本節主要講解的是部分排序演算法,包括快速排序、歸并排序、二分法查找,
文章目錄
- 1. 快速排序
- 1.1 快速排序的分析
- 1.2 快速排序的實作與時間復雜度
- 2. 歸并排序
- 2.1 歸并排序的分析
- 2.2 歸并排序的實作與時間復雜度
- 3. 常見排序演算法效率總結
- 4. 二分法查找
- 4.1 什么是二分法查找
- 4.2 二分法查找的兩種實作
1. 快速排序
快速排序(英語:Quicksort),又稱劃分交換排序(partition-exchange sort),通過一趟排序將要排序的資料分割成獨立的兩部分,其中一部分的所有資料都比另外一部分的所有資料都要小,然后再按此方法對這兩部分資料分別進行快速排序,整個排序程序可以遞回進行,以此達到整個資料變成有序序列,
步驟為:
1.1 快速排序的分析
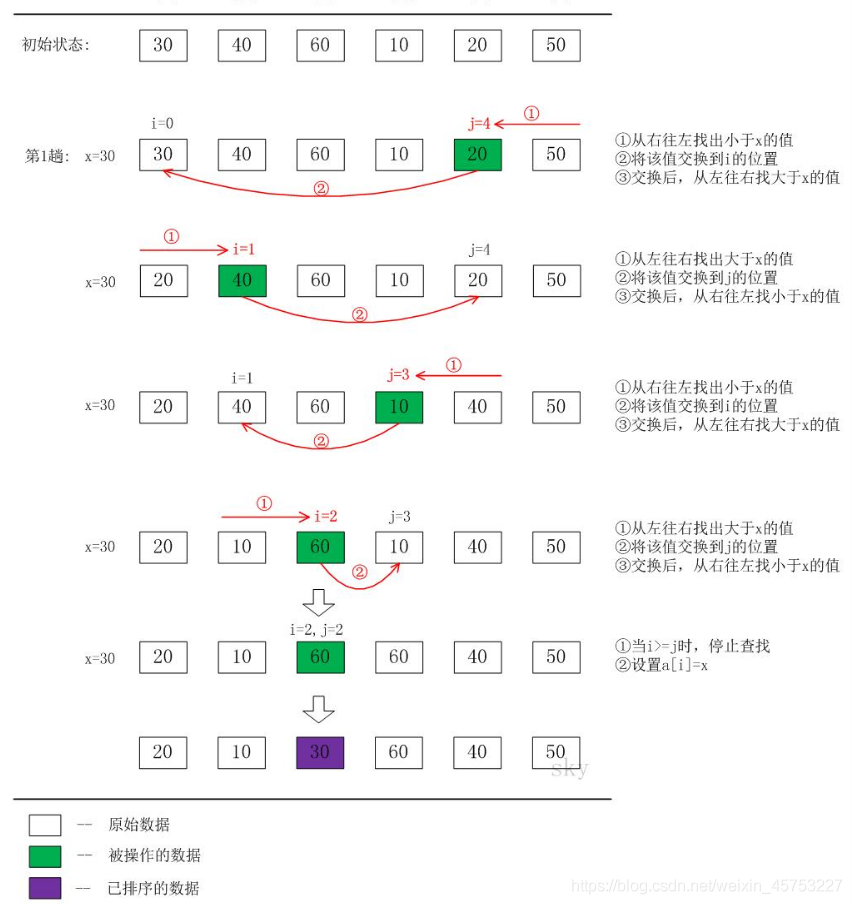
- 從數列中挑出一個元素,稱為"基準"(pivot),
- 重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的后面(相同的數可以到任一邊),在這個磁區結束之后,該基準就處于數列的中間位置,這個稱為磁區(partition)操作,
- 遞回地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序,
遞回的最底部情形,是數列的大小是零或一,也就是永遠都已經被排序好了,雖然一直遞回下去,但是這個演算法總會結束,因為在每次的迭代(iteration)中,它至少會把一個元素擺到它最后的位置去,
1.2 快速排序的實作與時間復雜度
def quick_sort(alist, start, end):
"""快速排序"""
# 遞回的退出條件
if start >= end:
return
# 設定起始元素為要尋找位置的基準元素
mid = alist[start]
# low為序列左邊的由左向右移動的游標
low = start
# high為序列右邊的由右向左移動的游標
high = end
while low < high:
# 如果low與high未重合,high指向的元素不比基準元素小,則high向左移動
while low < high and alist[high] >= mid:
high -= 1
# 將high指向的元素放到low的位置上
alist[low] = alist[high]
# 如果low與high未重合,low指向的元素比基準元素小,則low向右移動
while low < high and alist[low] < mid:
low += 1
# 將low指向的元素放到high的位置上
alist[high] = alist[low]
# 退出回圈后,low與high重合,此時所指位置為基準元素的正確位置
# 將基準元素放到該位置
alist[low] = mid
# 對基準元素左邊的子序列進行快速排序
quick_sort(alist, start, low-1)
# 對基準元素右邊的子序列進行快速排序
quick_sort(alist, low+1, end)
alist = [54,26,93,17,77,31,44,55,20]
quick_sort(alist,0,len(alist)-1)
print(alist)
最優時間復雜度:O(nlogn)
最壞時間復雜度:O(n2)
穩定性:不穩定
從一開始快速排序平均需要花費O(n log n)時間的描述并不明顯,但是不難觀察到的是磁區運算,陣列的元素都會在每次回圈中走訪過一次,使用O(n)的時間,在使用結合(concatenation)的版本中,這項運算也是O(n),
在最好的情況,每次我們運行一次磁區,我們會把一個數列分為兩個幾近相等的片段,這個意思就是每次遞回呼叫處理一半大小的數列,因此,在到達大小為一的數列前,我們只要作log n次嵌套的呼叫,這個意思就是呼叫樹的深度是O(log n),但是在同一層次結構的兩個程式呼叫中,不會處理到原來數列的相同部分;因此,程式呼叫的每一層次結構總共全部僅需要O(n)的時間(每個呼叫有某些共同的額外耗費,但是因為在每一層次結構僅僅只有O(n)個呼叫,這些被歸納在O(n)系數中),結果是這個演算法僅需使用O(n log n)時間,
演示:
2. 歸并排序
歸并排序是采用分治法的一個非常典型的應用,歸并排序的思想就是先遞回分解陣列,再合并陣列,
2.1 歸并排序的分析
將陣列分解最小之后,然后合并兩個有序陣列,基本思路是比較兩個陣列的最前面的數,誰小就先取誰,取了后相應的指標就往后移一位,然后再比較,直至一個陣列為空,最后把另一個陣列的剩余部分復制過來即可,

2.2 歸并排序的實作與時間復雜度
##python2
def merge_sort(alist):
if len(alist) <= 1:
return alist
# 二分分解
num = len(alist)/2
left = merge_sort(alist[:num])
right = merge_sort(alist[num:])
# 合并
return merge(left,right)
def merge(left, right):
'''合并操作,將兩個有序陣列left[]和right[]合并成一個大的有序陣列'''
#left與right的下標指標
l, r = 0, 0
result = []
while l<len(left) and r<len(right):
if left[l] < right[r]:
result.append(left[l])
l += 1
else:
result.append(right[r])
r += 1
result += left[l:]
result += right[r:]
return result
alist = [54,26,93,17,77,31,44,55,20]
sorted_alist = merge_sort(alist)
print(sorted_alist)
最優時間復雜度:O(nlogn)
最壞時間復雜度:O(nlogn)
穩定性:穩定
空間換時間
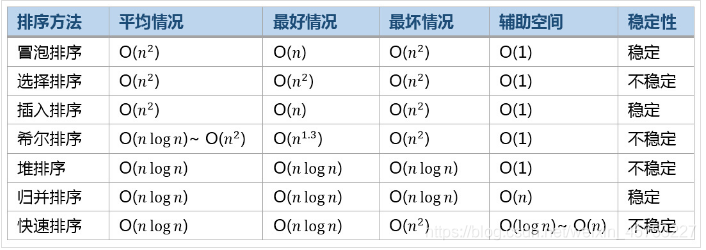
3. 常見排序演算法效率總結
4. 二分法查找
搜索是在一個專案集合中找到一個特定專案的演算法程序,搜索通常的答案是真的或假的,因為該專案是否存在, 搜索的幾種常見方法:順序查找、二分法查找、二叉樹查找、哈希查找,
4.1 什么是二分法查找
二分查找又稱折半查找,優點是比較次數少,查找速度快,平均性能好;其缺點是要求待查表為有序表,且插入洗掉困難,因此,折半查找方法適用于不經常變動而查找頻繁的有序串列,首先,假設表中元素是按升序排列,將表中間位置記錄的關鍵字與查找關鍵字比較,如果兩者相等,則查找成功;否則利用中間位置記錄將表分成前、后兩個子表,如果中間位置記錄的關鍵字大于查找關鍵字,則進一步查找前一子表,否則進一步查找后一子表,重復以上程序,直到找到滿足條件的記錄,使查找成功,或直到子表不存在為止,此時查找不成功,
二分法查找適用于順序表,
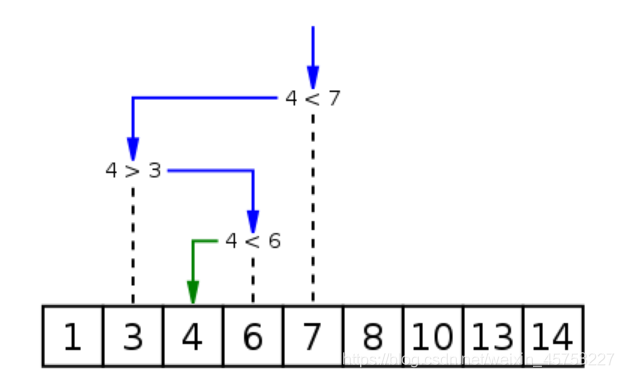
4.2 二分法查找的兩種實作
def binary_search(alist, item):
"""二分法查找非遞回實作 """
first = 0
last = len(alist) - 1
while first <= last:
midpoint = (first + last) // 2
if alist[midpoint] == item:
return True
elif item < alist[midpoint]:
last = midpoint - 1
else:
first = midpoint + 1
return False
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42, ]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))
def binary_search(alist, item):
"""二分法查找遞回實作"""
if len(alist) == 0:
return False
else:
midpoint = len(alist)//2
if alist[midpoint]==item:
return True
else:
if item<alist[midpoint]:
return binary_search(alist[:midpoint],item)
else:
return binary_search(alist[midpoint+1:],item)
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))
最優時間復雜度:O(1)
最壞時間復雜度:O(logn)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/262050.html
標籤:python
上一篇:【資料可視化】基于Dash制作的疫情資料可視化APP(Dash入門必讀,附可運行原始碼)(2021-02-19)