Python爬蟲實戰原始碼合集(持續更新)
百度搜索風云榜:http://top.baidu.com/
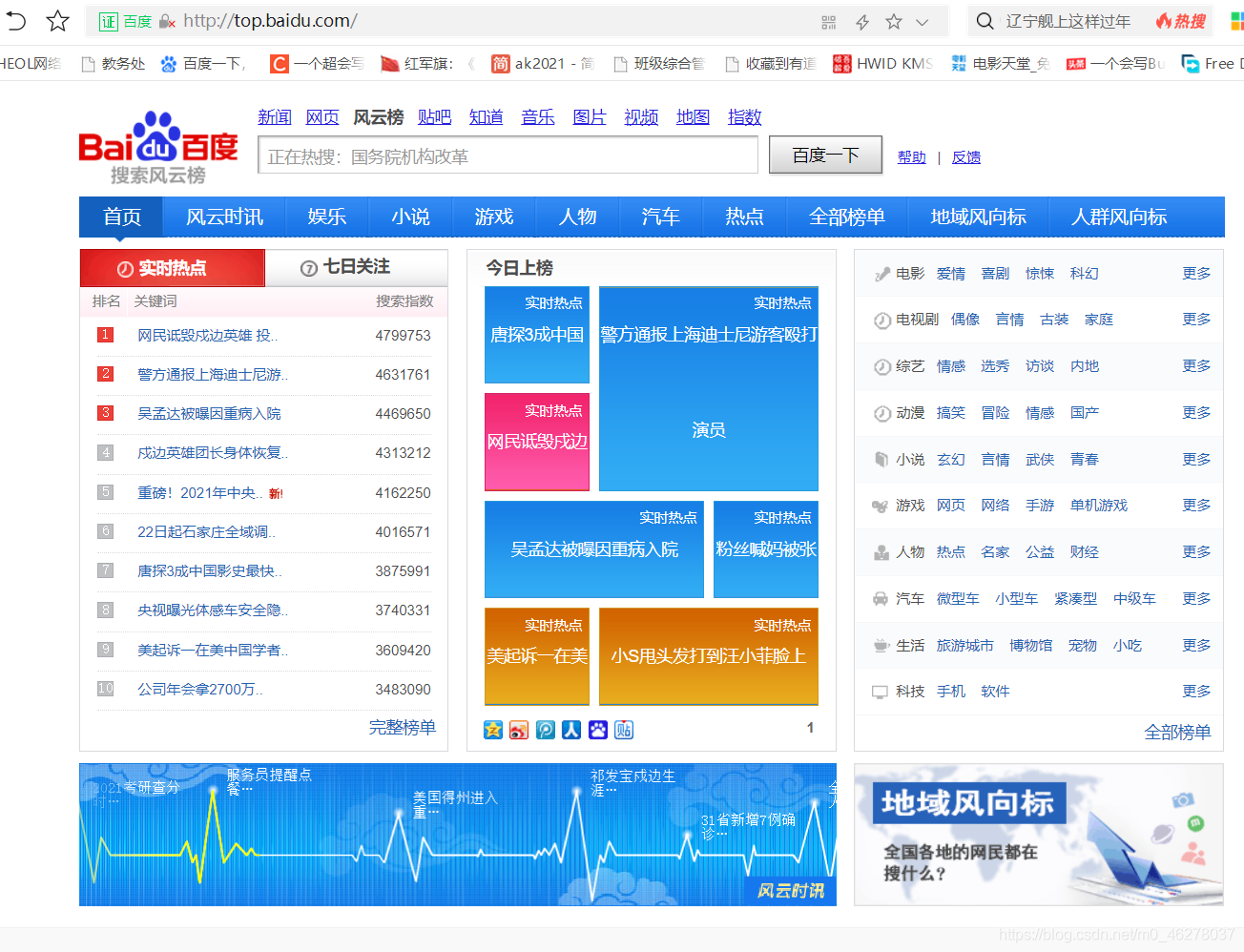
原始碼:
import os
import json
from datetime import datetime
from datetime import timezone
from datetime import timedelta
from collections import OrderedDict
import requests
from bs4 import BeautifulSoup
def get_utc8now():
utcnow = datetime.now(timezone.utc)
utc8now = utcnow.astimezone(timezone(timedelta(hours=8)))
return utc8now
def save_as_json(filename, records):
dict_obj = {}
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as f:
dict_obj = json.load(f, object_pairs_hook=OrderedDict)
time_str = str(get_utc8now())
for keyword, search_index in records:
time_count_dict = {'time': time_str, 'count': search_index}
dict_obj.setdefault(keyword, []).append(time_count_dict)
with open(filename, 'w', encoding='utf-8') as f:
json.dump(dict_obj, f, indent=4, separators=(',',': '),
ensure_ascii=False, sort_keys=False)
def crawl_baidu_top(buzz_no=1):
response = requests.get('http://top.baidu.com/buzz?b={}'.format(buzz_no))
response.encoding = 'gb18030'
soup = BeautifulSoup(response.text, 'html.parser')
table_tag = soup.find('table', {'class': 'list-table'})
item_tags = table_tag.find_all('tr')
keywords, search_indices = [], []
for item in item_tags:
keyword_tag = item.find('td', {'class': 'keyword'})
last_tag = item.find('td', {'class': 'last'})
if (keyword_tag is not None) and (last_tag is not None):
keyword_title_tag = keyword_tag.find('a', {'class': 'list-title'})
keywords.append(keyword_title_tag.text.strip())
search_indices.append(last_tag.text.strip())
return list(zip(keywords, search_indices))
if __name__ == '__main__':
now = get_utc8now()
year_str = now.strftime('%Y')
date_str = now.strftime('%Y%m%d')
os.makedirs(year_str, exist_ok=True)
filename = os.path.join(year_str, '{} 實時熱點.json'.format(date_str))
records = crawl_baidu_top()
save_as_json(filename, records)
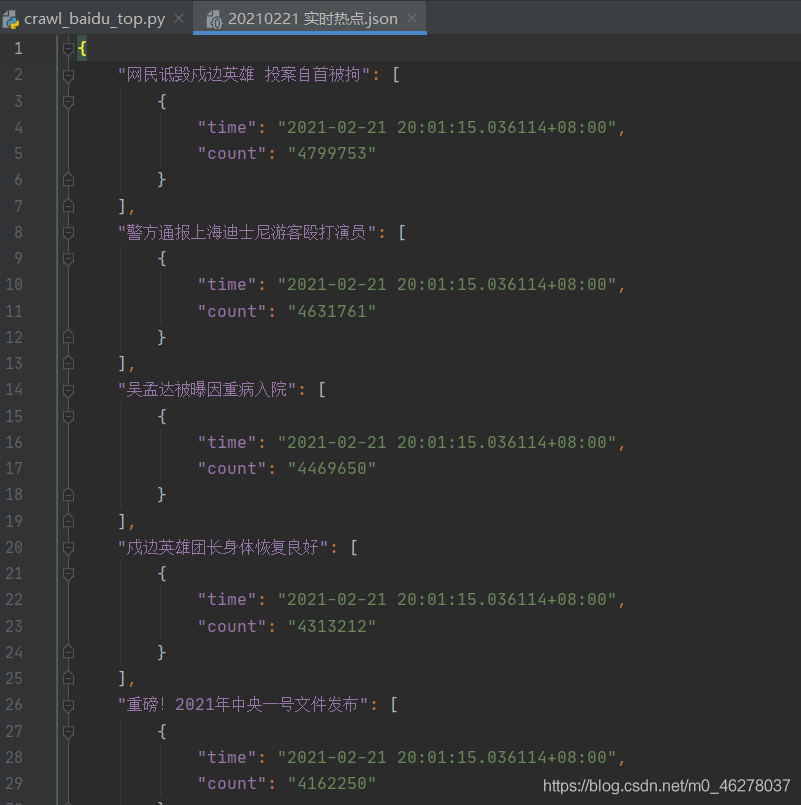
運行:
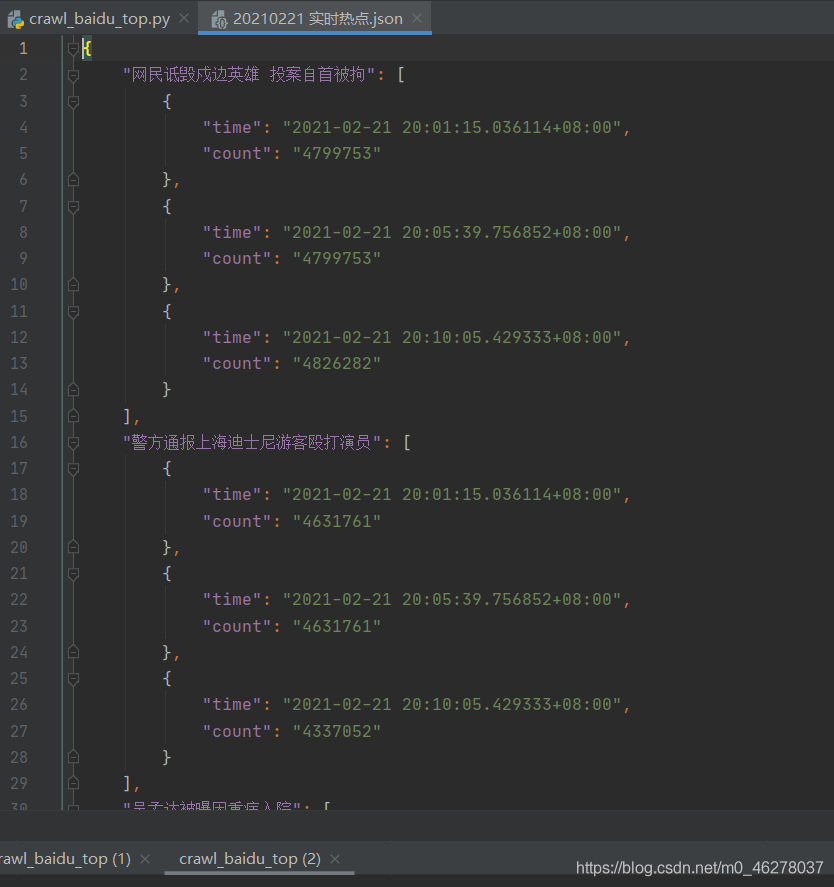
再次運行:

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/262621.html
標籤:python
上一篇:Java撰寫單詞小游戲
下一篇:一個滑動視窗最大差值的演算法