP 客戶端庫,我們可以用它得到HTML原始碼
二、使用步驟
1.引入庫
代碼如下:
本次我們采用的分別是requests請求庫,os檔案操作庫,lxml決議庫,和re正則庫
import requests
import os
from lxml import etree
import re
2.請求資料
代碼如下:
# 獲取網頁原始碼
def get_url(url):
# 進行頭部偽裝
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
}
res=requests.get(url,headers=headers)
res.encoding=res.apparent_encoding
html=res.text
# 回傳HTML頁面
return html
該處使用的url網路請求的資料,
3.決議資料
代碼如下:
def parse_html(html):
# 采用正則進行匹配我們所需要的文本
ul=re.findall(r'<ul class="clearfix">(.*?)</ul>',html,re.S)[0]
e=etree.HTML(ul)
src=e.xpath("//li//a/img/@src")
title=e.xpath("//li//a/b/text()")
for i,z in zip(src,title):
json={
"src":i,
"title":z
}
# 字典型別的傳參
save(json['src'],json['title'])
該處是進行資料的決議與處理,
4.保存資料
代碼如下:
def save(src,name):
src="http://pic.netbian.com/"+src
print("正在保存"+name)
resonse =requests.get(src)
# 創建路徑進行檔案的保存
path = 'E:\\lianxi\\test'
if not os.path.isdir(path):
os.makedirs(path) # 判斷沒有此路徑則創建
# 二進制保存圖片
with open('E:\\lianxi\\test\\'+name+'.jpg', 'wb') as f:
f.write(resonse.content)
該處是進行檔案的保存,
5.本地展示
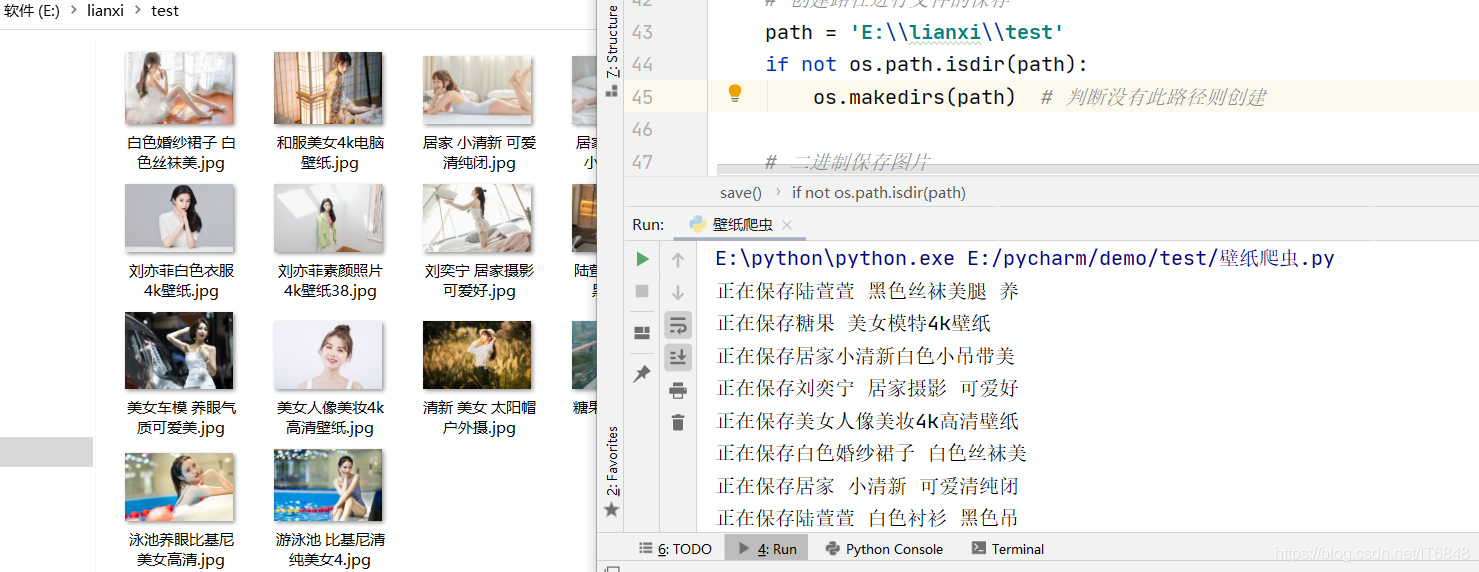
該處是進行展示,
6.全部代碼實作
#!/usr/bin/python3
# --coding:utf-8--
# @Author:陳同學
import requests
import os
from lxml import etree
import re
# 獲取網頁原始碼
def get_url(url):
# 進行頭部偽裝
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
}
res=requests.get(url,headers=headers)
res.encoding=res.apparent_encoding
html=res.text
# 回傳HTML頁面
return html
# 決議網頁
def parse_html(html):
# 采用正則進行匹配我們所需要的文本
ul=re.findall(r'<ul class="clearfix">(.*?)</ul>',html,re.S)[0]
e=etree.HTML(ul)
src=e.xpath("//li//a/img/@src")
title=e.xpath("//li//a/b/text()")
for i,z in zip(src,title):
json={
"src":i,
"title":z
}
# 字典型別的傳參
save(json['src'],json['title'])
# 保存函式
def save(src,name):
src="http://pic.netbian.com/"+src
print("正在保存"+name)
resonse =requests.get(src)
# 創建路徑進行檔案的保存
path = 'E:\\lianxi\\test'
if not os.path.isdir(path):
os.makedirs(path) # 判斷沒有此路徑則創建
# 二進制保存圖片
with open('E:\\lianxi\\test\\'+name+'.jpg', 'wb') as f:
f.write(resonse.content)
if __name__ == '__main__':
html=get_url('http://pic.netbian.com/4kmeinv/index.html')
parse_html(html)
總結
以上就是今天要講的內容,本文對壁紙網站進行爬取,由于時間較為緊張,沒有進行翻頁操作,有興趣的小伙伴可以進行主函式的修改就可以進行翻頁操作,要是有不懂可以私信留言,與大家共同成長,轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/261385.html
標籤:python